https://github.com/axruff/DeepLearning
A collection of research papers, datasets and software on Deep Learning
https://github.com/axruff/DeepLearning
List: DeepLearning
awesome-list best-practices computer-vision deep-learning machine-learning neural-network neural-networks papers research supervised-learning survey tomography unsupervised-learning
Last synced: 6 months ago
JSON representation
A collection of research papers, datasets and software on Deep Learning
- Host: GitHub
- URL: https://github.com/axruff/DeepLearning
- Owner: axruff
- Created: 2019-01-24T12:50:27.000Z (over 6 years ago)
- Default Branch: master
- Last Pushed: 2023-06-15T12:09:52.000Z (almost 2 years ago)
- Last Synced: 2024-05-20T05:35:43.446Z (about 1 year ago)
- Topics: awesome-list, best-practices, computer-vision, deep-learning, machine-learning, neural-network, neural-networks, papers, research, supervised-learning, survey, tomography, unsupervised-learning
- Homepage:
- Size: 969 KB
- Stars: 26
- Watchers: 5
- Forks: 6
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- ultimate-awesome - DeepLearning - A collection of research papers, datasets and software on Deep Learning. (Other Lists / Julia Lists)
README
# Deep Learning papers and resources
##### Table of Contents
- [💎 Neural Networks](#neural-networks)
- [⭕ Models](#models)
- [Multi-level](#multi-level)
- [Context and Attention](#context-and-attention)
- [Composition](#composition)
- [Capsule Networks](#capsule-networks)
- [Transformers](#transformers)
- [3D Shape and Neural Rendering](#3d-shape)
- [Logic and Semantics](#logic-and-semantics)
- [💪 Optimization](#optimization)
- [Optimization and Regularisation](#optimization-and-regularisation)
- [Pruning, Compression](#pruning-and-compression)
- [📊 Analysis and Interpretability](#analysis-and-interpretability)
- [📜 Tasks](#tasks)
- [Segmentation](#segmentation)
- [Instance Segmentation](#instance-segmentation)
- [Interactive Segmentation](#interactive-segmentation)
- [Semantic Correspondence](#semantic-correspondence)
- [Anomaly Detection](#anomaly-detection)
- [Optical Flow](#optical-flow)
- [⚙️ Methods](#neural-networks)
- [TL - Transfer Learning](#transfer-learning)
- [GM - Generative Modelling](#generative-modelling)
- [WS - Weakly Supervised Learning](#weakly-supervised)
- [SSL - Semi-supervised Learning](#semi-supervised)
- [USL - Un- and Self-supervised Learning](#unsupervised-learning)
- [CL - Collaborative Learning](#mutual-learning)
- [MTL - Multi-task Learning](#multitask-learning)
- [AD - Anomaly Detection](#anomaly-detection)
- [RL - Reinforcement Learning](#reinforcement-learning)
- [IRL - Inverse Reinforcement Learning](#inverse-reinforcement-learning)
- [🎁 Datasets](#datasets)
- [⚔ Benchmarks](#benchmarks)
- [🌍 Applications](#applications)
- [Applications: Medical Imaging](#applications-medical-imaging)
- [Applications: X-ray Imaging](#applications-x-ray-imaging)
- [Applications: Image Registration](#applications-image-registration)
- [Applications: Video and Motion](#applications-video)
- [Applications: Denoising and Superresolution](#application-denoising-and-superresolution)
- [Applications: Inpainting](#applications-inpainting)
- [Applications: Photography](#applications-photography)
- [Applications: Misc](#applications-misc)
- [💻 Software](#software)
- [📈 Overview](#overview)
- [💬 Opinions](#opinions)
**Notations**
:white_check_mark: - Checked
⭕ - To Check
📜 - Survey
# Neural Networks
## Models
[1998 - **[LeNet]**: Gradient-based learning applied to document recognition](https://ieeexplore.ieee.org/document/726791)
[2012 - **[AlexNet]** ImageNet Classification with Deep Convolutional Neural Networks](https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf) ✅
[2013 - Learning Hierarchical Features for Scene Labeling](http://yann.lecun.com/exdb/publis/pdf/farabet-pami-13.pdf)
---
[2013 - **[R-CNN]** Rich feature hierarchies for accurate object detection and semantic segmentation](https://arxiv.org/abs/1311.2524)
Object detection performance, as measured on the canonical PASCAL VOC dataset, has plateaued in the last few years. The best-performing methods are complex ensemble systems that typically combine multiple low-level image features with high-level context. In this paper, we propose a simple and scalable detection algorithm that improves mean average precision (mAP) by more than 30% relative to the previous best result on VOC 2012---achieving a mAP of 53.3%. Our approach combines two key insights: (1) one can apply high-capacity convolutional neural networks (CNNs) to bottom-up region proposals in order to localize and segment objects and (2) when labeled training data is scarce, supervised pre-training for an auxiliary task, followed by domain-specific fine-tuning, yields a significant performance boost. Since we combine region proposals with CNNs, we call our method R-CNN: Regions with CNN features. We also compare R-CNN to OverFeat, a recently proposed sliding-window detector based on a similar CNN architecture. We find that R-CNN outperforms OverFeat by a large margin on the 200-class ILSVRC2013 detection dataset.

[2014 - **[OverFeat]**: Integrated Recognition, Localization and Detection using Convolutional Networks](https://arxiv.org/pdf/1312.6229.pdf)
[2014 - **[Seq2Seq]**: Sequence to Sequence Learning with Neural Networks](https://arxiv.org/pdf/1409.3215.pdf)
---
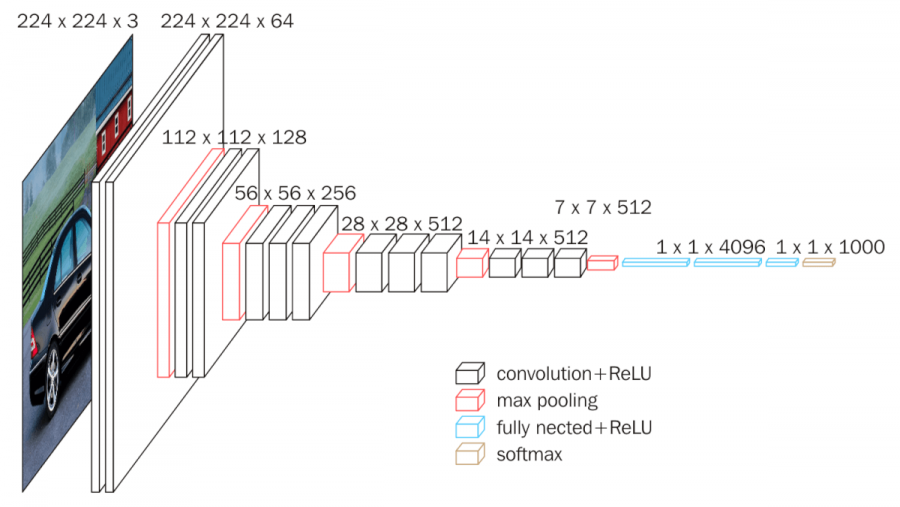
[2014 - **[VGG]** Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556) ✅
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16-19 weight layers. These findings were the basis of our ImageNet Challenge 2014 submission, where our team secured the first and the second places in the localisation and classification tracks respectively. We also show that our representations generalise well to other datasets, where they achieve state-of-the-art results. We have made our two best-performing ConvNet models publicly available to facilitate further research on the use of deep visual representations in computer vision.
---
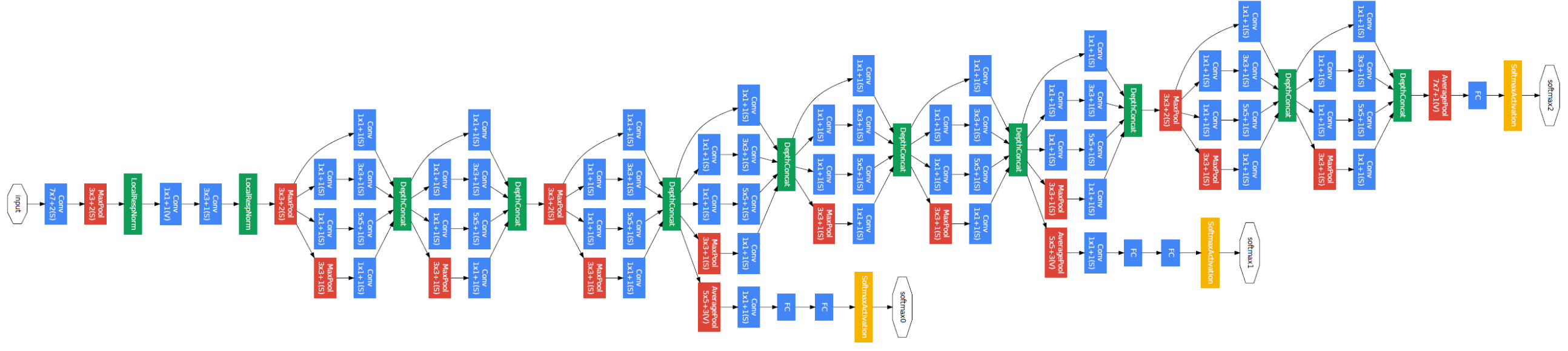
[2014 - **[GoogleNet]** Going Deeper with Convolutions](https://arxiv.org/abs/1409.4842) ✅
We propose a deep convolutional neural network architecture codenamed "Inception", which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). The main hallmark of this architecture is the improved utilization of the computing resources inside the network. This was achieved by a carefully crafted design that allows for increasing the depth and width of the network while keeping the computational budget constant. To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing. One particular incarnation used in our submission for ILSVRC 2014 is called GoogLeNet, a 22 layers deep network, the quality of which is assessed in the context of classification and detection.
[2014 - Neural Turing Machines](https://arxiv.org/abs/1410.5401)
---
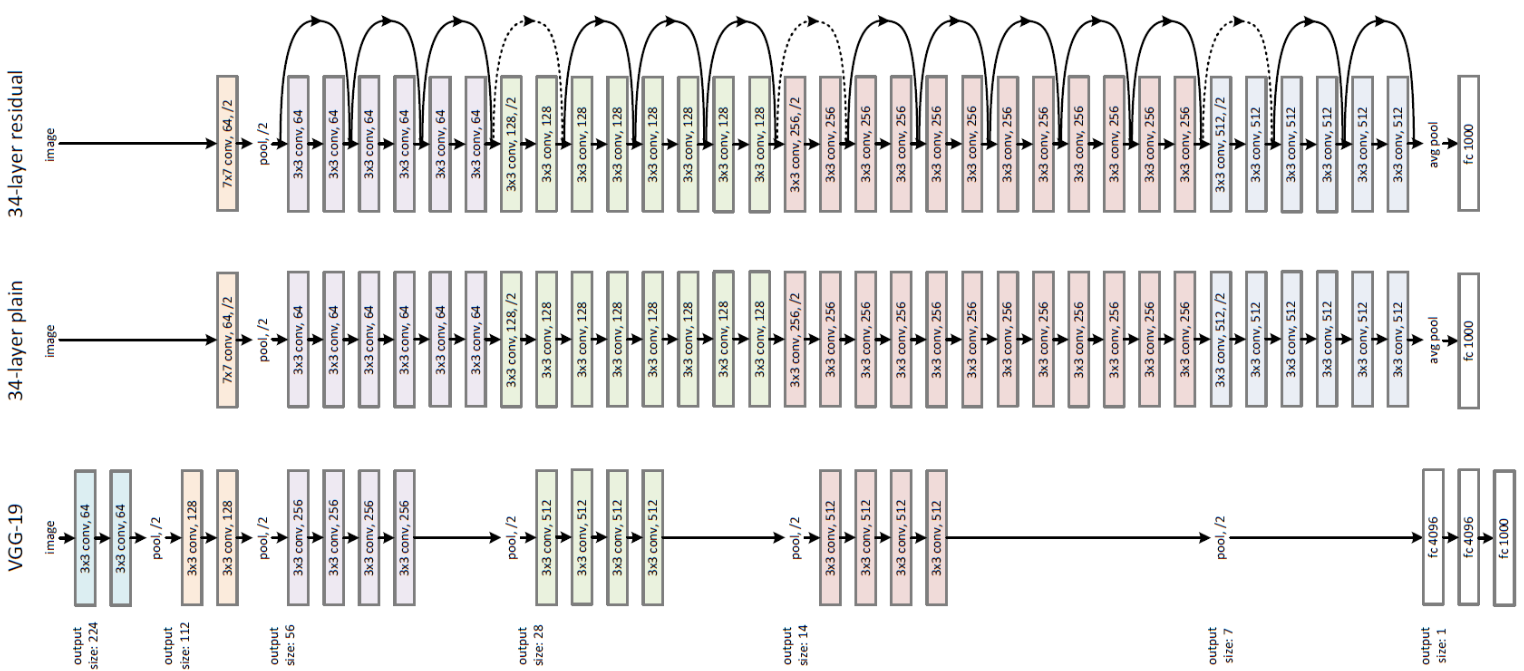
[2015 - **[ResNet]** Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) ✅
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
---
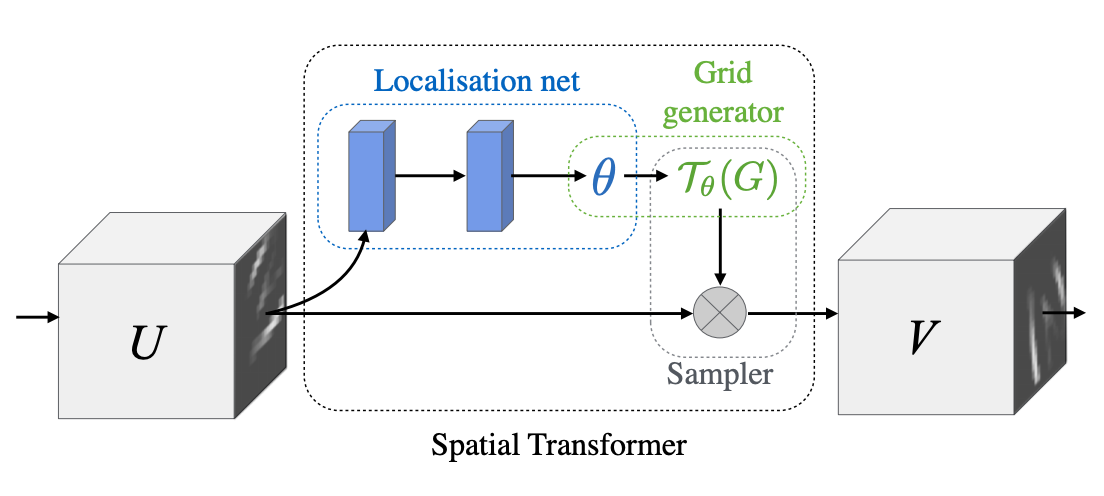
[2015 - Spatial Transformer Networks](https://arxiv.org/abs/1506.02025)
Convolutional Neural Networks define an exceptionally powerful class of models, but are still limited by the lack of ability to be spatially invariant to the input data in a computationally and parameter efficient manner. In this work we introduce a new learnable module, the Spatial Transformer, which explicitly allows the spatial manipulation of data within the network. This differentiable module can be inserted into existing convolutional architectures, giving neural networks the ability to actively spatially transform feature maps, conditional on the feature map itself, without any extra training supervision or modification to the optimisation process. We show that the use of spatial transformers results in models which learn invariance to translation, scale, rotation and more generic warping, resulting in state-of-the-art performance on several benchmarks, and for a number of classes of transformations.
---
[2016 - **[WRN]**: Wide Residual Networks](https://arxiv.org/abs/1605.07146) [[github]](https://github.com/szagoruyko/wide-residual-networks)
[2015 - **[FCN]** Fully Convolutional Networks for Semantic Segmentation](https://arxiv.org/abs/1411.4038)

[2015 - **[U-net]**: Convolutional networks for biomedical image segmentation](https://arxiv.org/abs/1505.04597) ✅
[2016 - **[Xception]**: Deep Learning with Depthwise Separable Convolutions](https://arxiv.org/abs/1610.02357)
[Implementation](https://colab.research.google.com/drive/1BT_t64JCzr8ge51orG8uLBLIL7w1Hos4)
[2016 - **[V-Net]**: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation](https://arxiv.org/abs/1606.04797)
[2017 - **[MobileNets]**: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861)
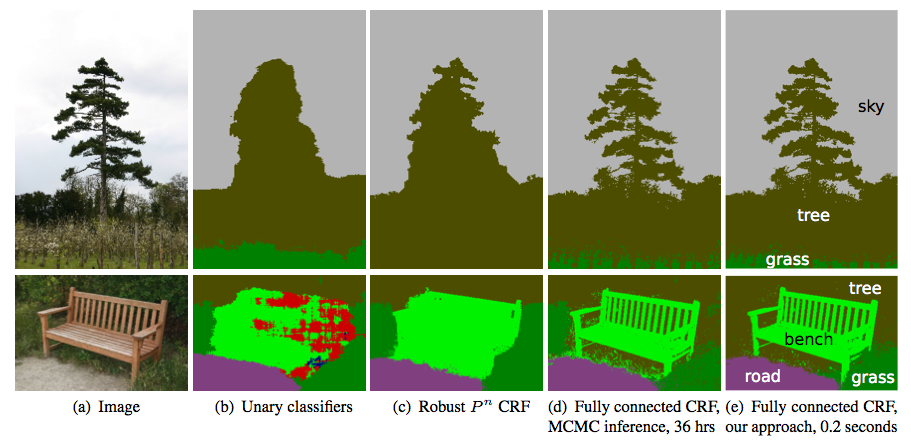
[Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials](https://arxiv.org/abs/1210.5644)
[2018 - **[TernausNet]**: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation](https://arxiv.org/abs/1801.05746) ✅
---
[2018 - CubeNet: Equivariance to 3D Rotation and Translation](http://openaccess.thecvf.com/content_ECCV_2018/papers/Daniel_Worrall_CubeNet_Equivariance_to_ECCV_2018_paper.pdf)[[github]](https://github.com/deworrall92/cubenet), [*[video]*](https://www.youtube.com/watch?v=TlzRyHbWeP0&feature=youtu.be) ⭕

---
[2018 - Deep Rotation Equivariant Network](https://arxiv.org/abs/1705.08623)[[github]](https://github.com/ZJULearning/DREN/raw/master/img/rotate_equivariant.png) ⭕

---
[2018 - ArcFace: Additive Angular Margin Loss for Deep Face Recognition](https://arxiv.org/abs/1801.07698)

