https://github.com/cedrickchee/awesome-transformer-nlp
A curated list of NLP resources focused on Transformer networks, attention mechanism, GPT, BERT, ChatGPT, LLMs, and transfer learning.
https://github.com/cedrickchee/awesome-transformer-nlp
List: awesome-transformer-nlp
attention-mechanism awesome awesome-list bert chatgpt gpt-2 gpt-3 gpt-4 language-model llama natural-language-processing neural-networks nlp pre-trained-language-models transfer-learning transformer xlnet
Last synced: 3 months ago
JSON representation
A curated list of NLP resources focused on Transformer networks, attention mechanism, GPT, BERT, ChatGPT, LLMs, and transfer learning.
- Host: GitHub
- URL: https://github.com/cedrickchee/awesome-transformer-nlp
- Owner: cedrickchee
- License: mit
- Created: 2019-01-13T13:37:08.000Z (almost 7 years ago)
- Default Branch: master
- Last Pushed: 2024-07-27T15:35:34.000Z (over 1 year ago)
- Last Synced: 2024-08-11T16:09:16.048Z (over 1 year ago)
- Topics: attention-mechanism, awesome, awesome-list, bert, chatgpt, gpt-2, gpt-3, gpt-4, language-model, llama, natural-language-processing, neural-networks, nlp, pre-trained-language-models, transfer-learning, transformer, xlnet
- Homepage:
- Size: 730 KB
- Stars: 1,054
- Watchers: 41
- Forks: 129
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-bert - cedrickchee/awesome-bert-nlp
- awesome-ChatGPT-repositories - awesome-transformer-nlp - A curated list of NLP resources focused on Transformer networks, attention mechanism, GPT, BERT, ChatGPT, LLMs, and transfer learning. (Awesome-lists)
- awesome-awesome-artificial-intelligence - Awesome Transformer NLP - transformer-nlp?style=social) | (Transformer)
- awesome-awesome-llm - cedrickchee/awesome-transformer-nlp - transformer-nlp.svg) | A collection of Transformer NLP papers, codes, and resources | | ★★★★☆ | (Topics / LLM & NLP & Information Extraction)
- awesome-llm-and-aigc - cedrickchee/awesome-transformer-nlp - transformer-nlp?style=social"/> : A curated list of NLP resources focused on Transformer networks, attention mechanism, GPT, BERT, ChatGPT, LLMs, and transfer learning. (Summary)
- ultimate-awesome - awesome-transformer-nlp - A curated list of NLP resources focused on Transformer networks, attention mechanism, GPT, BERT, ChatGPT, LLMs, and transfer learning. (Other Lists / TeX Lists)
README
# Awesome Transformer & Transfer Learning in NLP [](https://awesome.re)
This repository contains a hand-curated list of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, ChatGPT, and transfer learning in NLP.


Transformer (Source)
# Table of Contents
Expand Table of Contents
- [Papers](#papers)
- [Articles](#articles)
- [BERT and Transformer](#bert-and-transformer)
- [Attention Mechanism](#attention-mechanism)
- [Transformer Architecture](#transformer-architecture)
- [Generative Pre-Training Transformer (GPT)](#generative-pre-training-transformer-gpt)
- [ChatGPT](#chatgpt)
- [Large Language Model (LLM)](#large-language-model-llm)
- [Transformer Reinforcement Learning](#transformer-reinforcement-learning)
- [Additional Reading](#additional-reading)
- [Educational](#educational)
- [Tutorials](#tutorials)
- [AI Safety](#ai-safety)
- [Videos](#videos)
- [BERTology](#bertology)
- [Attention and Transformer Networks](#attention-and-transformer-networks)
- [Official BERT Implementations](#official-bert-implementations)
- [Transformer Implementations By Communities](#transformer-implementations-by-communities)
- [PyTorch and TensorFlow](#pytorch-and-tensorflow)
- [PyTorch](#pytorch)
- [Keras](#keras)
- [TensorFlow](#tensorflow)
- [Chainer](#chainer)
- [Other](#other)
- [Transfer Learning in NLP](#transfer-learning-in-nlp)
- [Books](#books)
- [Other Resources](#other-resources)
- [Tools](#tools)
- [Tasks](#tasks)
- [Named-Entity Recognition (NER)](#named-entity-recognition-ner)
- [Classification](#classification)
- [Text Generation](#text-generation)
- [Question Answering (QA)](#question-answering-qa)
- [Knowledge Graph](#knowledge-graph)
---
## Papers
1. [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
2. [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, William W. Cohen, Jaime Carbonell, Quoc V. Le and Ruslan Salakhutdinov.
- Uses smart caching to improve the learning of long-term dependency in Transformer. Key results: state-of-art on 5 language modeling benchmarks, including ppl of 21.8 on One Billion Word (LM1B) and 0.99 on enwiki8. The authors claim that the method is more flexible, faster during evaluation (1874 times speedup), generalizes well on small datasets, and is effective at modeling short and long sequences.
2. [Conditional BERT Contextual Augmentation](https://arxiv.org/abs/1812.06705) by Xing Wu, Shangwen Lv, Liangjun Zang, Jizhong Han and Songlin Hu.
3. [SDNet: Contextualized Attention-based Deep Network for Conversational Question Answering](https://arxiv.org/pdf/1812.03593) by Chenguang Zhu, Michael Zeng and Xuedong Huang.
4. [Language Models are Unsupervised Multitask Learners](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
5. [The Evolved Transformer](https://arxiv.org/abs/1901.11117) by David R. So, Chen Liang and Quoc V. Le.
- They used architecture search to improve Transformer architecture. Key is to use evolution and seed initial population with Transformer itself. The architecture is better and more efficient, especially for small size models.
6. [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
- A new pretraining method for NLP that significantly improves upon BERT on 20 tasks (e.g., SQuAD, GLUE, RACE).
- "Transformer-XL is a shifted model (each hyper-column ends with next token) while XLNet is a direct model (each hyper-column ends with contextual representation of same token)." — [Thomas Wolf](https://twitter.com/Thom_Wolf/status/1141803437719506944?s=20).
- [Comments from HN](https://news.ycombinator.com/item?id=20229145):
A clever dual masking-and-caching algorithm.
- This is NOT "just throwing more compute" at the problem.
- The authors have devised a clever dual-masking-plus-caching mechanism to induce an attention-based model to learn to predict tokens from all possible permutations of the factorization order of all other tokens in the same input sequence.
- In expectation, the model learns to gather information from all positions on both sides of each token in order to predict the token.
- For example, if the input sequence has four tokens, ["The", "cat", "is", "furry"], in one training step the model will try to predict "is" after seeing "The", then "cat", then "furry".
- In another training step, the model might see "furry" first, then "The", then "cat".
- Note that the original sequence order is always retained, e.g., the model always knows that "furry" is the fourth token.
- The masking-and-caching algorithm that accomplishes this does not seem trivial to me.
- The improvements to SOTA performance in a range of tasks are significant -- see tables 2, 3, 4, 5, and 6 in the paper.
7. [CTRL: Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar, Richard Socher et al. [[Code](https://github.com/salesforce/ctrl)].
8. [PLMpapers](https://github.com/thunlp/PLMpapers) - BERT (Transformer, transfer learning) has catalyzed research in pretrained language models (PLMs) and has sparked many extensions. This repo contains a list of papers on PLMs.
9. [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Google Brain.
- The group perform a systematic study of transfer learning for NLP using a unified Text-to-Text Transfer Transformer (T5) model and push the limits to achieve SoTA on SuperGLUE (approaching human baseline), SQuAD, and CNN/DM benchmark. [[Code](https://git.io/Je0cZ)].
10. [Reformer: The Efficient Transformer](https://openreview.net/forum?id=rkgNKkHtvB) by Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya.
- "They present techniques to reduce the time and memory complexity of Transformer, allowing batches of very long sequences (64K) to fit on one GPU. Should pave way for Transformer to be really impactful beyond NLP domain." — @hardmaru
11. [Supervised Multimodal Bitransformers for Classifying Images and Text](https://arxiv.org/abs/1909.02950) (MMBT) by Facebook AI.
11. [A Primer in BERTology: What we know about how BERT works](https://arxiv.org/abs/2002.12327) by Anna Rogers et al.
- "Have you been drowning in BERT papers?". The group survey over 40 papers on BERT's linguistic knowledge, architecture tweaks, compression, multilinguality, and so on.
12. [tomohideshibata/BERT-related papers](https://github.com/tomohideshibata/BERT-related-papers)
13. [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by Google Brain. [[Code]](https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py) | [[Blog post (unofficial)]](https://syncedreview.com/2021/01/14/google-brains-switch-transformer-language-model-packs-1-6-trillion-parameters/)
- Key idea: the architecture use a subset of parameters on every training step and on each example. Upside: model train much faster. Downside: super large model that won't fit in a lot of environments.
14. [An Attention Free Transformer](https://arxiv.org/abs/2105.14103) by Apple.
15. [A Survey of Transformers](https://arxiv.org/abs/2106.04554) by Tianyang Lin et al.
16. [Evaluating Large Language Models Trained on Code](https://arxiv.org/abs/2107.03374) by OpenAI.
- Codex, a GPT language model that powers GitHub Copilot.
- They investigate their model limitations (and strengths).
- They discuss the potential broader impacts of deploying powerful code generation techs, covering safety, security, and economics.
17. [Training language models to follow instructions with human feedback](https://arxiv.org/abs/2203.02155) by OpenAI. They call the resulting models [InstructGPT](https://openai.com/blog/instruction-following/). [ChatGPT](https://openai.com/blog/chatgpt/) is a sibling model to InstructGPT.
18. [LaMDA: Language Models for Dialog Applications](https://arxiv.org/abs/2201.08239) by Google.
19. [Training Compute-Optimal Large Language Models](https://arxiv.org/abs/2203.15556) by Hoffmann et al. at DeepMind. TLDR: introduces a new 70B LM called "Chinchilla" that outperforms much bigger LMs (GPT-3, Gopher). DeepMind has found the secret to cheaply scale large language models — to be compute-optimal, model size and training data must be scaled equally. It shows that most LLMs are severely starved of data and under-trained. Given the [new scaling law](https://www.alignmentforum.org/posts/6Fpvch8RR29qLEWNH/chinchilla-s-wild-implications), even if you pump a quadrillion parameters into a model (GPT-4 urban myth), the gains will not compensate for 4x more training tokens.
20. [Improving language models by retrieving from trillions of tokens](https://arxiv.org/abs/2112.04426) by Borgeaud et al. at DeepMind - The group explore an alternate path for efficient training with Internet-scale retrieval. The method is known as RETRO, for "Retrieval Enhanced TRansfOrmers". With RETRO **the model is not limited to the data seen during training – it has access to the entire training dataset through the retrieval mechanism. This results in significant performance gains compared to a standard Transformer with the same number of parameters**. RETRO obtains comparable performance to GPT-3 on the Pile dataset, despite using 25 times fewer parameters. They show that language modeling improves continuously as they increase the size of the retrieval database. [[blog post](https://www.deepmind.com/blog/improving-language-models-by-retrieving-from-trillions-of-tokens)]
21. [Scaling Instruction-Finetuned Language Models](https://arxiv.org/abs/2210.11416) by Google - They find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks. Flan-PaLM 540B achieves SoTA performance on several benchmarks. They also publicly release [Flan-T5 checkpoints](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints), which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B.
22. [Emergent Abilities of Large Language Models](https://arxiv.org/abs/2206.07682) by Google Research, Stanford University, DeepMind, and UNC Chapel Hill.
23. [Nonparametric Masked (NPM) Language Modeling](https://arxiv.org/abs/2212.01349) by Meta AI et al. [[code](https://github.com/facebookresearch/NPM)] - Nonparametric models with **500x fewer parameters outperform GPT-3 on zero-shot tasks.**
> It, crucially, does not have a softmax over a fixed output vocabulary, but instead has a fully nonparametric distribution over phrases. This
is in contrast to a recent (2022) body of work that incorporates nonparametric components in a parametric model.
