https://github.com/gokayfem/awesome-vlm-architectures
Famous Vision Language Models and Their Architectures
https://github.com/gokayfem/awesome-vlm-architectures
List: awesome-vlm-architectures
awesome awesome-list blip clip cogvlm image-encoder internlm kosmos llava multimodal qwen-vl text-encoder vision-language-model vlm
Last synced: 2 months ago
JSON representation
Famous Vision Language Models and Their Architectures
- Host: GitHub
- URL: https://github.com/gokayfem/awesome-vlm-architectures
- Owner: gokayfem
- License: cc0-1.0
- Created: 2024-02-15T16:57:39.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2025-02-24T15:16:02.000Z (4 months ago)
- Last Synced: 2025-04-20T22:02:17.643Z (2 months ago)
- Topics: awesome, awesome-list, blip, clip, cogvlm, image-encoder, internlm, kosmos, llava, multimodal, qwen-vl, text-encoder, vision-language-model, vlm
- Language: Markdown
- Homepage:
- Size: 2.26 MB
- Stars: 780
- Watchers: 15
- Forks: 39
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
- Code of conduct: CODE-OF-CONDUCT.md
Awesome Lists containing this project
- awesome-foundation-model-ros - Awesome VLM Architectures - A curated list of famous vision language models and their architectures. (Research-Grade Frameworks)
- awesome-foundation-model-ros - Awesome VLM Architectures - A curated list of famous vision language models and their architectures. (Research-Grade Frameworks)
- fucking-awesome - VLM Architectures - Vision Language Model architectures. (Theory)
- awesome - VLM Architectures - Vision Language Model architectures. (Theory)
- ultimate-awesome - awesome-vlm-architectures - Famous Vision Language Models and Their Architectures. (Other Lists / Julia Lists)
README
# 👁️🗨️Awesome VLM Architectures [](https://awesome.re)

**Vision-Language Models (VLMs)** feature a multimodal architecture that processes image and text data simultaneously. They can perform **Visual Question Answering (VQA)**, **image captioning** and **Text-To-Image search** kind of tasks. VLMs utilize techniques like multimodal fusing with cross-attention, masked-language modeling, and image-text matching to relate visual semantics to textual representations. This repository contains information on famous Vision Language Models (VLMs), including details about their architectures, training procedures, and the datasets used for training. **Click to expand for further details for every architecture**
- 📙 Visit my other repo to try Vision Language Models on ComfyUI
## Contents
- [Architectures](#architectures)
- [Important References](#important-references)
## Models
[LLaVA](#llava-large-language-and-vision-assistant---visual-instruction-tuning) | [LLaVA 1.5](#llava-15-improved-baselines-with-visual-instruction-tuning) | [LLaVA 1.6](#llava-16-llava-next-improved-reasoning-ocr-and-world-knowledge) | [PaliGemma](#paligemma-a-versatile-and-transferable-3b-vision-language-model) | [PaliGemma 2](#paligemma-2-a-family-of-versatile-vlms-for-transfer) | [AIMv2](#aimv2-multimodal-autoregressive-pre-training-of-large-vision-encoders) | [Apollo](#apollo-an-exploration-of-video-understanding-in-large-multimodal-models) | [ARIA](#aria-an-open-multimodal-native-mixture-of-experts-model) | [EVE](#eve-unveiling-encoder-free-vision-language-models) | [EVEv2](#evev2-improved-baselines-for-encoder-free-vision-language-models) | [Janus-Pro](#janus-pro-unified-multimodal-understanding-and-generation-with-data-and-model-scaling) | [LLaVA-CoT](#llava-cot-let-vision-language-models-reason-step-by-step) | [LLM2CLIP](#llm2clip-powerful-language-model-unlocks-richer-visual-representation) | [Maya](#maya-an-instruction-finetuned-multilingual-multimodal-model) | [MiniMax-01](#minimax-01-scaling-foundation-models-with-lightning-attention) | [NVLM](#nvlm-open-frontier-class-multimodal-llms) | [OmniVLM](#omnivlm-a-token-compressed-sub-billion-parameter-vision-language-model-for-efficient-on-device-inference) | [Pixtral 12B](#pixtral-12b-a-cutting-edge-open-multimodal-language-model) | [Sa2VA](#sa2va-marrying-sam2-with-llava-for-dense-grounded-understanding-of-images-and-videos) | [Tarsier2](#tarsier2-advancing-large-vision-language-models-from-detailed-video-description-to-comprehensive-video-understanding) | [UI-TARS](#ui-tars-pioneering-automated-gui-interaction-with-native-agents) | [VideoChat-Flash](#videochat-flash-hierarchical-compression-for-long-context-video-modeling) | [VideoLLaMA 3](#videollama-3-frontier-multimodal-foundation-models-for-image-and-video-understanding) | [Llama 3.2-Vision](#llama-32-vision-enhanced-multimodal-capabilities-built-on-llama-3) | [SmolVLM](#smolvlm-a-small-efficient-and-open-source-vision-language-model) | [IDEFICS](#idefics) | [IDEFICS2](#idefics2) | [IDEFICS3-8B](#idefics3-8b-building-and-better-understanding-vision-language-models) | [InternLM-XComposer2](#internlm-xcomposer2-mastering-free-form-text-image-composition-and-comprehension-in-vision-language-large-model) | [InternLM-XComposer2-4KHD](#internlm-xcomposer2-4khd-a-pioneering-large-vision-language-model-handling-resolutions-from-336-pixels-to-4k-hd) | [InternLM-XComposer-2.5](#internlm-xcomposer-25-a-versatile-large-vision-language-model-supporting-long-contextual-input-and-output) | [InternVL 2.5](#internvl-25-expanding-performance-boundaries-of-open-source-multimodal-models-with-model-data-and-test-time-scaling) | [DeepSeek-VL](#deepseek-vl-towards-real-world-vision-language-understanding) | [DeepSeek-VL2](#deepseek-vl2-mixture-of-experts-vision-language-models-for-advanced-multimodal-understanding) | [MANTIS](#mantis-mastering-multi-image-understanding-through-interleaved-instruction-tuning) | [Qwen-VL](#qwen-vl-a-versatile-vision-language-model-for-understanding-localization-text-reading-and-beyond) | [Qwen2-VL](#qwen2-vl-a-powerful-open-source-vision-language-model-for-image-and-video-understanding) | [Qwen2.5-VL](#qwen25-vl-enhanced-vision-language-capabilities-in-the-qwen-series) | [moondream1](#moondream1-and-moondream2) | [moondream2](#moondream1-and-moondream2) | [Moondream-next](#moondream-next-compact-vision-language-model-with-enhanced-capabilities) | [SPHINX-X](#sphinx-x-scaling-data-and-parameters-for-a-family-of-multi-modal-large-language-models) | [BLIP](#blip-bootstrapping-language-image-pre-training) | [BLIP-2](#blip-2-bootstrapping-language-image-pre-training-with-frozen-image-encoders-and-large-language-models) | [xGen-MM (BLIP-3)](#xgen-mm-blip-3-an-open-source-framework-for-building-powerful-and-responsible-large-multimodal-models) | [InstructBLIP](#instructblip-towards-general-purpose-vision-language-models-with-instruction-tuning) | [KOSMOS-1](#kosmos-1-language-is-not-all-you-need-aligning-perception-with-language-models) | [KOSMOS-2](#kosmos-2-grounding-multimodal-large-language-models-to-the-world) | [ConvLLaVA](#convllava-hierarchical-backbones-as-visual-encoder-for-large-multimodal-models) | [Parrot](#parrot-multilingual-visual-instruction-tuning) | [OMG-LLaVA](#omg-llava-bridging-image-level-object-level-pixel-level-reasoning-and-understanding) | [EVLM](#evlm-an-efficient-vision-language-model-for-visual-understanding) | [SlowFast-LLaVA](#slowfast-llava-a-strong-training-free-baseline-for-video-large-language-models) | [Nous-Hermes-2-Vision - Mistral 7B](#nous-hermes-2-vision---mistral-7b) | [TinyGPT-V](#tinygpt-v-efficient-multimodal-large-language-model-via-small-backbones) | [CoVLM](#covlm-composing-visual-entities-and-relationships-in-large-language-models-via-communicative-decoding) | [GLaMM](#glamm-pixel-grounding-large-multimodal-model) | [COSMO](#cosmo-contrastive-streamlined-multimodal-model-with-interleaved-pre-training) | [FireLLaVA](#firellava) | [u-LLaVA](#u-llava-unifying-multi-modal-tasks-via-large-language-model) | [MoE-LLaVA](#moe-llava-mixture-of-experts-for-large-vision-language-models) | [BLIVA](#bliva-a-simple-multimodal-llm-for-better-handling-of-text-rich-visual-questions) | [MobileVLM](#mobilevlm-a-fast-strong-and-open-vision-language-assistant-for-mobile-devices) | [FROZEN](#frozen-multimodal-few-shot-learning-with-frozen-language-models) | [Flamingo](#flamingo-a-visual-language-model-for-few-shot-learning) | [OpenFlamingo](#openflamingo-an-open-source-framework-for-training-large-autoregressive-vision-language-models) | [PaLI](#pali-a-jointly-scaled-multilingual-language-image-model) | [PaLI-3](#pali-3-vision-language-models-smaller-faster-stronger) | [PaLM-E](#palm-e-an-embodied-multimodal-language-model) | [MiniGPT-4](#minigpt-4-enhancing-vision-language-understanding-with-advanced-large-language-models) | [MiniGPT-v2](#minigpt-v2-large-language-model-as-a-unified-interface-for-vision-language-multi-task-learning) | [LLaVA-Plus](#llava-plus-learning-to-use-tools-for-creating-multimodal-agents) | [BakLLaVA](#bakllava) | [CogVLM](#cogvlm-visual-expert-for-pretrained-language-models) | [CogVLM2](#cogvlm2-enhanced-vision-language-models-for-image-and-video-understanding) | [Ferret](#ferret-refer-and-ground-anything-anywhere-at-any-granularity) | [Fuyu-8B](#fuyu-8b-a-multimodal-architecture-for-ai-agents) | [OtterHD](#otterhd-a-high-resolution-multi-modality-model) | [SPHINX](#sphinx-the-joint-mixing-of-weights-tasks-and-visual-embeddings-for-multi-modal-large-language-models) | [Eagle 2](#eagle-2-building-post-training-data-strategies-from-scratch-for-frontier-vision-language-models) | [EAGLE](#eagle-exploring-the-design-space-for-multimodal-llms-with-mixture-of-encoders) | [VITA](#vita-towards-open-source-interactive-omni-multimodal-llm) | [LLaVA-OneVision](#llava-onevision-easy-visual-task-transfer) | [MiniCPM-o-2.6](#minicpm-o-26-a-gpt-4o-level-mllm-for-vision-speech-and-multimodal-live-streaming) | [MiniCPM-V](#minicpm-v-a-gpt-4v-level-mllm-on-your-phone) | [INF-LLaVA](#inf-llava-high-resolution-image-perception-for-multimodal-large-language-models) | [Florence-2](#florence-2-a-deep-dive-into-its-unified-architecture-and-multi-task-capabilities) | [MULTIINSTRUCT](#multiinstruct-improving-multi-modal-zero-shot-learning-via-instruction-tuning) | [MouSi](#mousi-poly-visual-expert-vision-language-models) | [LaVIN](#lavin-cheap-and-quick-efficient-vision-language-instruction-tuning-for-large-language-models) | [CLIP](#clip-contrastive-language-image-pre-training) | [MetaCLIP](#metaclip-demystifying-clip-data) | [Alpha-CLIP](#alpha-clip-a-clip-model-focusing-on-wherever-you-want) | [GLIP](#glip-grounded-language-image-pre-training) | [ImageBind](#imagebind-one-embedding-space-to-bind-them-all) | [SigLIP](#siglip-sigmoid-loss-for-language-image-pre-training) | [ViT](#vit-an-image-is-worth-16x16-words-transformers-for-image-recognition-at-scale)
## Architectures
## **LLaVA: Large Language and Vision Assistant - Visual Instruction Tuning**
LLaVA seamlessly integrates a pre-trained language model (Vicuna) with a visual encoder (CLIP) using a simple linear layer, creating a robust architecture capable of effectively processing and understanding language-image instructions.
[](https://arxiv.org/abs/2304.08485) [](https://github.com/haotian-liu/LLaVA) [](https://llava.hliu.cc/)
Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee

ℹ️ More Information
**LLaVA**: At the heart of LLaVA's architecture is the fusion of a pre-trained language model with a visual model, specifically designed to process and understand language-image instruction data effectively. This integration enables LLaVA to leverage the distinct strengths of both models, employing the CLIP visual encoder for robust image feature extraction and the Vicuna language model for intricate language instruction processing. A noteworthy feature of this architecture is the use of **a simple linear layer** that bridges image features to the word embedding space, facilitating a seamless alignment between visual and linguistic representations. The training methodology of LLaVA is meticulously structured into a two-stage instruction-tuning procedure. Initially, the model undergoes pre-training focused on feature alignment, utilizing a carefully filtered dataset to synchronize image features with LLM word embeddings. Subsequently, the model is fine-tuned end-to-end on tailored tasks such as multimodal chatbot functionalities and Science QA, with the aim of refining its instruction-following prowess. This sophisticated training regimen is underpinned by the use of multimodal instruction-following data generated via GPT-4, converting image-text pairs into formats conducive to instruction-following tasks. The alignment of text and image data is innovatively achieved through **a trainable projection matrix**, converting visual features into language embedding tokens within a unified dimensional space, thereby enhancing the model's ability to encode vision and text cohesively.The datasets deployed for LLaVA's training and evaluation are strategically selected to bolster its multimodal capabilities. The Filtered CC3M dataset serves as the foundation for pre-training, aligning visual and language features, while the LLaVA-Instruct-158K dataset generated using GPT-4 is pivotal for fine-tuning the model on diverse multimodal tasks. Additionally, the ScienceQA dataset plays a critical role in assessing LLaVA's proficiency in multimodal reasoning tasks, demonstrating the model's comprehensive training and its potential to significantly advance the field of multimodal interaction and understanding.
## **LLaVA 1.5: Improved Baselines with Visual Instruction Tuning**
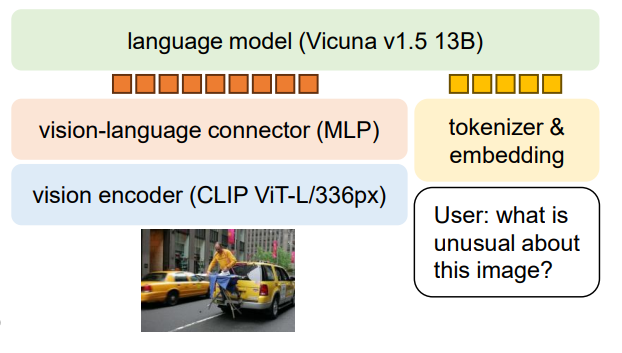
LLaVA 1.5 enhances its multimodal understanding by replacing its initial linear projection with a more powerful multi-layer perceptron (MLP), enabling a deeper integration of visual features from CLIP-ViT-L-336px and linguistic data.
[](https://arxiv.org/abs/2310.03744)
Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee
ℹ️ More Information
**LLaVA 1.5**: This iteration introduces a refined architecture that incorporates a CLIP-ViT-L-336px vision encoder alongside **a multi-layer perceptron (MLP) projection layer**. This combination not only boosts the model's data efficiency but also its performance across various benchmarks, showcasing a leap in multimodal understanding. The architecture's core components, the CLIP-ViT-L for visual encoding and the MLP for vision-language cross-modal connection, work synergistically to enhance the model's capacity to integrate and interpret visual and linguistic inputs.Training methods have been optimized in LLaVA 1.5 to achieve unprecedented performance on 11 benchmarks, utilizing a two-stage approach that emphasizes efficient feature alignment and fine-tuning with VQA data specifically tailored for academic tasks. The paper highlights a shift towards more sophisticated multimodal alignment techniques, **replacing the original linear projection** with a more powerful **MLP vision-language connector**. This strategic improvement facilitates a deeper and more nuanced integration of visual and linguistic data. Moreover, the adoption of an MLP-based vision-language connector for alignment fusion methods further strengthens the model's ability to merge visual and textual representations effectively, ensuring closer alignment in the embedding space.The utilization of datasets such as VQA-v2, GQA, and other academic-task-oriented VQA datasets, enriched with OCR and region-level perception data, underscores the model's enhanced visual understanding and reasoning capabilities. These datasets play a crucial role in elevating LLaVA 1.5's performance, enabling it to set new standards with academic-task-oriented data. Through these advancements, LLaVA 1.5 not only pushes the boundaries of multimodal learning but also sets a new benchmark for future research in the field.
## **LLaVA 1.6: LLaVA-NeXT Improved reasoning, OCR, and world knowledge**
LLaVA-NeXT advances on LLaVA-1.5 by incorporating high-resolution image processing, enhancing visual reasoning and OCR capabilities, while maintaining a data-efficient design through knowledge transfer from its predecessor and a refined training process.
[](https://llava-vl.github.io/blog/2024-01-30-llava-next/)
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, Yong Jae Lee

ℹ️ More Information
**LLaVA-NeXT**: Represents a significant step forward in the evolution of large language models with visual capabilities, building upon the foundations laid by LLaVA-1.5. This model introduces several enhancements aimed at improving image resolution, visual reasoning, optical character recognition (OCR), and the integration of world knowledge, all while retaining the minimalist and data-efficient design of its predecessor. The architecture of LLaVA-NeXT is optimized for high performance, supporting input image resolutions up to 672x672, 336x1344, and 1344x336 pixels. This improvement facilitates a more detailed visual perception, which, coupled with an enhanced visual instruction tuning data mixture, significantly bolsters the model's reasoning and OCR capabilities. Furthermore, LLaVA-NeXT achieves efficient deployment through the use of SGLang, a feature that underscores its design's focus on performance and data efficiency.Training LLaVA-NeXT requires less than 1 million visual instruction tuning samples, leveraging the **pre-trained connector** from LLaVA-1.5 for efficient knowledge transfer. The training process, remarkably swift, utilizes 32 A100 GPUs and completes in approximately one day, a testament to the model's efficient design and deployment strategy. The alignment techniques in LLaVA-NeXT are particularly noteworthy, utilizing high-resolution images and a high-quality data mixture to enhance the model's capabilities in visual conversation and instruction following. The model's use of dynamic high-resolution techniques, known as 'AnyRes', allows for effective handling of images with varying resolutions, improving the model's overall visual understanding.The datasets employed in training LLaVA-NeXT, including LAION-GPT-V, ShareGPT-4V, DocVQA, SynDog-EN, ChartQA, DVQA, and AI2D, are meticulously chosen to augment the model's visual reasoning, OCR capabilities, and comprehension of charts and diagrams. This strategic selection aims to elevate the model's performance across a wide range of multimodal tasks, emphasizing its enhanced ability to process and understand complex visual information. Through these improvements, LLaVA-NeXT sets a new benchmark for models at the intersection of language and vision, offering unprecedented capabilities in visual reasoning, OCR, and the application of world knowledge in multimodal contexts.
## **PaliGemma: A Versatile and Transferable 3B Vision-Language Model**
PaliGemma is a compact, open-source vision-language model designed to be easily transferable to a diverse range of tasks. It combines a powerful SigLIP image encoder with the Gemma-2B language model, achieving strong performance on over 40 diverse tasks, including standard VLM benchmarks, remote-sensing, and segmentation. PaliGemma is pretrained using a multi-stage approach, focusing on maximizing the density of learning signal and providing different checkpoints with varying image resolutions. This versatile foundation model is easily fine-tuned for specific tasks and serves as a valuable tool for researchers and practitioners exploring the capabilities of VLMs.
[](https://arxiv.org/pdf/2407.07726) [](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/README.md) [](https://huggingface.co/spaces/big-vision/paligemma)
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, Thomas Unterthiner, Daniel Keysers, Skanda Koppula, Fangyu Liu, Adam Grycner, Alexey Gritsenko, Neil Houlsby, Manoj Kumar, Keran Rong, Julian Eisenschlos, Rishabh Kabra, Matthias Bauer, Matko Bošnjak, Xi Chen, Matthias Minderer, Paul Voigtlaender, Ioana Bica, Ivana Balazevic, Joan Puigcerver, Pinelopi Papalampidi, Olivier Henaff, Xi Xiong, Radu Soricut, Jeremiah Harmsen, Xiaohua Zhai