---
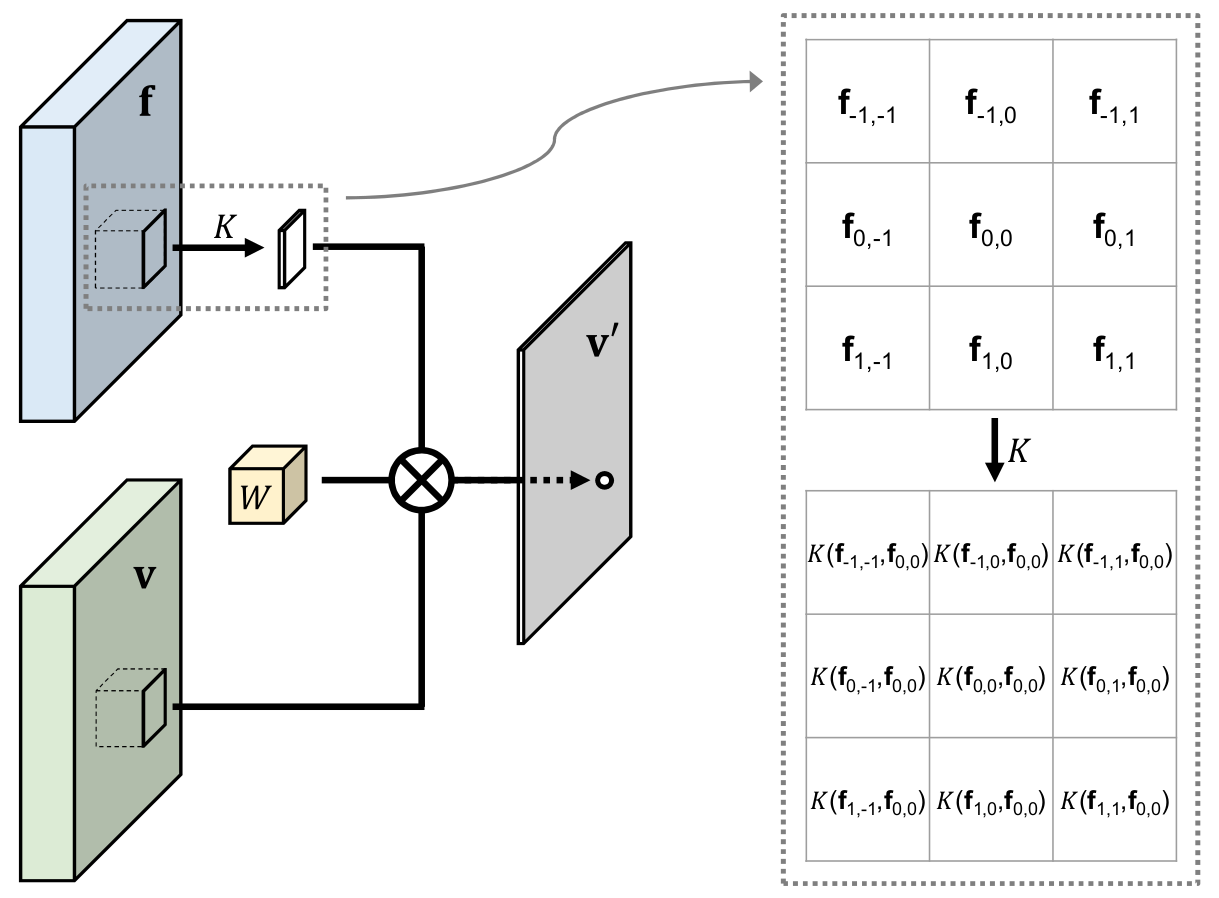
[2019 - **[PacNet]**: Pixel-Adaptive Convolutional Neural Networks](https://arxiv.org/abs/1904.05373)
---
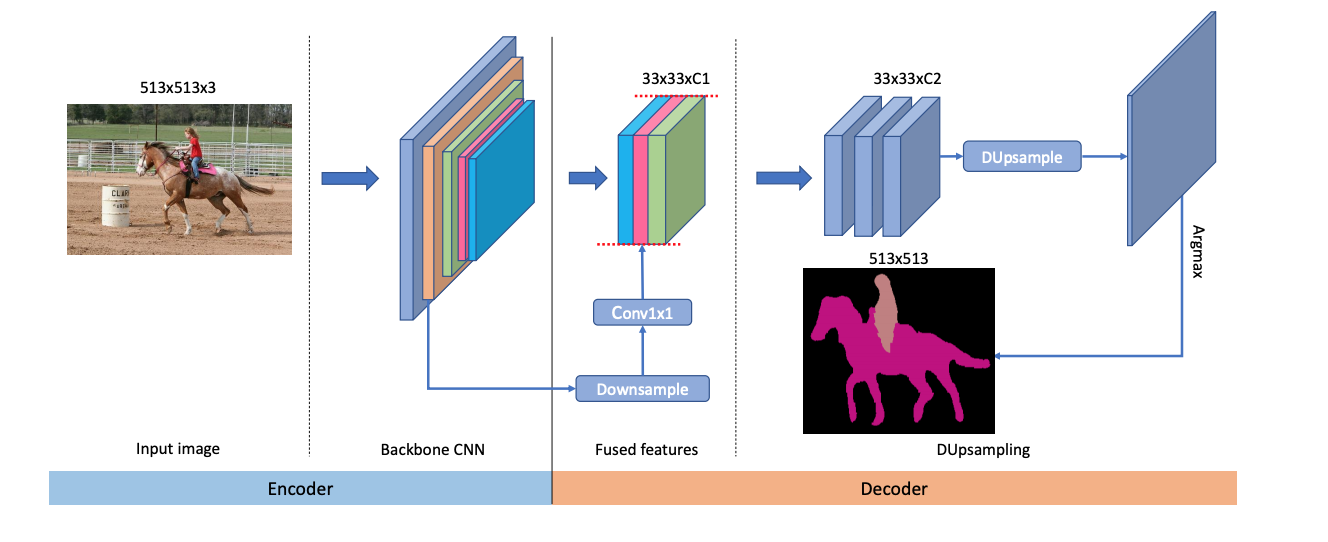
[2019 - Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation](https://arxiv.org/abs/1903.02120v3) [[github]](https://github.com/LinZhuoChen/DUpsampling) ⭕
[2019 - Panoptic Feature Pyramid Networks](http://openaccess.thecvf.com/content_CVPR_2019/html/Kirillov_Panoptic_Feature_Pyramid_Networks_CVPR_2019_paper.html) ⭕
---
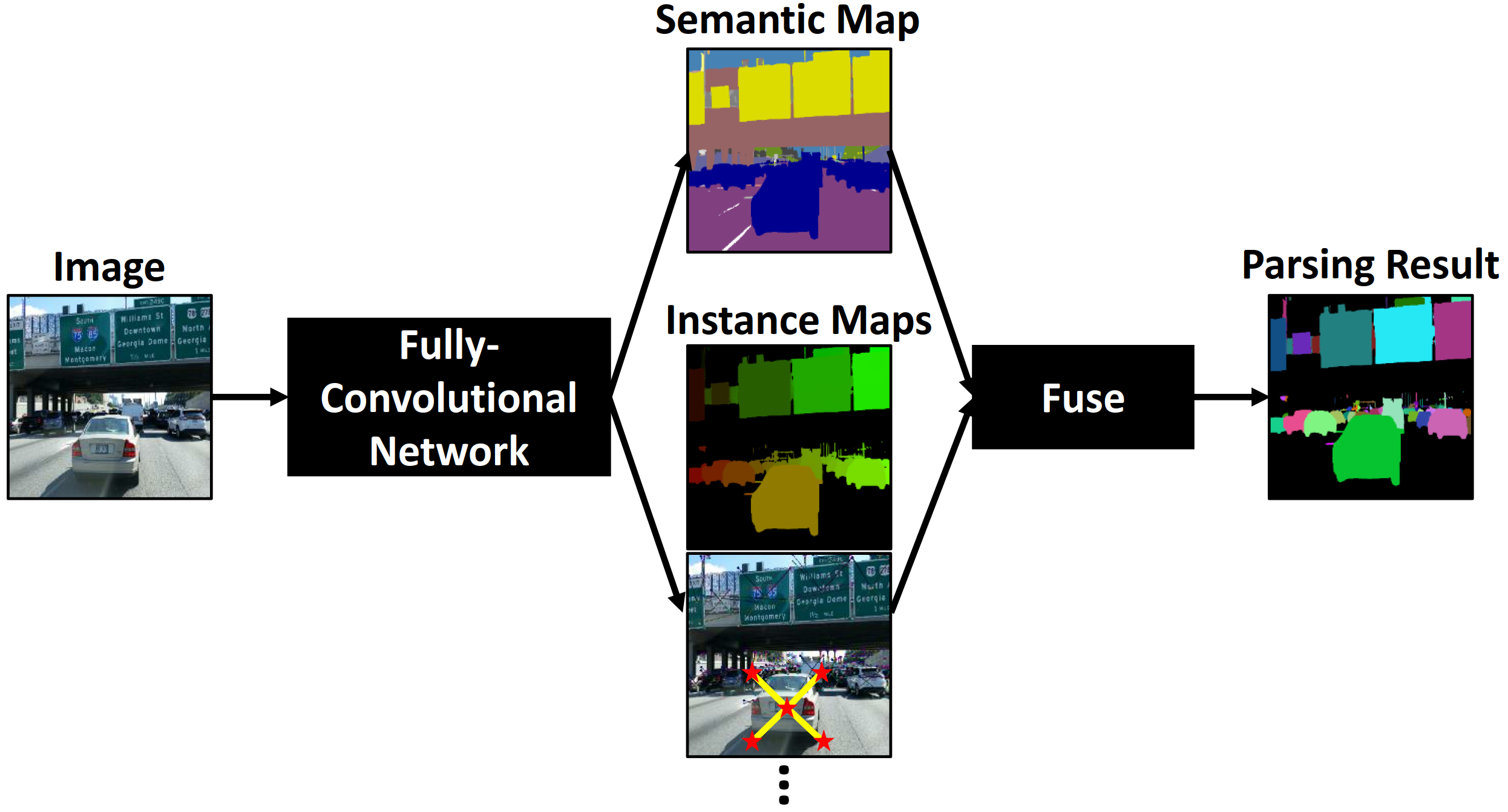
[2019 - **[DeeperLab]**: Single-Shot Image Parser](https://arxiv.org/abs/1902.05093) ⭕
---
[2019 - **[EfficientNet]**: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) ⭕
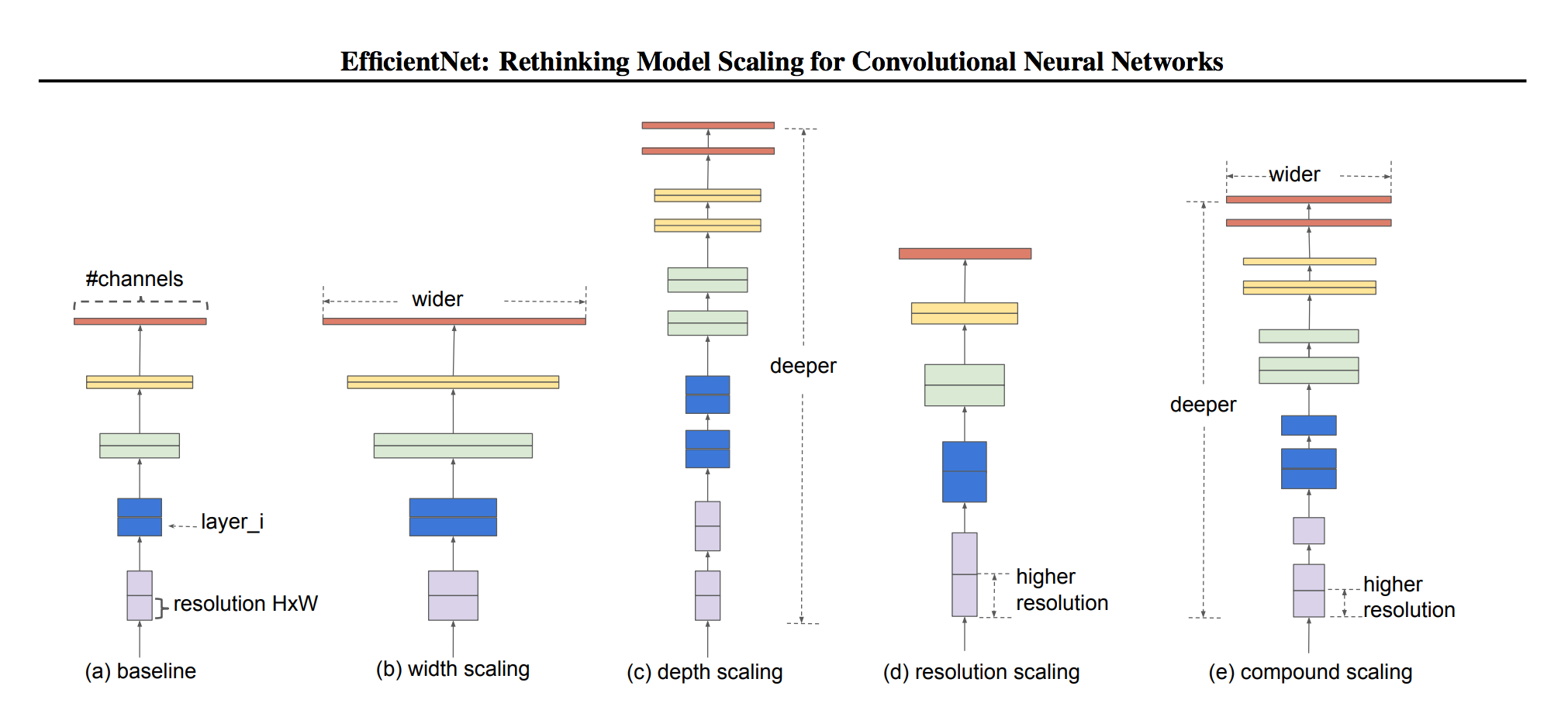
---
[2019 - Hamiltonian Neural Networks](https://arxiv.org/abs/1906.01563)
Even though neural networks enjoy widespread use, they still struggle to learn the basic laws of physics. How might we endow them with better inductive biases? In this paper, we draw inspiration from Hamiltonian mechanics to train models that learn and respect exact conservation laws in an unsupervised manner. We evaluate our models on problems where conservation of energy is important, including the two-body problem and pixel observations of a pendulum. Our model trains faster and generalizes better than a regular neural network. An interesting side effect is that our model is perfectly reversible in time.
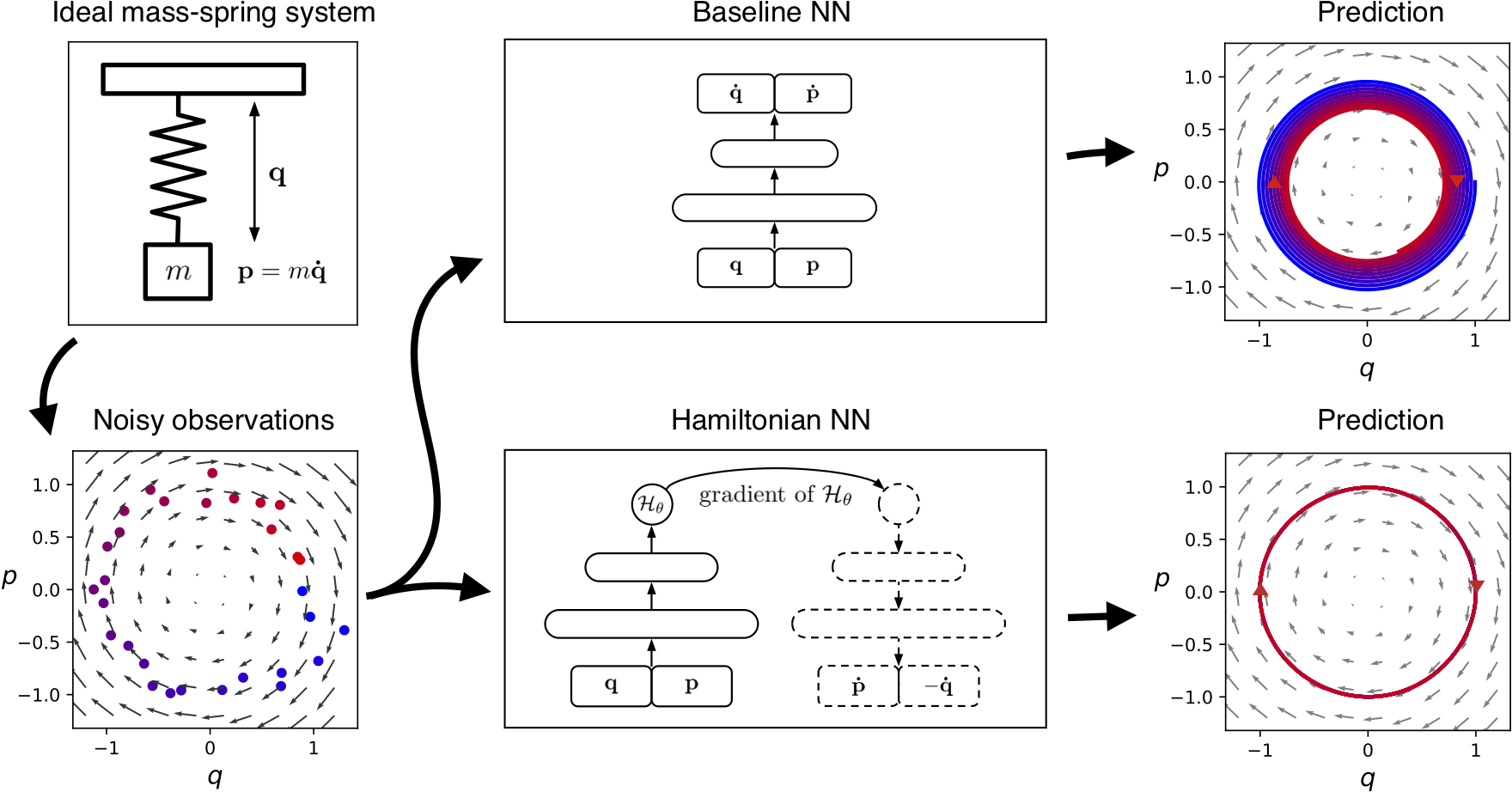 ^
^
---
[2020 - Roto-Translation Equivariant Convolutional Networks: Application to Histopathology Image Analysis](https://arxiv.org/abs/2002.08725)

---
[2020 - Neural Operator: Graph Kernel Network for Partial Differential Equations](https://arxiv.org/abs/2003.03485)

---
[2021 - Learning Neural Network Subspaces](https://arxiv.org/abs/2102.10472)

Recent observations have advanced our understanding of the neural network optimization landscape, revealing the existence of (1) paths of high accuracy containing diverse solutions and (2) wider minima offering improved performance. Previous methods observing diverse paths require multiple training runs. In contrast we aim to leverage both property (1) and (2) with a single method and in a single training run. With a similar computational cost as training one model, we learn lines, curves, and simplexes of high-accuracy neural networks. These neural network subspaces contain diverse solutions that can be ensembled, approaching the ensemble performance of independently trained networks without the training cost. Moreover, using the subspace midpoint boosts accuracy, calibration, and robustness to label noise, outperforming Stochastic Weight Averaging.
### Multi-level
---
[2014 - **[SPP-Net]** Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition](https://arxiv.org/abs/1406.4729)

---
[2016 - **[ParseNet]**: Looking Wider to See Better](https://arxiv.org/abs/1506.04579)
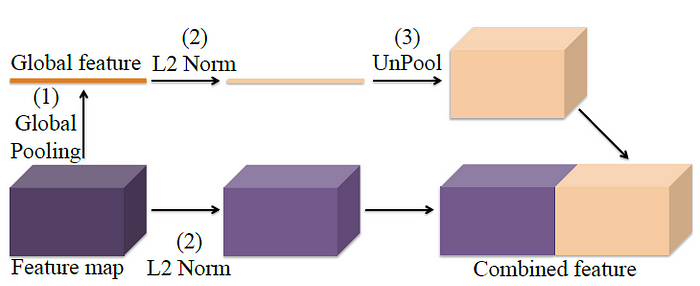
---
[2016 - **[PSPNet]**: Pyramid Scene Parsing Network](https://arxiv.org/abs/1612.01105v2) [[github]](https://github.com/hszhao/PSPNet) ✅
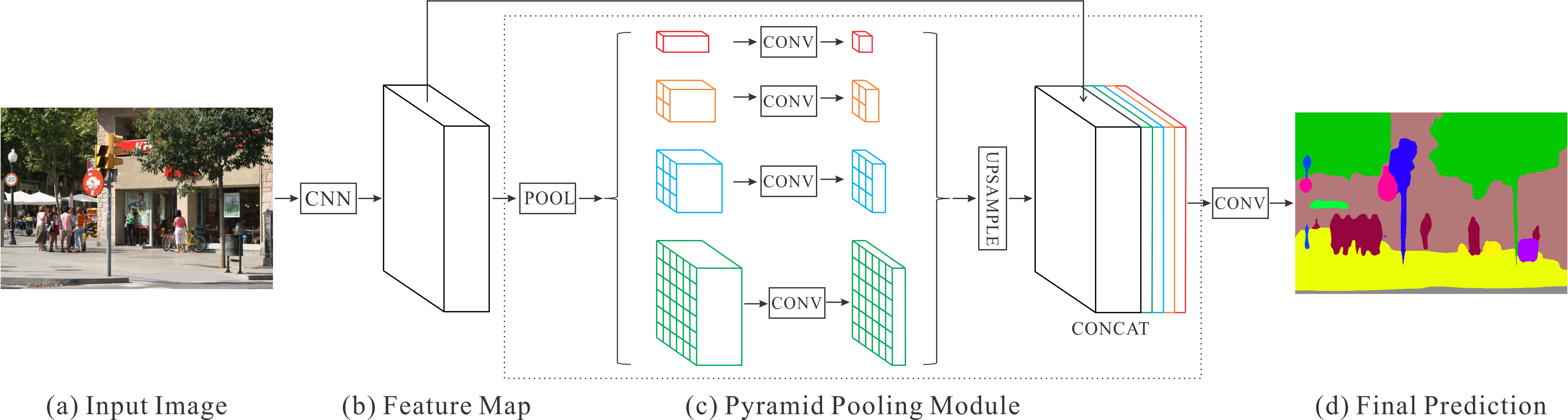
---
[2016 - **[DeepLab]**: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs](https://arxiv.org/pdf/1606.00915.pdf) ✅
---
[2015 - Zoom Better to See Clearer: Human and Object Parsing with Hierarchical Auto-Zoom Net](https://arxiv.org/abs/1511.06881)
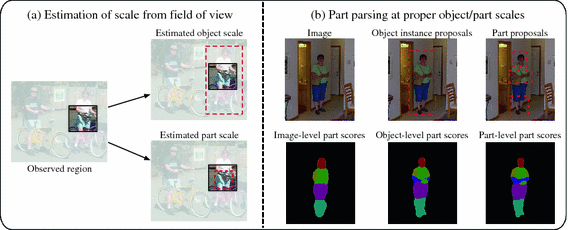
---
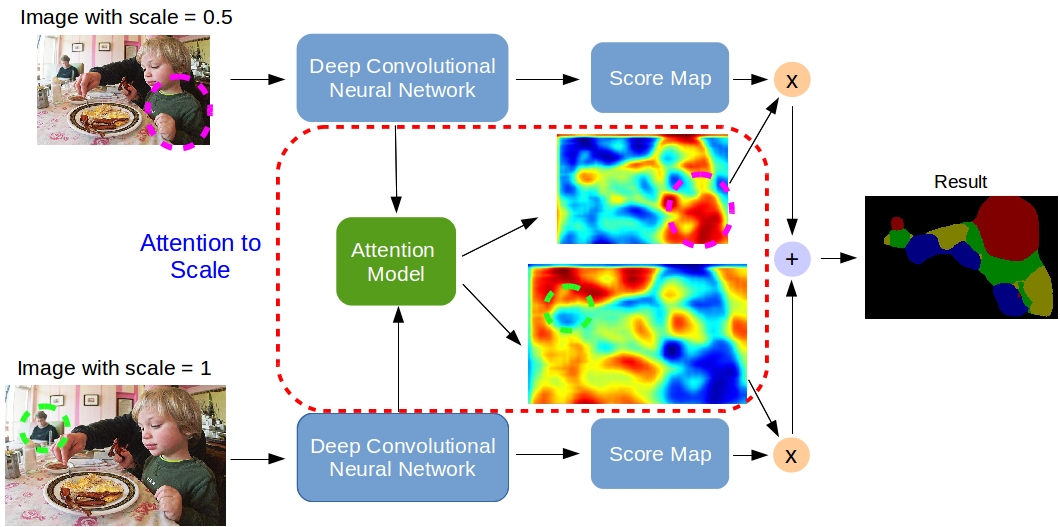
[2016 - Attention to Scale: Scale-aware Semantic Image Segmentation](https://arxiv.org/abs/1511.03339)
[2017 - Rethinking Atrous Convolution for Semantic Image Segmentation](https://arxiv.org/pdf/1706.05587.pdf)
---
[2017 - Feature Pyramid Networks for Object Detection](https://arxiv.org/abs/1612.03144)
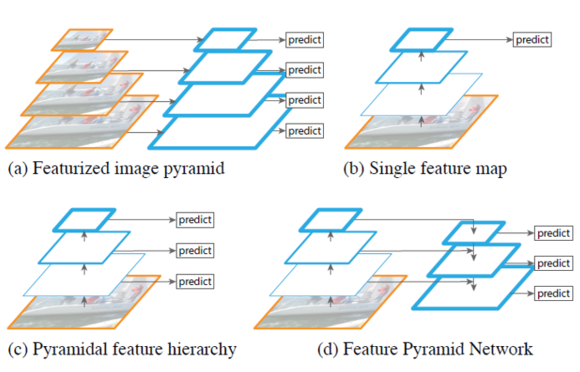
---
[2018 - **[DeepLabv3]**: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation](https://arxiv.org/abs/1802.02611)
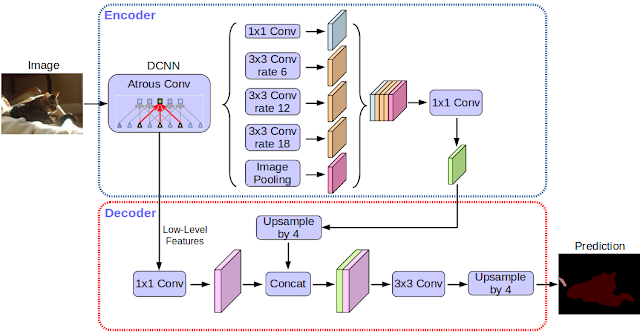
---
[2019 - **[FastFCN]**: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation](https://arxiv.org/abs/1903.11816v1) [[github]](https://github.com/wuhuikai/FastFCN) ✅

---
[2019 - Making Convolutional Networks Shift-Invariant Again](https://arxiv.org/abs/1904.11486)

---
[2019 - **[LEDNet]**: A Lightweight Encoder-Decoder Network for Real-Time Semantic Segmentation](https://arxiv.org/abs/1905.02423v1)

---
[2019 - Feature Pyramid Encoding Network for Real-time Semantic Segmentation](https://arxiv.org/abs/1909.08599v1)

---
[2019 - Efficient Segmentation: Learning Downsampling Near Semantic Boundaries](https://arxiv.org/abs/1907.07156)

---
[2019 - PointRend: Image Segmentation as Rendering](https://arxiv.org/abs/1912.08193)

---
[2019 - Fixing the train-test resolution discrepancy](https://arxiv.org/abs/1906.06423) ✅

> This paper first shows that existing augmentations induce a significant discrepancy between the typical size of the objects seen by the classifier at train and test time.
> We experimentally validate that, for a target test resolu- tion, using a lower train resolution offers better classification at test time.
### Context and Attention
---
[2016 - Image Captioning with Semantic Attention](https://arxiv.org/abs/1603.03925)
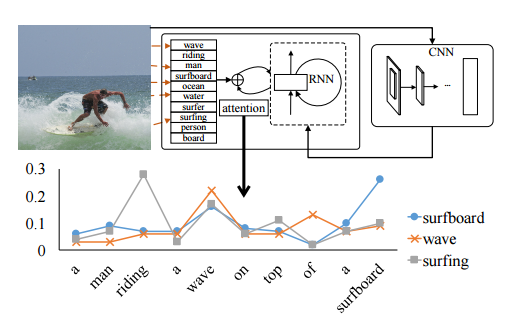
---
[2018 - **[EncNet]** Context Encoding for Semantic Segmentation](https://arxiv.org/abs/1803.08904v1) [[github]](https://github.com/zhanghang1989/PyTorch-Encoding) ⭕