>
> Results show that NPM is significantly more parameter-efficient, outperforming up to 500x larger parametric models and up to 37x larger retrieve-and-generate models.
24. [Transformer models: an introduction and catalog](https://arxiv.org/abs/2302.07730) by Xavier Amatriain, 2023 - The goal of this paper is to offer a somewhat comprehensive but simple catalog and classification of the most popular Transformer models. The paper also includes an introduction to the most important aspects and innovation in Transformer models.
25. [Foundation Models for Decision Making: Problems, Methods, and Opportunities](https://arxiv.org/abs/2303.04129) by Google Research et al., 2023 - A report of recent approaches (i.e., conditional generative modeling, RL, prompting) that ground pre-trained models (i.e., LMs) in practical decision making agents. Models can serve world dynamics or steer decisions.
26. [GPT-4 Technical Report](https://cdn.openai.com/papers/gpt-4.pdf) by OpenAI, 2023.
27. [The Llama 3 Herd of Models](https://ai.meta.com/research/publications/the-llama-3-herd-of-models/) by Llama Team, AI @ Meta, Jul 2024 - The paper, a oft-overlooked component of the project, proved to be just as vital, if not more so, than the model itself, and its significance came as a complete surprise. A masterpiece in its own right, the paper presented a treasure trove of detailed information on the model's pre-training and post-training processes, offering insights that were both profound and practical. [[Discussion](https://old.reddit.com//r/LocalLLaMA/comments/1eabf4l)]
## Articles
### BERT and Transformer
1. [Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing](https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html) from Google AI.
2. [The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)](https://jalammar.github.io/illustrated-bert/).
3. [Dissecting BERT](https://medium.com/dissecting-bert) by Miguel Romero and Francisco Ingham - Understand BERT in depth with an intuitive, straightforward explanation of the relevant concepts.
3. [A Light Introduction to Transformer-XL](https://medium.com/dair-ai/a-light-introduction-to-transformer-xl-be5737feb13).
4. [Generalized Language Models](https://lilianweng.github.io/lil-log/2019/01/31/generalized-language-models.html) by Lilian Weng, Research Scientist at OpenAI.
5. [What is XLNet and why it outperforms BERT](https://towardsdatascience.com/what-is-xlnet-and-why-it-outperforms-bert-8d8fce710335)
- Permutation Language Modeling objective is the core of XLNet.
6. [DistilBERT](https://github.com/huggingface/pytorch-transformers/tree/master/examples/distillation) (from HuggingFace), released together with the blog post [Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT](https://medium.com/huggingface/distilbert-8cf3380435b5).
7. [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations paper](https://arxiv.org/abs/1909.11942v3) from Google Research and Toyota Technological Institute. — Improvements for more efficient parameter usage: factorized embedding parameterization, cross-layer parameter sharing, and Sentence Order Prediction (SOP) loss to model inter-sentence coherence. [[Blog post](https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html) | [Code](https://github.com/google-research/ALBERT)]
8. [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://openreview.net/forum?id=r1xMH1BtvB) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning - A BERT variant like ALBERT and cost less to train. They trained a model that outperforms GPT by using only one GPU; match the performance of RoBERTa by using 1/4 computation. It uses a new pre-training approach, called replaced token detection (RTD), that trains a bidirectional model while learning from all input positions. [[Blog post](https://ai.googleblog.com/2020/03/more-efficient-nlp-model-pre-training.html) | [Code](https://github.com/google-research/electra)]
9. [Visual Paper Summary: ALBERT (A Lite BERT)](https://amitness.com/2020/02/albert-visual-summary/)
10. [Cramming: Training a Language Model on a Single GPU in One Day (paper)](https://arxiv.org/abs/2212.14034) (2022) - While most in the community are asking how to push the limits of extreme computation, we ask the opposite question: How far can we get with a single GPU in just one day? ... Through the lens of scaling laws, we categorize a range of recent improvements to training and architecture and discuss their merit and practical applicability (or lack thereof) for the limited compute setting.
11. [What happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives](https://www.yitay.net/blog/model-architecture-blogpost-encoders-prefixlm-denoising) by Yi Tay, Jul 2024
> to recap, we don't see any scaled up xBERTs running around: BERT models got deprecated in favor of more flexible forms of denoising (autoregressive) T5 models. This is largely due to paradigm unification where people would like to perform any task with a general purpose model (as opposed to task specific model). Meanwhile, autoregressive denoising gets sometimes folded as side objectives to casual language models.
### Attention Mechanism
[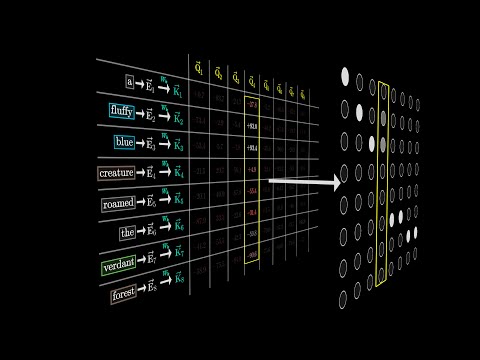](https://www.youtube.com/watch?v=eMlx5fFNoYc)
Visualizing Attention, a Transformer's Heart
1. [Neural Machine Translation by Jointly Learning to Align and Translate](https://arxiv.org/abs/1409.0473v1) by Dzmitry Bahdanau, KyungHyun Cho, and Yoshua Bengio, 2014 - [Bahdanau invented the content-based neural attention that is now a core tool in deep-learning-based NLP (language models)](https://archive.is/JxMmF#selection-99.0-103.76). A disadvantage of fixed-length context vector design is incapability of remembering long sentences. The attention mechanism was born to resolve this problem. It was born to help memorize long input sentences in language translation. [[Bahdanau deserve the praise](https://archive.is/3DwY5)]
2. [The Annotated Transformer by Harvard NLP Group](http://nlp.seas.harvard.edu/2018/04/03/attention.html) - Further reading to understand the "Attention is all you need" paper.
3. [Attention? Attention!](https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html) - Attention guide by Lilian Weng from OpenAI.
4. [Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)](https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/) by Jay Alammar, an Instructor from Udacity ML Engineer Nanodegree.
5. [Making Transformer networks simpler and more efficient](https://ai.facebook.com/blog/making-transformer-networks-simpler-and-more-efficient/) - FAIR released an all-attention layer to simplify the Transformer model and an adaptive attention span method to make it more efficient (reduce computation time and memory footprint).
6. [What Does BERT Look At? An Analysis of BERT’s Attention paper](https://arxiv.org/abs/1906.04341) by Stanford NLP Group.
7. [Fast Transformer Decoding: One Write-Head is All You Need (paper)](https://arxiv.org/abs/1911.02150) by Noam Shazeer, Google (2019) - They proposed a variant of attention type called **multi-query attention** (MQA). The plain multi-head attention mechanism has one query, key, and value per head; multi-query instead **shares one key and value across all of the different attention "heads"**. In practice, training time remains the same, but **much faster to decode in inference**. MQA significantly improves language models performance and efficiency. Users can get ~10x better throughput and ~30% lower latency on inference. However, MQA can lead to quality degradation, and moreover it may not be desirable to train a separate model just for faster inference. In 2022, PaLM, a decoder-style model and their use of MQA is an interesting architecture improvements over GPT. Recent models that use MQA include [TII's Falcon](https://falconllm.tii.ae/) (2023).
8. [GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints](https://arxiv.org/abs/2305.13245) by Google Research, 2023 - They (1) propose a **technique for uptraining existing multi-head attention (MHA) models into models with multi-query attention (MQA)** using 5% of original pre-training compute, and (2) introduce **grouped-query attention (GQA)**, a generalization of MQA which uses an intermediate (more than one, less than number of query heads) number of key-value heads. GQA achieves **benefits close to MHA** with **comparable inference speed to MQA** through reduced number of key-value heads. Models that use MQA include Meta's Llama 2 (2023). [[Some Tweets](https://twitter.com/_philschmid/status/1673335690912825347?s=20)]
9. [Ring Attention with Blockwise Transformers for Near-Infinite Context](https://arxiv.org/abs/2310.01889) by UC Berkeley, 2023 - Ring Attention is a system-level optimization technique by leveraging specific hardware architecture to make the exact attention computation more efficient.
10. [Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention](https://arxiv.org/abs/2404.07143) by Google, 2024 - Infini-attention has an additional compressive memory with linear attention for processing infinitely long contexts. They trained a 1B parameter Transformer model that was fine-tuned on up to 5K sequence length passkey instances solves the 1M tokens input length problem. The Infini-attention mechanism presents an efficient and powerful approach for Transformer language models to process very long contexts without prohibitive increases in memory or computation.
11. [Retrieval Head Mechanistically Explains Long-Context Factuality](https://arxiv.org/abs/2404.15574) by Wenhao Wu, Yao Fu et al., 2024 - The paper explains how LLMs actually deal with context windows. The findings: they discover LLMs have unexpectedly developed retrieval heads, they were not explicitly coded for by creators. [Code: [An algorithm that statistically calculate the retrieval score of attention heads in a transformer model](https://github.com/nightdessert/Retrieval_Head)]
### Transformer Architecture
1. [The Transformer blog post](https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html).
2. [The Illustrated Transformer](https://jalammar.github.io/illustrated-transformer/) by Jay Alammar, an Instructor from Udacity ML Engineer Nanodegree.
3. Watch [Łukasz Kaiser’s talk](https://www.youtube.com/watch?v=rBCqOTEfxvg) walking through the model and its details.
4. [Transformer-XL: Unleashing the Potential of Attention Models](https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html) by Google Brain.
5. [Generative Modeling with Sparse Transformers](https://openai.com/blog/sparse-transformer/) by OpenAI - an algorithmic improvement of the attention mechanism to extract patterns from sequences 30x longer than possible previously.
6. [Stabilizing Transformers for Reinforcement Learning](https://arxiv.org/abs/1910.06764) paper by DeepMind and CMU - they propose architectural modifications to the original Transformer and XL variant by moving layer-norm and adding gating creates Gated Transformer-XL (GTrXL). It substantially improve the stability and learning speed (integrating experience through time) in RL.
7. [The Transformer Family](https://lilianweng.github.io/lil-log/2020/04/07/the-transformer-family.html) by Lilian Weng - since the paper "Attention Is All You Need", many new things have happened to improve the Transformer model. This post is about that.
8. [DETR (**DE**tection **TR**ansformer): End-to-End Object Detection with Transformers](https://ai.facebook.com/blog/end-to-end-object-detection-with-transformers/) by FAIR - :fire: Computer vision has not yet been swept up by the Transformer revolution. DETR completely changes the architecture compared with previous object detection systems. ([PyTorch Code and pretrained models](https://github.com/facebookresearch/detr)). "A solid swing at (non-autoregressive) end-to-end detection. Anchor boxes + Non-Max Suppression (NMS) is a mess. I was hoping detection would go end-to-end back in ~2013)" — Andrej Karpathy
9. [Transformers for software engineers](https://blog.nelhage.com/post/transformers-for-software-engineers/) - This post will be helpful to software engineers who are interested in learning ML models, especially anyone interested in Transformer interpretability. The post walk through a (mostly) complete implementation of a GPT-style Transformer, but the goal will not be running code; instead, they use the language of software engineering and programming to explain how these models work and articulate some of the perspectives they bring to them when doing interpretability work.
10. [Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html) - PaLM is a dense decoder-only Transformer model trained with the Pathways system, which enabled Google to efficiently train a single model across multiple TPU v4 Pods. The example explaining a joke is remarkable. This shows that it can generate explicit explanations for scenarios that require a complex combination of multi-step logical inference, world knowledge, and deep language understanding.