ℹ️ More Information
PaliGemma stands out as a highly versatile and transferable 3-billion parameter Vision-Language Model (VLM) meticulously designed for broad applicability across a wide spectrum of visual-language tasks. Its foundation lies in the integration of two powerful components: a SigLIP-So400m vision encoder, known for its exceptional performance despite its compact size, and the Gemma-2B language model, a pretrained autoregressive decoder-only model from the Gemma family. This combination enables PaliGemma to effectively process and understand both visual and textual information, making it adept at handling tasks ranging from image captioning and visual question answering to more specialized tasks like remote-sensing and segmentation. PaliGemma's architecture is streamlined and efficient. It uses a simple linear projection to align the visual features extracted by the SigLIP encoder with the vocabulary tokens of the Gemma language model, enabling seamless fusion of the two modalities. A key aspect of PaliGemma's training is the emphasis on "density of learning signal," prioritizing a broad range of skills and knowledge over achieving high zero-shot performance. This approach involves a multi-stage pretraining process that starts with unimodal pretraining of individual components using publicly available checkpoints, followed by extensive multimodal pretraining on a diverse mixture of large-scale vision-language tasks. Notably, PaliGemma deviates from the common practice of freezing the image encoder during pretraining, allowing it to learn spatial and relational understanding from complex tasks like captioning. To further enhance its capabilities, PaliGemma undergoes a resolution increase stage, where it is trained on higher-resolution images, enabling it to handle tasks that benefit from finer visual details. This multi-stage pretraining process results in a family of three PaliGemma checkpoints at varying image resolutions (224px, 448px, and 896px), each pretrained with broad visual knowledge. These checkpoints serve as strong base models that can be easily transferred to specific downstream tasks. PaliGemma's transferability is demonstrated through its impressive performance on over 30 academic benchmarks, including those involving multiple images, such as NLVR2 and short-video understanding tasks. The model's ability to adapt quickly to new tasks with minimal fine-tuning highlights its versatility and makes it a valuable tool for exploring and advancing the capabilities of VLMs. Furthermore, the model's open-source nature, along with its straightforward architecture and training recipe, encourages further research and experimentation within the VLM community, driving progress towards more powerful and general-purpose multimodal AI systems.
## **PaliGemma 2: A Family of Versatile VLMs for Transfer**
PaliGemma 2 is an upgraded family of open Vision-Language Models (VLMs) based on Gemma 2 language models, combined with the SigLIP-So400m vision encoder. It offers models in three sizes (3B, 10B, 28B) and three resolutions (224px², 448px², 896px²), trained in multiple stages for broad knowledge transfer. PaliGemma 2 achieves state-of-the-art results on various tasks, including OCR-related challenges like table/molecular/music score recognition, and long-form captioning.
[](https://arxiv.org/abs/2412.03555)
[](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/README.md)
[](https://huggingface.co/collections/google/paligemma-2-release-67500e1e1dbfdd4dee27ba48)
Andreas Steiner, André Susano Pinto, Michael Tschannen, Daniel Keysers, Xiao Wang, Yonatan Bitton, Alexey Gritsenko, Matthias Minderer, Anthony Sherbondy, Shangbang Long, Siyang Qin, Reeve Ingle, Emanuele Bugliarello, Sahar Kazemzadeh, Thomas Mesnard, Ibrahim Alabdulmohsin, Lucas Beyer and Xiaohua Zhai

ℹ️ More Information
PaliGemma 2 closely follows the architecture of its predecessor, PaliGemma. It uses a pre-trained SigLIP-So400m vision encoder. The embeddings from this encoder are mapped to the input space of the Gemma 2 language model using a *linear projection*. The combined visual and text embeddings are then fed into the Gemma 2 model, which autoregressively generates the output. The model comes in three size variants (2B, 9B, and 27B parameters in the Gemma 2 component, corresponding to 3B, 10B, and 28B total parameters) and is trained at three resolutions (224x224, 448x448, and 896x896 pixels). This allows for analysis of the interplay between model size, resolution, and transfer performance. The input image gets concatenated with the input text tokes and Gemma 2 autoregressively completes this prefix with an answer. PaliGemma 2's training follows a three-stage approach, similar to the original PaliGemma: **Stage 1:** The pre-trained SigLIP-So400m and Gemma 2 checkpoints are combined and trained jointly on a multimodal task mixture of 1 billion examples. The image resolution is 224px². **Stage 2:** Training continues for 50 million examples at 448px² resolution, then for 10 million examples at 896px². Tasks benefiting from higher resolution are upweighted. **Stage 3:** Fine-tuning the checkpoints from stage 1 or 2 on the target tasks. The training data mixture includes captioning, grounded captioning, OCR, visual question answering (VQA), detection, and instance segmentation. Notably, the training data relies heavily on *machine-generated labels* from publicly available specialist models, *avoiding the use of large commercial VLMs* for label generation. **Gemma 2 Language Models:** The core upgrade is the use of the more recent and capable Gemma 2 family of language models, replacing the original Gemma model in PaliGemma. **Resolution and Model Size Scaling:** PaliGemma 2 systematically explores the impact of both image resolution and language model size on transfer performance. This is a key contribution, as most prior work did not jointly study these factors with consistent training recipes.
## **AIMv2: Multimodal Autoregressive Pre-training of Large Vision Encoders**
AIMv2 is a family of generalist vision encoders that autoregressively generates both image patches and text tokens, achieving state-of-the-art performance in multimodal image understanding and strong results in vision benchmarks like localization, grounding, and classification, demonstrating scalability and efficiency.
[](https://arxiv.org/abs/2411.14402)
[](https://github.com/apple/ml-aim)
[](https://huggingface.co/apple/aimv2-large-patch14-224)
Enrico Fini, Mustafa Shukor, David Haldimann, Sai Aitharaju, Alexander Toshev, Marcin Eichner, Moin Nabi, Xiujun Li, Philipp Dufter, Michal Klein, Victor G. Turrisi da Costa, Louis Béthune, Zhe Gan, Alaaeldin El-Nouby

ℹ️ More Information
AIMv2 (Autoregressive Image Models v2) introduces a novel pre-training method for large-scale vision encoders that extends autoregressive pre-training to a multimodal setting, encompassing both images and text. The core architecture pairs a Vision Transformer (ViT) encoder with a causal multimodal decoder. The vision encoder processes raw image patches (using prefix attention), while the multimodal decoder autoregressively generates both image patches (using pixel MSE loss) and text tokens (using cross-entropy loss). Crucially, image patches and text tokens are treated as a single, unified sequence. This allows the model to learn a joint representation of visual and textual information. The image is always prepended to the beginning of text sequence. The training process is streamlined and efficient. It resembles that of AIM and LLMs, relying solely on the autoregressive objective. There are no specialized inter-batch communication methods or excessively large batch sizes are required. This contrasts with contrastive methods (e.g., CLIP, SigLIP), which are often more challenging to train and scale. The training data consists of a mixture of publicly available (DFN-2B, COYO) and proprietary datasets (HQITP), comprising both alt-text and synthetic captions. AIMv2 demonstrates strong scaling properties, consistently improving performance with increased data or model parameters. The model family includes variants ranging from 300 million to 3 billion parameters. A key optimization is the use of prefix attention within the vision encoder, enabling bidirectional attention during inference without fine-tuning. Other architectural choices include the incorporation of SwiGLU and RMSNorm, inspired by recent successes in language modeling. AIMv2 excels in a variety of tasks. It performs favorably on multimodal understanding benchmarks compared to state-of-the-art vision-language pre-trained methods . It also exhibits strong performance on open-vocabulary object detection and referring expression comprehension, surpassing DINOv2. Additionally, it achieves impressive recognition performance with a frozen trunk. The model supports native image resolution and adaptation to zero-shot recognition, demonstrating its flexibility. Post-training strategies, including high-resolution adaptation, further enhance the model's capabilities. Ablation studies demonstrate the importance of joint image and text modeling, validate design choices, and explore scaling characteristics.
## **Apollo: An Exploration of Video Understanding in Large Multimodal Models**
Apollo is a state-of-the-art family of Large Multimodal Models (LMMs) designed for video understanding, achieving superior performance across different model sizes by leveraging "Scaling Consistency" and exploring video-specific aspects like sampling, architectures, data composition, and training schedules. The 7B model is start of the art, and Apollo-3B outperforms most existing 7B models.
[](https://arxiv.org/abs/2412.10360)
[](https://apollo-lmms.github.io/)
Orr Zohar, Xiaohan Wang, Yann Dubois, Nikhil Mehta, Tong Xiao, Philippe Hansen-Estruch, Licheng Yu, Xiaofang Wang, Felix Juefei-Xu, Ning Zhang, Serena Yeung-Levy, Xide Xia

ℹ️ More Information
Apollo leverages the Qwen2.5 series of Large Language Models (LLMs) with 1.5B, 3B, and 7B parameters. The key architectural innovation is the combination of a SigLIP-SO400M image encoder and an InternVideo2 video encoder. Features from both encoders are interpolated and concatenated channel-wise before being fed into a Perceiver Resampler, which outputs 32 tokens per frame. This combination was empirically found to be superior to other encoder choices. The model uses a 3-stage training approach. Critically, the paper introduces the concept of "Scaling Consistency," demonstrating that design decisions made on smaller models and datasets (up to a critical size) effectively transfer to larger models. This allows for more efficient experimentation. The paper also advocates for frames-per-second (fps) sampling during training, as opposed to uniform frame sampling, and demonstrates its superiority. The optimal number of tokens is 8-32 per frame. It also includes a curated benchmark, ApolloBench, that reduces evaluation time by 41x compared to existing benchmarks while maintaining high correlation and focusing on temporal reasoning and perception. The exploration also includes Token Resampling showing that Perceiver resampling has a good performace. Token Integration is also discussed: Adding tokens (text, learned, etc.) between the video tokens derived from different frames
or clips is sufficient for efficient token integration. Training Stages is also disscussed, concluding that progressively unfreezing the different components in different stages leads to superior model training dynamics. Finally, training the Video Encoder is discussed. The paper concludes that Finetuning video encoders on only video data further improves overall performance,
especially on reasoning and domain-specific tasks. Data Composition is also studied. It concludes that Data mixture matters, and including a moderate amount of text data and maintaining a
slight video-heavy mix leads to optimal performance.
## **ARIA: An Open Multimodal Native Mixture-of-Experts Model**
ARIA is an open-source, multimodal native Mixture-of-Experts (MoE) model designed to seamlessly integrate and understand diverse modalities like text, code, images, and video, achieving state-of-the-art performance in its class. It features a fine-grained MoE decoder for efficient parameter utilization, a lightweight visual encoder, and a 4-stage training pipeline that builds capabilities in language understanding, multimodal comprehension, long context handling, and instruction following.
[](https://arxiv.org/abs/2410.05993)
[](https://github.com/rhymes-ai/Aria)
[](https://huggingface.co/blog/RhymesAI/aria)
Dongxu Li, Yudong Liu, Haoning Wu, Yue Wang, Zhiqi Shen, Bowen Qu, Xinyao Niu, Fan Zhou, Chengen Huang, Yanpeng Li, Chongyan Zhu, Xiaoyi Ren, Chao Li, Yifan Ye, Peng Liu, Lihuan Zhang, Hanshu Yan, Guoyin Wang, Bei Chen, Junnan Li