---
[2018 - Tell Me Where to Look: Guided Attention Inference Network](https://arxiv.org/abs/1802.10171)

### Composition
[2005 - Image Parsing: Unifying Segmentation, Detection, and Recognition](https://link.springer.com/article/10.1007/s11263-005-6642-x) ⭕
[2013 - Complexity of Representation and Inference in Compositional Models with Part Sharing](https://arxiv.org/abs/1301.3560)
---
[2017 - Interpretable Convolutional Neural Networks](https://arxiv.org/abs/1710.00935) ⭕
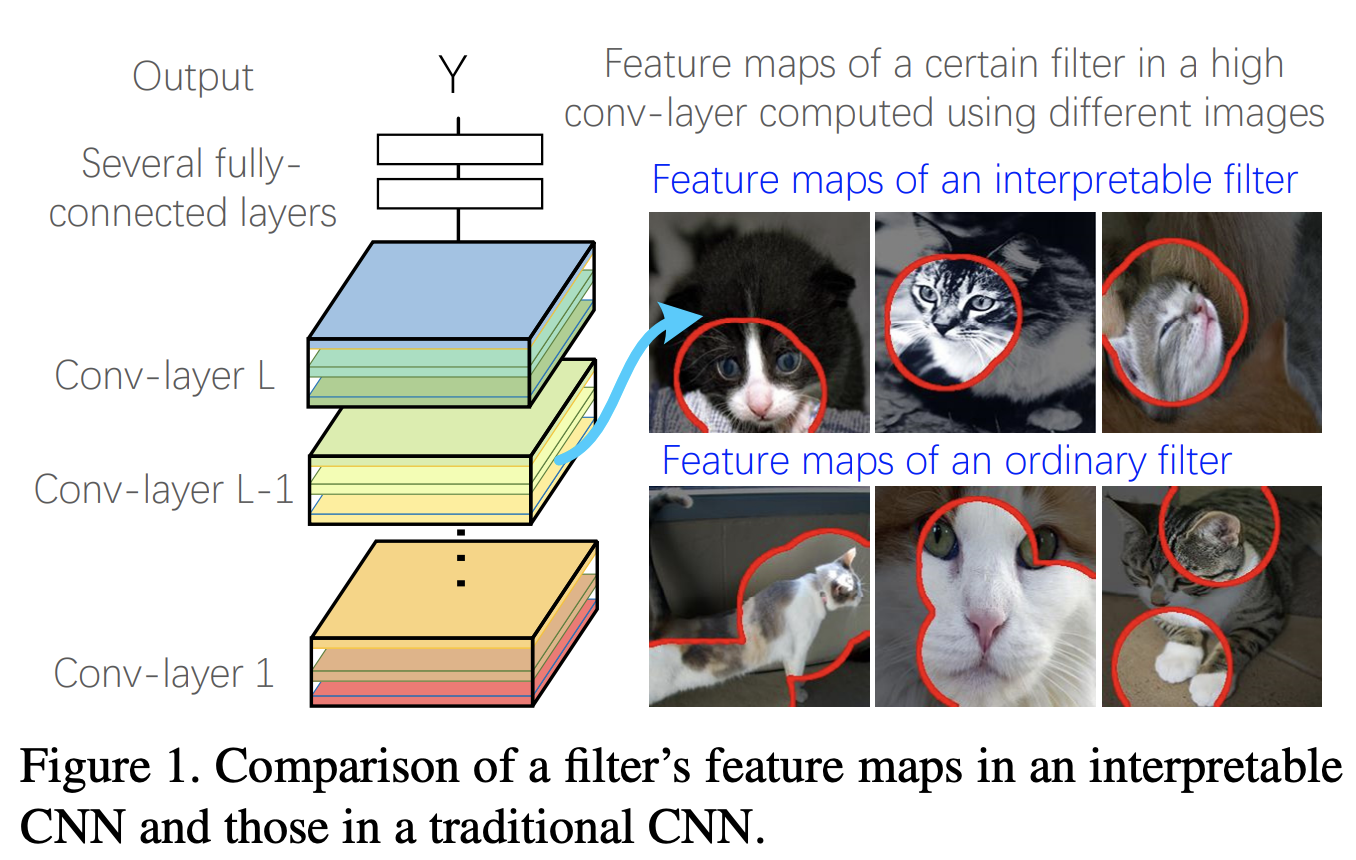
---
[2019 - Local Relation Networks for Image Recognition ](https://arxiv.org/pdf/1904.11491.pdf)

---
[2017 - Teaching Compositionality to CNNs](https://www.semanticscholar.org/paper/Teaching-Compositionality-to-CNNs-Stone-Wang/3726b82007512a15a530fd1adad57af58a9abb62) ⭕

---
[2020 - Concept Bottleneck Models](https://arxiv.org/abs/2007.04612) ⭕

### Capsule Networks
---
[2017 - Dynamic Routing Between Capsules](https://arxiv.org/abs/1710.09829) ⭕

### Transformers
[2020 - **SURVEY**: A Survey on Visual Transformer](https://arxiv.org/abs/2012.12556) 📜
[2021 - **SURVEY**: Transformers in Vision: A Survey](https://arxiv.org/abs/2101.01169) 📜
[2023 - **SURVEY**: A Comprehensive Survey on Applications of Transformers for Deep Learning Tasks](https://paperswithcode.com/paper/a-comprehensive-survey-on-applications-of) 📜
### 3D Shape
---
[2020 - **[NeRF]**: Representing Scenes as Neural Radiance Fields for View Synthesis ](https://arxiv.org/abs/2003.08934) ⭕
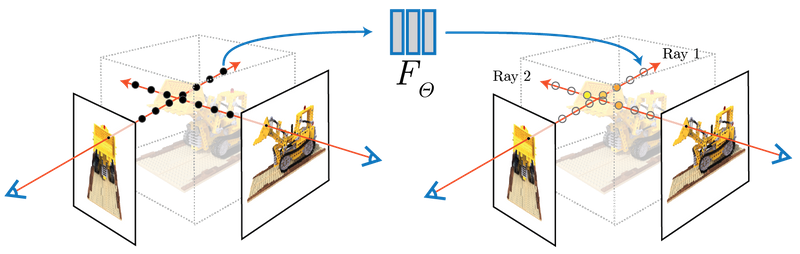
We present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views. Our algorithm represents a scene using a fully-connected (non-convolutional) deep network, whose input is a single continuous 5D coordinate (spatial location (x,y,z) and viewing direction (θ,ϕ)) and whose output is the volume density and view-dependent emitted radiance at that spatial location. We synthesize views by querying 5D coordinates along camera rays and use classic volume rendering techniques to project the output colors and densities into an image. Because volume rendering is naturally differentiable, the only input required to optimize our representation is a set of images with known camera poses. We describe how to effectively optimize neural radiance fields to render photorealistic novel views of scenes with complicated geometry and appearance, and demonstrate results that outperform prior work on neural rendering and view synthesis. View synthesis results are best viewed as videos, so we urge readers to view our supplementary video for convincing comparisons.
---
[2020 - [BLOG] NeRF Explosion 2020](https://dellaert.github.io/NeRF/)
---
[2020 - **[SURVEY]** State of the Art on Neural Rendering](https://arxiv.org/abs/2004.03805) 📜

---
[2020 - AutoInt: Automatic Integration for Fast Neural Volume Rendering](https://arxiv.org/abs/2012.01714?s=09)


Numerical integration is a foundational technique in scientific computing and is at the core of many computer vision applications. Among these applications, implicit neural volume rendering has recently been proposed as a new paradigm for view synthesis, achieving photorealistic image quality. However, a fundamental obstacle to making these methods practical is the extreme computational and memory requirements caused by the required volume integrations along the rendered rays during training and inference. Millions of rays, each requiring hundreds of forward passes through a neural network are needed to approximate those integrations with Monte Carlo sampling. Here, we propose automatic integration, a new framework for learning efficient, closed-form solutions to integrals using implicit neural representation networks. For training, we instantiate the computational graph corresponding to the derivative of the implicit neural representation. The graph is fitted to the signal to integrate. After optimization, we reassemble the graph to obtain a network that represents the antiderivative. By the fundamental theorem of calculus, this enables the calculation of any definite integral in two evaluations of the network. Using this approach, we demonstrate a greater than 10x improvement in computation requirements, enabling fast neural volume rendering.
---
[2020 - A Curvature and Density‐based Generative Representation of Shapes](https://onlinelibrary.wiley.com/doi/full/10.1111/cgf.14094)

This paper introduces a generative model for 3D surfaces based on a representation of shapes with mean curvature and metric, which are invariant under rigid transformation. Hence, compared with existing 3D machine learning frameworks, our model substantially reduces the influence of translation and rotation. In addition, the local structure of shapes will be more precisely captured, since the curvature is explicitly encoded in our model. Specifically, every surface is first conformally mapped to a canonical domain, such as a unit disk or a unit sphere. Then, it is represented by two functions: the mean curvature half‐density and the vertex density, over this canonical domain. Assuming that input shapes follow a certain distribution in a latent space, we use the variational autoencoder to learn the latent space representation. After the learning, we can generate variations of shapes by randomly sampling the distribution in the latent space. Surfaces with triangular meshes can be reconstructed from the generated data by applying isotropic remeshing and spin transformation, which is given by Dirac equation. We demonstrate the effectiveness of our model on datasets of man‐made and biological shapes and compare the results with other methods.
---
[2021 - Neural Parts: Learning Expressive 3D Shape Abstractions with Invertible Neural Networks](https://paschalidoud.github.io/neural_parts)
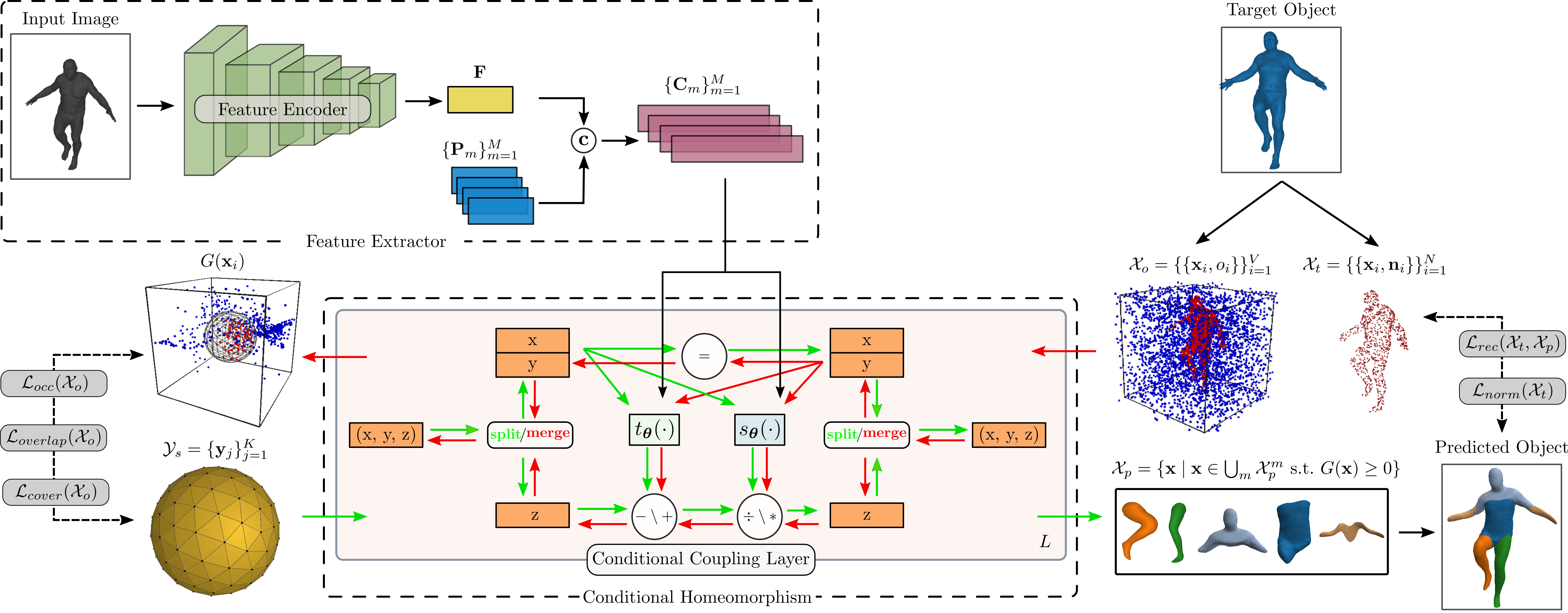
### Logic and Semantics
[2019 - Neural Logic Machines](https://arxiv.org/abs/1904.11694)
We propose the Neural Logic Machine (NLM), a neural-symbolic architecture for both inductive learning and logic reasoning. NLMs exploit the power of both neural networks---as function approximators, and logic programming---as a symbolic processor for objects with properties, relations, logic connectives, and quantifiers. After being trained on small-scale tasks (such as sorting short arrays), NLMs can recover lifted rules, and generalize to large-scale tasks (such as sorting longer arrays). In our experiments, NLMs achieve perfect generalization in a number of tasks, from relational reasoning tasks on the family tree and general graphs, to decision making tasks including sorting arrays, finding shortest paths, and playing the blocks world. Most of these tasks are hard to accomplish for neural networks or inductive logic programming alone.

## Optimization and Regularisation
[Random search for hyper-parameter optimisation](http://www.jmlr.org/papers/v13/bergstra12a.html)
[Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift](https://arxiv.org/pdf/1502.03167.pdf)
[**[Adam]**: A Method for Stochastic Optimization](https://arxiv.org/abs/1412.6980)
[**[Dropout]**: A Simple Way to Prevent Neural Networks from Overfitting](http://jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf)
[Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks](https://arxiv.org/abs/1406.6909) ✅
Multi-Scale Context Aggregation by Dilated Convolutions
https://arxiv.org/abs/1511.07122

---
[2017 - The Marginal Value of Adaptive Gradient Methods in Machine Learning](https://papers.nips.cc/paper/7003-the-marginal-value-of-adaptive-gradient-methods-in-machine-learning)
> (i) Adaptive methods find solutions that generalize worse than those found by non-adaptive methods.
> (ii) Even when the adaptive methods achieve
the same training loss or lower than non-adaptive methods, the development or test performance
is worse.
> (iii) Adaptive methods often display faster initial progress on the training set, but their
performance quickly plateaus on the development set.
> (iv) Though conventional wisdom suggests
that Adam does not require tuning, we find that tuning the initial learning rate and decay scheme for
Adam yields significant improvements over its default settings in all cases.
DARTS: Differentiable Architecture Search
https://arxiv.org/abs/1806.09055
[**Bag of Tricks** for Image Classification with Convolutional Neural Networks](htps://arxiv.org/abs/1812.01187v1) ✅
[2018 - **Tune**: A Research Platform for Distributed Model Selection and Training](https://arxiv.org/abs/1807.05118) [[github]](https://github.com/ray-project/ray/tree/master/python/ray/tune)
[2017 - Equilibrium Propagation: Bridging the Gap Between Energy-Based Models and Backpropagation](https://arxiv.org/abs/1602.05179)
[2017 - Understanding deep learning requires rethinking generalization](https://arxiv.org/abs/1611.03530) ⭕
[2018 - Error Forward-Propagation: Reusing Feedforward Connections to Propagate Errors in Deep Learning](https://arxiv.org/abs/1808.03357)
[2018 - An Empirical Model of Large-Batch Training](https://arxiv.org/abs/1812.06162v1)

[2018 - A disciplined approach to neural network hyper-parameters: Part 1 -- learning rate, batch size, momentum, and weight decay](https://arxiv.org/abs/1803.09820) ⭕
[2019 - Training Neural Networks with Local Error Signals](https://arxiv.org/abs/1901.06656) [[github]](https://github.com/anokland/local-loss) ⭕
[2019 - Switchable Normalization for Learning-to-Normalize Deep Representation](https://arxiv.org/abs/1907.10473)

[2019 - Revisiting Small Batch Training for Deep Neural Networks](https://arxiv.org/abs/1804.07612)
[2019 - Cyclical Learning Rates for Training Neural Networks](https://arxiv.org/abs/1506.01186)
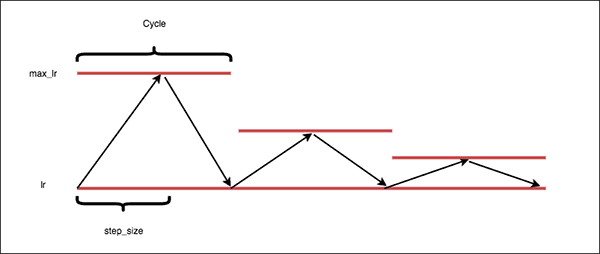
[2019 - DeepOBS: A Deep Learning Optimizer Benchmark Suite](https://arxiv.org/abs/1903.05499)

[2019 - A Recipe for Training Neural Networks. Andrey Karpathi Blog](http://karpathy.github.io/2019/04/25/recipe/)
[2020 - Fantastic Generalization Measures and Where to Find Them](https://arxiv.org/abs/1912.02178) ✅
> The most direct and principled approach for studying
generalization in deep learning is to prove a **generalization bound** which is typically an upper
bound on the test error based on some quantity that can be calculated on the training set.
> **Kendall’s Rank-Correlation Coefficient**: Given a set of models
resulted by training with hyperparameters in the set Θ, their associated generalization gap {g(θ)| θ ∈
Θ}, and their respective values of the measure {µ(θ)| θ ∈ Θ}, our goal is to analyze how consistent
a measure (e.g. L2 norm of network weights) is with the empirically observed generalization.
If complexity and generalization are independent, the coefficient becomes zero
> **VC-dimension** as well as the number of parameters are **negatively correlated** with
generalization gap which confirms the widely known empirical observation that overparametrization
improves generalization in deep learning.
> These results confirm the general understanding that larger margin, **lower cross-entropy** and higher entropy would
lead to **better generalization**
> we observed that the **initial phase** (to reach cross-entropy value of 0.1) of the optimization is **negatively
correlated** with the ??speed of optimization?? (error?) for both τ and Ψ. This would suggest that the **difficulty
of optimization** during the initial phase of the optimization **benefits the final generalization**.
> Towards the end of the training, the variance of the gradients also
captures a particular type of “flatness” of the local minima. This measure is surprisingly predictive
of the generalization both in terms of τ and Ψ, and more importantly, is positively correlated across
every type of hyperparameter.
> There are **mixed** results about how the **optimization speed** is relevant to generalization. On one hand
we know that adding Batch Normalization or using shortcuts in residual architectures help both
optimization and generalization.On the other hand, there are empirical results showing that adaptive
optimization methods that are faster, usually generalize worse (Wilson et al., 2017b).
> Based on empirical observations made by the community as a whole, the canonical ordering we give
to each of the hyper-parameter categories are as follows:
> 1. Batchsize: smaller batchsize leads to smaller generalization gap
> 2. Depth: deeper network leads to smaller generalization gap
> 3. Width: wider network leads to smaller generalization gap
> 4. Dropout: The higher the dropout (≤ 0.5) the smaller the generalization gap
> 5. Weight decay: The higher the weight decay (smaller than the maximum for each optimizer)
the smaller the generalization gap
> 6. Learning rate: The higher the learning rate (smaller than the maximum for each optimizer)
the smaller the generalization gap
> 7. Optimizer: Generalization gap of Momentum SGD < Generalization gap of Adam < Generalization gap of RMSProp
[2020 - Descending through a Crowded Valley -- Benchmarking Deep Learning Optimizers](https://arxiv.org/abs/2007.01547)

[2020 - Do Wide and Deep Networks Learn the Same Things? Uncovering How Neural Network Representations Vary with Width and Depth](https://arxiv.org/abs/2010.15327)

[2021 - Revisiting ResNets: Improved Training and Scaling Strategies](https://arxiv.org/abs/2103.07579)
Novel computer vision architectures monopolize the spotlight, but the impact of the model architecture is often conflated with simultaneous changes to training methodology and scaling strategies. Our work revisits the canonical ResNet (He et al., 2015) and studies these three aspects in an effort to disentangle them. Perhaps surprisingly, we find that training and scaling strategies may matter more than architectural changes, and further, that the resulting ResNets match recent state-of-the-art models. We show that the best performing scaling strategy depends on the training regime and offer two new scaling strategies: (1) scale model depth in regimes where overfitting can occur (width scaling is preferable otherwise); (2) increase image resolution more slowly than previously recommended (Tan & Le, 2019). Using improved training and scaling strategies, we design a family of ResNet architectures, ResNet-RS, which are 1.7x - 2.7x faster than EfficientNets on TPUs, while achieving similar accuracies on ImageNet. In a large-scale semi-supervised learning setup, ResNet-RS achieves 86.2% top-1 ImageNet accuracy, while being 4.7x faster than EfficientNet NoisyStudent. The training techniques improve transfer performance on a suite of downstream tasks (rivaling state-of-the-art self-supervised algorithms) and extend to video classification on Kinetics-400. We recommend practitioners use these simple revised ResNets as baselines for future research.
## Pruning and Compression
[2013 - Do Deep Nets Really Need to be Deep?](https://arxiv.org/abs/1312.6184)
[2015 - Learning both Weights and Connections for Efficient Neural Networks](https://arxiv.org/abs/1506.02626)
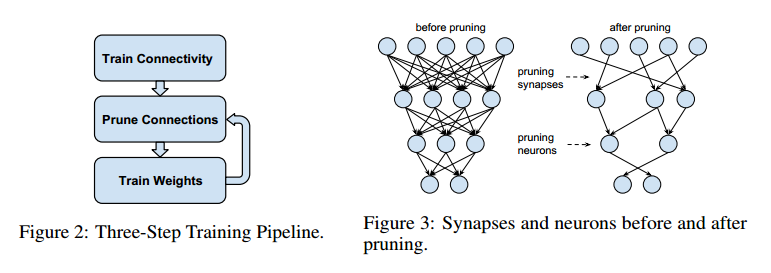
[2015 - Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding](https://arxiv.org/abs/1510.00149)

[2015 - Distilling the Knowledge in a Neural Network](https://arxiv.org/abs/1503.02531) ⭕
[2017 - Learning Efficient Convolutional Networks through Network Slimming](https://arxiv.org/abs/1708.06519) - [[github]](https://github.com/liuzhuang13/slimming) ⭕

[2018 - Rethinking the Value of Network Pruning](https://arxiv.org/abs/1810.05270) ✅