11. [Efficient Long Sequence Modeling via State Space Augmented Transformer (paper)](https://arxiv.org/abs/2212.08136) by Georgia Institute of Technology and Microsoft - The quadratic computational cost of the attention mechanism limits its practicality for long sequences. There are existing attention variants that improve the computational efficiency, but they have limited ability to effectively compute global information. In parallel to Transformer models, state space models (SSMs) are tailored for long sequences, but they are not flexible enough to capture complicated local information. They propose SPADE, short for State sPace AugmenteD TransformEr, which performs various baselines, including Mega, on the Long Range Arena benchmark and various LM tasks. This is an interesting direction. SSMs and Transformers were combined a while back.
12. [DeepNet: Scaling Transformers to 1,000 Layers (paper)](https://arxiv.org/abs/2203.00555) by Microsoft Research (2022) - The group introduced a **new normalization function (DEEPNORM)** to modify the residual connection in Transformer and showed that model updates can be bounded in a **stable way**. This improve the training stability of deep Transformers and scale the model depth by orders of magnitude (10x) compared to Gpipe (pipeline parallelism) by Google Brain (2019). (who remembers what ResNet (2015) did to ConvNet?)
13. [A Length-Extrapolatable Transformer (paper)](https://arxiv.org/abs/2212.10554) by Microsoft (2022) [[TorchScale code](https://github.com/microsoft/torchscale)] - This improves **modeling capability** of scaling Transformers.
14. [Hungry Hungry Hippos (H3): Towards Language Modeling with State Space Models (SSMs) (paper)](https://arxiv.org/abs/2212.14052) by Stanford AI Lab (2022) - A new language modeling architecture. It **scales nearly linearly with context size instead of quadratically**. No more fixed context windows, long context for everyone. Despite that, SSMs are still slower than Transformers due to poor hardware utilization. So, a Transformer successor? [[Tweet](https://twitter.com/realDanFu/status/1617605971395891201)]
15. [Accelerating Large Language Model Decoding with Speculative Sampling (paper)](https://arxiv.org/abs/2302.01318) by DeepMind (2023) - Speculative sampling algorithm enable the generation of multiple tokens from each transformer call. Achieves a 2–2.5x decoding speedup with Chinchilla in a distributed setup, without compromising the sample quality or making modifications to the model itself.
16. [A Survey on Efficient Training of Transformers (paper)](https://arxiv.org/abs/2302.01107) by Monash University et al., 2023 - The first systematic overview, covering 1) computation efficiency; optimization (i.e., sparse training) and data selection (i.e., token masking), 2) memory efficiency (i.e, data/model parallelism, offloading/use external mem) and 3) hardware/algorithm co-design (i.e, efficient attention, hardware-aware low-precisio).
17. [Deep Transformers without Shortcuts: Modifying Self-attention for Faithful Signal Propagation (paper)](https://arxiv.org/abs/2302.10322) by DeepMind et al., 2023
18. [Hyena Hierarchy: Towards Larger Convolutional Language Models (paper)](https://arxiv.org/abs/2302.10866) by Stanford U et al., 2023 - Attention is great. Hyena is an alternative to attention that can learn on sequences **10x longer**, up to **100x faster** than optimized attention, by using implicit long convolutions and gating. [[Tweet](https://twitter.com/MichaelPoli6/status/1633167040130453505)]
19. [FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (paper)](https://arxiv.org/abs/2205.14135) by Stanford University et al., 2022 - Transformers have grown deeper and wider, but training them on long sequences remains difficult. The attention layer at their heart is the compute and memory bottleneck: doubling the sequence length would quadruple the runtime and memory requirements. FlashAttention is a new algorithm to speed up attention and reduce its memory footprint—without any approximation. It enables training LLMs with longer context. [[code](https://github.com/HazyResearch/flash-attention)]
20. [Jump to Conclusions: Short-Cutting Transformers With Linear Transformations (paper)](https://arxiv.org/abs/2303.09435v1) by Google Research et al., 2023. [[Tweet](https://twitter.com/LChoshen/status/1637799047430905856)]
21. [CoLT5: Faster Long-Range Transformers with Conditional Computation (paper)](https://arxiv.org/abs/2303.09752) by Google Research, 2023 - 64K context size for language models! This approach enables faster training and inference while maintaining or improving performance compared to LONGT5. The main components of COLT5 include routing modules, conditional feedforward layers, and conditional attention layers. Routing modules select important tokens for each input and component, while the light branches process all tokens with lower capacity operations, and heavy branches apply higher capacity operations only on selected important tokens. Additionally, COLT5 incorporates multi-query cross-attention for faster inference speed as well as UL2 pre-training objective for improved in-context learning capabilities over long inputs. [[Tweet](https://twitter.com/miolini/status/1637677536921657344)]
22. [google-research/meliad](https://github.com/google-research/meliad) - The Meliad library is collection of models which are being developed as part of ongoing Google research into various architectural improvements in deep learning. The library currently consists of several transformer variations, which explore ways in which the popular transformer architecture can be extended to better support language modeling over long sequences. The variations are Memorizing Transformer, Transformer with sliding window, Block-Recurrent Transformer, and more.
23. [LongNet: Scaling Transformers to 1,000,000,000 Tokens (paper)](https://arxiv.org/abs/2307.02486) by Microsoft Research, 2023.
24. [vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention](https://vllm.ai/) by UC Berkeley et al., 2023 - The improved throughput comes from VRAM savings on an otherwise close to fullly utilized GPU.
25. [The Secret Sauce behind 100K context window in LLMs: all tricks in one place](https://blog.gopenai.com/how-to-speed-up-llms-and-use-100k-context-window-all-tricks-in-one-place-ffd40577b4c)
26. [Unlimiformer: Long-Range Transformers with Unlimited Length Input (paper)](https://arxiv.org/abs/2305.01625) by CMU, 2023.
27. [PaLM 2 Technical Report (PDF)](https://ai.google/static/documents/palm2techreport.pdf) by Google, 2023.
28. [Mixture-of-Depths (MoD): Dynamically allocating compute in transformer-based language models](https://arxiv.org/abs/2404.02258) by Google DeepMind et al., 2024 - MoD method scale in depth dimension while keeping the FLOPs constant (similarly how Mixture of Experts (MoE) does it in width). MoD model can learn to route more complex tokens through more layers (similarly how experts in MoE can specialize to certain domains). The group explores how to optimize compute budget and improve efficiency without sacrificing performance. Results: MoD matches baseline performance with 66% faster training. Now, the question is, can it scale above 1B tokens. They tested on 500M tokens. [ELI5 version: [Mixture of Depths Meets Mixture of Experts](https://lifeinthesingularity.com/p/googles-breakthroughs-in-ai-design)]
29. [Extending Context Window of Large Language Models via Positional Interpolation](https://arxiv.org/abs/2306.15595) by Meta Platforms, 2023 - Position Interpolation (PI) is an effective and efficient way to stably extend the context window of RoPE-based pretrained large language models such as LLaMA to much longer lengths (up to 32768) with minimal fine-tuning (within thousandth steps) while maintaining performance.
30. [PoSE: Efficient Context Window Extension of LLMs via Positional Skip-wise Training](https://arxiv.org/abs/2309.10400) by Dawei Zhu et al., ICLR 2024 - PoSE simulates longer input sequences during training by manipulating the position indices within a fixed context window, rather than training on the full target length. This allows decoupling of the training length from the target context length, greatly reducing memory and computational requirements compared to full-length fine-tuning. PoSE successfully extended LLaMA-1 to support context lengths up to 128k tokens using only a 2k training window, with minimal performance degradation. [This model](https://huggingface.co/winglian/Llama-3-8b-64k-PoSE) uses PoSE to extend Llama-3 8B context length from 8k to 64k. PoSE has potential to scale context lengths even further, limited only by inference memory, as efficient inference techniques continue improving. [Code: [PoSE](https://github.com/dwzhu-pku/PoSE)]
31. [Better & Faster Large Language Models via Multi-token Prediction](https://arxiv.org/abs/2404.19737) by FAIR at Meta, Apr 2024 - What happens if we make language models predict several tokens ahead instead of only the next one? They show that replacing next token prediction tasks with multiple token prediction can result in substantially better code generation performance **with the exact same training budget and data — while also increasing inference performance by 3x**. While similar approaches have previously been used in fine-tuning to improve inference speed, **this research expands to pre-training for large models, showing notable behaviors and results at these scales**.
32. [nGPT: Normalized Transformer with Representation Learning on the Hypersphere](https://arxiv.org/abs/2410.01131) by NVIDIA, Oct 2024 - A novel Transformer architecture where all vectors (embeddings, MLP, attention matrices, hidden states) are normalized to unit norm and operate on a hypersphere. Achieves 4-20x faster convergence during training compared to standard Transformers. Eliminates the need for weight decay by enforcing normalization. Normalization approach: matrix-vector multiplications become dot products bounded in [-1,1]. Architecture changes: 1) Attention mechanism - normalizes QKV projection matrices, introduces trainable scaling factors for Q-K dot products, 2) Layer structure: introduces learnable "eigen learning rates" (α) for attention and MLP blocks. Theoretical: can be interpreted in the context of Riemannian optimization. Advantages: more stable training, improved performance on downstream tasks, simplified architecture.
33. [Differential Transformer](https://arxiv.org/abs/2410.05258) by Microsoft Research et al., Oct 2024 - They presents **significant improvements over standard Transformers** in multiple dimensions, with particular emphasis on attention efficiency and practical applications in LM tasks. A new architecture that improves attention mechanisms by reducing attention to irrelevant context. Achieves better performance while requiring fewer parameters and training tokens compared to standard Transformers. Solution: introduces "differential attention" mechanism that calculates attention scores as the difference between two separate softmax attention. This subtraction cancel out noise. It can be implemented efficiently using existing FlashAttention. Scaling efficiency: **needs only ~65% of parameters or training tokens to match standard Transformer performance**. Improvements: 1) Better performance on long sequences up to 64K tokens. 2) Better at finding key information embedded in documents. 3) ICL: more robust to prompt order permutations. 4) Reduces attention misallocation, a primary cause of hallucinations. Technical details: includes headwise normalization to handle sparse attention patterns, etc. Future: development of efficient low-bit attention kernels, potential for compressing KV caches due to sparser attention patterns, etc. [Listen to [NotebookLM podcast](https://notebooklm.google.com/notebook/8e4c0907-8b12-4bc9-9d29-26c03daab71d/audio)]
### Generative Pre-Training Transformer (GPT)
[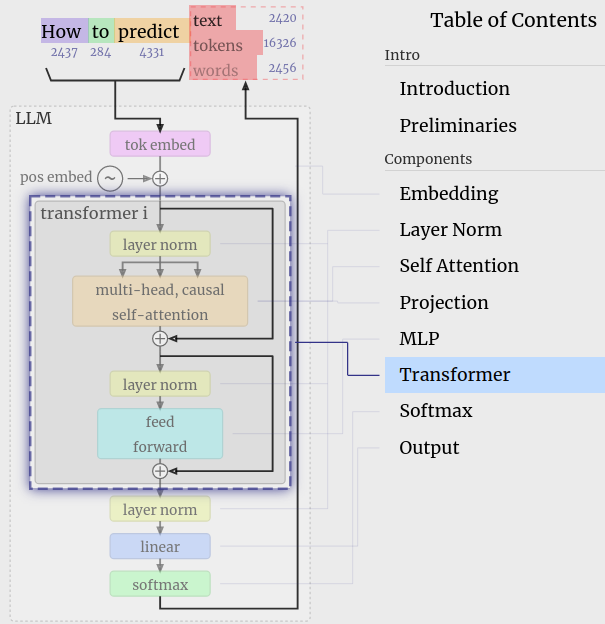](https://bbycroft.net/llm)
GPT visualization
1. [Better Language Models and Their Implications](https://openai.com/blog/better-language-models/).
2. [Improving Language Understanding with Unsupervised Learning](https://blog.openai.com/language-unsupervised/) - this is an overview of the original OpenAI GPT model.
3. [🦄 How to build a State-of-the-Art Conversational AI with Transfer Learning](https://convai.huggingface.co/) by Hugging Face.
4. [The Illustrated GPT-2 (Visualizing Transformer Language Models)](https://jalammar.github.io/illustrated-gpt2/) by Jay Alammar.
