https://github.com/davendw49/Awesome-Long-Context-Language-Modeling
Papers of Long Context Language Model
https://github.com/davendw49/Awesome-Long-Context-Language-Modeling
List: Awesome-Long-Context-Language-Modeling
awesome-list llm long-context nlp
Last synced: 3 months ago
JSON representation
Papers of Long Context Language Model
- Host: GitHub
- URL: https://github.com/davendw49/Awesome-Long-Context-Language-Modeling
- Owner: davendw49
- License: apache-2.0
- Created: 2023-07-26T07:15:11.000Z (almost 2 years ago)
- Default Branch: main
- Last Pushed: 2024-03-28T04:53:16.000Z (about 1 year ago)
- Last Synced: 2025-03-26T20:01:34.134Z (3 months ago)
- Topics: awesome-list, llm, long-context, nlp
- Homepage:
- Size: 14.6 KB
- Stars: 10
- Watchers: 2
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- ultimate-awesome - Awesome-Long-Context-Language-Modeling - Papers of Long Context Language Model. (Other Lists / Julia Lists)
README
 Awesome Long-context Language Modeling papers
Awesome Long-context Language Modeling papers
---
## Introduction (Draft by ChatGPT😄)
Traditional language models like [ChatGPT](https://chat.openai.com/) have a fixed context window, which means they can only consider a limited number of tokens (words or subwords) as input to generate the next word in a sequence. For example, the original GPT-3.5 has a maximum context window of **2,048** tokens. This limitation poses challenges when dealing with longer pieces of text, as it may cut off relevant information beyond the context window.
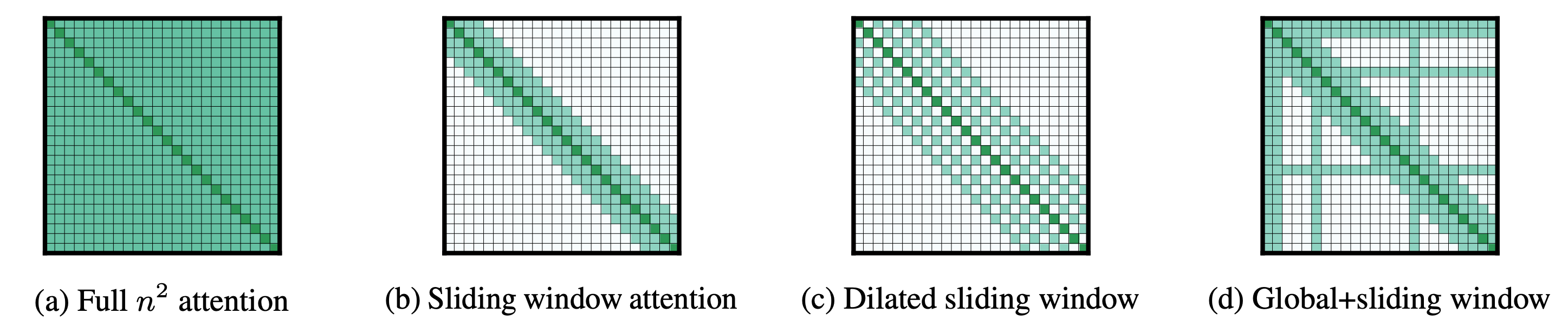
To overcome this limitation and better model long-range dependencies in text, researchers have explored various techniques and architectures. The following are some approaches that might be considered as "long context language models".
## PaperList
### Memory/Cache-Augmented Models
>Some language models incorporate external memory mechanisms, allowing them to store information from past tokens and retrieve it when necessary. These memories enable the model to maintain context over longer segments of text.