ℹ️ More Information
ARIA's architecture is centered around a fine-grained Mixture-of-Experts (MoE) decoder, which is more efficient than traditional dense decoders. This MoE approach activates 3.5B parameters per text token and 3.9B per visual token, out of a total of 24.9B parameters. The model uses 66 experts in each MoE layer, with 2 shared across all inputs for common knowledge, and 6 activated per token by a router. The visual encoder is a lightweight (438M parameter) Vision Transformer (ViT) combined with a projection module. The ViT processes images at various resolutions (medium, high, and ultra-high), preserving aspect ratios. The projection module uses cross-attention and an FFN layer to convert image embeddings into visual tokens, which are then integrated with text tokens by the MoE. ARIA's training uses a 4-stage pipeline: (1) Language pre-training (6.4T text tokens, 8K context window); (2) Multimodal pre-training (400B multimodal tokens, including interleaved image-text, synthetic image captions, document transcriptions and QA, video captions and QA); (3) Multimodal long-context pre-training (extending context to 64K tokens); and (4) Multimodal post-training (instruction following with 20B tokens). The data curation process is rigorous, incorporating techniques like de-duplication, quality filtering, and data clustering. The training infrastructure avoids pipeline parallelism, using a combination of expert parallelism and ZeRO-1 data parallelism, which contributes to efficient training without the need for tensor parallelism. A load-balancing loss and z-loss are used to stabilize training.
The paper demonstrates that, despite having modality-generic experts, ARIA naturally develops expert specialization during pre-training. Analysis of expert activation shows distinct visual specialization in several layers, particularly for image, video, and PDF content. ARIA also shows excellent performance in handling long-context multimodal data, surpassing other open models and competing favorably with proprietary models in tasks like long video and document understanding.
## **EVE: Unveiling Encoder-Free Vision-Language Models**
EVE is an encoder-free vision-language model (VLM) that directly processes images and text within a unified decoder-only architecture, eliminating the need for a separate vision encoder. It achieves competitive performance with encoder-based VLMs of similar size on multiple vision-language benchmarks using only 35M publicly accessible data, with the model efficiently handling high-resolution images with arbitrary aspect ratios.
[](https://arxiv.org/abs/2406.11832)
[](https://github.com/baaivision/EVE)
[](https://huggingface.co/BAAI/EVE-7B-HD-v1.0)
Haiwen Diao, Yufeng Cui, Xiaotong Li, Yueze Wang, Huchuan Lu, Xinlong Wang

ℹ️ More Information
**EVE (Encoder-free Vision-language modEl)**: This model distinguishes itself by completely removing the vision encoder component typically found in VLMs. Instead, it directly integrates visual information into a decoder-only architecture (based on Vicuna-7B). This is achieved through a novel **Patch Embedding Layer (PEL)** that processes image patches directly, combined with a **Patch Aligning Layer (PAL)** that facilitates learning from a pre-trained vision encoder (CLIP-ViT-L/14) without updating the encoder itself. Crucially, EVE does *not* use a traditional image encoder during inference. The **PEL** uses a convolution layer and average pooling to create 2D feature maps from the input image. It then employs cross-attention (CA1) within a limited receptive field to enhance these features. A special `` token provides a holistic view of each patch feature, and a learnable newline token `` is inserted after each row of patch features to represent the 2D structure. The **PAL** aligns EVE's patch features with those from a frozen, pre-trained vision encoder (CLIP-ViT-L/14). This is done hierarchically, aggregating features across multiple layers of the decoder and using a layer-wise cross-attention (CA3) mechanism. A Mean Squared Error (MSE) loss between EVE's features and the vision encoder's features encourages alignment. This "implicit" supervision from the vision encoder improves visual understanding. Importantly, PAL is *only* used during training, not inference. The training process occurs in three stages: **LLM-guided Pre-training:** Only the PEL and PAL are trained, aligning the visual features with the frozen LLM (Vicuna-7B). This stage uses a subset (16M) of the total training data. **Generative Pre-training:** The entire model (including the LLM) is trained, using the full 33M dataset. Both text prediction (cross-entropy loss) and visual alignment (MSE loss) are used. **Supervised Fine-tuning:** The entire model is fine-tuned on instruction-following datasets (LLaVA-mix-665K and others). The key innovations that allow EVE to work well without a vision encoder are: **LLM-Centric Pre-alignment:** Stage 1 is critical for preventing model collapse and accelerating convergence. Aligning visual features *before* fully training the LLM is essential. **Vision Recognition Capability via Extra Supervision:** The PAL provides supervision from a pre-trained vision encoder during training, which enhances visual understanding without requiring the encoder during inference. **Flexible Input Handling:** The architecture naturally handles images of arbitrary aspect ratios and resolutions, without needing resizing, padding, or partitioning. No reliance on vision encoder: The image are directly input into the LLM model.
EVE uses a curated dataset of 33M publicly available image-text pairs for pre-training, with captions generated by Emu2 and LLaVA-1.5. Supervised fine-tuning utilizes datasets like LLaVA-mix-665K, AI2D, DocVQA, and others.
Okay, let's break down the information from the provided paper on EVEv2 and create a feature extraction similar to your examples.
## **EVEv2: Improved Baselines for Encoder-Free Vision-Language Models**
EVEv2 represents a significant advancement in encoder-free vision-language models (VLMs), addressing limitations of previous approaches by introducing a "Divide-and-Conquer" architecture that maximizes scaling efficiency, reduces inter-modality interference, and achieves strong performance with superior data efficiency.
[](https://github.com/baaivision/EVE/blob/main/EVEv2/images/EVEv2.0.pdf)
[](https://github.com/baaivision/EVE/blob/main/EVEv2/README.md)
[](https://huggingface.co/BAAI/EVE-7B-HD-v2.0)
Haiwen Diao, Xiaotong Li, Yufeng Cui, Yueze Wang, Haoge Deng, Ting Pan, Wenxuan Wang, Huchuan Lu, Xinlong Wang

ℹ️ More Information
EVEv2 departs from the traditional encoder-based VLM approach. Instead of relying on a pre-trained vision encoder (like CLIP), it builds visual perception *directly within* a decoder-only Large Language Model (LLM). Key architectural features include: **Divide-and-Conquer:** This is the core innovation. Instead of mixing visual and textual information throughout the entire LLM, EVEv2 introduces *modality-specific* components. This means separate attention matrices (query, key, value), Layer Normalization layers, and Feed-Forward Networks for visual and textual tokens. This reduces interference and allows for more efficient learning. It's a fully sparse, decoder-only architecture. **Patch Embedding Layer:** A minimalist patch embedding layer is learned *from scratch*. This avoids the inductive biases of pre-trained vision encoders. It uses two convolutional layers (Conv1 and Conv2) to process image patches. **Lossless Encoding:** Unlike some encoder-free models that use discrete tokenization (which can lose information), EVEv2 aims for lossless encoding of visual information. **LLM Adaptation:** The architecture is designed for seamless adaptation to existing LLMs. The paper experiments with Vicuna-7B and Qwen2-7B. **Multi-Stage Training:** A four-stage training process is used: **LLM-guided Pre-aligning:** Only the patch embedding layer is trained, using re-captioned web data (EVE-recap-10M). The LLM is frozen. This establishes a basic alignment between visual and textual representations. **Vision Perception Learning:** Vision layers within the LLM are trained, using progressively larger datasets and image resolutions. The LLM weights are still frozen. **Vision-Text Fully alligning:** The entire network is update. **Supervised Fine-tuning (SFT):** The entire model is fine-tuned on question-answering and instruction-following datasets. **DenseFusion++:** A new, efficient captioning engine is introduced to generate high-quality image-text pairs for training. This is crucial for building strong visual perception from scratch. It leverages multiple vision experts. **Data Efficiency:** A key focus of the research is demonstrating that EVEv2 can achieve strong performance with *less* data than comparable encoder-based models, thanks to its efficient architecture.
## **Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling**
Janus-Pro significantly improves upon the original Janus model by optimizing the training strategy, expanding the training data, and scaling up the model size, resulting in enhanced multimodal understanding, text-to-image instruction-following, and generation stability.
[](https://arxiv.org/abs/2501.17811)
[](https://github.com/deepseek-ai/Janus)
[](https://huggingface.co/deepseek-ai/Janus-Pro-7B)
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan

ℹ️ More Information
Janus-Pro maintains the core architecture of Janus, which decouples visual encoding for multimodal understanding and generation. It uses a unified autoregressive transformer but employs separate encoders for understanding (SigLIP) and generation (VQ tokenizer). The understanding encoder extracts semantic features, flattened and mapped to the LLM's input space via an "understanding adaptor." The generation encoder converts images to discrete IDs, flattened and mapped via a "generation adaptor." These feature sequences are concatenated and fed to the LLM. The model includes a built-in prediction head (from the LLM) and a randomly initialized prediction head for image generation. The key improvements in Janus-Pro lie in three areas: **Optimized Training Strategy:** Janus-Pro uses a three-stage training process. **Stage I:** Focuses on training the adaptors and image head with longer training on ImageNet, improving parameter initialization. **Stage II:** Unified pretraining, updating all components *except* the understanding and generation encoders. Crucially, it *removes* ImageNet data from this stage and uses only "normal" text-to-image data, improving efficiency. **Stage III:** Supervised fine-tuning, further updating the understanding encoder. The data ratio (multimodal:text:text-to-image) is adjusted from 7:3:10 to 5:1:4, improving multimodal understanding without sacrificing generation. **Data Scaling:** Janus-Pro significantly expands the training data. **Multimodal Understanding:** Adds ~90 million samples from sources like DeepSeek-VL2, including image captions (YFCC), table/chart/document understanding (Docmatix), MEME understanding, and Chinese conversational data. **Visual Generation:** Adds ~72 million *synthetic* aesthetic data samples, balancing real and synthetic data 1:1 during unified pretraining. This improves generation stability and aesthetic quality. **Model Scaling:** Janus-Pro scales up from 1.5B to 7B LLM parameters (DeepSeek-LLM). This significantly improves convergence speed for both understanding and generation. The training uses a sequence length of 4096, SigLIP-Large-Patch16-384 for understanding, and a VQ tokenizer with a codebook of 16,384 for generation. Adaptors are two-layer MLPs. Training is performed with HAI-LLM, a distributed training framework. Evaluation is conducted on benchmarks like GQA, MME, SEED, MMB, MM-Vet, MMMU (for understanding) and GenEval, DPG-Bench (for generation). Janus-Pro achieves state-of-the-art results among unified multimodal models, demonstrating significant improvements in both multimodal understanding and text-to-image generation.
## **LLaVA-CoT: Let Vision Language Models Reason Step-by-Step**
LLaVA-CoT is a novel Vision-Language Model (VLM) designed to perform autonomous, multi-stage reasoning, enabling it to tackle complex visual question-answering tasks by independently engaging in sequential stages of summarization, visual interpretation, logical reasoning, and conclusion generation.
[](https://arxiv.org/abs/2411.10440)
[](https://github.com/PKU-YuanGroup/LLaVA-CoT)
[](https://huggingface.co/Xkev/Llama-3.2V-11B-cot)
Guowei Xu, Peng Jin, Hao Li, Yibing Song, Lichao Sun, Li Yuan