5. [MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism](https://nv-adlr.github.io/MegatronLM) by NVIDIA ADLR.
6. [OpenGPT-2: We Replicated GPT-2 Because You Can Too](https://medium.com/@vanya_cohen/opengpt-2-we-replicated-gpt-2-because-you-can-too-45e34e6d36dc) - the authors trained a 1.5 billion parameter GPT-2 model on a similar sized text dataset and they reported results that can be compared with the original model.
7. [MSBuild demo of an OpenAI generative text model generating Python code](https://www.youtube.com/watch?v=fZSFNUT6iY8) [video] - The model that was trained on GitHub OSS repos. The model uses English-language code comments or simply function signatures to generate entire Python functions. Cool!
8. [GPT-3: Language Models are Few-Shot Learners (paper)](https://arxiv.org/abs/2005.14165) by Tom B. Brown (OpenAI) et al. - "We train GPT-3, an autoregressive language model with 175 billion parameters :scream:, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting."
9. [elyase/awesome-gpt3](https://github.com/elyase/awesome-gpt3) - A collection of demos and articles about the OpenAI GPT-3 API.
10. [How GPT3 Works - Visualizations and Animations](https://jalammar.github.io/how-gpt3-works-visualizations-animations/) by Jay Alammar.
11. [GPT-Neo](https://www.eleuther.ai/projects/gpt-neo/) - Replicate a GPT-3 sized model and open source it for free. GPT-Neo is "an implementation of model parallel GPT2 & GPT3-like models, with the ability to scale up to full GPT3 sizes (and possibly more!), using the mesh-tensorflow library." [[Code](https://github.com/EleutherAI/gpt-neo)].
12. [GitHub Copilot](https://copilot.github.com/), powered by OpenAI Codex - Codex is a descendant of GPT-3. Codex translates natural language into code.
13. [GPT-4 Rumors From Silicon Valley](https://thealgorithmicbridge.substack.com/p/gpt-4-rumors-from-silicon-valley) - GPT-4 is almost ready. GPT-4 would be multimodal, accepting text, audio, image, and possibly video inputs. Release window: Dec - Feb. #hype
14. [New GPT-3 model: text-Davinci-003](https://beta.openai.com/docs/models/davinci) - Improvements:
- Handle more complex intents — you can get even more creative with how you make use of its capabilities now.
- Higher quality writing — clearer, more engaging, and more compelling content.
- Better at longer form content generation.
15. [GPT-4 research](https://openai.com/research/gpt-4) landing page.
16. [A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models](https://arxiv.org/abs/2303.10420) by Fudan University et al., 2023.
17. [Sparks of Artificial General Intelligence: Early experiments with GPT-4](https://arxiv.org/abs/2303.12712) by Microsoft Research, 2023 - There are completely mind-blowing examples in the paper.
#### ChatGPT
[What is ChatGPT?](https://openai.com/blog/chatgpt/)
**TL;DR:** ChatGPT is a conversational web interface, backed by OpenAI's newest language model fine-tuned from a model in the [GPT-3.5 series](https://beta.openai.com/docs/model-index-for-researchers) (which finished training in early 2022), optimized for dialogue. It is trained using Reinforcement Learning from Human Feedback (RLHF); human AI trainers provide supervised fine-tuning by playing both sides of the conversation.
It's evidently better than GPT-3 at following user instructions and context. [People have noticed](https://archive.ph/m6AOQ) ChatGPT's output quality seems to represent a notable improvement over previous GPT-3 models.
For more, please take a look at [ChatGPT Universe](https://github.com/cedrickchee/chatgpt-universe). This is my fleeting notes on everything I understand about ChatGPT and stores a collection of interesting things about ChatGPT.
### Large Language Model (LLM)

ChatGPT among the LLMs [^1]
1. [GPT-J-6B](https://towardsdatascience.com/cant-access-gpt-3-here-s-gpt-j-its-open-source-cousin-8af86a638b11) - Can't access GPT-3? Here's GPT-J — its open-source cousin.
2. [Fun and Dystopia With AI-Based Code Generation Using GPT-J-6B](https://minimaxir.com/2021/06/gpt-j-6b/) - Prior to GitHub Copilot tech preview launch, Max Woolf, a data scientist tested GPT-J-6B's code "writing" abilities.
3. [GPT-Code-Clippy (GPT-CC)](https://github.com/CodedotAl/gpt-code-clippy) - An open source version of GitHub Copilot. The GPT-CC models are fine-tuned versions of GPT-2 and GPT-Neo.
4. [GPT-NeoX-20B](https://blog.eleuther.ai/announcing-20b/) - A 20 billion parameter model trained using EleutherAI’s [GPT-NeoX](https://github.com/EleutherAI/gpt-neox) framework. They expect it to perform well on many tasks. You can try out the model on [GooseAI](https://goose.ai/) playground.
5. [Metaseq](https://github.com/facebookresearch/metaseq) - A codebase for working with [Open Pre-trained Transformers (OPT)](https://arxiv.org/abs/2205.01068).
6. [YaLM 100B](https://github.com/yandex/YaLM-100B) by Yandex is a GPT-like pretrained language model with 100B parameters for generating and processing text. It can be used **freely** by developers and researchers from all over the world.
7. [BigScience's BLOOM-176B](https://huggingface.co/bigscience/bloom) from the Hugging Face repository [[paper](https://arxiv.org/abs/2210.15424), [blog post](https://bigscience.huggingface.co/blog/bloom)] - BLOOM is a 175-billion parameter model for language processing, able to generate text much like GPT-3 and OPT-175B. It was developed to be multilingual, being deliberately trained on datasets containing 46 natural languages and 13 programming languages.
8. [bitsandbytes-Int8 inference for Hugging Face models](https://docs.google.com/document/d/1JxSo4lQgMDBdnd19VBEoaG-mMfQupQ3XvOrgmRAVtpU/edit) - You can run BLOOM-176B/OPT-175B easily on a single machine, without performance degradation. If true, this could be a game changer in enabling people outside of big tech companies being able to use these LLMs.
9. [WeLM: A Well-Read Pre-trained Language Model for Chinese (paper)](https://arxiv.org/abs/2209.10372) by WeChat. [[online demo](https://welm.weixin.qq.com/docs/playground/)]
10. [GLM-130B: An Open Bilingual (Chinese and English) Pre-Trained Model (code and paper)](https://github.com/THUDM/GLM-130B) by Tsinghua University, China [[article](https://keg.cs.tsinghua.edu.cn/glm-130b/posts/glm-130b/)] - One of the major contributions is making LLMs cost affordable using int4 quantization so it can run in limited compute environments.
> The resultant GLM-130B model offers **significant outperformance over GPT-3 175B** on a wide range of popular English benchmarks while the performance advantage is not observed in OPT-175B and BLOOM-176B. It also consistently and significantly outperforms ERNIE TITAN 3.0 260B -- the largest Chinese language model -- across related benchmarks. Finally, we leverage **a unique scaling property of GLM-130B to reach INT4 quantization, without quantization aware training and with almost no performance loss**, making it the first among 100B-scale models. **More importantly, the property allows its effective inference on 4×RTX 3090 (24G) or 8×RTX 2080 Ti (11G) GPUs, the most ever affordable GPUs required for using 100B-scale models**.
11. [Teaching Small Language Models to Reason (paper)](https://arxiv.org/abs/2212.08410) - They finetune a student model on the chain of thought (CoT) outputs generated by a larger teacher model. For example, the **accuracy of T5 XXL on GSM8K improves from 8.11% to 21.99%** when finetuned on PaLM-540B generated chains of thought.
12. [ALERT: Adapting Language Models to Reasoning Tasks (paper)](https://arxiv.org/abs/2212.08286) by Meta AI - They introduce ALERT, a benchmark and suite of analyses for assessing language models' reasoning ability comparing pre-trained and finetuned models on complex tasks that require reasoning skills to solve. It covers 10 different reasoning skills including logistic, causal, common-sense, abductive, spatial, analogical, argument and deductive reasoning as well as textual entailment, and mathematics.
13. [Evaluating Human-Language Model Interaction (paper)](https://arxiv.org/abs/2212.09746) by Stanford University and Imperial College London - They find that non-interactive performance does not always result in better human-LM interaction and that first-person and third-party metrics can diverge, suggesting the importance of examining the nuances of human-LM interaction.
14. [Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor (paper)](https://arxiv.org/abs/2212.09689) by Meta AI [[data](https://github.com/orhonovich/unnatural-instructions)] - Fine-tuning a T5 on a large dataset collected with virtually no human labor leads to a model that surpassing the performance of models such as T0++ and Tk-Instruct across various benchmarks. These results demonstrate the potential of model-generated data as a **cost-effective alternative to crowdsourcing for dataset expansion and diversification**.
15. [OPT-IML (OPT + Instruction Meta-Learning) (paper)](https://raw.githubusercontent.com/facebookresearch/metaseq/main/projects/OPT-IML/optimal_paper_v1.pdf) by Meta AI - OPT-IML is a set of instruction-tuned versions of OPT, on a collection of ~2000 NLP tasks — for research use cases. It boosts the performance of the original OPT-175B model using instruction tuning to improve zero-shot and few-shot generalization abilities — allowing it to adapt for more diverse language applications (i.e., answering Q’s, summarizing text). This improves the model's ability to better process natural instruction style prompts. Ultimately, humans should be able to "talk" to models as naturally and fluidly as possible. [[code (available soon), weights released](https://github.com/facebookresearch/metaseq/tree/main/projects/OPT-IML)]
16. [jeffhj/LM-reasoning](https://github.com/jeffhj/LM-reasoning) - This repository contains a collection of papers and resources on reasoning in Large Language Models.
17. [Rethinking with Retrieval: Faithful Large Language Model Inference (paper)](https://arxiv.org/abs/2301.00303) by University of Pennsylvania et al., 2022 - They shows the potential of enhancing LLMs by retrieving relevant external knowledge based on decomposed reasoning steps obtained through chain-of-thought (CoT) prompting. I predict we're going to see many of these types of retrieval-enhanced LLMs in 2023.
18. [REPLUG: Retrieval-Augmented Black-Box Language Models (paper)](https://arxiv.org/abs/2301.12652) by Meta AI et al., 2023 - TL;DR: Enhancing GPT-3 with world knowledge — a retrieval-augmented LM framework that combines a frozen LM with a frozen/tunable retriever. It improves GPT-3 in language modeling and downstream tasks by prepending retrieved documents to LM inputs. [[Tweet](https://twitter.com/WeijiaShi2/status/1620497381962977281)]
19. [Progressive Prompts: Continual Learning for Language Models (paper)](https://arxiv.org/abs/2301.12314) by Meta AI et al., 2023 - Current LLMs have hard time with catastrophic forgetting and leveraging past experiences. The approach learns a prompt for new task and concatenates with frozen previously learned prompts. This efficiently transfers knowledge to future tasks. [[code](https://github.com/arazd/ProgressivePrompts)]
20. [Large Language Models Can Be Easily Distracted by Irrelevant Context (paper)](https://arxiv.org/abs/2302.00093) by Google Research et al., 2023 - Adding the instruction "Feel free to ignore irrelevant information given in the questions." consistently improves robustness to irrelevant context.
21. [Toolformer: Language Models Can Teach Themselves to Use Tools (paper)](https://arxiv.org/abs/2302.04761) by Meta AI, 2023 - A smaller model trained to translate human intention into actions (i.e. decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction).
22. [ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation (paper)](https://arxiv.org/abs/2112.12731) by Baidu et al., 2021 - ERNIE 3.0 Titan is the latest addition to Baidu's ERNIE (Enhanced Representation through kNowledge IntEgration) family. It's inspired by the masking strategy of Google's BERT. ERNIE is also a unified framework. They also proposed a controllable learning algorithm and a credible learning algorithm. They apply online distillation technique to compress their model. To their knowledge, it is the largest (260B parameters) Chinese dense pre-trained model so far. [[article](http://research.baidu.com/Blog/index-view?id=165)]
23. [Characterizing Attribution and Fluency Tradeoffs for Retrieval-Augmented Large Language Models (paper)](https://arxiv.org/abs/2302.05578) by Google Research, 2023 - Despite recent progress, it has been difficult to prevent semantic hallucinations in generative LLMs. One common solution to this is augmenting LLMs with a retrieval system and making sure that the generated output is attributable to the retrieved information.