> For all state-of-the-art structured pruning algorithms we examined, fine-tuning a pruned model only gives
comparable or worse performance than training that model with randomly initialized weights. For pruning algorithms which assume a predefined target network architecture, one can get rid of the full pipeline and directly train the target network from scratch.
> Our observations are consistent for multiple network architectures, datasets, and tasks, which imply that:
> 1) training a large, over-parameterized model is often not necessary to obtain an efficient final model
> 2) learned “important” weights of the large model are typically not useful for the small pruned
model
> 3) the pruned architecture itself, rather than a set of inherited “important”
weights, is more crucial to the efficiency in the final model, which suggests that in
some cases pruning can be useful as an architecture search paradigm.
[2018 - Slimmable Neural Networks](https://arxiv.org/abs/1812.08928)
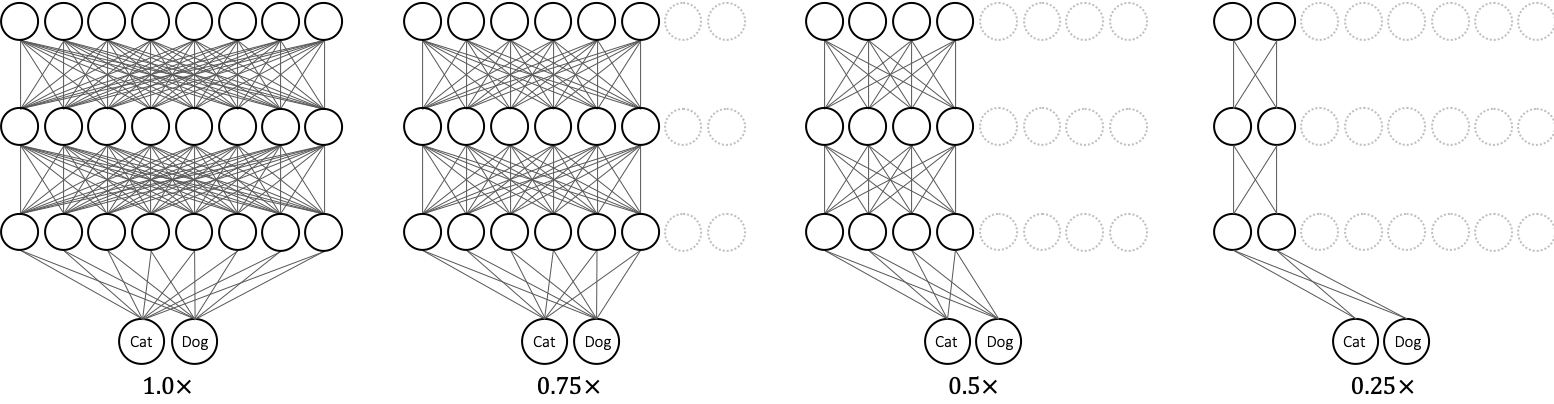
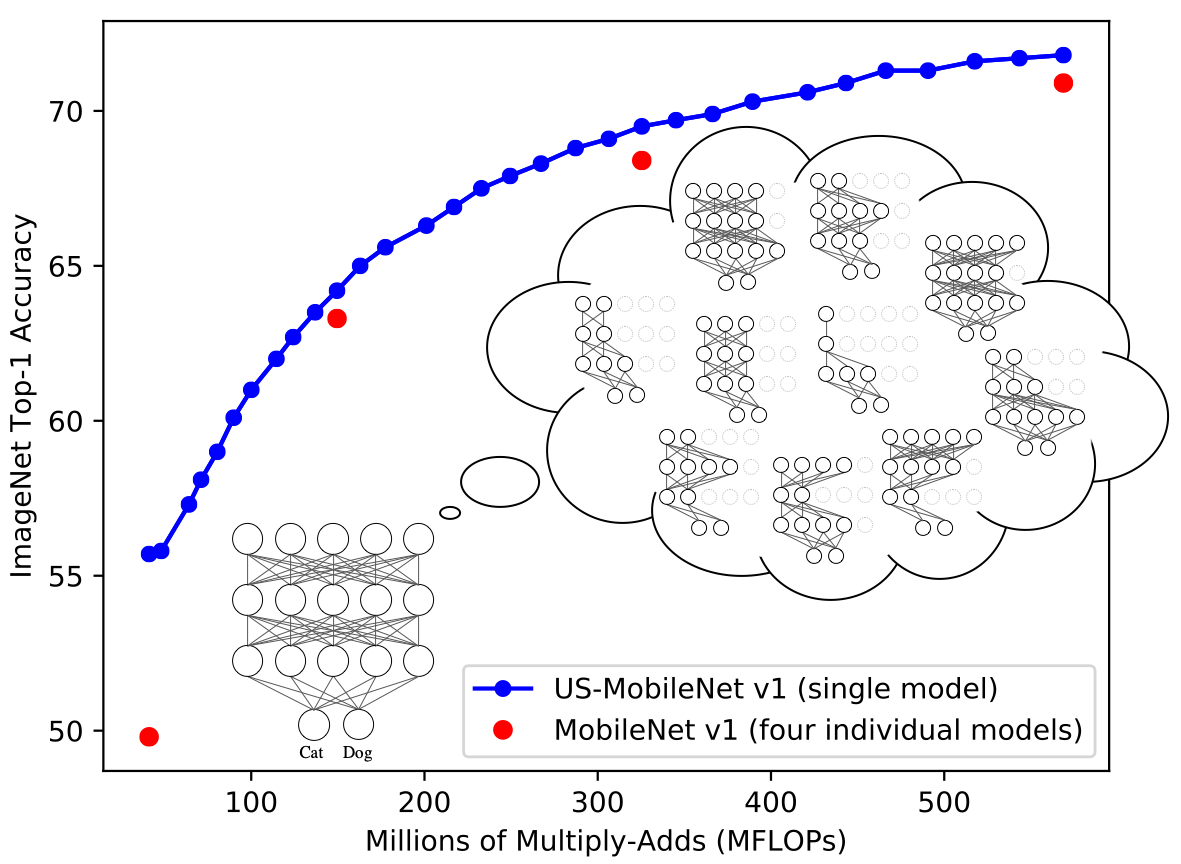
[2019 - Universally Slimmable Networks and Improved Training Techniques](https://arxiv.org/abs/1903.05134)
[2019 - The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks](https://arxiv.org/abs/1803.03635) ✅
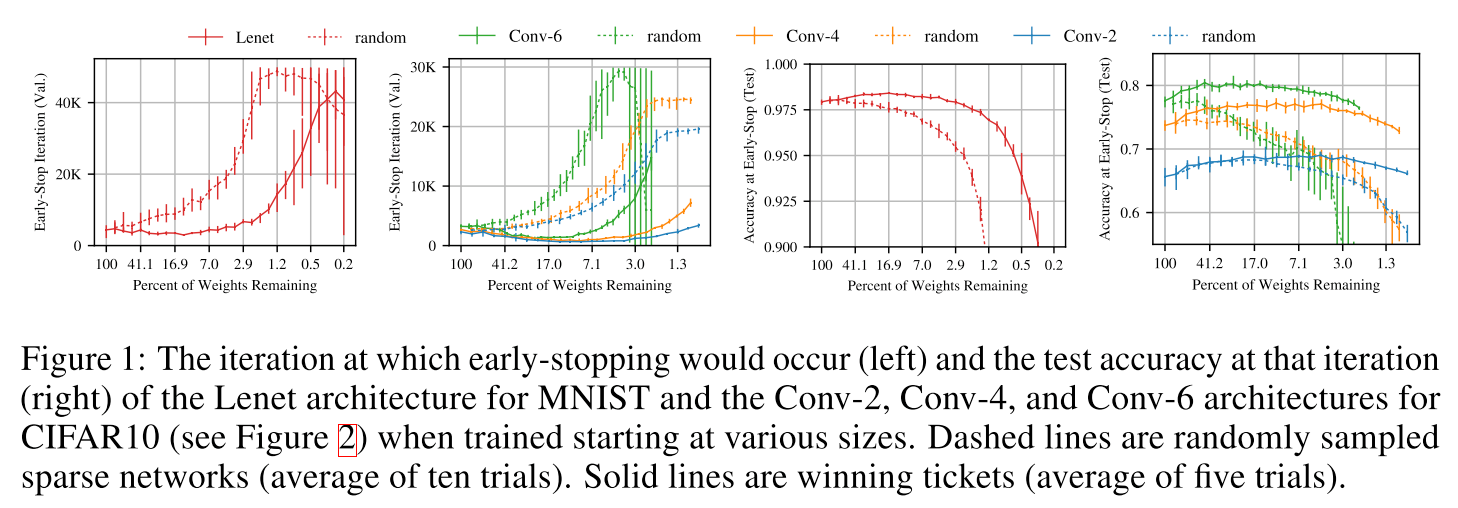
> Based on these results, we articulate the lottery ticket hypothesis: dense, randomly-initialized, feed-forward
networks contain subnetworks (winning tickets) that—when trained in isolation—
reach test accuracy comparable to the original network in a similar number of
iterations.
> The winning tickets we find have won the **initialization** lottery: their
connections have initial weights that make training particularly effective.
[2019 - AutoSlim: Towards One-Shot Architecture Search for Channel Numbers](https://arxiv.org/abs/1903.11728)

## Analysis and Interpretability
[2015 - Visualizing and Understanding Recurrent Networks](https://arxiv.org/abs/1506.02078)
[2016 - Discovering Causal Signals in Images](https://arxiv.org/abs/1605.08179)
[2016 - **[Grad-CAM]**: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization](https://arxiv.org/abs/1610.02391) [[github]](https://github.com/jacobgil/pytorch-grad-cam)

[2017 - Visualizing the Loss Landscape of Neural Nets](https://arxiv.org/abs/1712.09913)

[2019 - **[SURVEY]** Visual Analytics in Deep Learning: An Interrogative Survey for the Next Frontiers](https://ieeexplore.ieee.org/document/8371286) 📜
[2018 - GAN Dissection: Visualizing and Understanding Generative Adversarial Networks](https://arxiv.org/abs/1811.10597v1)

[2018 Interactive tool](https://gandissect.csail.mit.edu/)
[**[Netron ]** Visualizer for deep learning and machine learning models](https://github.com/lutzroeder/Netron)

[2019 - **[Distill]**: Computing Receptive Fields of Convolutional Neural Networks](https://distill.pub/2019/computing-receptive-fields/)
[2019 - On the Units of GANs](https://arxiv.org/abs/1901.09887)
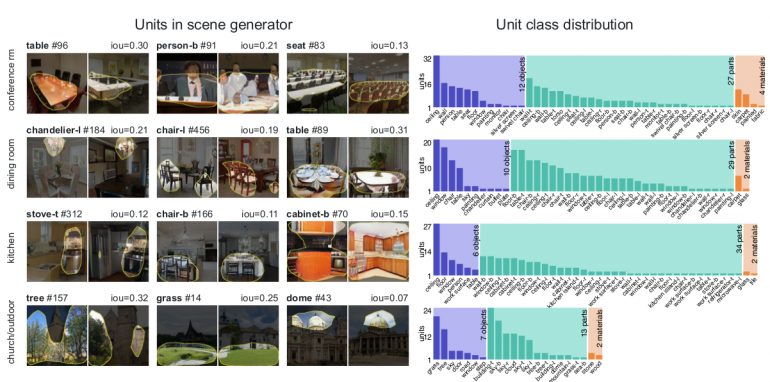
[2019 - Unmasking Clever Hans Predictors and Assessing What Machines Really Learn](https://arxiv.org/abs/1902.10178)

Current learning machines have successfully solved hard application problems, reaching high accuracy and displaying seemingly "intelligent" behavior. Here we apply recent techniques for explaining decisions of state-of-the-art learning machines and analyze various tasks from computer vision and arcade games. This showcases a spectrum of problem-solving behaviors ranging from naive and short-sighted, to well-informed and strategic. We observe that standard performance evaluation metrics can be oblivious to distinguishing these diverse problem solving behaviors. Furthermore, we propose our semi-automated Spectral Relevance Analysis that provides a practically effective way of characterizing and validating the behavior of nonlinear learning machines. This helps to assess whether a learned model indeed delivers reliably for the problem that it was conceived for. Furthermore, our work intends to add a voice of caution to the ongoing excitement about machine intelligence and pledges to evaluate and judge some of these recent successes in a more nuanced manner.
[2020 - Actionable Attribution Maps for Scientific Machine Learning](https://arxiv.org/abs/2006.16533)

[2020 - Shortcut Learning in Deep Neural Networks](https://arxiv.org/abs/2004.07780)

Deep learning has triggered the current rise of artificial intelligence and is the workhorse of today's machine intelligence. Numerous success stories have rapidly spread all over science, industry and society, but its limitations have only recently come into focus. In this perspective we seek to distil how many of deep learning's problem can be seen as different symptoms of the same underlying problem: shortcut learning. Shortcuts are decision rules that perform well on standard benchmarks but fail to transfer to more challenging testing conditions, such as real-world scenarios. Related issues are known in Comparative Psychology, Education and Linguistics, suggesting that shortcut learning may be a common characteristic of learning systems, biological and artificial alike. Based on these observations, we develop a set of recommendations for model interpretation and benchmarking, highlighting recent advances in machine learning to improve robustness and transferability from the lab to real-world applications.
---
[2021 - VIDEO: CVPR 2021 Workshop. Interpretable Neural Networks for Computer Vision: Clinical Decisions that are Aided, not Automated](https://www.youtube.com/watch?v=x7U5qC6eMnE)

---
[2021 - VIDEO. CVPR 2021 Workshop. Interpreting Deep Generative Models for Interactive AI Content Creation by Bolei Zhou (CUHK)](https://www.youtube.com/watch?v=PtRU2B6Iml4)

# Tasks
## Segmentation
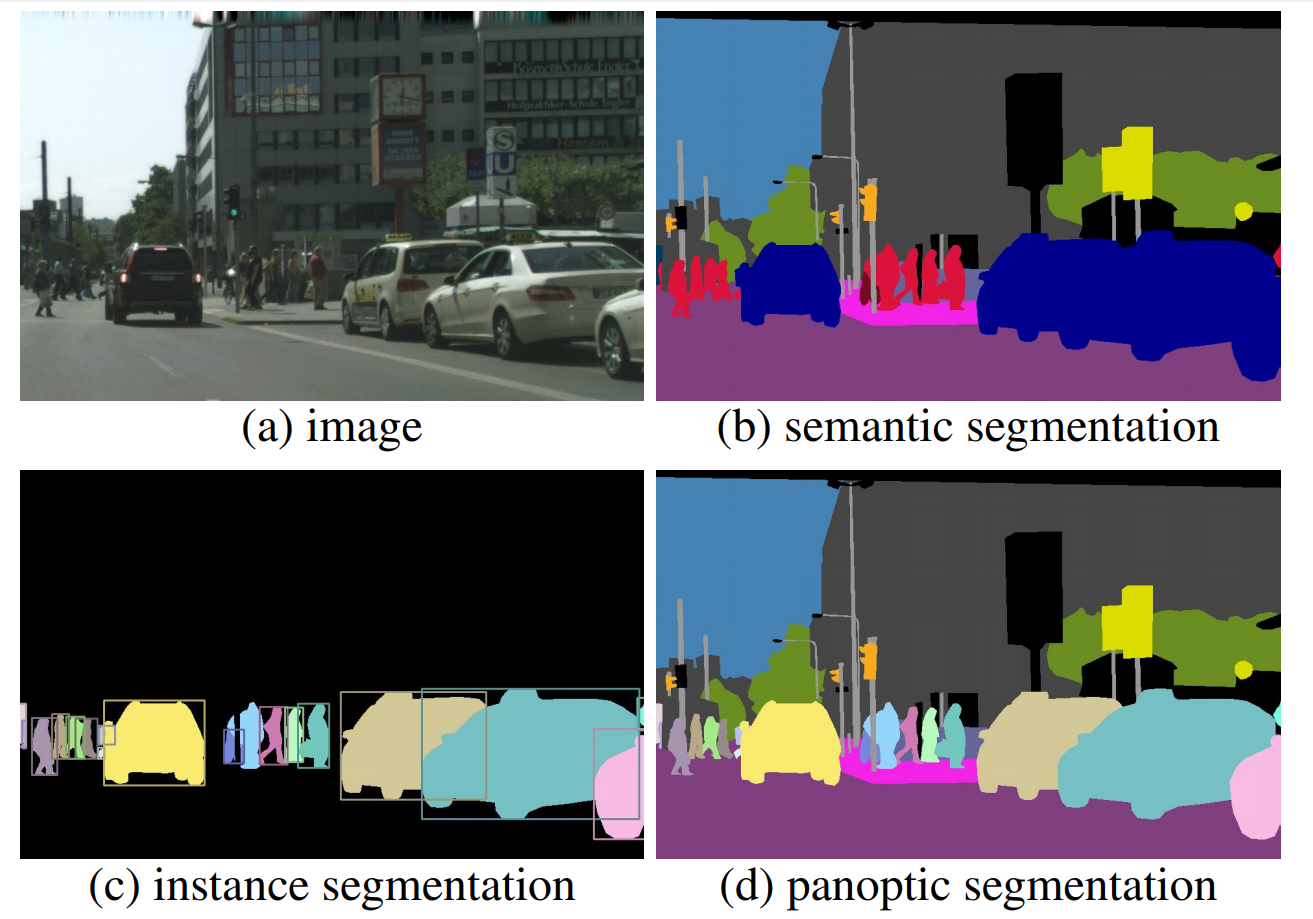
[2019 - Panoptic Segmentation](http://openaccess.thecvf.com/content_CVPR_2019/html/Kirillov_Panoptic_Segmentation_CVPR_2019_paper.html) ✅
[2019 - The Best of Both Modes: Separately Leveraging RGB and Depth for Unseen Object Instance Segmentation](https://arxiv.org/abs/1907.13236) ✅

> Recognizing unseen objects is a challenging perception task
since the robot needs to learn the concept of “objects” and generalize it to unseen objects
> An ideal method would combine the generalization capability of training on synthetic depth
and the ability to produce sharp masks by training on RGB.
> Training DSN with depth images allows for better generalization to the real world data
> We posit that mask refinement is an easier problem than directly using RGB as input to produce instance masks.
> For the semantic segmentation loss, we use a weighted cross entropy as this
has been shown to work well in detecting object boundaries in imbalanced images [29].
> In order to train the RRN, we need examples of perturbed masks along with ground truth masks.
Since such perturbations do not exist, this problem can be seen as a data augmentation task where we
augment the ground truth mask into something that resembles an initial mask
> In order to seek a fair comparison, all models trained in this section are trained for 100k iterations
of SGD using a fixed learning rate of 1e-2 and batch size of 8.
[2019 - ShapeMask: Learning to Segment Novel Objects by Refining Shape Priors](https://arxiv.org/abs/1904.03239)

[2019 - Learning to Segment via Cut-and-Paste](https://arxiv.org/abs/1803.06414)
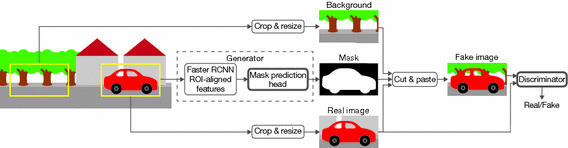
[2019 - YOLACT Real-time Instance Segmentation](https://arxiv.org/abs/1904.02689)[[github]](https://github.com/dbolya/yolact)

---
[2021 - Boundary IoU: Improving Object-Centric Image Segmentation Evaluation](https://arxiv.org/abs/2103.16562) [[github]](https://bowenc0221.github.io/boundary-iou/)
We present Boundary IoU (Intersection-over-Union), a new segmentation evaluation measure focused on boundary quality. We perform an extensive analysis across different error types and object sizes and show that Boundary IoU is significantly more sensitive than the standard Mask IoU measure to boundary errors for large objects and does not over-penalize errors on smaller objects. The new quality measure displays several desirable characteristics like symmetry w.r.t. prediction/ground truth pairs and balanced responsiveness across scales, which makes it more suitable for segmentation evaluation than other boundary-focused measures like Trimap IoU and F-measure. Based on Boundary IoU, we update the standard evaluation protocols for instance and panoptic segmentation tasks by proposing the Boundary AP (Average Precision) and Boundary PQ (Panoptic Quality) metrics, respectively. Our experiments show that the new evaluation metrics track boundary quality improvements that are generally overlooked by current Mask IoU-based evaluation metrics. We hope that the adoption of the new boundary-sensitive evaluation metrics will lead to rapid progress in segmentation methods that improve boundary quality.

## Instance Segmentation
[2017 - Mask R-CNN](https://arxiv.org/abs/1703.06870v3) ⭕
We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding-box object detection, and person keypoint detection. Without bells and whistles, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners. We hope our simple and effective approach will serve as a solid baseline and help ease future research in instance-level recognition

[2019 - Instance Segmentation by Jointly Optimizing Spatial Embeddings and Clustering Bandwidth](https://arxiv.org/abs/1906.11109)[[github](https://github.com/axruff/SpatialEmbeddings)] ⭕
Current state-of-the-art instance segmentation methods are not suited for real-time applications like autonomous driving, which require fast execution times at high accuracy. Although the currently dominant proposal-based methods have high accuracy, they are slow and generate masks at a fixed and low resolution. Proposal-free methods, by contrast, can generate masks at high resolution and are often faster, but fail to reach the same accuracy as the proposal-based methods. In this work we propose a new clustering loss function for proposal-free instance segmentation. The loss function pulls the spatial embeddings of pixels belonging to the same instance together and jointly learns an instance-specific clustering bandwidth, maximizing the intersection-over-union of the resulting instance mask. When combined with a fast architecture, the network can perform instance segmentation in real-time while maintaining a high accuracy. We evaluate our method on the challenging Cityscapes benchmark and achieve top results (5\% improvement over Mask R-CNN) at more than 10 fps on 2MP images.

## Interactive Segmentation
[2020 - Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections](https://arxiv.org/abs/1911.12709) ⭕
In interactive object segmentation a user collaborates with a computer vision model to segment an object. Recent works employ convolutional neural networks for this task: Given an image and a set of corrections made by the user as input, they output a segmentation mask. These approaches achieve strong performance by training on large datasets but they keep the model parameters unchanged at test time. Instead, we recognize that user corrections can serve as sparse training examples and we propose a method that capitalizes on that idea to update the model parameters on-the-fly to the data at hand. Our approach enables the adaptation to a particular object and its background, to distributions shifts in a test set, to specific object classes, and even to large domain changes, where the imaging modality changes between training and testing. We perform extensive experiments on 8 diverse datasets and show: Compared to a model with frozen parameters, our method reduces the required corrections (i) by 9%-30% when distribution shifts are small between training and testing; (ii) by 12%-44% when specializing to a specific class; (iii) and by 60% and 77% when we completely change domain between training and testing.