ℹ️ More Information
LLaVA-CoT builds upon the Llama-3.2-Vision model and introduces a structured, four-stage reasoning process: Summary (briefly outlines the task), Caption (describes relevant image parts), Reasoning (detailed analysis), and Conclusion (provides the final answer). Each stage is marked with specific tags (, , , ) to maintain clarity. Unlike traditional Chain-of-Thought (CoT) prompting, LLaVA-CoT promotes structured thinking by first organizing the problem and known information, then performing detailed reasoning, and finally deriving a conclusion. The model is trained on the newly compiled LLaVA-CoT-100k dataset. This dataset integrates samples from various visual question answering sources and providing structured reasoning instructions. The dataset contains 99k image and Question answer pairs using GPT-4o to provide details. Data is gathered from general VQA datasets (ShareGPT4V, ChartQA, A-OKVQA, DocVQA, PISC, CLEVR) and Science targeted VQA (AI2D, GeoQA+, ScienceQA, CLEVR-Math). The paper also proposes a novel inference-time stage-level beam search method. This method generates multiple candidate results at *each* stage of the reasoning process, selecting the best to continue, improving performance and scalability. This contrasts with traditional best-of-N or sentence-level beam search. The entire model is trained using the Supervised-Fine Tuning.
## **LLM2CLIP: Powerful Language Model Unlocks Richer Visual Representation**
LLM2CLIP is a fine-tuning approach which integrates Large Language Models (LLMs) with pre-trained CLIP visual encoders. It improves the model by using the LLM's ability to proccess and understant long captions, open-world knowledge.
[](https://arxiv.org/abs/2411.04997)
[](https://github.com/microsoft/LLM2CLIP)
[](https://huggingface.co/microsoft/LLM2CLIP-EVA02-B-16)
Weiquan Huang, Aoqi Wu, Yifan Yang, Xufang Luo, Yuqing Yang, Liang Hu, Qi Dai, Xiyang Dai, Dongdong Chen, Chong Luo, Lili Qiu

ℹ️ More Information
LLM2CLIP is fine-tuning approach. It integrates LLM (Large Language Models) to already pretrained CLIP visual encoders. The main problem which is tried to be solved is that; LLM's text understanding capability is not reflected on CLIP models. The authors highlight that directly incorporating LLMs into CLIP often fails due to the poor separability of LLM output features. To tackle this, they introduce a two-stage approach. **Stage 1: Caption Contrastive (CC) Fine-tuning:** The LLM (specifically Llama-3 8B) is fine-tuned using a contrastive learning framework on a dataset of image captions (CC3M). This stage *doesn't train for autoregressive capabilities*, instead, it is transforming the causal attention to bidirectional, to function it as an encoder. This stage aims to improve the discriminative power of the LLM's output space, making it easier to distinguish between different captions, using supervised SimCSE loss. **Stage 2: CLIP Vision Encoder Fine-tuning:** The pre-trained CLIP visual encoder is fine-tuned using the CC-fine-tuned LLM, now acting as a "super" text encoder. The LLM's gradients are *frozen* during this stage to preserve its acquired knowledge and reduce computational cost. Learnable adapters (linear layers) are added after the LLM to facilitate alignment with the CLIP visual encoder.
Instead of the typical image-text contrastive loss, a caption-to-caption contrastive framework is used during LLM fine-tuning. This forces the LLM to produce distinct representations for different captions describing the same image. It uses Supervised SimCSE. Makes the model encoder. Freezing the LLM during CLIP fine-tuning is crucial for efficiency and preserving the LLM's knowledge. These adapters bridge the gap between the frozen LLM and the CLIP visual encoder. The method is surprisingly efficient, requiring only a small amount of open-source data (15M or even 3M image-text pairs) and a single epoch of training in some cases. It leverages LoRA (Low-Rank Adaptation) for efficient fine-tuning. LLM2CLIP can effectively leverage dense captions (detailed image descriptions), a known limitation of standard CLIP. Uses ShareCaptioner-modified CC-3M (for CC fine-tuning), Wikitext-103, and a combination of CC-3M, CC-12M, YFCC-15M, and Recaption-1B for CLIP fine-tuning. The paper demonstrates that, after fine-tuning of the output space of the LLM, using LLM has a significant impact and it substantially improves the performance on downstream tasks.
## **Maya: An Instruction Finetuned Multilingual Multimodal Model**
Maya is an open-source Multimodal Multilingual Vision Language Model (mVLM) designed to address the limitations of current VLMs in handling low-resource languages and diverse cultural contexts, achieved by creating a new multilingual image-text pretraining dataset, performing toxicity analysis and mitigation, and fine-tuning for enhanced cultural and linguistic comprehension.
[](https://arxiv.org/abs/2412.07112)
[](https://github.com/nahidalam/maya)
[](https://huggingface.co/maya-multimodal/maya)
Nahid Alam, Karthik Reddy Kanjula, Bala Krishna S Vegesna, S M Iftekhar Uddin, Drishti Sharma, Abhipsha Das, Shayekh Bin Islam, Surya Guthikonda, Timothy Chung, Anthony Susevski, Ryan Sze-Yin Chan, Roshan Santhosh, Snegha A, Chen Liu, Isha Chaturvedi, Ashvanth.S, Snehanshu Mukherjee, Alham Fikri Aji

ℹ️ More Information
**Architecture:** Maya builds upon the LLaVA 1.5 framework. It uses the Aya-23 8B model as its Large Language Model (LLM) due to Aya's strong multilingual capabilities (trained on 23 languages). Critically, it *replaces* the CLIP vision encoder used in LLaVA with SigLIP. This is motivated by SigLIP's superior performance, multilingual support, and ability to handle variable-length image patches (allowing for more flexible input sizes). The visual features from SigLIP (`Zv = g(Xv)`) are passed through a trainable projection matrix (`W`, a 2-layer MLP with GELU activation) to align them with the LLM's embedding space, producing visual features `Hv`. The architecture is fairly standard for this type of model, concatenating visual and textual features for input to the LLM. The training process involves two main phases: pretraining and finetuning. **Pretraining:** The model is pretrained on a newly created multilingual image-text dataset. This dataset is derived from the English-only LLaVA pretraining dataset (558k image-text pairs) and translated into seven additional languages (Chinese, French, Spanish, Russian, Hindi, Japanese, and Arabic) using a sophisticated translation pipeline. This pipeline uses the Aya 35B model, optimized prompt engineering (determined empirically using BLEU and N-gram scores), and a batch processing approach with quality checks. Crucially, this dataset undergoes *toxicity filtering*. LLaVAGuard and Toxic-BERT are used to identify and remove toxic image-caption pairs, creating a "toxicity-free" version of the dataset (removing 7,531 toxic images). The pretraining uses a learning rate of 1e-3 and a cosine scheduler. Only the projection matrix is trained during pretraining. **Finetuning:** The pretrained model is then instruction-tuned using the PALO 150K instruction-tuning dataset (which covers 10 languages). Full finetuning is performed (as opposed to LoRA), with frozen vision encoder and LLM. The core alignment technique is the trainable projection matrix (the 2-layer MLP) that maps the SigLIP visual features into the embedding space of the Aya-23 LLM. This is a simple but effective method, common in many VLMs. The paper *explicitly* states they did *not* use more complex alignment techniques like gated soft-attention (Flamingo) or Q-Former (BLIP-2) in this phase, reserving those for future work. **Pretraining Dataset:** A new multilingual dataset created by translating and filtering the LLaVA pretraining dataset. This dataset is a key contribution of the paper. The translation process and toxicity filtering are described in detail. **Instruction Tuning Dataset:** PALO 150K instruction-tuning dataset. **Evaluation Datasets**: PALO multilingual evalution, VizWiz, GQA, ScienceQA, TextVQA, POPE, MMBench, MM-Vet, MME. **Multilingual Image-Text Pretraining Dataset:** A new dataset of 558,000 images in eight languages. **Toxicity Analysis and Mitigation:** A thorough analysis of toxicity in the original LLaVA dataset and the creation of a toxicity-free version. This is a significant and novel aspect. **Multilingual Model:** A model (Maya) that shows improved performance in understanding cultural and linguistic nuances, especially in comparison to models trained primarily on English data. The results show that Maya performs comparably to or better than models of similar size (LLaVA-7B) and often approaches the performance of larger models (PALO-13B) on multilingual benchmarks. The toxicity filtering has a minimal impact on overall performance, suggesting that valuable information isn't lost by removing toxic content. The paper includes both quantitative benchmark results and qualitative examples demonstrating the model's capabilities.
## **MiniMax-01: Scaling Foundation Models with Lightning Attention**
MiniMax-01 is a series of large foundation models, including MiniMax-Text-01 and MiniMax-VL-01, that achieve performance comparable to top-tier models (like GPT-4o and Claude-3.5-Sonnet) while offering significantly longer context windows (up to 4 million tokens). It achieves this through a novel architecture incorporating lightning attention (a highly efficient linear attention variant), Mixture of Experts (MoE), and optimized training/inference frameworks.
[](https://arxiv.org/abs/2501.08313)
[](https://github.com/MiniMax-AI/MiniMax-01)
[](https://huggingface.co/MiniMaxAI/MiniMax-VL-01)
MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, Enwei Jiao, Gengxin Li, Guojun Zhang, Haohai Sun, Houze Dong, Jiadai Zhu, Jiaqi Zhuang, Jiayuan Song, Jin Zhu, Jingtao Han, Jingyang Li, Junbin Xie, Junhao Xu, Junjie Yan, Kaishun Zhang, Kecheng Xiao, Kexi Kang, Le Han, Leyang Wang, Lianfei Yu, Liheng Feng, Lin Zheng, Linbo Chai, Long Xing, Meizhi Ju, Mingyuan Chi, Mozhi Zhang, Peikai Huang, Pengcheng Niu, Pengfei Li, Pengyu Zhao, Qi Yang, Qidi Xu, Qiexiang Wang, Qin Wang, Qiuhui Li, Ruitao Leng, Shengmin Shi, Shuqi Yu, Sichen Li, Songquan Zhu, Tao Huang, Tianrun Liang, Weigao Sun, Weixuan Sun, Weiyu Cheng, Wenkai Li, Xiangjun Song, Xiao Su, Xiaodong Han, Xinjie Zhang, Xinzhu Hou, Xu Min, Xun Zou, Xuyang Shen, Yan Gong, Yingjie Zhu, Yipeng Zhou, Yiran Zhong, Yongyi Hu, Yuanxiang Fan, Yue Yu, Yufeng Yang, Yuhao Li, Yunan Huang, Yunji Li, Yunpeng Huang, Yunzhi Xu, Yuxin Mao, Zehan Li, Zekang Li, Zewei Tao, Zewen Ying, Zhaoyang Cong, Zhen Qin, Zhenhua Fan, Zhihang Yu, Zhuo Jiang, Zijia Wu
ℹ️ More Information
**Hybrid Attention:** The core innovation is the hybrid attention mechanism. It primarily uses "lightning attention" (an I/O-aware implementation of TransNormer linear attention) for efficiency. However, to maintain strong retrieval capabilities, it strategically inserts a standard transformer block with softmax attention after every seven transnormer blocks (with lightning attention). This is a key differentiator from purely linear attention models, which often struggle with retrieval tasks. **Mixture of Experts (MoE):** To scale the model efficiently, MiniMax-01 employs a Mixture of Experts (MoE) architecture in the feed-forward layers. It has a massive 456 billion total parameters, but only 45.9 billion are activated for each token, using 32 experts with a top-2 routing strategy. This allows for a large model capacity without a corresponding increase in computational cost per token. **Vision-Language Model (MiniMax-VL-01):** The vision-language model (MiniMax-VL-01) builds upon MiniMax-Text-01 by integrating a lightweight Vision Transformer (ViT) module. It uses a dynamic resolution strategy, resizing input images to various sizes (from 336x336 to 2016x2016) and concatenating features from both resized patches and a standard thumbnail. It *does not* use pooling or downsampling on the visual features, relying instead on the long-context capabilities of the architecture. Demonstrates the viability of linear attention at a massive scale, achieving performance comparable to top-tier models while significantly extending the context window. **Long-Context Capability:** Supports context inputs of up to 4 million tokens, with strong performance in long-context evaluations. **Efficient Training and Inference Framework:** Introduces several novel algorithmic and engineering optimizations to handle the hybrid architecture, MoE, and long contexts efficiently.
**Pre-training:** A meticulously curated corpus incorporating academic literature, books, web content, and programming code. **Vision-Language Pre-training (VL-01):** A substantial image-caption dataset (694 million unique pairs) and a dataset of 100 million images with fine-grained descriptions. **Vision-Language Instruction Data (VL-01):** A comprehensive and diverse instruction-based dataset synthesized from a wide array of image-related tasks. **Alignment Datasets** are also mentioned but are not detailed in the ocr. **Hybrid Attention:** The core fusion method is the hybrid attention mechanism, which combines the efficiency of lightning attention (linear) with the retrieval capabilities of softmax attention. **MoE Routing:** The MoE architecture with its top-2 routing strategy allows for selective activation of experts, enhancing model capacity without increasing computational cost per token. A global router is used for load balancing. **Vision-Language Fusion (VL-01):** Visual features from the ViT are projected into the embedding space of the LLM using a two-layer MLP. The raw, high-dimensional visual features are directly used without pooling or downsampling, leveraging the long-context capabilities of the architecture. **Varlen Ring Attention and LASP+:** These algorithms enable efficient handling of long, variable-length sequences and data packing during both training and inference. Post-Training and Alignment: Various techniques are used for alignment.
## **NVLM: Open Frontier-Class Multimodal LLMs**
NVLM 1.0 is a family of multimodal large language models (LLMs) achieving state-of-the-art results on vision-language tasks, rivaling proprietary and open-access models. It demonstrates improved text-only performance after multimodal training and offers a comprehensive comparison of decoder-only and cross-attention-based architectures, introducing a novel hybrid architecture and a 1-D tile-tagging design for high-resolution images.
[](https://arxiv.org/abs/2409.11402)
[](https://github.com/NVIDIA/Megatron-LM/tree/NVLM-1.0)
[](https://huggingface.co/nvidia/NVLM-D-72B)
Wenliang Dai, Nayeon Lee, Boxin Wang, Zhuolin Yang, Zihan Liu, Jon Barker, Tuomas Rintamaki, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping

ℹ️ More Information
**NVLM (NVIDIA Vision Language Model)** introduces a family of models with three primary architectures: NVLM-D (Decoder-only), NVLM-X (Cross-attention-based), and NVLM-H (Hybrid). All models share a common vision pathway, employing a frozen InternViT-6B-448px-V1-5 vision encoder with dynamic high-resolution (DHR) processing. DHR involves dividing input images into tiles (up to 6, with varying aspect ratios) and a downscaled global "thumbnail" tile. These tiles are processed by the vision encoder, and the resulting 1024 tokens per tile are downsampled to 256 via pixel shuffling. **NVLM-D (Decoder-only):** Connects the vision encoder to the LLM (Qwen2-72B-Instruct or Nous-Hermes-2-Yi-34B) via a 2-layer MLP projector. It introduces a novel *1-D tile-tagging* design for handling high-resolution images. Text-based tile tags (e.g., ``) are inserted before the flattened image tokens of each tile to provide positional information to the LLM. Training involves pretraining (frozen LLM and vision encoder, training only the MLP) and supervised fine-tuning (SFT) (unfrozen LLM and MLP). Crucially, a high-quality text-only SFT dataset is included to maintain/improve text-only performance. **NVLM-X (Cross-attention-based):** Uses gated cross-attention layers to process image tokens, similar to Flamingo, but *without* a Perceiver resampler. Image features are projected to the LLM's hidden dimension with a one-layer MLP. Gated X-attention layers are interleaved with LLM self-attention layers. Training also has pretraining and SFT stages. The LLM backbone is unfrozen during SFT, and a high-quality text-only dataset is used. 1-D tile tags are also used, but within the X-attention layers. **NVLM-H (Hybrid):** Combines aspects of NVLM-D and NVLM-X. The thumbnail image tokens are processed by the LLM's self-attention layers (like NVLM-D), while the regular tile tokens are processed by gated cross-attention (like NVLM-X). This aims to balance multimodal reasoning with computational efficiency. It also uses 1-D tile tags in cross-attention. The 1-D tile-tagging design significantly improves performance, especially on OCR-related tasks, compared to simply concatenating image tokens or using 2D grid/bounding box tags. The authors emphasize that dataset quality and task diversity are more important than sheer scale, even during pretraining. NVLM models achieve strong performance on *both* vision-language and text-only tasks. This is achieved by including a high-quality text-only dataset during SFT and incorporating multimodal math and reasoning data. Decoder VS X-Attention: Cross attention based models are more efficient in high-resolution images. However, Decoder models provides unified multimodel reasoning and higher accuracy in OCR-related tasks. Curated from open-source datasets, including captioning (COCO, CC3M, SBU, LAION-115M), VQA (VQAv2, Visual Genome, DVQA), document understanding (Docmatix), OCR/Scene-Text (various datasets), and Math (CLEVR-Math). Emphasis on quality over quantity. A diverse collection of task-oriented datasets, including captioning, VQA, chart/diagram understanding, document understanding, OCR, math, and science datasets. High-quality text-only data from various sources (ShareGPT, SlimOrca, EvolInstruct, etc.) and categories (general, math, coding) is crucial for maintaining/improving text-only performance. Refined using GPT-40 and GPT-40-mini. NVLM models are evaluated on a wide range of vision-language benchmarks (MMMU, MathVista, OCRBench, AI2D, ChartQA, DocVQA, TextVQA, RealWorldQA, VQAv2) and text-only benchmarks (MMLU, GSM8K, MATH, HumanEval).
## **OmniVLM: A Token-Compressed, Sub-Billion-Parameter Vision-Language Model for Efficient On-Device Inference**
OmniVLM is a sub-billion-parameter vision-language model designed for efficient on-device inference, featuring a token compression mechanism that reduces visual token sequence length from 729 to 81, drastically cutting computational overhead while maintaining visual-semantic fidelity. It uses Qwen2.5-0.5B-Instruct model, Google's SigLIP-400M.
[](https://arxiv.org/abs/2412.11475)
[](https://github.com/NexaAI/nexa-sdk)
[](https://huggingface.co/NexaAIDev/OmniVLM-968M)
Wei Chen, Zhiyuan Li, Shuo Xin

ℹ️ More Information
OmniVLM addresses the challenges of deploying vision-language models (VLMs) on resource-constrained edge devices. It achieves this through a novel token compression mechanism and a multi-stage training pipeline. The core innovation is the **image token compression**, which transforms the embedding dimensions from [batch_size, 729, hidden_size] to [batch_size, 81, hidden_size] within the projection layer. This 9x reduction in token count is achieved through reshaping, chosen after empirical comparison against convolution-based methods. The model architecture (Figure 1) builds upon the LLaVA framework, employing Google's SigLIP-400M as the vision encoder, Qwen2.5-0.5B-Instruct as the base language model, and a Multi-Layer Perceptron (MLP) as the projection layer. The training pipeline consists of three stages: (1) **Pretraining** on large-scale image-caption pairs (primarily from the LLaVA pretraining dataset) to learn visual-linguistic alignments, training only the projection layer; (2) **Supervised Fine-Tuning (SFT)** on a mix of datasets (LLaVA, UnimmChat, and internal data) to improve contextual understanding and conversational coherence, training the projector and LLM while freezing the vision encoder; and (3) **Minimal-Edit Direct Preference Optimization (DPO)**, using a teacher model to create minimally edited corrections to the base model's outputs, forming chosen-rejected pairs for preference learning, again freezing the vision encoder and training the projector and LLM. The DPO process leverages GPT-4V to generate synthetic training pairs. Extensive experiments show that the 81-token configuration provides the optimal balance between computational efficiency and model performance. OmniVLM outperforms nanoLLAVA on benchmarks like ScienceQA, POPE, and MMMU, demonstrating improved reasoning, multimodal comprehension, and generalization. Crucially, it achieves significantly faster inference speeds (9.1x faster time-to-first-token and 1.5x higher decoding speed compared to nanoLLAVA on a laptop, and 8x faster TTFT on a mobile device), making it suitable for deployment on edge devices like smartphones and laptops.
## **Pixtral 12B: A Cutting-Edge Open Multimodal Language Model**
Pixtral 12B is a 12-billion-parameter multimodal language model developed by Mistral AI, designed to excel in both understanding images and text, achieving leading performance on various multimodal benchmarks. The core of the VLM is built upon the transformer architecture. A strong aspect of the VLM is, Pixtral 12B is trained with a new vision encoder from scratch to natively support variable image sizes and aspect ratios.
[](https://arxiv.org/abs/2410.07073)
[](https://github.com/huggingface/transformers/blob/main/docs/source/en/model_doc/pixtral.md)
[](https://huggingface.co/mistralai/Pixtral-12B-2409)
Pravesh Agrawal, Szymon Antoniak, Emma Bou Hanna, Baptiste Bout, Devendra Chaplot, Jessica Chudnovsky, et al. (Mistral AI Science Team)

ℹ️ More Information
**Pixtral 12B** has two main components, *vision encoder (Pixtral-ViT)*, which tokenizes images and a *multimodal decoder*, which predicts the next token given a sequence of text and images. Pixtral can take an arbitrary number of images as an input, provided they fit within its 128K context window. **The vision encoder (Pixtral-ViT)** is trained from scratch with a novel ROPE-2D implementation, allowing it to process images at their native resolution and aspect ratio. The model can flexibly process images at low resolution in latency-constrained settings, while processing images at high resolution when fine-grained reasoning is required. For distinguishing between images with same number of patches but different aspect ratios, **[IMAGE BREAK]** tokens are inserted between image rows. Additionally, an **[IMAGE END]** token at the end of image sequence. The model employs a **gated FFN** architecture, implementing gating in the hidden layer in place of standard feedforward layer in the attention block. For processing images within a single batch, the model flattens images along the sequence dimension and concatenates them. A block diagonal mask is constructed to prevent attention leakage between patches of different images. Traditional learned and absolute position embeddings are replaced by **ROPE-2D**, which allows handling variable image sizes. The **multimodal decoder** of Pixtral is built on top of Mistral Nemo 12B [15], a 12-billion parameter decoder-only language model. The decoder uses a causal self-attention. The vision encoder is connected to the multimodal decoder by a two-layer fully connected network. The paper describes Pixtral as an instruction-tuned model, pre-trained on large-scale interleaved image and text documents. The Paper contributes an open-source benchmark called **MM-MT-Bench**, for evaluating vision-language models. Pixtral excels at multimodal instruction following, surpassing comparable open-source models
on the MM-MT-Bench benchmark.
## **Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos**
Sa2VA is a unified model for dense grounded understanding of both images and videos, integrating the SAM-2 video segmentation model with the LLaVA vision-language model. It supports a wide array of image and video tasks, like referring segmentation and conversation, by treating all inputs (text, images, videos) as tokens in a shared LLM space, generating instruction tokens that guide SAM-2 for precise mask production.
[](https://arxiv.org/abs/2501.04001)
[](https://github.com/magic-research/Sa2VA)
[](https://huggingface.co/papers/2501.04001)
Haobo Yuan, Xiangtai Li, Tao Zhang, Zilong Huang, Shilin Xu, Shunping Ji, Yunhai Tong, Lu Qi, Jiashi Feng, Ming-Hsuan Yang