24. [Augmented Language Models (ALMs): a Survey (paper)](https://arxiv.org/abs/2302.07842) by Meta AI, 2023 - Augmenting language models with reasoning skills and the ability to use various, non-parametric external modules for context processing and outperform traditional LMs on several benchmarks. This new research direction has the potential to address interpretability, consistency and scalability issues.
25. [A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT (paper)](https://arxiv.org/abs/2302.09419) by MSU et al., 2023 - My remarks: this paper raises a lot of questions around the term "foundation models", i.e., what's the model bare minimum number of parameters to qualify as foundation? It sounds to me foundation models are an "invented" concept that doesn't have good validity.
26. [Multimodal Chain-of-Thought Reasoning in Language Models (paper)](https://arxiv.org/abs/2302.00923) by Amazon Web Service et al., 2023 - The model outperform GPT-3.5 by 16% on the ScienceQA benchmark. This work is the first to study CoT reasoning in different modalities, language (text) and vision (images). Unfortunately, they never provide ablation study on how much of that performance gain was caused by the new modalities. [[code](https://github.com/amazon-science/mm-cot)]
27. [RECITE: Recitation-Augmented Language Models (paper)](https://arxiv.org/abs/2210.01296) by Google Research et al., ICLR 2023 - How can ChatGPT-like models achieve greater factual accuracy without relying on an external retrieval search engine? This paper shows that recitation can help LLMs generate accurate factual knowledge by reciting relevant passages from their own memory (by sampling) before producing final answers. The core idea is motivated by the intuition: recite-step that recollects relevant knowledge pieces helps answer-step (generation) better output. That's a recite-answer paradigm: first ask the LLM to generate the support paragraphs that contain the answer (knowledge-recitation) and then use it as additional prompt, along with the question to ask the LLM to generate the answer. They verify the effectiveness on four LLMs. They also show that recitation can be more effective than retrieval. This is important since having a retriever may lead to unpredictable behavior (i.e., Bing/Sydney). [[code](https://github.com/Edward-Sun/RECITE)]
28. [LLaMA: Open and Efficient Foundation Language Models (paper)](https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/) by Meta AI, 2023 - A collection of language models ranging from 7B to 65B parameters. LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla70B and PaLM-540B. This shows that **smaller models trained with more data can outperform larger models**. This is **not contradictory to anything in the Chinchilla paper**, because it's not compute-optimally trained. GPU hours for training 7B model=82,432, 65B model=1,022,362 :scream:. Total time spent for all models: 2048 A100-80GB GPU for a period of approximately 5 months. The 65B model cost something in the range of ~$1-4M. Access to the model will be granted on a case-by-case basis though. People interested can apply for access. (Mar 2: [they just approved access to the models](https://twitter.com/cedric_chee/status/1631182890418712578), llama-7B works in Colab [cedrickchee/llama](https://github.com/cedrickchee/llama/blob/main/notebooks/vi_LLaMA_alpha.ipynb)) [Takeaways: [Tweet](https://threadreaderapp.com/thread/1629496763148017665.html)]
29. [Language Is Not All You Need: Aligning Perception with Language Models (paper)](https://arxiv.org/abs/2302.14045) by Microsoft, 2023 - They introduce KOSMOS-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot). The total number of parameters is about 1.6B.
30. [Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback](https://arxiv.org/abs/2302.12813) by Microsoft Research et al - LLM-Augmenter significantly reduces ChatGPT's hallucinations without sacrificing the fluency and informativeness of its responses. The architecture and data flow: 1) Retrieve evidence from external knowledge. 2) Context and reasoning chains. 3) Give to LLM (i.e., ChatGPT). 4) Verify hallucinations. 5) If hallucinate, give feedback and revise.
31. [UL2: Unifying Language Learning Paradigms (paper)](https://arxiv.org/abs/2205.05131) by Google Brain, 2022 - UL2 is a unified framework for pretraining models that are universally effective across datasets and setups. _Takeaways: Objective matters way more than architecture. Mixture-of-Denoisers (MoD) is effective if you care about doing well on more than one type of tasks/settings._ UL2 frames different objective functions for training language models as denoising tasks, where the model has to recover missing sub-sequences of a given input. During pre-training it uses Mixture-of-Denoisers (MoD) that samples from a varied set of such objectives, each with different configurations. MoD combines diverse pre-training paradigms together. They demonstrated that models trained using the UL2 framework perform well in a variety of language domains, including prompt-based few-shot learning and models fine-tuned for down-stream tasks. They open sourced UL2 20B model and checkpoints back in 2022. In 2023, they open sourced Flan-UL2 20B and released the weights. Check out: [[blog post](https://archive.is/20230303191656/https://www.yitay.net/blog/flan-ul2-20b), [Tweet](https://twitter.com/YiTayML/status/1631359474421366784)]. I'm excited to see what the community does with this new model.
32. [Larger language models do in-context learning (ICL) differently (paper)](https://arxiv.org/abs/2303.03846) by Google Research, 2023 - Overriding semantic priors when presented with enough flipped labels is an emergent ability of scale. LLMs learn better mappings when ICL labels are semantically unrelated to inputs (i.e., apple/orange, negative/positive). Fine-tuning to follow instruction helps both. [[Tweet](https://twitter.com/JerryWeiAI/status/1633548780619571200)]
33. [The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset (paper)](https://arxiv.org/abs/2303.03915) by Hugging Face et al., 2023 - Documents the data creation and curation efforts of Responsible Open-science Open-collaboration Text Source (ROOTS) corpus, a dataset used to train BLOOM. [[Tweet](https://twitter.com/arankomatsuzaki/status/1633282997020672000)]
34. [PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing (paper)](https://arxiv.org/abs/2303.10845) by Huawei Technologies, 2023 - They develop a system that trained a trillion-parameter language model on a cluster of Ascend 910 AI processors and MindSpore framework. This resulted in a 6.3x increase in training throughput through heterogeneous computing.
35. [Context-faithful Prompting for Large Language Models (paper)](https://arxiv.org/abs/2303.11315) by USC et al., 2023
36. [Llama 2: Open Foundation and Fine-Tuned Chat Models (paper)](https://arxiv.org/abs/2307.09288) by Meta AI, 2023 - Llama 2 pretrained models are trained on 2 trillion tokens, and have double the context length than Llama 1. Its fine-tuned models have been trained on over 1 million human annotations. It outperforms other open source language models on many benchmarks. License: The model and weights are available for free for research and commercial use. It is not an open source model, rather an open approach model — for commercial use, your product cannot have more than 700 million monthly active users and requires a form to get access. Llama-2-chat is the new addition and is created through using supervised fine-tuning and then iteratively refined using RLHF. [[Nathan Lambert's summary of the paper](https://www.interconnects.ai/p/llama-2-from-meta)]
37. [Code Llama: Open Foundation Models for Code (paper)](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Meta AI, 2023 - Code Llama is a family of LLMs for code based on Llama 2 providing SoTA performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. It is capable of generating code, and natural language about code, from both code and natural language prompts. It's available in three models: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. It outperformed publicly available LLMs benchmark on code tasks. They release it under the same permissive license (community license) as Llama 2.
38. [Introducing Llama 3: The most capable openly available LLM to date (article)](https://ai.meta.com/blog/meta-llama-3/) by Meta AI, 2024 - In the coming months, they’ll share the Llama 3 research paper. [[Code](https://github.com/meta-llama/llama3)]
39. [Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context](https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf) by Google, May 2024 - The Gemini 1.5 model family technical report. Highlights: Gemini 1.5 Pro is now Google's most capable model (surpassing 1.0 Ultra), Gemini 1.5 models achieve near-perfect recall on long-context retrieval tasks across modalities, improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens.
### Transformer Reinforcement Learning
Transformer Reinforcement Learning from Human Feedback (RLHF).
- [Illustrating Reinforcement Learning from Human Feedback](https://huggingface.co/blog/rlhf) - Recent advances with language models (ChatGPT for example) have been powered by RLHF.
- [Training a Helpful and Harmless Assistant with RLHF (paper)](https://arxiv.org/abs/2204.05862) by Anthropic. [[code and red teaming data](https://huggingface.co/datasets/Anthropic/hh-rlhf), [tweet](https://twitter.com/anthropicai/status/1514277273070825476)]
- [The Wisdom of Hindsight Makes Language Models Better Instruction Followers (paper)](https://arxiv.org/abs/2302.05206) by UC Berkeley, 2023 - The underlying RLHF algo is complex and requires an additional training pipeline for reward and value networks. They consider an alternative approach, Hindsight Instruction Relabeling (HIR): converting feedback to instruction by relabeling the original one and training the model for better alignment.
- [From r to Q∗: Your Language Model is Secretly a Q-Function](https://arxiv.org/abs/2404.12358) by Stanford University, Apr 2024 - The paper bridges the gap between two approaches to RLHF - the standard RLHF setup and Direct Preference Optimization (DPO) - by deriving DPO as a general inverse Q-learning algorithm in a token-level MDP (Markov Decision Process). The authors provide empirical insights into the benefits of DPO, including its ability to perform credit assignment, and demonstrate improvements over the base DPO policy using simple beam search, with **potential applications in multi-turn dialogue, reasoning, and agentic systems**.
- [Iterative Reasoning Preference Optimization (IRPO)](https://arxiv.org/abs/2404.19733) by Jason Weston (Meta) et al., May 2024 - Llama-2-70B-Chat improves **from 55.6% to 81.6% on GSM8K** with this method. They apply iterative preference optimization to improve reasoning: generate chain-of-thought candidates with LLM, construct preference pairs based on if answer is correct or not, train with DPO + NLL, and repeat. For example, imagine a group of people trying to decide how to allocate a limited budget. Each person has their own priorities and preferences for how the money should be spent. Using the IRPO approach, the group would engage in a back-and-forth discussion, with each person adjusting their preferences based on the arguments and compromises made by the others. Over time, the group would converge on a set of preferences that everyone can accept, even if it's not exactly what any one person wanted initially.
#### Tools for RLHF
- [lvwerra/TRL](https://github.com/lvwerra/trl) - Train transformer language models with reinforcement learning.
Open source effort towards ChatGPT:
- [CarperAI/TRLX](https://github.com/CarperAI/trlx) - Originated as a fork of TRL. It allows you to fine-tune Hugging Face language models (GPT2, GPT-NeoX based) up to 20B parameters using Reinforcement Learning. Brought to you by CarperAI (born at EleutherAI, an org part of StabilityAI family). CarperAI is developing production ready open-source RLHF tools. They have [announced plans for the first open-source "instruction-tuned" LM](https://carper.ai/instruct-gpt-announcement/).
- [allenai/RL4LMs](https://github.com/allenai/RL4LMs) - RL for language models (RL4LMs) by Allen AI. It's a modular RL library to fine-tune language models to human preferences.
### Additional Reading
1. [How to Build OpenAI's GPT-2: "The AI That's Too Dangerous to Release"](https://www.reddit.com/r/MachineLearning/comments/bj0dsa/d_how_to_build_openais_gpt2_the_ai_thats_too/).
2. [OpenAI’s GPT2 - Food to Media hype or Wake Up Call?](https://www.skynettoday.com/briefs/gpt2)
3. [How the Transformers broke NLP leaderboards](https://hackingsemantics.xyz/2019/leaderboards/) by Anna Rogers. :fire::fire::fire:
- A well put summary post on problems with large models that dominate NLP these days.
- Larger models + more data = progress in Machine Learning research :question:
4. [Transformers From Scratch](http://www.peterbloem.nl/blog/transformers) tutorial by Peter Bloem.