## Anomaly Detection
[2009 - Anomaly Detection: A Survey](https://www.vs.inf.ethz.ch/edu/HS2011/CPS/papers/chandola09_anomaly-detection-survey.pdf) 📜
[2017 - Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery](https://arxiv.org/abs/1703.05921v1)
## Semantic Correspondence
[2017 - End-to-end weakly-supervised semantic alignment](https://arxiv.org/abs/1712.06861)

[2019 - SFNet: Learning Object-aware Semantic Correspondence](https://arxiv.org/abs/1904.01810) - [[github]](https://github.com/cvlab-yonsei/SFNet)

[2020 - Deep Semantic Matching with Foreground Detection and Cycle-Consistency](https://arxiv.org/abs/2004.00144)

## Optical Flow
[2019 - SelFlow: Self-Supervised Learning of Optical Flow](https://arxiv.org/abs/1904.09117) [- [github]](https://github.com/ppliuboy/SelFlow)

We present a self-supervised learning approach for optical flow. Our method distills reliable flow estimations from non-occluded pixels, and uses these predictions as ground truth to learn optical flow for hallucinated occlusions. We further design a simple CNN to utilize temporal information from multiple frames for better flow estimation. These two principles lead to an approach that yields the best performance for unsupervised optical flow learning on the challenging benchmarks including MPI Sintel, KITTI 2012 and 2015. More notably, our self-supervised pre-trained model provides an excellent initialization for supervised fine-tuning. Our fine-tuned models achieve state-of-the-art results on all three datasets. At the time of writing, we achieve EPE=4.26 on the Sintel benchmark, outperforming all submitted methods.
[2021 - AutoFlow: Learning a Better Training Set for Optical Flow](http://people.csail.mit.edu/celiu/pdfs/CVPR21_AutoFlow.pdf)

Synthetic datasets play a critical role in pre-training CNN models for optical flow, but they are painstaking to generate and hard to adapt to new applications. To automate the process, we present AutoFlow, a simple and effective method to render training data for optical flow that optimizes the performance of a model on a target dataset. AutoFlow takes a layered approach to render synthetic data, where the motion, shape, and appearance of each layer are controlled by learnable hyperparameters. Experimental results show that AutoFlow achieves state-of-the-art accuracy in pre-training both PWC-Net and RAFT.
[2021 - SMURF: Self-Teaching Multi-Frame Unsupervised RAFT with Full-Image Warping](https://arxiv.org/abs/2105.07014)

# Methods
## Transfer Learning
- [Transfer Learning](https://github.com/axruff/TransferLearning)
- [Domain Adaptation](https://github.com/axruff/TransferLearning)
- [Domain Randomization](https://github.com/axruff/TransferLearning#domain-randomization)
- [Style Transfer](https://github.com/axruff/TransferLearning#style-transfer)
## Generative Modelling
- [Generative Models](https://github.com/axruff/TransferLearning#generative-models)
## Weakly Supervised
[2015 - Constrained Convolutional Neural Networks for Weakly Supervised Segmentation](https://arxiv.org/abs/1506.03648)

[2018 - Deep Learning with Mixed Supervision for Brain Tumor Segmentation](https://arxiv.org/abs/1812.04571)
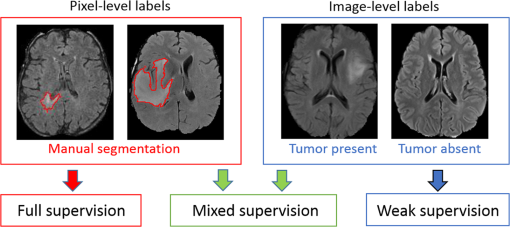
[2019 - Localization with Limited Annotation for Chest X-rays](https://arxiv.org/abs/1909.08842v1)

[2019 - Doubly Weak Supervision of Deep Learning Models for Head CT](https://jdunnmon.github.io/miccai_crc.pdf)
[2019 - Training Complex Models with Multi-Task Weak Supervision](https://www.ncbi.nlm.nih.gov/pubmed/31565535)
As machine learning models continue to increase in complexity, collecting large hand-labeled training sets has become one of the biggest roadblocks in practice. Instead, weaker forms of supervision that provide noisier but cheaper labels are often used. However, these weak supervision sources have diverse and unknown accuracies, may output correlated labels, and may label different tasks or apply at different levels of granularity. We propose a framework for integrating and modeling such weak supervision sources by viewing them as labeling different related sub-tasks of a problem, which we refer to as the multi-task weak supervision setting. We show that by solving a matrix completion-style problem, we can recover the accuracies of these multi-task sources given their dependency structure, but without any labeled data, leading to higher-quality supervision for training an end model. Theoretically, we show that the generalization error of models trained with this approach improves with the number of unlabeled data points, and characterize the scaling with respect to the task and dependency structures. On three fine-grained classification problems, we show that our approach leads to average gains of 20.2 points in accuracy over a traditional supervised approach, 6.8 points over a majority vote baseline, and 4.1 points over a previously proposed weak supervision method that models tasks separately.

[2020 - Fast and Three-rious: Speeding Up Weak Supervision with Triplet Methods](https://arxiv.org/abs/2002.11955)
## Semi Supervised
[2014 - Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks](https://arxiv.org/abs/1406.6909) ✅

[2017 - Random Erasing Data Augmentation](https://arxiv.org/abs/1708.04896v2)[[github]](https://github.com/zhunzhong07/Random-Erasing)

[2017 - Smart Augmentation - Learning an Optimal Data Augmentation Strategy](https://arxiv.org/abs/1703.08383)
[2017 - Population Based Training of Neural Networks](https://arxiv.org/abs/1711.09846) ⭕
[2018 - **[Survey]**: Not-so-supervised: a survey of semi-supervised, multi-instance, and transfer learning in medical image analysis](https://arxiv.org/abs/1804.06353) 📜
[2018 - Albumentations: fast and flexible image augmentations](https://arxiv.org/abs/1809.06839) - [[github]](https://github.com/albu/albumentations) ✅
[2018 - Data Augmentation by Pairing Samples for Images Classification](https://arxiv.org/abs/1801.02929)
[2018 - **[AutoAugment]**: Learning Augmentation Policies from Data](https://arxiv.org/abs/1805.09501)
[2018 - Synthetic Data Augmentation using GAN for Improved Liver Lesion Classification](https://arxiv.org/abs/1801.02385)
[2018 - GAN Augmentation: Augmenting Training Data using Generative Adversarial Networks](https://arxiv.org/abs/1810.10863)
[2019 - **[UDA]**: Unsupervised Data Augmentation for Consistency Training](https://arxiv.org/abs/1904.12848) - [[github]](https://github.com/google-research/uda) ⭕
Common among recent approaches is the use of consistency training on a large amount of unlabeled data to constrain model predictions to be invariant to input noise. In this work, we present a new perspective on how to effectively noise unlabeled examples and argue that the quality of noising, specifically those produced by advanced data augmentation methods, plays a crucial role in semi-supervised learning. Our method also combines well with transfer learning, e.g., when finetuning from BERT, and yields improvements in high-data regime, such as ImageNet, whether when there is only 10% labeled data or when a full labeled set with 1.3M extra unlabeled examples is used.

[2019 - **[MixMatch]**: A Holistic Approach to Semi-Supervised Learning](https://arxiv.org/abs/1905.02249) ⭕
Semi-supervised learning has proven to be a powerful paradigm for leveraging unlabeled data to mitigate the reliance on large labeled datasets. In this work, we unify the current dominant approaches for semi-supervised learning to produce a new algorithm, MixMatch, that works by guessing low-entropy labels for data-augmented unlabeled examples and mixing labeled and unlabeled data using MixUp. We show that MixMatch obtains state-of-the-art results by a large margin across many datasets and labeled data amounts.
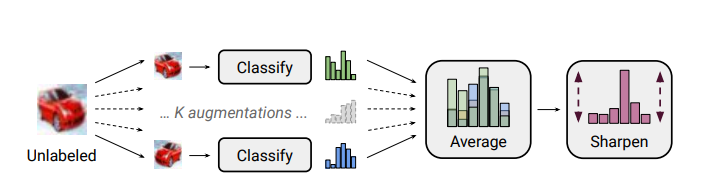
[2019 - **[RealMix]**: Towards Realistic Semi-Supervised Deep Learning Algorithms](https://arxiv.org/abs/1912.08766v1) ✅

[2019 - Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules](https://arxiv.org/abs/1905.05393) [[github]](https://github.com/arcelien/pba) ✅
[2019 - **[AugMix]**: A Simple Data Processing Method to Improve Robustness and Uncertainty](https://arxiv.org/abs/1912.02781v1) [[github]](https://github.com/google-research/augmix) ✅

[2019 - Self-training with **[Noisy Student]** improves ImageNet classification](https://arxiv.org/abs/1911.04252) ✅
We present a simple self-training method that achieves 88.4% top-1 accuracy on ImageNet, which is 2.0% better than the state-of-the-art model that requires 3.5B weakly labeled Instagram images. On robustness test sets, it improves ImageNet-A top-1 accuracy from 61.0% to 83.7%.
To achieve this result, we first train an EfficientNet model on labeled ImageNet images and use it as a teacher to generate pseudo labels on 300M unlabeled images. We then train a larger EfficientNet as a student model on the combination of labeled and pseudo labeled images. We iterate this process by putting back the student as the teacher. During the generation of the pseudo labels, the teacher is not noised so that the pseudo labels are as accurate as possible. However, during the learning of the student, we inject noise such as dropout, stochastic depth and data augmentation via RandAugment to the student so that the student generalizes better than the teacher.

[2020 - Rain rendering for evaluating and improving robustness to bad weather](https://arxiv.org/abs/2009.03683)
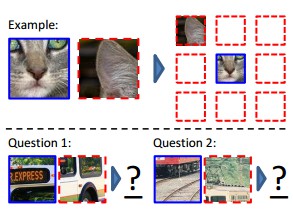
## Unsupervised Learning
---
[2015 - Unsupervised Visual Representation Learning by Context Prediction](https://arxiv.org/abs/1505.05192)
This work explores the use of spatial context as a source of free and plentiful supervisory signal for training a rich visual representation. Given only a large, unlabeled image collection, we extract random pairs of patches from each image and train a convolutional neural net to predict the position of the second patch relative to the first. We argue that doing well on this task requires the model to learn to recognize objects and their parts. We demonstrate that the feature representation learned using this within-image context indeed captures visual similarity across images. For example, this representation allows us to perform unsupervised visual discovery of objects like cats, people, and even birds from the Pascal VOC 2011 detection dataset. Furthermore, we show that the learned ConvNet can be used in the R-CNN framework and provides a significant boost over a randomly-initialized ConvNet, resulting in state-of-the-art performance among algorithms which use only Pascal-provided training set annotations.
---
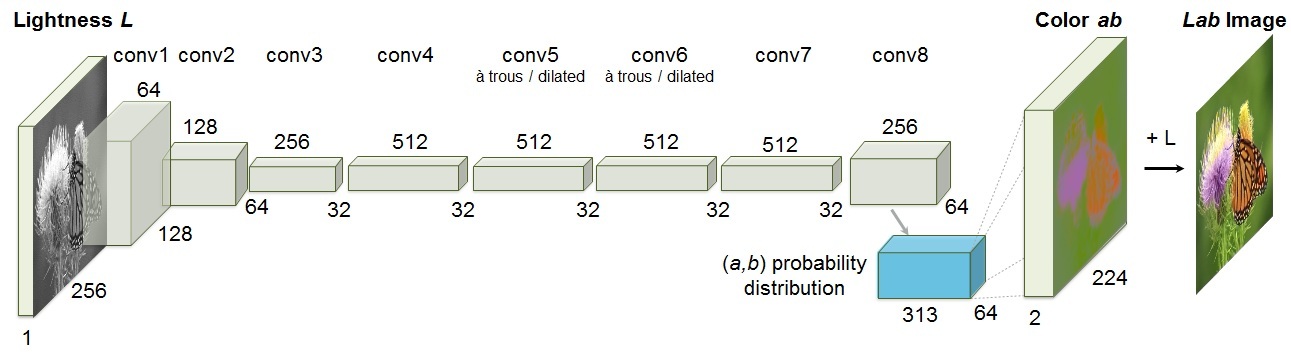
[2016 - Colorful Image Colorization](https://arxiv.org/abs/1603.08511)
---
[2016 - Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles](https://arxiv.org/abs/1603.09246)
In this paper we study the problem of image representation learning without human annotation. By following the principles of self-supervision, we build a convolutional neural network (CNN) that can be trained to solve Jigsaw puzzles as a pretext task, which requires no manual labeling, and then later repurposed to solve object classification and detection. To maintain the compatibility across tasks we introduce the context-free network (CFN), a siamese-ennead CNN. The CFN takes image tiles as input and explicitly limits the receptive field (or context) of its early processing units to one tile at a time. We show that the CFN includes fewer parameters than AlexNet while preserving the same semantic learning capabilities. By training the CFN to solve Jigsaw puzzles, we learn both a feature mapping of object parts as well as their correct spatial arrangement. Our experimental evaluations show that the learned features capture semantically relevant content. Our proposed method for learning visual representations outperforms state of the art methods in several transfer learning benchmarks.

---
[2016 - Context Encoders: Feature Learning by Inpainting](https://www.semanticscholar.org/paper/Context-Encoders%3A-Feature-Learning-by-Inpainting-Pathak-Kr%C3%A4henb%C3%BChl/7d0effebfa4bed19b6ba41f3af5b7e5b6890de87)

---
[2018 - Unsupervised Representation Learning by Predicting Image Rotations](https://www.semanticscholar.org/paper/Unsupervised-Representation-Learning-by-Predicting-Gidaris-Singh/aab368284210c1bb917ec2d31b84588e3d2d7eb4)

[2019 - Greedy InfoMax for Biologically Plausible Self-Supervised Representation Learning](https://arxiv.org/abs/1905.11786)
[2019 - Unsupervised Learning via Meta-Learning](https://arxiv.org/abs/1810.02334)
---
[2019 - **[PIRL]**: Self-Supervised Learning of Pretext-Invariant Representations](https://www.semanticscholar.org/paper/Self-Supervised-Learning-of-Pretext-Invariant-Misra-Maaten/0170bb0b524df2c81b5adc3062c6001a2eb34c96)
Ishan Misra, L. V. D. Maaten
The goal of self-supervised learning from images is to construct image representations that are semantically meaningful via pretext tasks that do not require semantic annotations. Many pretext tasks lead to representations that are covariant with image transformations. We argue that, instead, semantic representations ought to be invariant under such transformations. Specifically, we develop Pretext-Invariant Representation Learning (PIRL, pronounced as `pearl') that learns invariant representations based on pretext tasks. We use PIRL with a commonly used pretext task that involves solving jigsaw puzzles. We find that PIRL substantially improves the semantic quality of the learned image representations. Our approach sets a new state-of-the-art in self-supervised learning from images on several popular benchmarks for self-supervised learning. Despite being unsupervised, PIRL outperforms supervised pre-training in learning image representations for object detection. Altogether, our results demonstrate the potential of self-supervised representations with good invariance properties

[2019 - Representation Learning with Contrastive Predictive Coding](https://arxiv.org/abs/1807.03748)
---
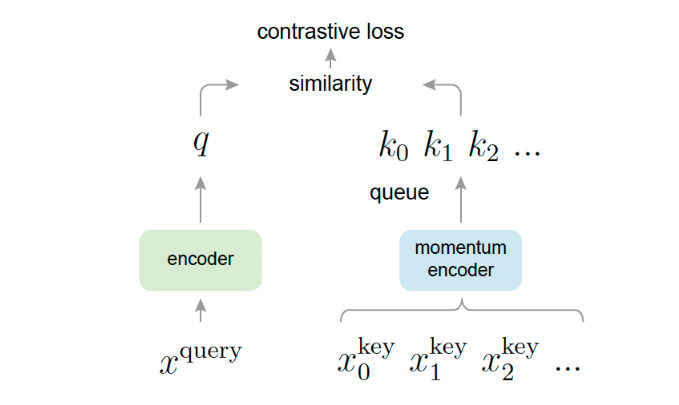
[2019 - **[MoCo]**: Momentum Contrast for Unsupervised Visual Representation Learning](https://arxiv.org/abs/1911.05722)
We present Momentum Contrast (MoCo) for unsupervised visual representation learning. From a perspective on contrastive learning as dictionary look-up, we build a dynamic dictionary with a queue and a moving-averaged encoder. This enables building a large and consistent dictionary on-the-fly that facilitates contrastive unsupervised learning. MoCo provides competitive results under the common linear protocol on ImageNet classification. More importantly, the representations learned by MoCo transfer well to downstream tasks. MoCo can outperform its supervised pre-training counterpart in 7 detection/segmentation tasks on PASCAL VOC, COCO, and other datasets, sometimes surpassing it by large margins. This suggests that the gap between unsupervised and supervised representation learning has been largely closed in many vision tasks.
[2019 - Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey](https://arxiv.org/abs/1902.06162)
---
[2020 - **[SimCLR]**: A Simple Framework for Contrastive Learning of Visual Representations](https://arxiv.org/abs/2002.05709) ✅
This paper presents SimCLR: a simple framework for contrastive learning of visual representations. We simplify recently proposed contrastive self-supervised learning algorithms without requiring specialized architectures or a memory bank. In order to understand what enables the contrastive prediction tasks to learn useful representations, we systematically study the major components of our framework. We show that (1) composition of data augmentations plays a critical role in defining effective predictive tasks, (2) introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations, and (3) contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning. By combining these findings, we are able to considerably outperform previous methods for self-supervised and semi-supervised learning on ImageNet. A linear classifier trained on self-supervised representations learned by SimCLR achieves 76.5% top-1 accuracy, which is a 7% relative improvement over previous state-of-the-art, matching the performance of a supervised ResNet-50. When fine-tuned on only 1% of the labels, we achieve 85.8% top-5 accuracy, outperforming AlexNet with 100X fewer labels.
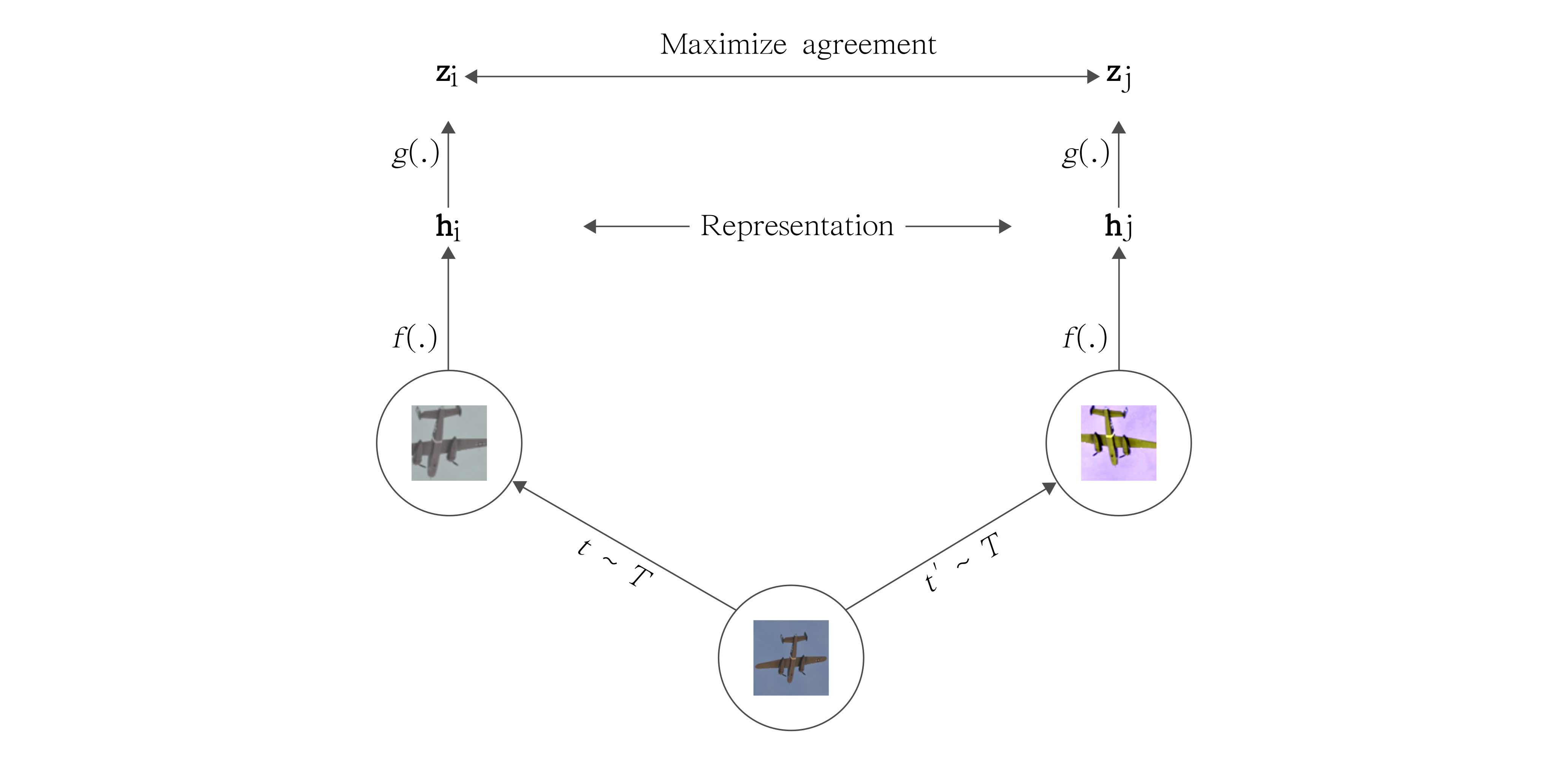
[2020 - **::SURVEY::** Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey](https://arxiv.org/abs/1902.06162) 📜⭕
[2020 - **[NeurIPS 2020 Workshop]**: Self-Supervised Learning - Theory and Practice](https://sslneuips20.github.io/pages/Accepted%20Paper.html) ⭕
---
[2020 - **[BYOL]**: Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning](https://www.semanticscholar.org/paper/Bootstrap-Your-Own-Latent%3A-A-New-Approach-to-Grill-Strub/38f93092ece8eee9771e61c1edaf11b1293cae1b)
We introduce Bootstrap Your Own Latent (BYOL), a new approach to self-supervised image representation learning. BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view of an image, we train the online network to predict the target network representation of the same image under a different augmented view. At the same time, we update the target network with a slow-moving average of the online network. While state-of-the art methods rely on negative pairs, BYOL achieves a new state of the art without them.