ℹ️ More Information
Sa2VA leverages a pre-trained LLaVA-like model (containing a visual encoder, visual projection layer, and LLM) and appends SAM-2 alongside it. Crucially, it uses a *decoupled design*, where SAM-2's decoder and memory module are frozen. This preserves SAM-2's perception and tracking capabilities and allows Sa2VA to be a plug-and-play module, updatable with newer MLLMs. The connection between the LLM and SAM-2 is a special "[SEG]" token. The LLM generates this token, and its hidden states act as a spatial-temporal prompt for SAM-2's decoder, which produces segmentation masks. The model is trained end-to-end, demonstrating scalability. The training uses a unified instruction-tuning format for various tasks: referring segmentation, visual question answering (VQA), and grounded conversation generation (GCG) for both images and videos. It treats all images, videos and prompts as visual tokens. A key aspect is the co-training with multiple datasets, including image and video data. The authors introduce *Ref-SAV*, an auto-labeled dataset with over 72,000 object expressions in complex video scenes, and manually validate 2,000 video objects in Ref-SAV for benchmarking referring video object segmentation. A simple mask tracking method re-utilizes SAM-2's knowledge. The model formulates all tasks as a single instruction-tuning process. Datasets used for co-training are: LLAVA 1.5 (665K), RefCOCO (17K), RefCOCO+ (17K), RefCOCOg (22K), Grand-f (214K), ChatUniVi (100K). Ref-YTVOS (3.5K), MeVIS (0.6K), ReVOS (1.7K) and Ref-SAV (37K).
## **Tarsier2: Advancing Large Vision-Language Models from Detailed Video Description to Comprehensive Video Understanding**
Tarsier2 is a state-of-the-art large vision-language model (LVLM) that excels in generating detailed and accurate video descriptions and demonstrates superior general video understanding capabilities. It scales pre-training data, performs fine-grained temporal alignment during supervised fine-tuning, and uses model-based sampling with Direct Preference Optimization (DPO) to improve performance, outperforming models like GPT-4o and Gemini 1.5 Pro.
[](https://arxiv.org/abs/2501.07888) [](https://github.com/bytedance/tarsier) [](https://huggingface.co/omni-research/Tarsier-7b)
Liping Yuan, Jiawei Wang, Haomiao Sun, Yuchen Zhang, Yuan Lin

ℹ️ More Information
Tarsier2 utilizes a straightforward architecture consisting of a vision encoder, a vision adaptor, and a large language model (LLM), specifically building upon Qwen2-VL. The model undergoes a three-stage training process: pre-training, supervised fine-tuning (SFT), and reinforcement learning (RL) using Direct Preference Optimization (DPO). A key improvement over its predecessor, Tarsier, is the significant expansion of the pre-training dataset from 11 million to 40 million video-text pairs. This expansion includes the meticulous collection and filtering of 11 million commentary videos (explanations and analyses of movies and TV shows), providing rich contextual information. During the SFT stage, Tarsier2 is trained on a dataset containing 150K instances, each with a detailed video description and specific frame annotations corresponding to each described event. This *fine-grained temporal alignment* provides supervision that improves accuracy and reduces hallucinations compared to traditional video-caption alignment. The SFT phase is conducted in two steps. The initial step is frame to event allignment. Then, the model's output to make a more human-like style. The final training stage employs DPO with automatically generated preference data. Negative samples are created by corrupting videos (clip-switching, clip-reversing, clip-cropping, and down-sampling), and a preference data filtering method (using AutoDQ) ensures high-quality pairs. Tarsier2 achieves state-of-the-art results on 15 public benchmarks, demonstrating its versatility across tasks such as video question-answering, video grounding, hallucination tests, and embodied question-answering. A recaptioning dataset, Tarsier2-Recap-585K, is also released.
## **UI-TARS: Pioneering Automated GUI Interaction with Native Agents**
UI-TARS is a native GUI agent model that operates solely on screenshots, performing human-like interactions (keyboard and mouse operations). Unlike frameworks relying on wrapped commercial models (e.g., GPT-4o), UI-TARS is an end-to-end model achieving state-of-the-art (SOTA) performance on 10+ GUI agent benchmarks in perception, grounding, and task execution, significantly outperforming sophisticated frameworks.
[](https://arxiv.org/abs/2501.12326) [](https://github.com/bytedance/UI-TARS) [](https://huggingface.co/bytedance-research/UI-TARS-7B-SFT)
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, Wanjun Zhong, Kuanye Li, Jiale Yang, Yu Miao, Woyu Lin, Longxiang Liu, Xu Jiang, Qianli Ma, Jingyu Li, Xiaojun Xiao, Kai Cai, Chuang Li, Yaowei Zheng, Chaolin Jin, Chen Li, Xiao Zhou, Minchao Wang, Haoli Chen, Zhaojian Li, Haihua Yang, Haifeng Liu, Feng Lin, Tao Peng, Xin Liu, Guang Shi

ℹ️ More Information
UI-TARS leverages several key innovations: (1) **Enhanced Perception**, utilizing a large-scale GUI screenshot dataset for context-aware understanding and precise captioning of UI elements; (2) **Unified Action Modeling**, standardizing actions into a unified space across platforms and achieving precise grounding through large-scale action traces; (3) **System-2 Reasoning**, incorporating deliberate reasoning for multi-step decision-making, including task decomposition, reflection, and milestone recognition; and (4) **Iterative Training with Reflective Online Traces**, addressing the data bottleneck by automatically collecting, filtering, and refining interaction traces on hundreds of virtual machines. The model is trained iteratively and tuned via reflection, continuously learning from mistakes and adapting to new situations with minimal human intervention. The architecture takes screenshots as input and uses a Vision-Language Model (VLM), specifically Qwen-2-VL 7B and 72B, to process visual information and generate actions. The action space is unified across platforms (mobile, desktop, web) and includes actions like click, type, scroll, and drag. Reasoning is infused by generating explicit "thoughts" before each action, inspired by the ReAct framework. These thoughts are generated through a combination of curated GUI tutorials and augmented action traces, incorporating patterns like task decomposition, long-term consistency, milestone recognition, trial and error, and reflection. The training process involves multiple stages, starting with perception enhancement using a curated dataset of GUI screenshots and associated metadata. This dataset supports tasks like element description, dense captioning, state transition captioning, question answering, and set-of-mark prompting. Action modeling is improved by creating a large-scale dataset of action traces and using grounding data to pair element descriptions with spatial coordinates. The model is trained using a combination of supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) with reflection tuning to learn from errors.
## **VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling**
VideoChat-Flash is a system designed for handling long-form video content in multimodal large language models (MLLMs). It introduces a Hierarchical visual token Compression (HiCo) method to reduce computational load while preserving essential details, and uses a multi-stage learning approach with a new long-video dataset (LongVid) to achieve state-of-the-art performance on both long and short video benchmarks.
[](https://arxiv.org/abs/2501.00574) [](https://github.com/OpenGVLab/VideoChat-Flash) [](https://huggingface.co/OpenGVLab/VideoChat-Flash-Qwen2_5-2B_res448)
Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chenting Wang, Yu Qiao, Yali Wang, Limin Wang

ℹ️ More Information
**Hierarchical visual token Compression (HiCo):** This is the core innovation. It compresses video information at two levels: **Clip-level Compression:** The video is divided into clips. A visual encoder (UMT-L) processes each clip, and a compressor (token merging with MLP) reduces the number of visual tokens. This exploits inter-frame redundancy. **Video-level Compression:** During the LLM (Qwen2-7B) interaction, visual tokens are further reduced using a progressive visual dropout strategy. This leverages the idea that the LLM focuses on the entire context at shallow layers and specific details at deeper layers. It combines uniform dropout (shallow layers) and text-guided selection (deep layers). **Visual Encoder:** UMT-L@224 [30] (a video encoder, shown to be more efficient than image encoders like SigLIP). **Visual-Language Connector:** A compressor (token merging) followed by an MLP projection. **Large Language Model (LLM):** Qwen2-7B. **Multi-stage Short-to-Long Learning:** This is a crucial training strategy: **Stage 1: Video-Language Alignment:** Train the compressor and MLP with image-text and short video-text pairs (0.5M each). **Stage 2: Short Video Pre-training:** Enhance visual understanding with more images (3.5M) and short videos (2.5M). **Stage 3: Joint Short & Long Video Instruction Tuning:** Fine-tune on a mix of images (1.1M), short videos (1.7M), and long videos (0.7M) with instruction-following data. **Stage 4: Efficient High-Resolution Post-finetuning:** Adapt to higher resolutions (224 to 448) by fine-tuning the video encoder on a subset (25%) of Stage 3 data.**Dynamic Video Sampling:** Uses a dual sampling strategy: dense sampling (15 fps) for short videos (capturing motion) and sparse sampling (1 fps) for long videos (capturing events). **Timestamp-aware Prompt:** Uses a simple text prompt to provide timestamp information to the model: "The video lasts for N seconds, and T frames are uniformly sampled from it.**LongVid:** A new large-scale long video instruction-tuning dataset introduced in the paper. It contains 114,228 long videos and 3,444,849 question-answer pairs across five task types. It leverages existing datasets (Ego4D, HowTo100M, HD-Vila, MiraData) and generates dense event labels. **Mixed Training Data:** Uses a combination of short and long videos during training. **NIAH (Needle In A video Haystack)**. A newly created dataset for testing models capabilities for understanding long contexts.
## **VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding**
VideoLLaMA3 is a vision-centric multimodal foundation model designed for both image and video understanding, emphasizing a training paradigm and framework that prioritize high-quality image-text data, alongside an adaptable vision encoder and video token compression, to achieve state-of-the-art performance.
[](https://arxiv.org/abs/2501.13106v1)
[](https://github.com/DAMO-NLP-SG/VideoLLaMA3)
[](https://huggingface.co/papers/2501.13106)
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, Deli Zhao