5. [Real-time Natural Language Understanding with BERT using NVIDIA TensorRT](https://devblogs.nvidia.com/nlu-with-tensorrt-bert/) on Google Cloud T4 GPUs achieves 2.2 ms latency for inference. Optimizations are open source on GitHub.
6. [NLP's Clever Hans Moment has Arrived](https://thegradient.pub/nlps-clever-hans-moment-has-arrived/) by The Gradient.
7. [Language, trees, and geometry in neural networks](https://pair-code.github.io/interpretability/bert-tree/) - a series of expository notes accompanying the paper, "Visualizing and Measuring the Geometry of BERT" by Google's People + AI Research (PAIR) team.
8. [Benchmarking Transformers: PyTorch and TensorFlow](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2) by Hugging Face - a comparison of inference time (on CPU and GPU) and memory usage for a wide range of transformer architectures.
9. [Evolution of representations in the Transformer](https://lena-voita.github.io/posts/emnlp19_evolution.html) - An accessible article that presents the insights of their EMNLP 2019 paper. They look at how the representations of individual tokens in Transformers trained with different objectives change.
10. [The dark secrets of BERT](https://text-machine-lab.github.io/blog/2020/bert-secrets/) - This post probes fine-tuned BERT models for linguistic knowledge. In particular, the authors analyse how many self-attention patterns with some linguistic interpretation are actually used to solve downstream tasks. TL;DR: They are unable to find evidence that linguistically interpretable self-attention maps are crucial for downstream performance.
11. [A Visual Guide to Using BERT for the First Time](https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/) - Tutorial on using BERT in practice, such as for sentiment analysis on movie reviews by Jay Alammar.
12. [Turing-NLG: A 17-billion-parameter language model](https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/) by Microsoft that outperforms the state of the art on many downstream NLP tasks. This work would not be possible without breakthroughs produced by the [DeepSpeed library](https://github.com/microsoft/DeepSpeed) (compatible with PyTorch) and [ZeRO optimizer](https://arxiv.org/abs/1910.02054), which can be explored more in this accompanying [blog post](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters).
13. [MUM (Multitask Unified Model): A new AI milestone for understanding information](https://blog.google/products/search/introducing-mum/) by Google.
- Based on transformer architecture but more powerful.
- Multitask means: supports text and images, knowledge transfer between 75 languages, understand context and go deeper in a topic, and generate content.
14. [GPT-3 is No Longer the Only Game in Town](https://lastweekin.ai/p/gpt-3-is-no-longer-the-only-game) - GPT-3 was by far the largest AI model of its kind last year (2020). Now? Not so much.
15. [OpenAI's API Now Available with No Waitlist](https://openai.com/blog/api-no-waitlist/) - GPT-3 access without the wait. However, apps must be approved before [going live](https://beta.openai.com/docs/going-live). This release also allow them to review applications, monitor for misuse, and better understand the effects of this tech.
16. [The Inherent Limitations of GPT-3](https://lastweekin.ai/p/the-inherent-limitations-of-gpt-3) - One thing missing from the article if you've read [Gwern's GPT-3 Creative Fiction article](https://www.gwern.net/GPT-3#repetitiondivergence-sampling) before is the mystery known as "Repetition/Divergence Sampling":
> when you generate free-form completions, they have a tendency to eventually fall into repetitive loops of gibberish.
For those using Copilot, you should have experienced this wierdness where it generates the same line or block of code over and over again.
17. [Language Modelling at Scale: Gopher, Ethical considerations, and Retrieval](https://deepmind.com/blog/article/language-modelling-at-scale) by DeepMind - The paper present an analysis of Transformer-based language model performance across a wide range of model scales — from models with tens of millions of parameters up to a 280 billion parameter model called Gopher.
18. [Competitive programming with AlphaCode](https://deepmind.com/blog/article/Competitive-programming-with-AlphaCode) by DeepMind - AlphaCode uses transformer-based language models to generate code that can create novel solutions to programming problems which require an understanding of algorithms.
19. [Building games and apps entirely through natural language using OpenAI's code-davinci model](https://andrewmayneblog.wordpress.com/2022/03/17/building-games-and-apps-entirely-through-natural-language-using-openais-davinci-code-model/) - The author built several small games and apps without touching a single line of code, simply by telling the model what they want.
20. [Open AI gets GPT-3 to work by hiring an army of humans to fix GPT’s bad answers](https://statmodeling.stat.columbia.edu/2022/03/28/is-open-ai-cooking-the-books-on-gpt-3/)
21. [GPT-3 can run code](https://mayt.substack.com/p/gpt-3-can-run-code) - You provide an input text and a command and GPT-3 will transform them into an expected output. It works well for tasks like changing coding style, translating between programming languages, refactoring, and adding doc. For example, converts JSON into YAML, translates Python code to JavaScript, improve the runtime complexity of the function.
22. [Using GPT-3 to explain how code works](https://simonwillison.net/2022/Jul/9/gpt-3-explain-code/) by Simon Willison.
23. [Character AI announces they're building a full stack AGI company](https://blog.character.ai/introducing-character/) so you could create your own AI to help you with anything, using conversational AI research. The co-founders Noam Shazeer (co-invented Transformers, scaled them to supercomputers for the first time, and pioneered large-scale pretraining) and Daniel de Freitas (led the development of LaMDA), all of which are foundational to recent AI progress.
24. [How Much Better is OpenAI’s Newest GPT-3 Model?](https://scale.com/blog/gpt-3-davinci-003-comparison) - In addition to ChatGPT, OpenAI releases text-davinci-003, a Reinforcement Learning-tuned model that performs better long-form writing. Example, it can explain code in the style of Eminem. 😀
25. [OpenAI rival Cohere launches language model API](https://venturebeat.com/uncategorized/openai-rival-cohere-launches-language-model-api/) - Backed by AI experts, they aims to bring Google-quality predictive language to the masses. Aidan Gomez co-wrote a seminal 2017 paper at Google Brain that invented a concept known as "Transformers".
26. [Startups competing with OpenAI's GPT-3 all need to solve the same problems](https://www.theregister.com/2022/03/03/language_model_gpt3/) - Last year, two startups released their own proprietary text-generation APIs. AI21 Labs, launched its 178-billion-parameter Jurassic-1 in Aug 2021, and Cohere, released a range of models. Cohere hasn't disclosed how many parameters its models contain. ... There are other up-and-coming startups looking to solve the same issues. Anthropic, the AI safety and research company started by a group of ex-OpenAI employees. Several researchers have left Google Brain to join two new ventures started by their colleagues. One outfit is named Character.ai, and the other Persimmon Labs.
27. [Cohere Wants to Build the Definitive NLP Platform](https://albertoromgar.medium.com/cohere-wants-to-build-the-definitive-nlp-platform-7d090c0de9ca) - Beyond generative models like GPT-3.
28. [Transformer Inference Arithmetic](https://kipp.ly/blog/transformer-inference-arithmetic/) technical write-up from Carol Chen, ML Ops at Cohere. This article presents detailed few-principles reasoning about LLM inference performance, with no experiments or difficult math.
29. [State of AI Report 2022](https://www.stateof.ai/2022-report-launch.html) - Key takeaways:
- New independent research labs are rapidly open sourcing the closed source output of major labs.
- AI safety is attracting more talent... yet remains extremely neglected.
- OpenAI's Codex, which drives GitHub Copilot, has impressed the computer science community with its ability to complete code on multiple lines or directly from natural language instructions. This success spurred more research in this space.
- DeepMind revisited LM scaling laws and found that current LMs are significantly undertrained: they’re not trained on enough data given their large size. They train Chinchilla, a 4x smaller version of their Gopher, on 4.6x more data, and find that Chinchilla outperforms Gopher and other large models on BIG-bench.
- Reinforcement Learning from Human Feedback (RLHF) has emerged as a key method to finetune LLMs and align them with human values. This involves humans ranking language model outputs sampled for a given input, using these rankings to learn a reward model of human preferences, and then using this as a reward signal to finetune the language model with using RL.
30. [The Scaling Hypothesis](https://www.gwern.net/Scaling-hypothesis) by Gwern - On GPT-3: meta-learning, scaling, implications, and deep theory.
31. [AI And The Limits Of Language — An AI system trained on words and sentences alone will never approximate human understanding](https://www.noemamag.com/ai-and-the-limits-of-language/) by Jacob Browning and Yann LeCun - What LLMs like ChatGPT can and cannot do, and why AGI is not here yet.
32. [Use GPT-3 foundational models incorrectly: reduce costs 40x and increase speed by 5x](https://www.buildt.ai/blog/incorrectusage) - When fine-tuning a model, it is important to keep a few things in mind. There's still a lot to learn about working with these models at scale. We need a better guide.
33. [The Next Generation Of Large Language Models](https://archive.vn/WFZnG) - It highlights 3 emerging areas: 1) models that can generate their own training data to improve themselves, 2) models that can fact-check themselves, and 3) massive sparse expert models.
34. [GPT-4 analysis and predictions](https://www.lesswrong.com/posts/qdStMFDMrWAnTqNWL/gpt-4-predictions) - Somehow related, in ["Bing Chat is blatantly, aggressively misaligned"](https://www.lesswrong.com/posts/jtoPawEhLNXNxvgTT/bing-chat-is-blatantly-aggressively-misaligned) post, Gwern think how Bing Chat/Sydney can be so different from ChatGPT and his hypothesis: "Sydney is not a RLHF trained GPT-3 model but a GPT-4 model developed in a hurry". Some have also argued that Sydney performs better on reasoning tasks than ChatGPT/GPT-3.5 and it may be GPT-4.
35. [Mosaic LLMs (Part 2): GPT-3 quality for <$500k (2022)](https://archive.is/gu2li) - They claimed their [Composer PyTorch framework](https://github.com/mosaicml/composer) ease model training. Now with Colossal-AI framework, I wonder how good is their solution. Until their users train it, I guess everything is purely hypothetical.
36. [I made a transformer by hand (no training!)](https://vgel.me/posts/handmade-transformer/) (2023) - Make a transformer to predict a simple sequence manually — not by training one, or using pretrained weights, but instead by **assigning each weight, by hand**, over an evening.
37. [Finetune Llama 3.1 on GCP for production use cases](https://www.zenml.io/blog/how-to-finetune-llama-3-1-with-zenml)
## Educational
- [minGPT](https://github.com/karpathy/minGPT) by Andrej Karpathy - A PyTorch re-implementation of GPT, both training and inference. minGPT tries to be small, clean, interpretable and educational, as most of the currently available GPT model implementations can a bit sprawling. GPT is not a complicated model and this implementation is appropriately about 300 lines of code.
- [nanoGPT](https://github.com/karpathy/nanoGPT) - It's a re-write of minGPT. Still under active development. The associated and ongoing video lecture series _[Neural Networks: Zero to Hero](https://karpathy.ai/zero-to-hero.html)_, build GPT, from scratch, in code and aspire to spell everything out. Note that Karpathy's bottom up approach and fast.ai teaching style work well together. (FYI, fast.ai has both top-down ("part 1") and bottom-up ("part 2") approach.)
- [A visual intro to large language models (LLMs) by Jay Alammar/Cohere](https://jalammar.github.io/applying-large-language-models-cohere/) - A high-level look at LLMs and some of their applications for language processing. It covers text generation models (like GPT) and representation models (like BERT).
- [Interfaces for Explaining Transformer Language Models](https://jalammar.github.io/explaining-transformers/) by Jay Alammar - A gentle visual to Transformer models by looking at input saliency and neuron activation inside neural networks. **Our understanding of why these models work so well, however, still lags behind these developments**.