---
[2021 - [POST] Facebook: Self-supervised learning: The dark matter of intelligence](https://ai.facebook.com/blog/self-supervised-learning-the-dark-matter-of-intelligence/)

---
[2021 - Task Fingerprinting for Meta Learning in Biomedical Image Analysis](https://www.semanticscholar.org/paper/Task-Fingerprinting-for-Meta-Learning-in-Biomedical-Godau-Maier-Hein/b3b7433817380b98951d4a6502a889b8ce8c7422)

## Mutual Learning
[2017 - Deep Mutual Learning](https://arxiv.org/abs/1706.00384) ✅

[2019 - Feature Fusion for Online Mutual Knowledge Distillation ](https://arxiv.org/abs/1904.09058)

## Multitask Learning
---
[2016 - Cross-Stitch Networks for Multi-task Learning](https://www.semanticscholar.org/paper/Cross-Stitch-Networks-for-Multi-task-Learning-Misra-Shrivastava/f14325ec3041a73118bc4d819204cbbca07d5a71)
Ishan Misra, Abhinav Shrivastava, A. Gupta, M. Hebert

[2017 - An Overview of Multi-Task Learning in Deep Neural Networks](https://arxiv.org/abs/1706.05098)
Multi-task learning (MTL) has led to successes in many applications of machine learning, from natural language processing and speech recognition to computer vision and drug discovery. This article aims to give a general overview of MTL, particularly in deep neural networks. It introduces the two most common methods for MTL in Deep Learning, gives an overview of the literature, and discusses recent advances. In particular, it seeks to help ML practitioners apply MTL by shedding light on how MTL works and providing guidelines for choosing appropriate auxiliary tasks.
[2017 - Multi-task Self-Supervised Visual Learning](https://arxiv.org/abs/1708.07860)
We investigate methods for combining multiple self-supervised tasks--i.e., supervised tasks where data can be collected without manual labeling--in order to train a single visual representation. First, we provide an apples-to-apples comparison of four different self-supervised tasks using the very deep ResNet-101 architecture. We then combine tasks to jointly train a network. We also explore lasso regularization to encourage the network to factorize the information in its representation, and methods for "harmonizing" network inputs in order to learn a more unified representation. We evaluate all methods on ImageNet classification, PASCAL VOC detection, and NYU depth prediction. Our results show that deeper networks work better, and that combining tasks--even via a naive multi-head architecture--always improves performance. Our best joint network nearly matches the PASCAL performance of a model pre-trained on ImageNet classification, and matches the ImageNet network on NYU depth prediction.
## Reinforcement Learning
An Introduction to Deep Reinforcement Learning
https://arxiv.org/abs/1811.12560
Deep Reinforcement Learning
https://arxiv.org/abs/1810.06339
Playing Atari with Deep Reinforcement Learning
https://arxiv.org/pdf/1312.5602.pdf
Key Papers in Deep Reinforcment Learning
https://spinningup.openai.com/en/latest/spinningup/keypapers.html
Recurrent Models of Visual Attention
https://arxiv.org/abs/1406.6247
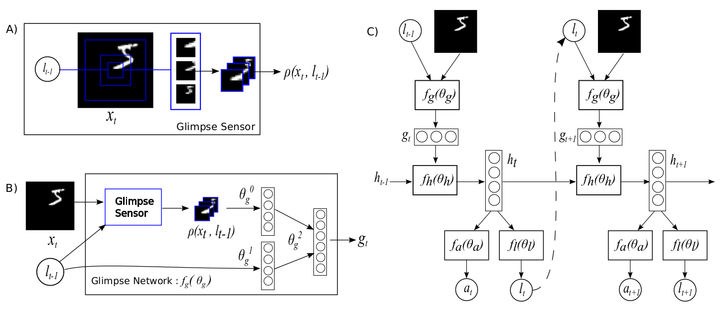
### Inverse Reinforcement Learning
[2019 - On the Feasibility of Learning, Rather than Assuming, Human Biases for Reward Inference](https://arxiv.org/abs/1906.09624)

# Visual Questions and Object Retrieval
[2015 - Natural Language Object Retrieval](https://arxiv.org/abs/1511.04164)
[2019 - CLEVR-Ref+: Diagnosing Visual Reasoning with Referring Expressions](https://arxiv.org/abs/1901.00850)
# Datasets
[**[ADE20K Dataset]**: Semantic Segmentation [website]](http://groups.csail.mit.edu/vision/datasets/ADE20K/)
Scene Parsing through ADE20K Dataset
http://people.csail.mit.edu/bzhou/publication/scene-parse-camera-ready.pdf

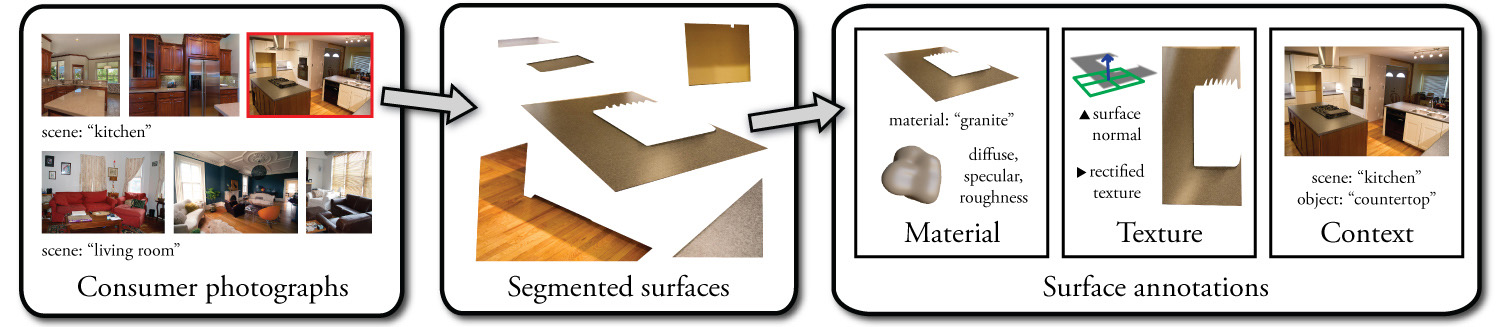
[**[OPENSURFACES]**: A Richly Annotated Catalog of Surface Appearance](http://opensurfaces.cs.cornell.edu/)
https://www.cs.cornell.edu/~paulu/opensurfaces.pdf
[**[ShapeNet]** - a richly-annotated, large-scale dataset of 3D shapes [website] ](https://www.shapenet.org/)

[ShapeNet: An Information-Rich 3D Model Repository](https://arxiv.org/abs/1512.03012)
[Beyond PASCAL: A Benchmark for 3D Object Detection in the Wild [website]](http://cvgl.stanford.edu/projects/pascal3d.html)
[[paper]](https://ieeexplore.ieee.org/document/6836101)
[**[ObjectNet3D]**: A Large Scale Database for 3D Object Recognition](http://cvgl.stanford.edu/projects/objectnet3d/)
[**[ModelNet]**: a comprehensive clean collection of 3D CAD models for objects [website]](http://modelnet.cs.princeton.edu/)

[**[3D ShapeNets]**: A Deep Representation for Volumetric Shapes (2015)](https://ieeexplore.ieee.org/document/7298801)
[**[BLEND SWAP]**: IS A COMMUNITY OF PASSIONATE BLENDER ARTISTS WHO SHARE THEIR WORK UNDER CREATIVE COMMONS LICENSES](https://www.blendswap.com/)
[**[DTD]**: Describable Textures Dataset](https://www.robots.ox.ac.uk/~vgg/data/dtd/)

[**[MegaDepth]**: Learning Single-View Depth Prediction from Internet Photos](https://research.cs.cornell.edu/megadepth/)

[Microsoft **[COCO]**: Common Objects in Context](https://arxiv.org/abs/1405.0312)[[website]](https://cocodataset.org/#home)

[2020 - **[CARLA]** Open-source simulator for autonomous driving research.](https://carla.org/)

[A Browsable Petascale Reconstruction of the Human Cortex](https://ai.googleblog.com/2021/06/a-browsable-petascale-reconstruction-of.html)

[2021 - Medical Segmentation Decathlon. Generalisable 3D Semantic Segmentation](http://medicaldecathlon.com/)
Aim: With recent advances in machine learning, semantic segmentation algorithms are becoming increasingly general purpose and translatable to unseen tasks. Many key algorithmic advances in the field of medical imaging are commonly validated on a small number of tasks, limiting our understanding of the generalisability of the proposed contributions. A model which works out-of-the-box on many tasks, in the spirit of AutoML, would have a tremendous impact on healthcare. The field of medical imaging is also missing a fully open source and comprehensive benchmark for general purpose algorithmic validation and testing covering a large span of challenges, such as: small data, unbalanced labels, large-ranging object scales, multi-class labels, and multimodal imaging, etc. This challenge and dataset aims to provide such resource thorugh the open sourcing of large medical imaging datasets on several highly different tasks, and by standardising the analysis and validation process.

# Benchmarks
[MLPerf: A broad ML benchmark suite for measuring performance of ML software frameworks, ML hardware accelerators, and ML cloud platforms.](https://mlperf.org/results/)
[DAWNBench: is a benchmark suite for end-to-end deep learning training and inference.](https://dawn.cs.stanford.edu/benchmark/)
[DAWNBench: An End-to-End Deep Learning Benchmark and Competition (paper) (2017)](https://dawn.cs.stanford.edu/benchmark/papers/nips17-dawnbench.pdf)
# Applications
Material Recognition in the Wild with the Materials in Context Database
http://opensurfaces.cs.cornell.edu/publications/minc/
tempoGAN: A Temporally Coherent, Volumetric GAN for Super-resolution Fluid Flow
https://ge.in.tum.de/publications/tempogan/

[BubGAN: Bubble Generative Adversarial Networks for Synthesizing Realistic Bubbly Flow Images](https://arxiv.org/abs/1809.02266)

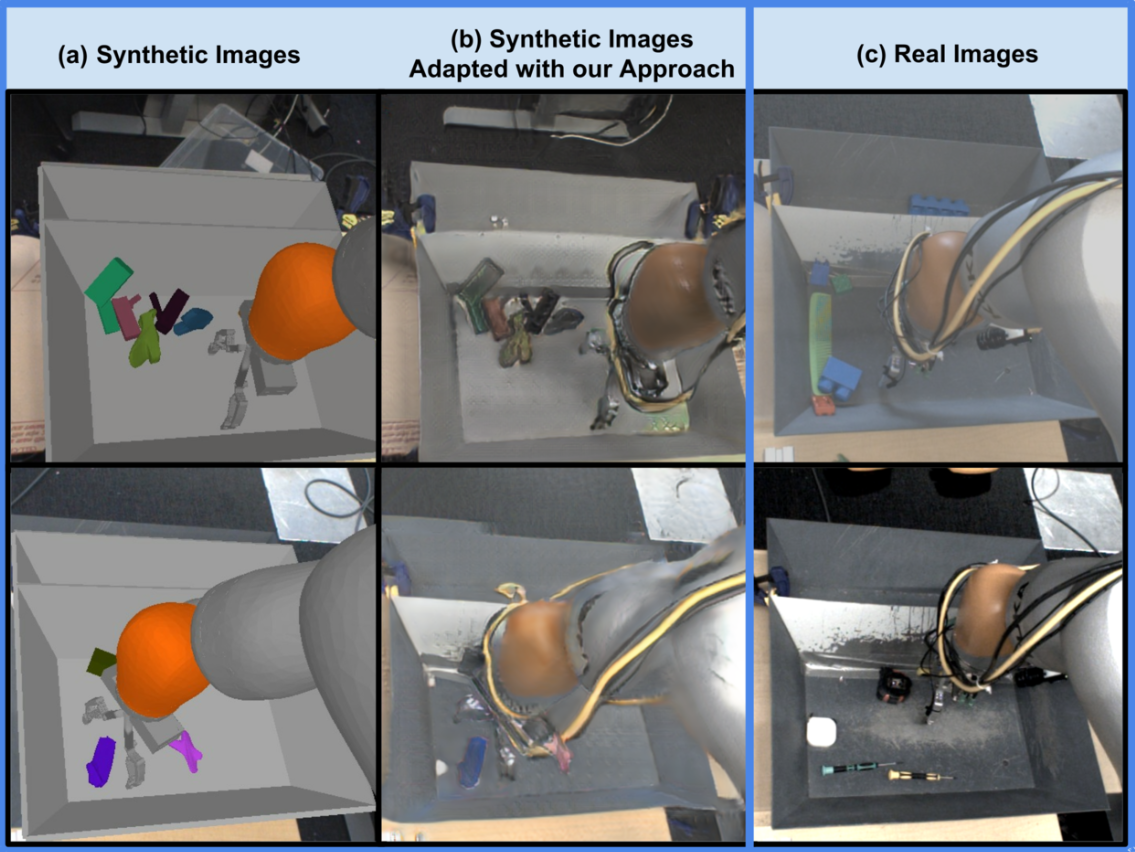
[Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping (2018)](https://ieeexplore.ieee.org/abstract/document/8460875)
# Applications: Medical Imaging
Generative adversarial networks for specular highlight removal in endoscopic images
https://doi.org/10.1117/12.2293755

[Deep learning with domain adaptation for accelerated projection‐reconstruction MR (2017)](https://onlinelibrary.wiley.com/doi/full/10.1002/mrm.27106)
[Synthetic Data Augmentation using GAN for Improved Liver Lesion Classification (2018)](https://arxiv.org/abs/1801.02385)
[GAN Augmentation: Augmenting Training Data using Generative Adversarial Networks (2018)](https://arxiv.org/abs/1810.10863)
[Abdominal multi-organ segmentation with organ-attention networks and statistical fusion (2018)](https://arxiv.org/abs/1804.08414)
[Prior-aware Neural Network for Partially-Supervised Multi-Organ Segmentation (2019)](https://arxiv.org/abs/1904.06346)


[Breast Tumor Segmentation and Shape Classification in Mammograms using Generative Adversarial and Convolutional Neural Network (2018)](https://arxiv.org/abs/1809.01687)
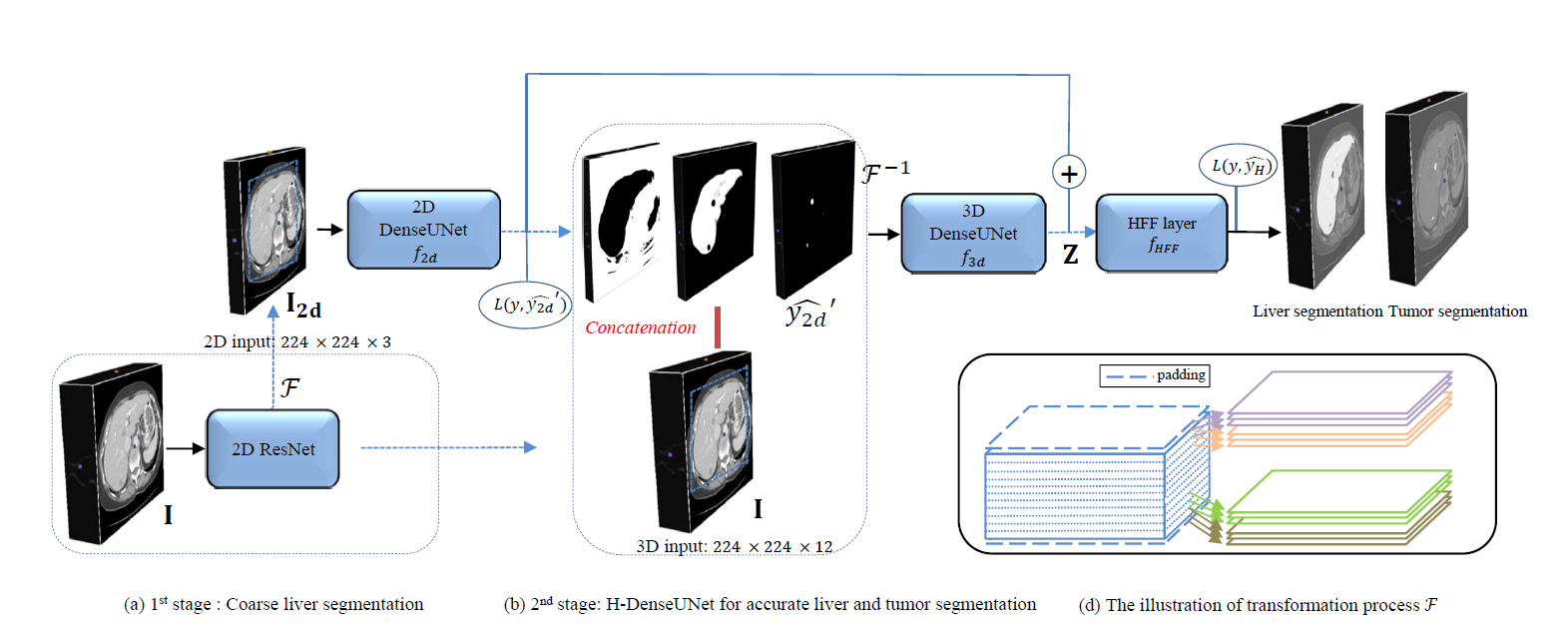
[2019 - H-DenseUNet: Hybrid Densely Connected UNet for Liver and Tumor Segmentation from CT Volumes](https://arxiv.org/abs/1709.07330v3)
[2020 - **[TorchIO]**: a Python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images in deep learning](https://arxiv.org/abs/2003.04696) [[github]](https://github.com/fepegar/torchio)
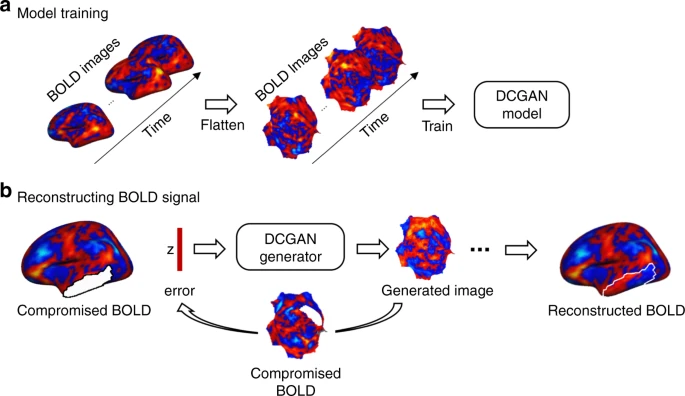
[2020 - Reconstructing lost BOLD signal in individual participants using deep machine learning](https://www.nature.com/articles/s41467-020-18823-9#disqus_thread)
# Applications: X-ray Imaging
Low-dose X-ray tomography through a deep convolutional neural network
https://www.nature.com/articles/s41598-018-19426-7
*In synchrotron-based XRT, CNN-based processing improves the SNR in the data by an order of magnitude, which enables low-dose fast acquisition of radiation-sensitive samples*
[2019 - Deep learning optoacoustic tomography with sparse data](https://www.nature.com/articles/s42256-019-0095-3)

[2019 - A deep learning reconstruction framework for X-ray computed tomography with incomplete data](https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0224426)

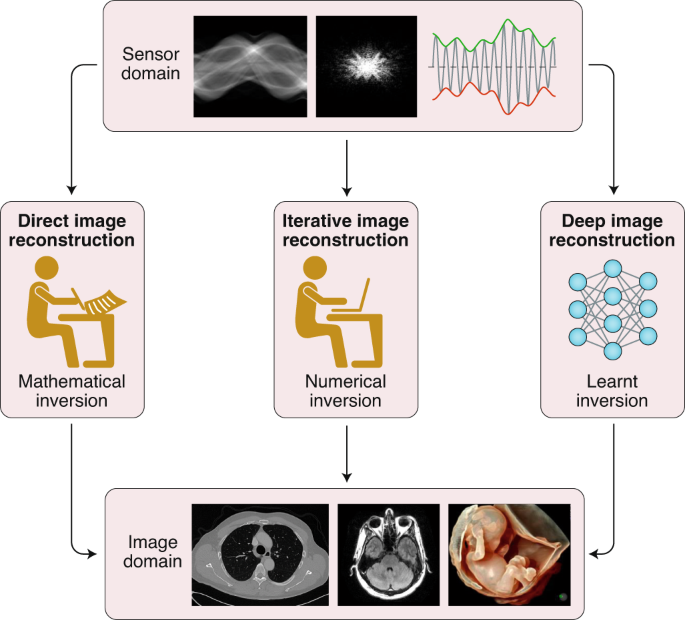
[2020 - Deep Learning Techniques for Inverse Problems in Imaging](https://ieeexplore.ieee.org/abstract/document/9084378) ⭕
[2020 - **[Review]**: Deep learning for tomographic image reconstruction (closed)](https://www.nature.com/articles/s42256-020-00273-z#author-information)
[2020 - Patient-specific reconstruction of volumetric computed tomography images from a single projection view via deep learning.](https://www.nature.com/articles/s41551-019-0466-4)

[2020 - End-To-End Convolutional Neural Network for 3D Reconstruction of Knee Bones from Bi-planar X-Ray Images](https://link.springer.com/chapter/10.1007%2F978-3-030-61598-7_12)
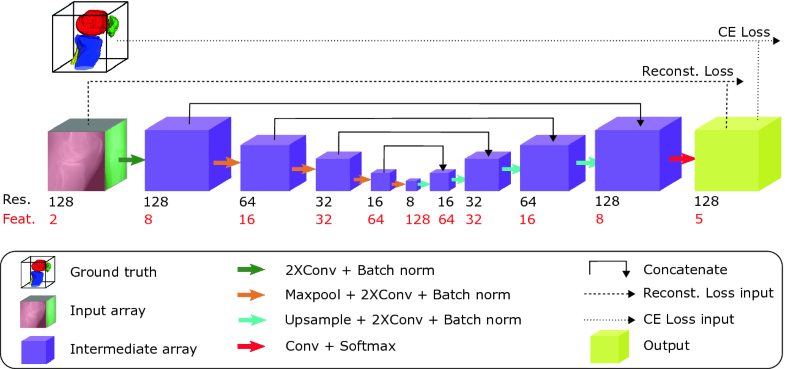
[2020 - Differentiated Backprojection Domain Deep Learning for Conebeam Artifact Removal](https://ieeexplore.ieee.org/document/9109572)

[2020 - Extreme Sparse X-ray Computed Laminography Via Convolutional Neural Networks](https://ieeexplore.ieee.org/abstract/document/9288349/authors)

[2021 - **[SliceGAN]**: Generating 3D structures from a 2D slice with GAN-based dimensionality expansion](https://arxiv.org/abs/2102.07708)

Generative adversarial networks (GANs) can be trained to generate 3D image data, which is useful for design optimisation. However, this conventionally requires 3D training data, which is challenging to obtain. 2D imaging techniques tend to be faster, higher resolution, better at phase identification and more widely available. Here, we introduce a generative adversarial network architecture, SliceGAN, which is able to synthesise high fidelity 3D datasets using a single representative 2D image. This is especially relevant for the task of material microstructure generation, as a cross-sectional micrograph can contain sufficient information to statistically reconstruct 3D samples. Our architecture implements the concept of uniform information density, which both ensures that generated volumes are equally high quality at all points in space, and that arbitrarily large volumes can be generated. SliceGAN has been successfully trained on a diverse set of materials, demonstrating the widespread applicability of this tool. The quality of generated micrographs is shown through a statistical comparison of synthetic and real datasets of a battery electrode in terms of key microstructural metrics. Finally, we find that the generation time for a 108 voxel volume is on the order of a few seconds, yielding a path for future studies into high-throughput microstructural optimisation.
[2021 - DeepPhase: Learning phase contrast signal from dual energy X-ray absorption images](https://www.sciencedirect.com/science/article/abs/pii/S014193822100038X)