- [Dual Cache for Long Document Neural Coreference Resolution](https://aclanthology.org/2023.acl-long.851.pdf)
- [Augmenting Language Models with Long-Term Memory](https://arxiv.org/pdf/2306.07174.pdf)
- [In-context Autoencoder for Context Compression in a Large Language Model](https://arxiv.org/abs/2307.06945)
- [LM-Infinite: Simple On-the-Fly Length Generalization for Large Language Models](https://arxiv.org/pdf/2308.16137.pdf)
>Hierarchical Models / Data-Centric or Compress happens in context / key-value
- [Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading](https://arxiv.org/pdf/2310.05029.pdf)
- [Compressing Context to Enhance Inference Efficiency of Large Language Models](https://arxiv.org/pdf/2310.06201.pdf)
- [Context Compression for Auto-regressive Transformers with Sentinel Tokens](https://arxiv.org/pdf/2310.08152.pdf)
- [Learned Token Pruning for Transformers](https://arxiv.org/pdf/2107.00910.pdf)
- [Block-Recurrent Transformers](https://arxiv.org/pdf/2203.07852.pdf)
- [Recurrent Memory Transformer](https://arxiv.org/pdf/2207.06881.pdf)
>Probably transformer variants, which means that the architecture of the transformers
- [Memorizing Transformers](https://arxiv.org/pdf/2203.08913.pdf)
- [Compressive Transformers for Long-Range Sequence Modelling](https://arxiv.org/pdf/1911.05507.pdf)
- [Focused Transformer: Contrastive Training for Context Scaling](https://arxiv.org/pdf/2307.03170.pdf)
### Transformer Variants (Totally change the KV or position embedding of the transformers)
>Researchers have explored variants that can better handle long context by utilizing techniques like sparse attention, axial attention, and reformulating the self-attention mechanism.
- [Adapting Language Models to Compress Contexts](https://arxiv.org/pdf/2305.14788.pdf)
- [LONGNET: Scaling Transformers to 1,000,000,000 Tokens](https://arxiv.org/pdf/2307.02486.pdf)
- [Blockwise Parallel Transformer for Long Context Large Models](https://arxiv.org/pdf/2305.19370.pdf)
- [ETC: Encoding Long and Structured Inputs in Transformers](https://arxiv.org/pdf/2004.08483.pdf)
- [Improving Long Context Document-Level Machine Translation](https://arxiv.org/pdf/2306.05183.pdf)
- [Extending context window of large language models via positional interpolation](https://arxiv.org/pdf/2306.15595.pdf)
### Window-Based/On-the-fly Methods
>Rather than relying on a fixed context window, some models use a sliding window approach. They process the text in smaller chunks, capturing local dependencies within each window and passing relevant information between adjacent windows.
- [Efficient Long-Text Understanding with Short-Text Models](https://arxiv.org/pdf/2208.00748.pdf)
- [LongCoder: A Long-Range Pre-trained Language Model for Code Completion](https://arxiv.org/pdf/2306.14893.pdf)
- [Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time](https://openreview.net/pdf?id=wIPIhHd00i)
- [Train short, test long: Attention with linear biases enables input length extrapolation](https://arxiv.org/pdf/2108.12409.pdf)
### Analysis
- [Lost in the Middle: How Language Models Use Long Contexts](https://arxiv.org/pdf/2307.03172.pdf)
- [Do Long-Range Language Models Actually Use Long-Range Context?](https://arxiv.org/pdf/2109.09115.pdf)
- [Understanding the Role of Input Token Characters in Language Models: How Does Information Loss Affect Performance?](https://arxiv.org/pdf/2310.17271.pdf)
### Reinforcement Learning
>Some approaches use reinforcement learning to guide the model's attention to focus on important parts of the input text while considering the context.
- [A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis](https://arxiv.org/pdf/2307.12856.pdf)
### Benchmark
- [L-Eval: Instituting Standardized Evaluation for Long Context Language Models](https://arxiv.org/pdf/2307.11088.pdf)
- [Long Range Arena: A Benchmark for Efficient Transformers](https://arxiv.org/pdf/2011.04006.pdf)
- [Large-Scale Language Model Rescoring on Long-Form Data](https://arxiv.org/pdf/2306.08133.pdf)
### CV-Inspired
- [XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model](https://arxiv.org/pdf/2207.07115.pdf)
- [Visual Transformers needs Registers](https://arxiv.org/pdf/2309.16588.pdf)
## Contact Me
If you have any questions or comments, please feel free to let us know: 📧 [Cheng Deng](mailto:[email protected]). The main contribution of the contributor:
- **[Cheng Deng](https://www.big-cheng.com) @ SJTU**