- [The GPT-3 Architecture, on a Napkin](https://dugas.ch/artificial_curiosity/GPT_architecture.html)
- [PicoGPT: GPT in 60 Lines of NumPy](https://jaykmody.com/blog/gpt-from-scratch/)
- [Video explainer about the core of transformer architecture](https://youtu.be/kWLed8o5M2Y?si=YOMpWS1gfWMADzTX) (2023) - Read The Illustrated Transformer, but still didn't feel like you had an intuitive understanding of what the various pieces of attention were doing? In this video, a more constructive approach to explaining the transformer and attention can help you understand it better: starting from a simple convolutional neural network (CNN), the author will step you through all of the changes that need to be made to a CNN to become a transformer.
- [A Hackers' Guide to Language Models (video)](https://youtu.be/jkrNMKz9pWU?si=4qsEubcueqp45geo) (2023) by Jeremy Howard, fast.ai - A quick run through all the basic ideas of language models, how to use them (both open models and OpenAI-based models) using code as much as possible.
### Tutorials
1. [How to train a new language model from scratch using Transformers and Tokenizers](https://huggingface.co/blog/how-to-train) tutorial by Hugging Face. :fire:
## AI Safety
Interpretability research and AI alignment research.
- [Transformer Circuits Thread](https://transformer-circuits.pub/) project by Anthropic - Can we reverse engineer transformer language models into human-understandable computer programs? Interpretability research benefits a lot from interactive articles. As part of their effort, they've created several other resources besides their paper like "A Mathematical Framework for Transformer Circuits" and ["toy models of superposition"](https://threadreaderapp.com/thread/1570087876053942272.html).
- [Discovering Language Model Behaviors with Model-Written Evaluations (paper)](https://arxiv.org/abs/2212.09251) by Anthropic et al. - They automatically generate evaluations with LMs. They discover new cases of inverse scaling where LMs get worse with size. They also find some of the first examples of inverse scaling in RLHF, where more RLHF makes LMs worse.
- [Transformers learn in-context by gradient descent (paper)](https://arxiv.org/abs/2212.07677) by J von Oswald et al. [[AI Alignment Forum](https://www.alignmentforum.org/posts/firtXAWGdvzXYAh9B/paper-transformers-learn-in-context-by-gradient-descent)]
- [Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers (paper)](https://arxiv.org/abs/2212.10559v2) by Microsoft Research.
- [Cognitive Biases in Large Language Models](https://universalprior.substack.com/p/cognitive-biases-in-large-language)
- [Tracr: Compiled Transformers as a Laboratory for Interpretability (paper)](https://arxiv.org/abs/2301.05062) (2023) by DeepMind - TRACR (TRAnsformer Compiler for RASP) is a compiler for converting RASP programs (DSL for Transformers) into weights of a GPT-like model. Usually, we train Transformers to encode algorithms in their weights. With TRACR, we go in the reverse direction; compile weights **directly** from explicit code. Why do this? Accelerate interpretability research. Think of it like formal methods (from software eng.) on Transformers. It can be difficult to check if the explanation an interpretability tool provides is correct. [[Tweet](https://twitter.com/davlindner/status/1613900577804525573), [code](https://github.com/deepmind/tracr)]
- [Yann LeCun's unwavering opinion on current (auto-regressive) LLMs (Tweet)](https://web.archive.org/web/20230213173604/https://twitter.com/ylecun/status/1625118108082995203)
- [Core Views on AI Safety: When, Why, What, and How](https://www.anthropic.com/index/core-views-on-ai-safety) by Anthropic, 2023.
- [Personalisation within bounds: A risk taxonomy and policy framework for the alignment of large language models with personalised feedback](https://arxiv.org/abs/2303.05453) by University of Oxford, 2023. [[Tweet](https://twitter.com/hannahrosekirk/status/1634228684893700096)]
- [GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models (paper)](https://arxiv.org/abs/2303.10130) by OpenAI et al., 2023 - The paper argues GPT is a General Purpose Technology.
## Videos
### [BERTology](https://huggingface.co/transformers/bertology.html)
1. [XLNet Explained](https://www.youtube.com/watch?v=naOuE9gLbZo) by NLP Breakfasts.
- Clear explanation. Also covers the two-stream self-attention idea.
2. [The Future of NLP](https://youtu.be/G5lmya6eKtc) by 🤗
- Dense overview of what is going on in transfer learning in NLP currently, limits, and future directions.
3. [The Transformer neural network architecture explained](https://youtu.be/FWFA4DGuzSc) by AI Coffee Break with Letitia Parcalabescu.
- High-level explanation, best suited when unfamiliar with Transformers.
### Attention and Transformer Networks
1. [Sequence to Sequence Learning Animated (Inside Transformer Neural Networks and Attention Mechanisms)](https://youtu.be/GTVgJhSlHEk) by learningcurve.
### General
- [Trials and tribulations of OPT-175B training by Susan Zhang at Meta](https://www.youtube.com/watch?v=p9IxoSkvZ-M) - In this talk, they walk through the development lifecycle of OPT-175B, covering infrastructure and training convergence challenges faced at scale, along with methods of addressing these issues going forward. Amazing that they managed to pull off such a feat. Key takeaway: data matters a lot! Super deep understanding of neural networks nuts&bolts (LR, SGD, etc.) and engineering. Even more than usual time spend staring at the loss curves. Understanding the Chinchilla's scaling law of how the new architecture/algorithms works as you scale up. [[LLM training log](https://github.com/facebookresearch/metaseq/blob/main/projects/OPT/chronicles/OPT175B_Logbook.pdf)]
## Official BERT Implementations
1. [google-research/bert](https://github.com/google-research/bert) - TensorFlow code and pre-trained models for BERT.
## Transformer Implementations By Communities
GPT and/or BERT implementations.
### PyTorch and TensorFlow
1. [🤗 Hugging Face Transformers](https://github.com/huggingface/transformers) (formerly known as [pytorch-transformers](https://github.com/huggingface/pytorch-transformers) and [pytorch-pretrained-bert](https://github.com/huggingface/pytorch-pretrained-BERT)) provides state-of-the-art general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet, CTRL...) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between TensorFlow 2.0 and PyTorch. [[Paper](https://arxiv.org/abs/1910.03771)]
2. [spacy-transformers](https://github.com/explosion/spacy-transformers) - a library that wrap Hugging Face's Transformers, in order to extract features to power NLP pipelines. It also calculates an alignment so the Transformer features can be related back to actual words instead of just wordpieces.
3. [FasterTransformer](https://github.com/NVIDIA/FasterTransformer) - Transformer related optimization, including BERT and GPT. This repo provides a script and recipe to run the highly optimized transformer-based encoder and decoder component, and it is tested and maintained by NVIDIA.
### PyTorch
1. [codertimo/BERT-pytorch](https://github.com/codertimo/BERT-pytorch) - Google AI 2018 BERT pytorch implementation.
2. [innodatalabs/tbert](https://github.com/innodatalabs/tbert) - PyTorch port of BERT ML model.
3. [kimiyoung/transformer-xl](https://github.com/kimiyoung/transformer-xl) - Code repository associated with the Transformer-XL paper.
4. [dreamgonfly/BERT-pytorch](https://github.com/dreamgonfly/BERT-pytorch) - A PyTorch implementation of BERT in "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding".
5. [dhlee347/pytorchic-bert](https://github.com/dhlee347/pytorchic-bert) - A Pytorch implementation of Google BERT.
6. [pingpong-ai/xlnet-pytorch](https://github.com/pingpong-ai/xlnet-pytorch) - A Pytorch implementation of Google Brain XLNet.
7. [facebook/fairseq](https://github.com/pytorch/fairseq/blob/master/examples/roberta/README.md) - RoBERTa: A Robustly Optimized BERT Pretraining Approach by Facebook AI Research. SoTA results on GLUE, SQuAD and RACE.
8. [NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM) - Ongoing research training transformer language models at scale, including: BERT.
9. [deepset-ai/FARM](https://github.com/deepset-ai/FARM) - Simple & flexible transfer learning for the industry.
10. [NervanaSystems/nlp-architect](https://www.intel.ai/nlp-transformer-models/) - NLP Architect by Intel AI. Among other libraries, it provides a quantized version of Transformer models and efficient training method.
11. [kaushaltrivedi/fast-bert](https://github.com/kaushaltrivedi/fast-bert) - Super easy library for BERT based NLP models. Built based on 🤗 Transformers and is inspired by fast.ai.
12. [NVIDIA/NeMo](https://github.com/NVIDIA/NeMo) - Neural Modules is a toolkit for conversational AI by NVIDIA. They are trying to [improve speech recognition with BERT post-processing](https://nvidia.github.io/NeMo/nlp/intro.html#improving-speech-recognition-with-bertx2-post-processing-model).
13. [facebook/MMBT](https://github.com/facebookresearch/mmbt/) from Facebook AI - Multimodal transformers model that can accept a transformer model and a computer vision model for classifying image and text.
14. [dbiir/UER-py](https://github.com/dbiir/UER-py) from Tencent and RUC - Open Source Pre-training Model Framework in PyTorch & Pre-trained Model Zoo (with more focus on Chinese).
15. [lucidrains/x-transformers](https://github.com/lucidrains/x-transformers) - A simple but complete full-attention transformer with a set of promising experimental features from various papers (good for learning purposes). There is a 2021 paper rounding up Transformer modifications, [_Do Transformer Modifications Transfer Across Implementations and Applications?_](https://arxiv.org/abs/2102.11972).
### Keras
1. [Separius/BERT-keras](https://github.com/Separius/BERT-keras) - Keras implementation of BERT with pre-trained weights.
2. [CyberZHG/keras-bert](https://github.com/CyberZHG/keras-bert) - Implementation of BERT that could load official pre-trained models for feature extraction and prediction.
3. [bojone/bert4keras](https://github.com/bojone/bert4keras) - Light reimplement of BERT for Keras.
### TensorFlow
1. [guotong1988/BERT-tensorflow](https://github.com/guotong1988/BERT-tensorflow) - BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
2. [kimiyoung/transformer-xl](https://github.com/kimiyoung/transformer-xl) - Code repository associated with the Transformer-XL paper.
3. [zihangdai/xlnet](https://github.com/zihangdai/xlnet) - Code repository associated with the XLNet paper.
### Chainer
1. [soskek/bert-chainer](https://github.com/soskek/bert-chainer) - Chainer implementation of "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding".
### Other
- [llama.cpp](https://github.com/ggerganov/llama.cpp) - Port of Facebook's LLaMA model in C/C++.
- [Cformers](https://github.com/NolanoOrg/cformers) - SoTA Transformers with C-backend for fast inference on your CPU.
- [Transformers.js](https://github.com/xenova/transformers.js) - Run 🤗 Transformers in your browser.
- [Alpaca.cpp](https://github.com/antimatter15/alpaca.cpp) - Run a fast ChatGPT-like model locally on your device.
- [LLaMA compatible port](https://github.com/cedrickchee/llama#llama-compatible-port)
- [Apple Neural Engine (ANE) Transformers](https://github.com/apple/ml-ane-transformers) - Transformer architecture optimized for Apple Silicon.
## Transfer Learning in NLP
NLP finally had a way to do transfer learning probably as well as Computer Vision could.
As Jay Alammar put it:
> The year 2018 has been an inflection point for machine learning models handling text (or more accurately, Natural Language Processing or NLP for short). Our conceptual understanding of how best to represent words and sentences in a way that best captures underlying meanings and relationships is rapidly evolving. Moreover, the NLP community has been putting forward incredibly powerful components that you can freely download and use in your own models and pipelines (It's been referred to as [NLP's ImageNet moment](http://ruder.io/nlp-imagenet/), referencing how years ago similar developments accelerated the development of machine learning in Computer Vision tasks).
>
> One of the latest milestones in this development is the [release](https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html) of [BERT](https://github.com/google-research/bert), an event [described](https://twitter.com/lmthang/status/1050543868041555969) as marking the beginning of a new era in NLP. BERT is a model that broke several records for how well models can handle language-based tasks. Soon after the release of the paper describing the model, the team also open-sourced the code of the model, and made available for download versions of the model that were already pre-trained on massive datasets. This is a momentous development since it enables anyone building a machine learning model involving language processing to use this powerhouse as a readily-available component – saving the time, energy, knowledge, and resources that would have gone to training a language-processing model from scratch.