[2022 - Machine learning denoising of high-resolution X-ray nanotomography data](https://journals.iucr.org/s/issues/2022/01/00/tv5025/index.html#BB12)
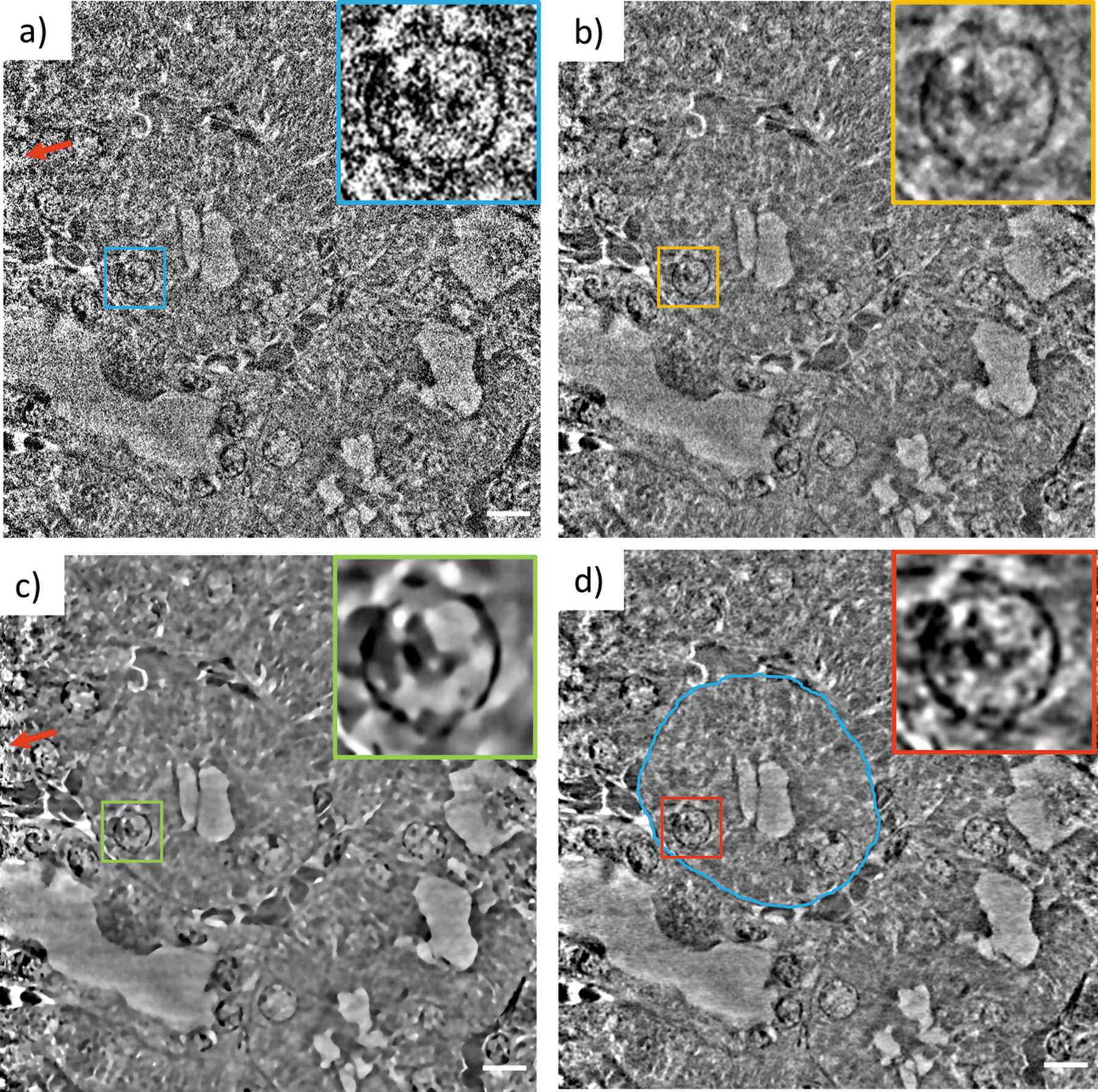
High-resolution X-ray nanotomography is a quantitative tool for investigating specimens from a wide range of research areas. However, the quality of the reconstructed tomogram is often obscured by noise and therefore not suitable for automatic segmentation. Filtering methods are often required for a detailed quantitative analysis. However, most filters induce blurring in the reconstructed tomograms. Here, machine learning (ML) techniques offer a powerful alternative to conventional filtering methods. In this article, we verify that a self-supervised denoising ML technique can be used in a very efficient way for eliminating noise from nanotomography data. The technique presented is applied to high-resolution nanotomography data and compared to conventional filters, such as a median filter and a nonlocal means filter, optimized for tomographic data sets. The ML approach proves to be a very powerful tool that outperforms conventional filters by eliminating noise without blurring relevant structural features, thus enabling efficient quantitative analysis in different scientific fields.
# Applications: Image Registration
[2014 - Do Convnets Learn Correspondence?](https://arxiv.org/abs/1411.1091)

[2016 - Universal Correspondence Network](https://arxiv.org/abs/1606.03558)
We present a deep learning framework for accurate visual correspondences and demonstrate its effectiveness for both geometric and semantic matching, spanning across rigid motions to intra-class shape or appearance variations. In contrast to previous CNN-based approaches that optimize a surrogate patch similarity objective, we use deep metric learning to directly learn a feature space that preserves either geometric or semantic similarity. Our fully convolutional architecture, along with a novel correspondence contrastive loss allows faster training by effective reuse of computations, accurate gradient computation through the use of thousands of examples per image pair and faster testing with O(n) feed forward passes for n keypoints, instead of O(n2) for typical patch similarity methods. We propose a convolutional spatial transformer to mimic patch normalization in traditional features like SIFT, which is shown to dramatically boost accuracy for semantic correspondences across intra-class shape variations. Extensive experiments on KITTI, PASCAL, and CUB-2011 datasets demonstrate the significant advantages of our features over prior works that use either hand-constructed or learned features.
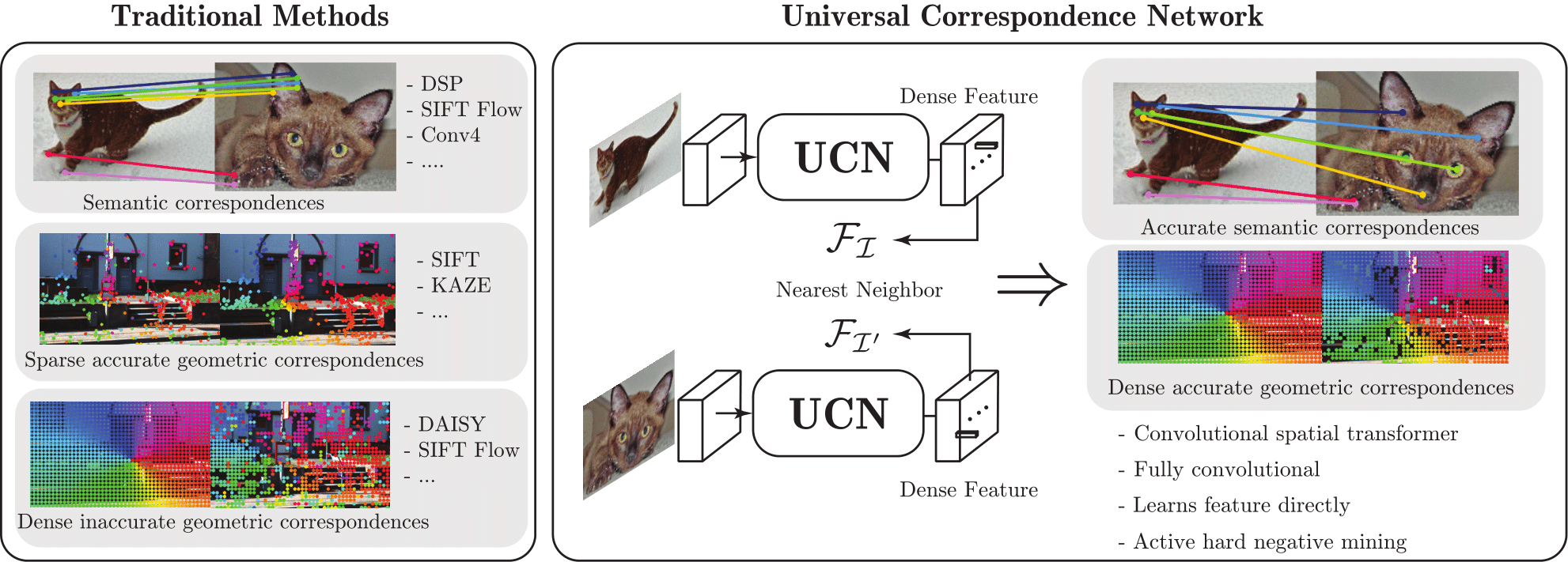
[2016 - Learning Dense Correspondence via 3D-guided Cycle Consistency](https://arxiv.org/abs/1604.05383)
Discriminative deep learning approaches have shown impressive results for problems where human-labeled ground truth is plentiful, but what about tasks where labels are difficult or impossible to obtain? This paper tackles one such problem: establishing dense visual correspondence across different object instances. For this task, although we do not know what the ground-truth is, we know it should be consistent across instances of that category. We exploit this consistency as a supervisory signal to train a convolutional neural network to predict cross-instance correspondences between pairs of images depicting objects of the same category. For each pair of training images we find an appropriate 3D CAD model and render two synthetic views to link in with the pair, establishing a correspondence flow 4-cycle. We use ground-truth synthetic-to-synthetic correspondences, provided by the rendering engine, to train a ConvNet to predict synthetic-to-real, real-to-real and real-to-synthetic correspondences that are cycle-consistent with the ground-truth. At test time, no CAD models are required. We demonstrate that our end-to-end trained ConvNet supervised by cycle-consistency outperforms state-of-the-art pairwise matching methods in correspondence-related tasks.

[2017 - Convolutional neural network architecture for geometric matching](https://arxiv.org/abs/1703.05593)[[github]](https://github.com/ignacio-rocco/cnngeometric_pytorch)
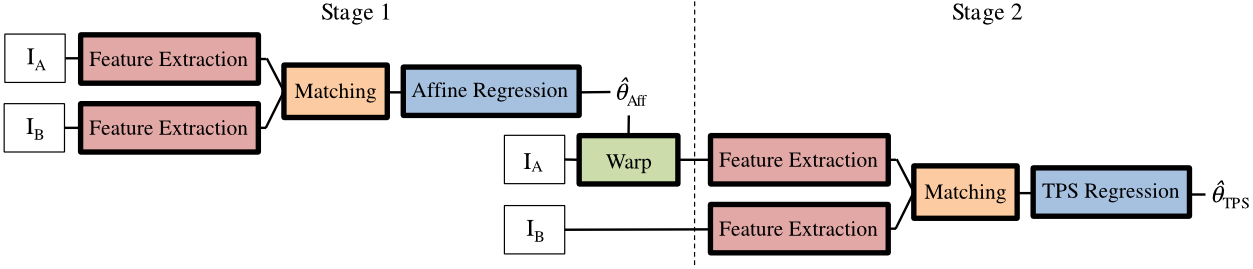
[2018 - **[DGC-Net]**: Dense Geometric Correspondence Network](https://arxiv.org/abs/1810.08393) [[github]](https://github.com/AaltoVision/DGC-Net)

[2018 - An Unsupervised Learning Model for Deformable Medical Image Registration](https://arxiv.org/abs/1802.02604)
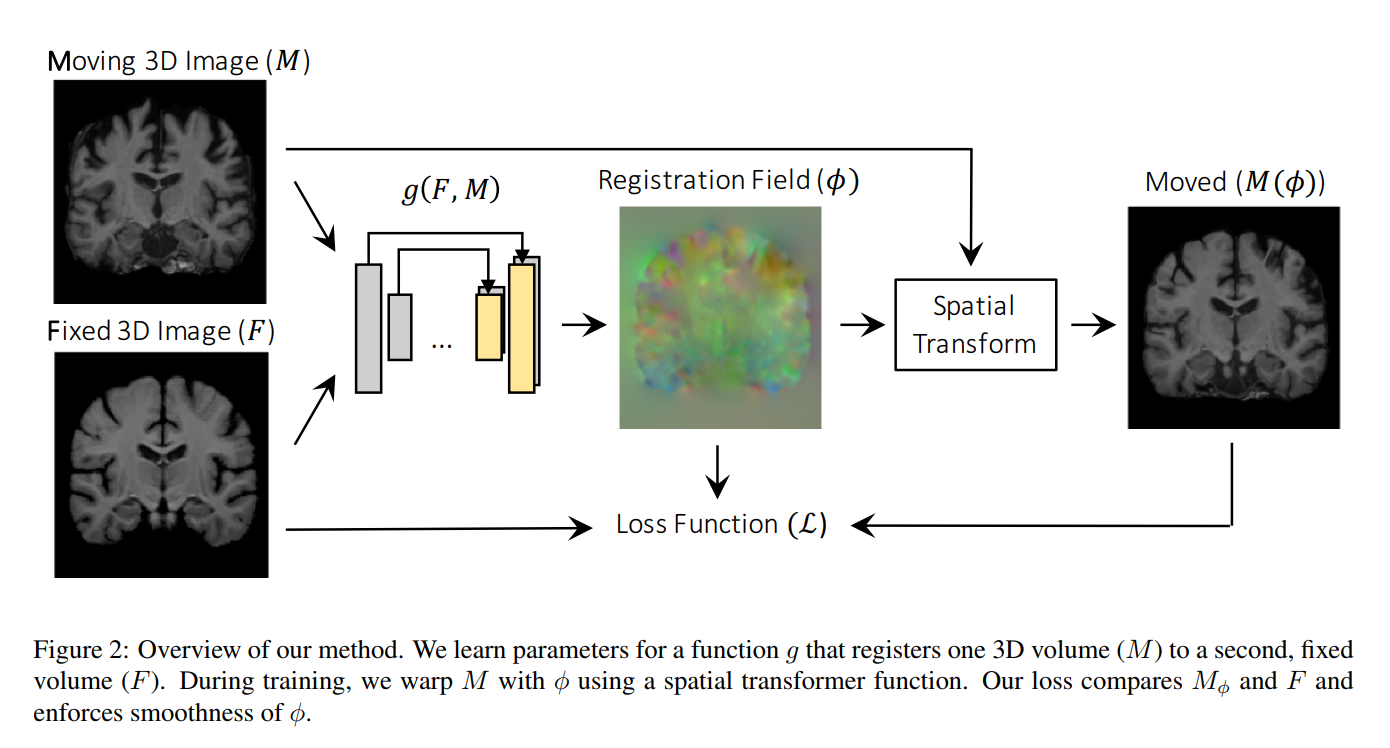
[2018 - VoxelMorph: A Learning Framework for Deformable Medical Image Registration](https://arxiv.org/abs/1809.05231) [[github]](https://github.com/voxelmorph/voxelmorph)

[2019 - A Deep Learning Framework for Unsupervised Affine and Deformable Image Registration](https://arxiv.org/abs/1809.06130)

[2019 - Unsupervised Learning of Probabilistic Diffeomorphic Registration for Images and Surfaces](https://arxiv.org/abs/1903.03545)
![]()
[2020 - RANSAC-Flow: generic two-stage image alignment](https://arxiv.org/abs/2004.01526)
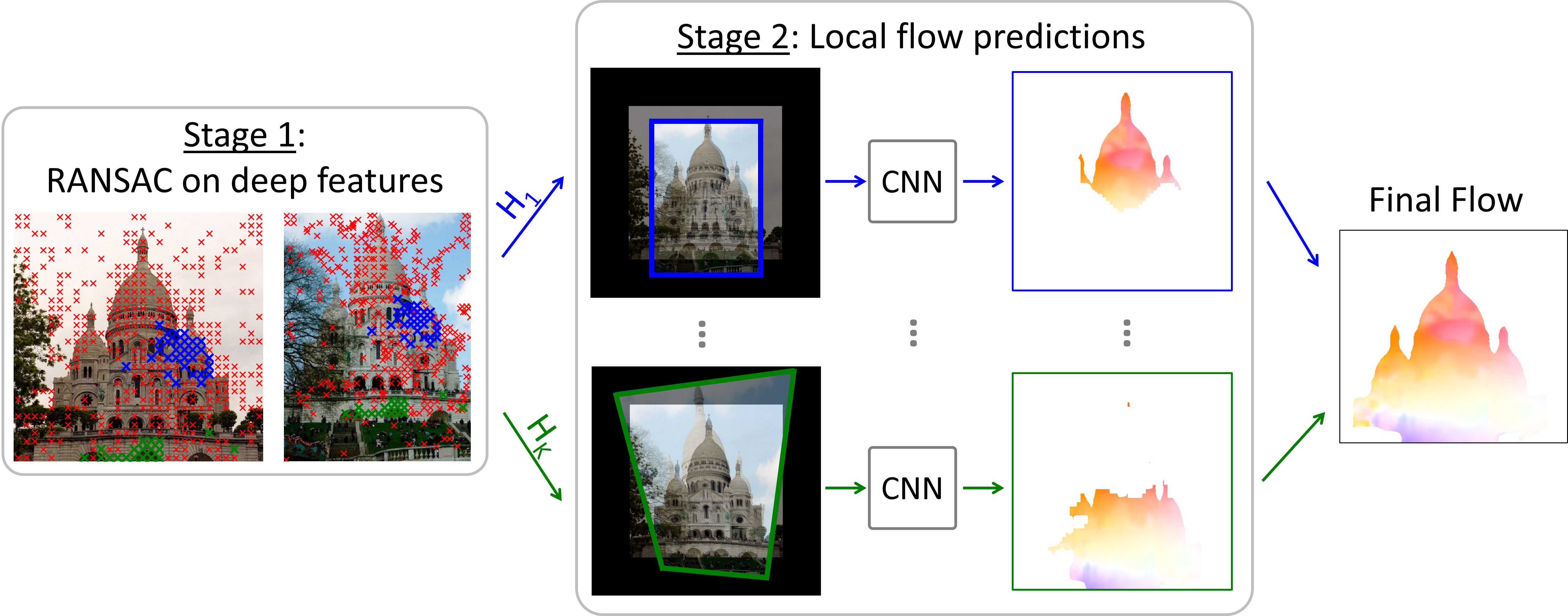
# Applications: Video
Flow-Guided Feature Aggregation for Video Object Detection
https://arxiv.org/abs/1703.10025
Deep Feature Flow for Video Recognition
https://arxiv.org/abs/1611.07715
[Video-to-Video Synthesis (2018)](https://arxiv.org/abs/1808.06601) [[github]](https://github.com/NVIDIA/vid2vid)
[2017 - PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume](https://arxiv.org/abs/1709.02371)[[github]](https://github.com/axruff/pytorch-pwc)
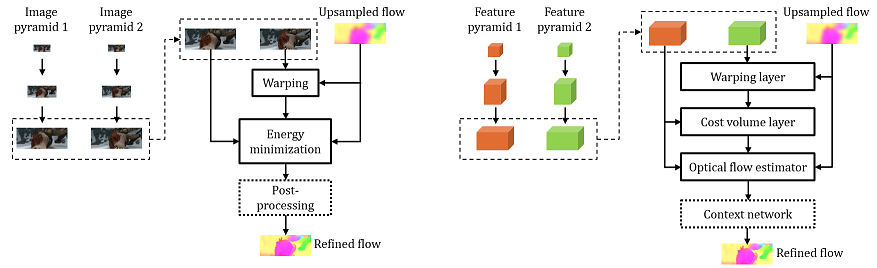
[2020 - Softmax Splatting for Video Frame Interpolation](https://arxiv.org/abs/2003.05534) [[github]](https://github.com/sniklaus/softmax-splatting)

[2017 - **[TOFlow]** Video Enhancement with Task-Oriented Flow](https://arxiv.org/abs/1711.09078)

Many video enhancement algorithms rely on optical flow to register frames in a video sequence. Precise flow estimation is however intractable; and optical flow itself is often a sub-optimal representation for particular video processing tasks. In this paper, we propose task-oriented flow (TOFlow), a motion representation learned in a self-supervised, task-specific manner. We design a neural network with a trainable motion estimation component and a video processing component, and train them jointly to learn the task-oriented flow. For evaluation, we build Vimeo-90K, a large-scale, high-quality video dataset for low-level video processing. TOFlow outperforms traditional optical flow on standard benchmarks as well as our Vimeo-90K dataset in three video processing tasks: frame interpolation, video denoising/deblocking, and video super-resolution.
# Applications: Simulations
[2020 - Automating turbulence modelling by multi-agent reinforcement learning](https://www.nature.com/articles/s42256-020-00272-0)
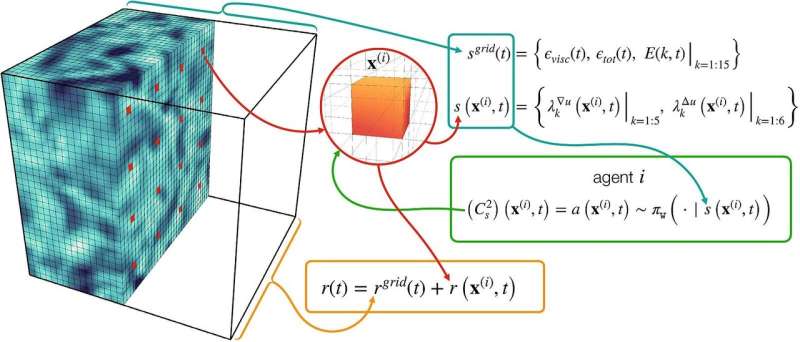
# Application: Denoising and Superresolution
[2017 - "Zero-Shot" Super-Resolution using Deep Internal Learning](https://arxiv.org/abs/1712.06087)

[2018 - Residual Dense Network for Image Restoration](https://arxiv.org/abs/1812.10477v1) [[github]](https://github.com/yulunzhang/RDN)

[2018 - Image Super-Resolution Using Very Deep Residual Channel Attention Networks](https://arxiv.org/abs/1807.02758)
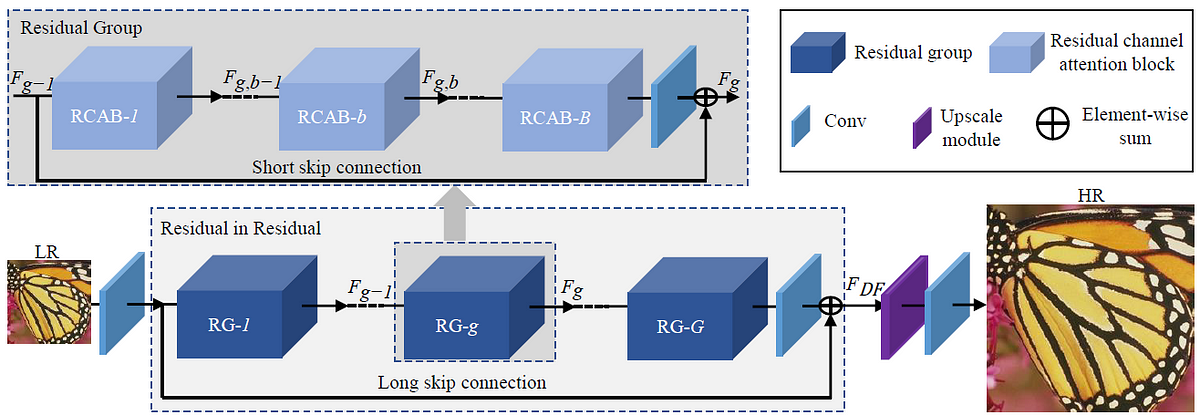
---
[2019 - Noise2Self: Blind Denoising by Self-Supervision](https://www.semanticscholar.org/paper/Noise2Self%3A-Blind-Denoising-by-Self-Supervision-Batson-Royer/ea9cf47573638745c9992cf9c5ebdabadd3c6849)
We propose a general framework for denoising high-dimensional measurements which requires no prior on the signal, no estimate of the noise, and no clean training data. The only assumption is that the noise exhibits statistical independence across different dimensions of the measurement, while the true signal exhibits some correlation. For a broad class of functions ("$\mathcal{J}$-invariant"), it is then possible to estimate the performance of a denoiser from noisy data alone. This allows us to calibrate $\mathcal{J}$-invariant versions of any parameterised denoising algorithm, from the single hyperparameter of a median filter to the millions of weights of a deep neural network. We demonstrate this on natural image and microscopy data, where we exploit noise independence between pixels, and on single-cell gene expression data, where we exploit independence between detections of individual molecules. This framework generalizes recent work on training neural nets from noisy images and on cross-validation for matrix factorization.

[2020 - Improving Blind Spot Denoising for Microscopy](https://arxiv.org/abs/2008.08414)

Many microscopy applications are limited by the total amount of usable light and are consequently challenged by the resulting levels of noise in the acquired images. This problem is often addressed via (supervised) deep learning based denoising. Recently, by making assumptions about the noise statistics, self-supervised methods have emerged. Such methods are trained directly on the images that are to be denoised and do not require additional paired training data. While achieving remarkable results, self-supervised methods can produce high-frequency artifacts and achieve inferior results compared to supervised approaches. Here we present a novel way to improve the quality of self-supervised denoising. Considering that light microscopy images are usually diffraction-limited, we propose to include this knowledge in the denoising process. We assume the clean image to be the result of a convolution with a point spread function PSF) and explicitly include this operation at the end of our neural network. As a consequence, we are able to eliminate high-frequency artifacts and achieve self-supervised results that are very close to the ones achieved with traditional supervised methods.
[2021 - Denoising-based Image Compression for Connectomics](https://www.biorxiv.org/content/10.1101/2021.05.29.445828v1)

---
[2021 - Task-Assisted GAN for Resolution Enhancement and Modality Translation in Fluorescence Microscopy]()

# Applications: Inpainting
[2018 - Image Inpainting for Irregular Holes Using Partial Convolutions](http://openaccess.thecvf.com/content_ECCV_2018/papers/Guilin_Liu_Image_Inpainting_for_ECCV_2018_paper.pdf)[[github official]](https://github.com/NVIDIA/partialconv), [[github]](https://github.com/MathiasGruber/PConv-Keras)

[2017 - Globally and Locally Consistent Image Completion](http://iizuka.cs.tsukuba.ac.jp/projects/completion/data/completion_sig2017.pdf)[[github]](https://github.com/satoshiiizuka/siggraph2017_inpainting)

[2017 - Generative Image Inpainting with Contextual Attention](https://arxiv.org/abs/1801.07892)[[github]](https://github.com/JiahuiYu/generative_inpainting)

[2018 - Free-Form Image Inpainting with Gated Convolution](https://arxiv.org/abs/1806.03589)

# Applications: Photography
[Photo-realistic single image super-resolution using a generative adversarial network (2016)](https://arxiv.org/abs/1609.04802)[[github]](https://github.com/tensorlayer/srgan)

[A Closed-form Solution to Photorealistic Image Stylization (2018)](https://arxiv.org/abs/1802.06474)[[github]](https://github.com/NVIDIA/FastPhotoStyle)

---
[2021 - COIN: COmpression with Implicit Neural representations](https://www.semanticscholar.org/paper/COIN%3A-COmpression-with-Implicit-Neural-Dupont-Goli'nski/1bf444b861acc3dad72d968c2c69bcb863885ff9)

# Applications: Misc
[**[pix2code]**: Generating Code from a Graphical User Interface Screenshot](https://arxiv.org/abs/1705.07962v2) [[github]](https://github.com/tonybeltramelli/pix2code)

[Fast Interactive Object Annotation with Curve-GCN (2019)](https://arxiv.org/abs/1903.06874v1)
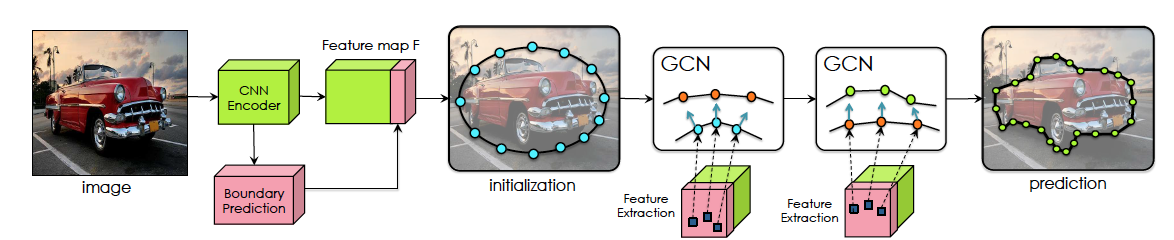
[2017 - Learning Fashion Compatibility with Bidirectional LSTMs](https://arxiv.org/abs/1707.05691)[[github]](https://github.com/xthan/polyvore)

[2020 - A Systematic Literature Review on the Use of Deep Learning in Software Engineering Research](https://arxiv.org/abs/2009.06520)
[2020 - Fourier Neural Operator for Parametric Partial Differential Equations](https://arxiv.org/abs/2010.08895)
# Software
[**Caffe**: Convolutional Architecture for Fast Feature Embedding](https://arxiv.org/abs/1408.5093)
[**Tune**: A Research Platform for Distributed Model Selection and Training (2018)](https://arxiv.org/abs/1807.05118) [[github]](https://github.com/ray-project/ray/tree/master/python/ray/tune)
[**Glow**: Compiler for Neural Network hardware accelerators](https://github.com/pytorch/glow)

[**Lucid**: A collection of infrastructure and tools for research in neural network interpretability](https://github.com/tensorflow/lucid)
[**PySyft**: A generic framework for privacy preserving deep learning](https://arxiv.org/abs/1811.04017) [[github]](https://github.com/OpenMined/PySyft)
[**Crypten**: A framework for Privacy Preserving Machine Learning](https://crypten.ai/) [[github]](https://github.com/facebookresearch/crypten)
[**[Snorkel]**: Programmatically Building and Managing Training Data](https://www.snorkel.org/)
[**[Netron ]** Visualizer for deep learning and machine learning models](https://github.com/lutzroeder/Netron)
[**[Interactive Tools]** for ML, DL and Math](https://github.com/Machine-Learning-Tokyo/Interactive_Tools)
[**[Efemarai]**](https://efemarai.com/)
[**[mlflow]** - An open source platform for the machine learning lifecycle](https://mlflow.org/)
[OpenAI Microscope](https://microscope.openai.com/models)

[**[TorchIO]** - Medical image preprocessing and augmentation toolkit for deep learning](https://github.com/fepegar/torchio)
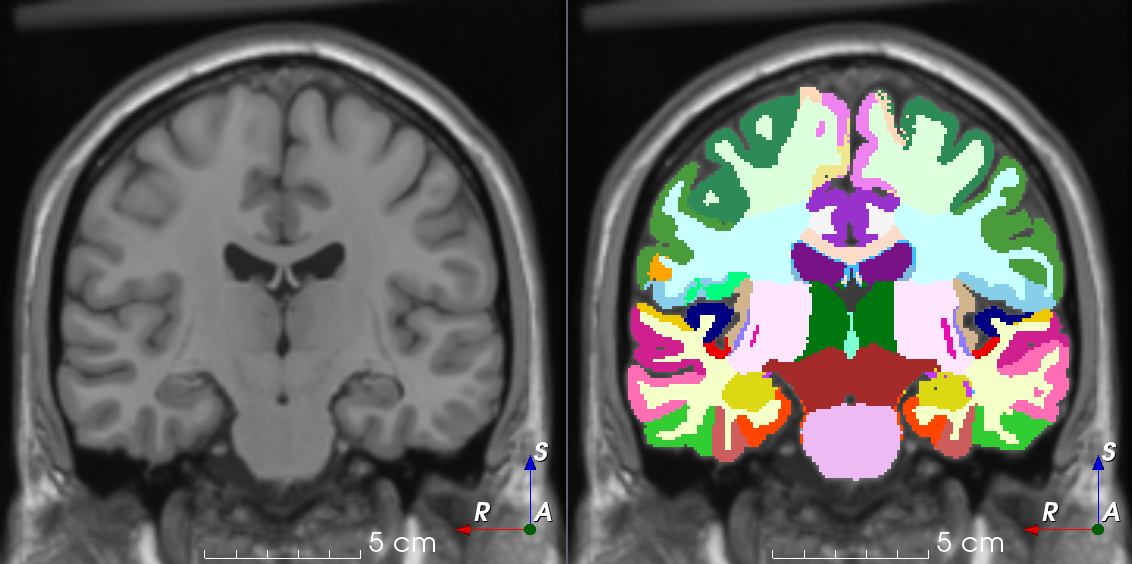
[**[Ignite]** - high-level library to help with training and evaluating neural networks](https://github.com/pytorch/ignite)

[**[Cadene]** - Pretrained models for Pytorch](https://github.com/Cadene/pretrained-models.pytorch)
[**[PyTorch Toolbelt]** - a Python library with a set of bells and whistles for PyTorch for fast R&D prototyping](https://github.com/BloodAxe/pytorch-toolbelt)
[**[PyTorch Lightning]**- The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate](https://github.com/PyTorchLightning/pytorch-lightning)

[**[Rapid]** - Open GPU Data Science](https://rapids.ai/index.html)

[**[DALI]** - NVIDIA Data Loading Library](https://developer.nvidia.com/dali)
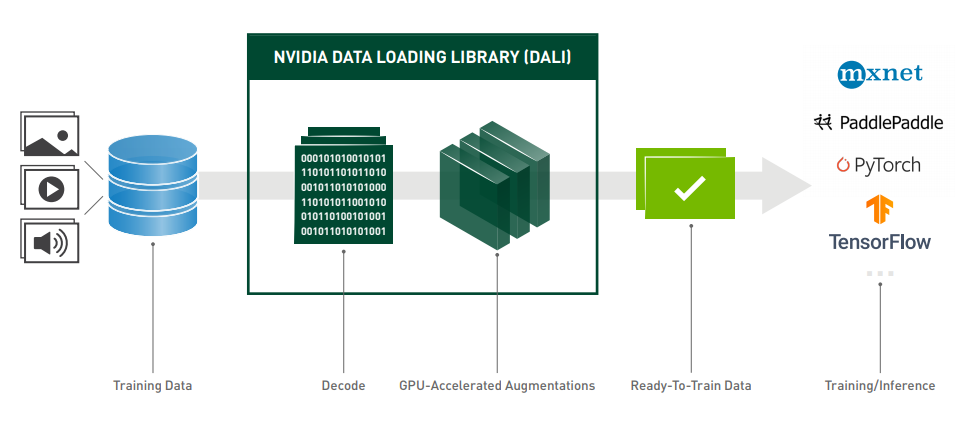
[**[Ray]** - Fast and Simple Distributed Computing](https://ray.io/)
[**[PhotonAI]** - A high level Python API for designing and optimizing machine learning pipelines.](https://www.photon-ai.com/)

[**[DeepImageJ]**: A user-friendly environment to run deep learning models in ImageJ](https://deepimagej.github.io/deepimagej/)

[**[ImJoy]**: Deep Learning Made Easy!](https://imjoy.io/#/)
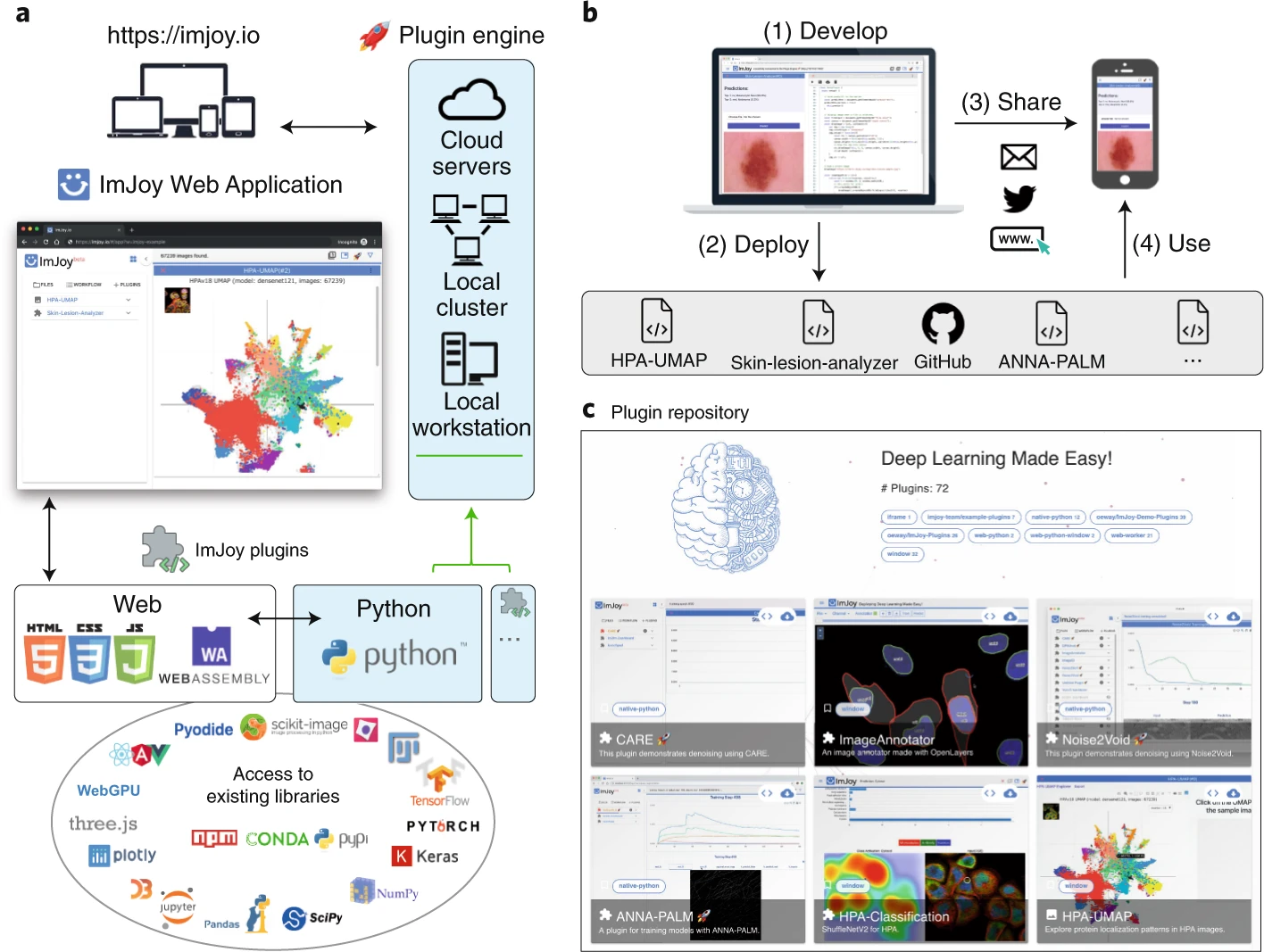
[**[BioImage.IO]**: Bioimage Model Zoo](https://bioimage.io/#/)

[**[DeepImageTranslator]**: a free, user-friendly graphical interface for image translation using deep-learning and its applications in 3D CT image analysis](https://prelights.biologists.com/highlights/deepimagetranslator-a-free-user-friendly-graphical-interface-for-image-translation-using-deep-learning-and-its-applications-in-3d-ct-image-analysis/)
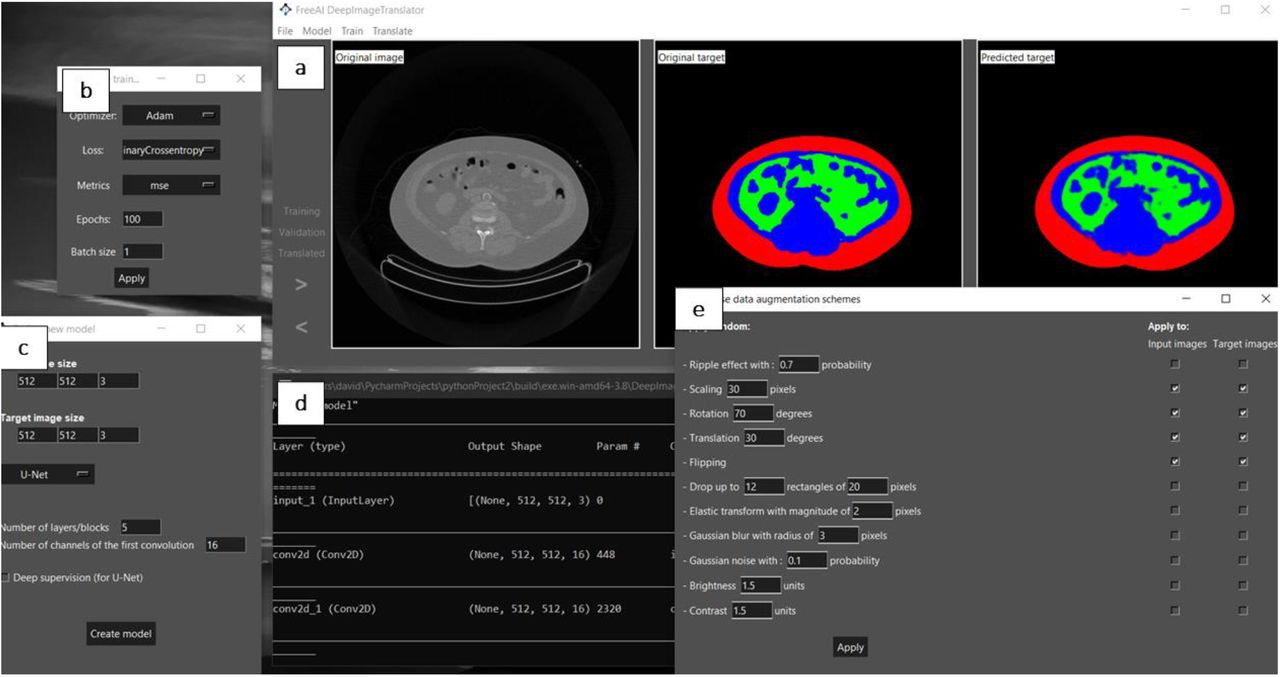
---
[Analytics Zoo (Intel): Distributed TensorFlow, PyTorch, Keras and BigDL on Apache Spark & Ray](https://github.com/intel-analytics/analytics-zoo)
Analytics Zoo is an open source Big Data AI platform, and includes the following features for scaling end-to-end AI to distributed Big Data:
Orca: seamlessly scale out TensorFlow and PyTorch for Big Data (using Spark & Ray)
RayOnSpark: run Ray programs directly on Big Data clusters
BigDL Extensions: high-level Spark ML pipeline and Keras-like APIs for BigDL
Chronos: scalable time series analysis using AutoML
PPML: privacy preserving big data analysis and machine learning (experimental)

---
[**[OpenMMLab]** - Open source projects for academic research and industrial applications](https://openmmlab.com/home)
![]()
---
[2021 - BTrack: Bayesian Tracker](https://github.com/quantumjot/BayesianTracker)
BayesianTracker (btrack) is a Python library for multi object tracking, used to reconstruct trajectories in crowded fields. Here, we use a probabilistic network of information to perform the trajectory linking. This method uses spatial information as well as appearance information for track linking.

# Overview
[2016 - An Analysis of Deep Neural Network Models for Practical Applications](https://arxiv.org/abs/1605.07678)
[2017 - Revisiting Unreasonable Effectiveness of Data in Deep Learning Era](https://arxiv.org/abs/1707.02968)
[2019 - High-performance medicine: the convergence of human and artificial intelligence](https://www.nature.com/articles/s41591-018-0300-7)
[2020 - Maithra Raghu, Eric Schmidt. A Survey of Deep Learning for Scientific Discovery](https://arxiv.org/abs/2003.11755v1)
[**[ml-surveys [github]]** - a selection of survey papers summarizing the advances in the field](https://github.com/eugeneyan/ml-surveys) 📜
[**[DALI]** - NVIDIA Data Loading Library ](https://developer.nvidia.com/dali)
[2021 - Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans](https://www.nature.com/articles/s42256-021-00307-0) 📜
# Opinions
[2016 - Building Machines That Learn and Think Like People](https://www.semanticscholar.org/paper/Building-Machines-That-Learn-and-Think-Like-People-Lake-Ullman/5721a0c623aeb12a65b4d6f5a5c83a5f82988d7c) ⭕
[2016 - A Berkeley View of Systems Challenges for AI](https://arxiv.org/abs/1712.05855)
[2018 - Deep Learning: A Critical Appraisal](https://arxiv.org/abs/1801.00631)
[2018 - Human-level intelligence or animal-like abilities?](https://dl.acm.org/citation.cfm?id=3271625)
[2018 - When Will AI Exceed Human Performance? Evidence from AI Experts](https://arxiv.org/abs/1705.08807)

[2018 - The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation](https://docs.google.com/document/d/e/2PACX-1vQzbSybtXtYzORLqGhdRYXUqiFsaEOvftMSnhVgJ-jRh6plwkzzJXoQ-sKtej3HW_0pzWTFY7-1eoGf/pub)

[2018 - Deciphering China’s AI Dream: The context, components, capabilities, and consequences of China’s strategy to lead the world in AI](https://www.fhi.ox.ac.uk/deciphering-chinas-ai-dream/)
[2018 - The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities](https://arxiv.org/abs/1803.03453)
Biological evolution provides a creative fount of complex and subtle adaptations, often surprising the scientists who discover them. However, because evolution is an algorithmic process that transcends the substrate in which it occurs, evolution's creativity is not limited to nature. Indeed, many researchers in the field of digital evolution have observed their evolving algorithms and organisms subverting their intentions, exposing unrecognized bugs in their code, producing unexpected adaptations, or exhibiting outcomes uncannily convergent with ones in nature. Such stories routinely reveal creativity by evolution in these digital worlds, but they rarely fit into the standard scientific narrative. Instead they are often treated as mere obstacles to be overcome, rather than results that warrant study in their own right. The stories themselves are traded among researchers through oral tradition, but that mode of information transmission is inefficient and prone to error and outright loss. Moreover, the fact that these stories tend to be shared only among practitioners means that many natural scientists do not realize how interesting and lifelike digital organisms are and how natural their evolution can be. To our knowledge, no collection of such anecdotes has been published before. This paper is the crowd-sourced product of researchers in the fields of artificial life and evolutionary computation who have provided first-hand accounts of such cases. It thus serves as a written, fact-checked collection of scientifically important and even entertaining stories. In doing so we also present here substantial evidence that the existence and importance of evolutionary surprises extends beyond the natural world, and may indeed be a universal property of all complex evolving systems.
[2019 - Deep Nets: What have they ever done for Vision?](https://arxiv.org/abs/1805.04025) ✅
This is an opinion paper about the strengths and weaknesses of Deep Nets for vision. They are at the center of recent progress on artificial intelligence and are of growing importance in cognitive science and neuroscience. They have enormous successes but also clear limitations. There is also only partial understanding of their inner workings. It seems unlikely that Deep Nets in their current form will be the best long-term solution either for building general purpose intelligent machines or for understanding the mind/brain, but it is likely that many aspects of them will remain. At present Deep Nets do very well on specific types of visual tasks and on specific benchmarked datasets. But Deep Nets are much less general purpose, flexible, and adaptive than the human visual system. Moreover, methods like Deep Nets may run into fundamental difficulties when faced with the enormous complexity of natural images which can lead to a combinatorial explosion. To illustrate our main points, while keeping the references small, this paper is slightly biased towards work from our group.
[2020 - State of AI Report 2020](https://www.stateof.ai/)
[2020 - The role of artificial intelligence in achieving the Sustainable Development Goals](https://www.nature.com/articles/s41467-019-14108-y)

[2020 - The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence](https://arxiv.org/abs/2002.06177) ⭕
Recent research in artificial intelligence and machine learning has largely emphasized general-purpose learning and ever-larger training sets and more and more compute. In contrast, I propose a hybrid, knowledge-driven, reasoning-based approach, centered around cognitive models, that could provide the substrate for a richer, more robust AI than is currently possible.
[2021 - Why AI is Harder Than We Think by Melanie Mitchell](https://arxiv.org/abs/2104.12871)
Since its beginning in the 1950s, the field of artificial intelligence has cycled several times between periods of optimistic predictions and massive investment ("AI spring") and periods of disappointment, loss of confidence, and reduced funding ("AI winter"). Even with today's seemingly fast pace of AI breakthroughs, the development of long-promised technologies such as self-driving cars, housekeeping robots, and conversational companions has turned out to be much harder than many people expected. One reason for these repeating cycles is our limited understanding of the nature and complexity of intelligence itself. In this paper I describe four fallacies in common assumptions made by AI researchers, which can lead to overconfident predictions about the field. I conclude by discussing the open questions spurred by these fallacies, including the age-old challenge of imbuing machines with humanlike common sense.