>
> BERT builds on top of a number of clever ideas that have been bubbling up in the NLP community recently – including but not limited to [Semi-supervised Sequence Learning](https://arxiv.org/abs/1511.01432) (by [Andrew Dai](https://twitter.com/iamandrewdai) and [Quoc Le](https://twitter.com/quocleix)), [ELMo](https://arxiv.org/abs/1802.05365) (by Matthew Peters and researchers from [AI2](https://allenai.org/) and [UW CSE](https://www.engr.washington.edu/about/bldgs/cse)), [ULMFiT](https://arxiv.org/abs/1801.06146) (by [fast.ai](https://fast.ai) founder [Jeremy Howard](https://twitter.com/jeremyphoward) and [Sebastian Ruder](https://twitter.com/seb_ruder)), the [OpenAI transformer](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf) (by OpenAI researchers [Radford](https://twitter.com/alecrad), [Narasimhan](https://twitter.com/karthik_r_n), [Salimans](https://twitter.com/timsalimans), and [Sutskever](https://twitter.com/ilyasut)), and the Transformer ([Vaswani et al](https://arxiv.org/abs/1706.03762)).
>
> **ULMFiT: Nailing down Transfer Learning in NLP**
>
> [ULMFiT introduced methods to effectively utilize a lot of what the model learns during pre-training](http://nlp.fast.ai/classification/2018/05/15/introducting-ulmfit.html) – more than just embeddings, and more than contextualized embeddings. ULMFiT introduced a language model and a process to effectively fine-tune that language model for various tasks.
>
> NLP finally had a way to do transfer learning probably as well as Computer Vision could.
[MultiFiT: Efficient Multi-lingual Language Model Fine-tuning](http://nlp.fast.ai/classification/2019/09/10/multifit.html) by Sebastian Ruder et al. MultiFiT extends ULMFiT to make it more efficient and more suitable for language modelling beyond English. ([EMNLP 2019 paper](https://arxiv.org/abs/1909.04761))
## Books
1. [Transfer Learning for Natural Language Processing](https://www.manning.com/books/transfer-learning-for-natural-language-processing) - A book that is a practical primer to transfer learning techniques capable of delivering huge improvements to your NLP models.
2. [Natural Language Processing with Transformers](https://transformersbook.com/) by Lewis Tunstall, Leandro von Werra, and Thomas Wolf - This practical book shows you how to train and scale these large models using Hugging Face Transformers. The authors use a hands-on approach to teach you how transformers work and how to integrate them in your applications.
## Other Resources
Expand Other Resources
1. [hanxiao/bert-as-service](https://github.com/hanxiao/bert-as-service) - Mapping a variable-length sentence to a fixed-length vector using pretrained BERT model.
2. [brightmart/bert_language_understanding](https://github.com/brightmart/bert_language_understanding) - Pre-training of Deep Bidirectional Transformers for Language Understanding: pre-train TextCNN.
3. [algteam/bert-examples](https://github.com/algteam/bert-examples) - BERT examples.
4. [JayYip/bert-multiple-gpu](https://github.com/JayYip/bert-multiple-gpu) - A multiple GPU support version of BERT.
5. [HighCWu/keras-bert-tpu](https://github.com/HighCWu/keras-bert-tpu) - Implementation of BERT that could load official pre-trained models for feature extraction and prediction on TPU.
6. [whqwill/seq2seq-keyphrase-bert](https://github.com/whqwill/seq2seq-keyphrase-bert) - Add BERT to encoder part for https://github.com/memray/seq2seq-keyphrase-pytorch
7. [xu-song/bert_as_language_model](https://github.com/xu-song/bert_as_language_model) - BERT as language model, a fork from Google official BERT implementation.
8. [Y1ran/NLP-BERT--Chinese version](https://github.com/Y1ran/NLP-BERT--ChineseVersion)
9. [yuanxiaosc/Deep_dynamic_word_representation](https://github.com/yuanxiaosc/Deep_dynamic_word_representation) - TensorFlow code and pre-trained models for deep dynamic word representation (DDWR). It combines the BERT model and ELMo's deep context word representation.
10. [yangbisheng2009/cn-bert](https://github.com/yangbisheng2009/cn-bert)
11. [Willyoung2017/Bert_Attempt](https://github.com/Willyoung2017/Bert_Attempt)
12. [Pydataman/bert_examples](https://github.com/Pydataman/bert_examples) - Some examples of BERT. `run_classifier.py` based on Google BERT for Kaggle Quora Insincere Questions Classification challenge. `run_ner.py` is based on the first season of the Ruijin Hospital AI contest and a NER written by BERT.
13. [guotong1988/BERT-chinese](https://github.com/guotong1988/BERT-chinese) - Pre-training of deep bidirectional transformers for Chinese language understanding.
14. [zhongyunuestc/bert_multitask](https://github.com/zhongyunuestc/bert_multitask) - Multi-task.
15. [Microsoft/AzureML-BERT](https://github.com/Microsoft/AzureML-BERT) - End-to-end walk through for fine-tuning BERT using Azure Machine Learning.
16. [bigboNed3/bert_serving](https://github.com/bigboNed3/bert_serving) - Export BERT model for serving.
17. [yoheikikuta/bert-japanese](https://github.com/yoheikikuta/bert-japanese) - BERT with SentencePiece for Japanese text.
18. [nickwalton/AIDungeon](https://github.com/nickwalton/AIDungeon) - AI Dungeon 2 is a completely AI generated text adventure built with OpenAI's largest 1.5B param GPT-2 model. It's a first of it's kind game that allows you to enter and will react to any action you can imagine.
19. [turtlesoupy/this-word-does-not-exist](https://github.com/turtlesoupy/this-word-does-not-exist) - "This Word Does Not Exist" is a project that allows people to train a variant of GPT-2 that makes up words, definitions and examples from scratch. We've never seen fake text so real.
## Tools
1. [jessevig/bertviz](https://github.com/jessevig/bertviz) - Tool for visualizing attention in the Transformer model.
2. [FastBert](https://github.com/kaushaltrivedi/fast-bert) - A simple deep learning library that allows developers and data scientists to train and deploy BERT based models for NLP tasks beginning with text classification. The work on FastBert is inspired by fast.ai.
3. [gpt2tc](https://bellard.org/libnc/gpt2tc.html) - A small program using the GPT-2 LM to complete and compress texts. It has no external dependency, requires no GPU and is quite fast. The smallest model (117M parameters) is provided. Larger models can be downloaded as well. (no waitlist, no sign up required).
## Tasks
### Named-Entity Recognition (NER)
Expand NER
1. [kyzhouhzau/BERT-NER](https://github.com/kyzhouhzau/BERT-NER) - Use google BERT to do CoNLL-2003 NER.
2. [zhpmatrix/bert-sequence-tagging](https://github.com/zhpmatrix/bert-sequence-tagging) - Chinese sequence labeling.
3. [JamesGu14/BERT-NER-CLI](https://github.com/JamesGu14/BERT-NER-CLI) - Bert NER command line tester with step by step setup guide.
4. [sberbank-ai/ner-bert](https://github.com/sberbank-ai/ner-bert)
5. [mhcao916/NER_Based_on_BERT](https://github.com/mhcao916/NER_Based_on_BERT) - This project is based on Google BERT model, which is a Chinese NER.
6. [macanv/BERT-BiLSMT-CRF-NER](https://github.com/macanv/BERT-BiLSMT-CRF-NER) - TensorFlow solution of NER task using Bi-LSTM-CRF model with Google BERT fine-tuning.
7. [ProHiryu/bert-chinese-ner](https://github.com/ProHiryu/bert-chinese-ner) - Use the pre-trained language model BERT to do Chinese NER.
8. [FuYanzhe2/Name-Entity-Recognition](https://github.com/FuYanzhe2/Name-Entity-Recognition) - Lstm-CRF, Lattice-CRF, recent NER related papers.
9. [king-menin/ner-bert](https://github.com/king-menin/ner-bert) - NER task solution (BERT-Bi-LSTM-CRF) with Google BERT https://github.com/google-research.
### Classification
Expand Classification
1. [brightmart/sentiment_analysis_fine_grain](https://github.com/brightmart/sentiment_analysis_fine_grain) - Multi-label classification with BERT; Fine Grained Sentiment Analysis from AI challenger.
2. [zhpmatrix/Kaggle-Quora-Insincere-Questions-Classification](https://github.com/zhpmatrix/Kaggle-Quora-Insincere-Questions-Classification) - Kaggle baseline—fine-tuning BERT and tensor2tensor based Transformer encoder solution.
3. [maksna/bert-fine-tuning-for-chinese-multiclass-classification](https://github.com/maksna/bert-fine-tuning-for-chinese-multiclass-classification) - Use Google pre-training model BERT to fine-tune for the Chinese multiclass classification.
4. [NLPScott/bert-Chinese-classification-task](https://github.com/NLPScott/bert-Chinese-classification-task) - BERT Chinese classification practice.
5. [fooSynaptic/BERT_classifer_trial](https://github.com/fooSynaptic/BERT_classifer_trial) - BERT trial for Chinese corpus classfication.
6. [xiaopingzhong/bert-finetune-for-classfier](https://github.com/xiaopingzhong/bert-finetune-for-classfier) - Fine-tuning the BERT model while building your own dataset for classification.
7. [Socialbird-AILab/BERT-Classification-Tutorial](https://github.com/Socialbird-AILab/BERT-Classification-Tutorial) - Tutorial.
8. [malteos/pytorch-bert-document-classification](https://github.com/malteos/pytorch-bert-document-classification/) - Enriching BERT with Knowledge Graph Embedding for Document Classification (PyTorch)
### Text Generation
Expand Text Generation
1. [asyml/texar](https://github.com/asyml/texar) - Toolkit for Text Generation and Beyond. [Texar](https://texar.io) is a general-purpose text generation toolkit, has also implemented BERT here for classification, and text generation applications by combining with Texar's other modules.
2. [Plug and Play Language Models: a Simple Approach to Controlled Text Generation](https://arxiv.org/abs/1912.02164) (PPLM) paper by Uber AI.
### Question Answering (QA)
Expand QA
1. [matthew-z/R-net](https://github.com/matthew-z/R-net) - R-net in PyTorch, with BERT and ELMo.
2. [vliu15/BERT](https://github.com/vliu15/BERT) - TensorFlow implementation of BERT for QA.
3. [benywon/ChineseBert](https://github.com/benywon/ChineseBert) - This is a Chinese BERT model specific for question answering.
4. [xzp27/BERT-for-Chinese-Question-Answering](https://github.com/xzp27/BERT-for-Chinese-Question-Answering)
5. [facebookresearch/SpanBERT](https://github.com/facebookresearch/SpanBERT) - Question Answering on SQuAD; improving pre-training by representing and predicting spans.
### Knowledge Graph
Expand Knowledge Graph
1. [sakuranew/BERT-AttributeExtraction](https://github.com/sakuranew/BERT-AttributeExtraction) - Using BERT for attribute extraction in knowledge graph. Fine-tuning and feature extraction. The BERT-based fine-tuning and feature extraction methods are used to extract knowledge attributes of Baidu Encyclopedia characters.
2. [lvjianxin/Knowledge-extraction](https://github.com/lvjianxin/Knowledge-extraction) - Chinese knowledge-based extraction. Baseline: bi-LSTM+CRF upgrade: BERT pre-training.
## License
Expand License
This repository contains a variety of content; some developed by Cedric Chee, and some from third-parties. The third-party content is distributed under the license provided by those parties.
*I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer.*
The content developed by Cedric Chee is distributed under the following license:
### Code
The code in this repository, including all code samples in the notebooks listed above, is released under the [MIT license](LICENSE). Read more at the [Open Source Initiative](https://opensource.org/licenses/MIT).
### Text
The text content is released under the CC-BY-SA 4.0 license. Read more at [Creative Commons](https://creativecommons.org/licenses/by-sa/4.0/).
[^1]: Infographic by AIM.