ℹ️ More Information
**VideoLLaMA3** introduces a vision-centric approach in both its training paradigm and framework design, focusing on enhancing image and video understanding capabilities. The core architecture incorporates a pre-trained vision encoder (SigLIP), a video compressor (DiffFP), a projector, and a large language model (LLM - Qwen2.5). The model employs a four-stage training process: 1) **Vision Encoder Adaptation**, where the vision encoder is adapted to accept images of variable resolutions using scene images, document data, and scene text images; 2) **Vision-Language Alignment**, which jointly tunes the vision encoder, projector, and LLM using large-scale image-text data (including detailed captions, documents, and charts) and a small amount of text-only data; 3) **Multi-task Fine-tuning**, incorporating image-text data for downstream tasks and general video caption data; and 4) **Video-centric Fine-tuning**, using general videos, streaming videos, temporally grounded videos, image-only, and text-only data. A key innovation is **Any-resolution Vision Tokenization (AVT)**, which allows the vision encoder to process images and videos of any resolution by replacing fixed positional embeddings with Rotary Position Embedding (RoPE). This enables handling images with variable shapes and minimal information loss. For video inputs, **Differential Frame Pruner (DiffFP)** acts as a video compressor, reducing the number of vision tokens by comparing the 1-norm distance between temporally consecutive patches in pixel space and pruning redundant patches. This makes video representations more compact and precise. The training data mixture is carefully curated for each stage, emphasizing high-quality image-text data. The Vision Encoder Adaptation stage uses datasets like VL3-Syn7M-short, LLaVA-Pretrain-558k, and document datasets. The Vision-Language Alignment stage expands on this with detailed captions, OCR data, and fine-grained data with bounding boxes. The Multi-task Fine-tuning stage adds question-answering data and general video caption data. Finally, the Video-centric Fine-tuning stage includes general videos, streaming videos, and temporal grounding data. This "vision-centric" approach, prioritizing image understanding as a foundation for video understanding, along with AVT and DiffFP, allows VideoLLaMA3 to achieve strong performance on both image and video benchmarks.
## **Llama 3.2-Vision: Enhanced Multimodal Capabilities Built on Llama 3**
Llama 3.2-Vision extends the Llama 3 text-only model with multimodal capabilities, allowing it to process both text and images. This model, available in 11B and 90B parameter sizes, leverages a vision adapter with cross-attention layers to integrate image representations from a separate vision encoder into the core Llama 3 LLM, achieving strong performance on visual recognition, image reasoning, captioning, and visual question answering.
[](https://github.com/meta-llama/llama-models) [](https://huggingface.co/meta-llama/Llama-3.2-11B-Vision)
Meta

ℹ️ More Information
**Llama 3.2-Vision** builds upon the Llama 3 architecture, an auto-regressive language model using an optimized transformer. It adds a *vision adapter*, comprised of cross-attention layers, to incorporate visual information. This adapter receives input from a *separate vision encoder* (not part of the core Llama 3 model), allowing the model to process images without directly converting them into text tokens. The `<|image|>` tag within the prompt signifies the presence of an image and dictates where the visual information is integrated via cross-attention. This integration occurs *after* the image tag and influences *subsequent* text tokens. The model supports a context length of 128k tokens and utilizes Grouped-Query Attention (GQA). The model family was trained on 6B image-text pairs. Pretraining data cutoff is December 2023, supports English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai. However image-text tasks are only in English. The model's training involves supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) for instruction-tuned versions. The base models are suitable for text completion, with or without an image, using specific prompt formats. Instruction-tuned models excel at tasks like Visual Question Answering (VQA), Document VQA (DocVQA), image captioning, and image-text retrieval. The training process includes stages of pretraining and annealing, leveraging a vast amount of data and significant computational resources (H100 GPUs). Key capabilities include handling both text and image inputs, answering questions about images, generating captions, and performing visual reasoning. The model *does not* support built-in tool calling (like `brave_search` or `wolfram_alpha`) when an image is present in the prompt; tool calling is only available for text-only inputs. The intended use cases cover a wide range of applications, but usage is restricted by the Llama 3.2 Community License and Acceptable Use Policy, particularly regarding languages and potential misuse. Meta emphasizes a responsible deployment approach, including providing tools like Llama Guard for safety and encouraging developers to implement appropriate safeguards. The model underwent extensive evaluations, including red teaming and assessments for critical risks such as CBRNE, child safety, and cyber attacks.
## **SmolVLM: A Small, Efficient, and Open-Source Vision-Language Model**
SmolVLM is a 2B parameter vision-language model (VLM) that achieves state-of-the-art performance for its memory footprint, offering a small, fast, and memory-efficient solution for multimodal tasks. It is fully open-source, with all model checkpoints, datasets, training recipes, and tools released under the Apache 2.0 license, enabling local deployment, reduced inference costs, and user customization.
[](https://huggingface.co/blog/smolvlm)
[](https://github.com/huggingface/smollm)
[](https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct)
Andres Marafioti, Merve Noyan, Miquel Farré, Elie Bakouch, Pedro Cuenca

ℹ️ More Information
SmolVLM builds upon the architecture of Idefics3, leveraging a similar implementation in transformers but with key differences to enhance efficiency. It replaces the Llama 3.1 8B language backbone with the smaller SmolLM2 1.7B model. A more aggressive image compression strategy is employed, using a pixel shuffle strategy that reduces visual information by a factor of 9 (compared to 4x in Idefics3). This allows for 384x384 patches, and a shape-optimized SigLIP is used as the vision backbone with 14x14 inner patches. The model demonstrates superior memory usage compared to other VLMs in transformers, enabling efficient on-device inference. For instance, encoding a single image and prompt requires only 1.2k tokens, significantly less than models like Qwen2-VL. This efficiency translates to faster prefill and generation throughputs. SmolVLM achieves strong performance on benchmarks such as MMMU, MathVista, MMStar, DocVQA, and TextVQA. It also shows promising results in basic video analysis, leveraging its long context capabilities. Training involved extending the context window of SmolLM2 to 16k tokens using techniques like RoPE base value adjustment and fine-tuning on a mixture of long- and short-context datasets. A curated training dataset, largely based on The Cauldron and Docmatix, was used for the VLM training. Checkpoint selection was based on a weighted metric across multiple vision-language benchmarks. The model is integrated with VLMEvalKit for easy evaluation, and it can be readily used and fine-tuned with the transformers library. TRL integration allows for applying Direct Preference Optimization (DPO). A notebook is provided for fine-tuning on VQAv2, with options for LoRA, QLoRA, or full fine-tuning, even within the constraints of consumer GPUs.
## **Idefics2**
IDEFICS2, an 8B parameter open-source vision-language model, efficiently processes interleaved image and text sequences by combining a SigLIP vision encoder, a Mistral-7B LLM, and a Perceiver pooling layer with MLP projection for robust text encoding, excelling in tasks like OCR and document understanding.
[](https://arxiv.org/abs/2405.02246) [](https://huggingface.co/spaces/HuggingFaceM4/idefics-8b)
Hugo Laurençon, Léo Tronchon, Matthieu Cord, Victor Sanh

ℹ️ More Information
IDEFICS2 is an 8B parameter open-source vision-language model adept at handling interleaved image and text sequences. IDEFICS2 utilizes a vision-language architecture designed for efficient processing of image and text sequences. It employs the SigLIP model as the vision encoder, extracting features from images in their native resolutions and aspect ratios. The Mistral-7B model serves as the LLM backbone, providing language understanding and generation capabilities. For text encoding, IDEFICS2 leverages a **Perceiver pooling layer** followed by an **MLP projection** to integrate visual features with the LLM's embedding space. This combination of vision encoder, LLM, and text encoder enables IDEFICS2 to handle various multimodal tasks, with a particular focus on OCR and document understanding. The model is trained on a diverse dataset encompassing OBELICS, LAION Coco, and PMD, with additional data for OCR tasks. Fine-tuning is performed on instruction datasets like The Cauldron and OpenHermes-2.5.
## **Idefics3-8B: Building and Better Understanding Vision-Language Models**
Idefics3-8B is a powerful open-source vision-language model (VLM) that significantly outperforms its predecessor, Idefics2-8B, while being trained efficiently and exclusively on open datasets. It leverages a straightforward pipeline and introduces Docmatix, a massive dataset for document understanding, to achieve state-of-the-art performance within its size category across various multimodal benchmarks.
[](https://arxiv.org/abs/2408.12637) [](https://huggingface.co/spaces/HuggingFaceM4/idefics3)
Hugo Laurençon, Andrés Marafioti, Victor Sanh, Léo Tronchon

ℹ️ More Information
Idefics3-8B builds upon the foundation of pre-trained unimodal models, specifically Llama 3.1 instruct as the language model and SigLIP-SO400M as the vision encoder. It adopts a self-attention architecture, where visual features are treated as tokens and concatenated with text tokens before being fed into the LLM. To enhance OCR capabilities and address the bottleneck of limited visual tokens per image, Idefics3-8B replaces the perceiver resampler used in Idefics2 with a simple pixel shuffle strategy, similar to InternVL-1.5. This strategy reduces the number of image hidden states by a factor of 4, allowing for the encoding of larger images (up to 364x364 pixels) into 169 visual tokens. The model utilizes an image-splitting strategy during both training and inference, dividing the original image into a matrix of 364x364 pixel tiles. To preserve the 2D structure and positional information of these tiles, a text token '\n' is inserted after each row of tiles, and the downscaled original image is appended to the sequence. Additionally, each tile is prepended with textual tokens indicating its position in the matrix. The training process consists of three stages of pre-training followed by supervised fine-tuning. In the first pre-training stage, the backbones (LLM and vision encoder) are frozen, and only the newly initialized parameters are trained. The maximum image resolution is gradually increased from 364² to 1820². From the second stage onward, the backbones are efficiently trained using DoRA (a variant of LoRA), and larger images are introduced into the training data. The final pre-training stage focuses on training with large synthetic datasets, including Docmatix, Websight, LNQA, PixelProse, and ChartGemma. During supervised fine-tuning, NEFTune noise is applied to the inputs, and the loss is calculated only on the answer tokens. The learning rate is kept constant for the first two pre-training stages and linearly decayed to zero during the final pre-training stage and supervised fine-tuning. Idefics3-8B demonstrates significant improvements over Idefics2, particularly in document understanding tasks, achieving a 13.7-point improvement on DocVQA. This highlights the effectiveness of the Docmatix dataset and the architectural choices made in Idefics3-8B. The model also achieves state-of-the-art performance within its size category across various multimodal benchmarks, including MMMU, MathVista, MMStar, and TextVQA, showcasing its strong capabilities in visual understanding and reasoning.
## **InternLM-XComposer2: Mastering Free-form Text-Image Composition and Comprehension in Vision-Language Large Model**
InternLM-XComposer2 excels in free-form text-image composition and comprehension by connecting a CLIP pre-trained vision encoder with the powerful InternLM-2 LLM using a novel Partial LoRA module, enabling efficient alignment of visual and language tokens for enhanced multimodal understanding.
[](https://arxiv.org/abs/2401.16420) [](https://github.com/InternLM/InternLM-XComposer) [](https://huggingface.co/spaces/Willow123/InternLM-XComposer)
Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Xilin Wei, Songyang Zhang, Haodong Duan, Maosong Cao, Wenwei Zhang, Yining Li, Hang Yan, Yang Gao, Xinyue Zhang, Wei Li, Jingwen Li, Kai Chen, Conghui He, Xingcheng Zhang, Yu Qiao, Dahua Lin, Jiaqi Wang

ℹ️ More Information
**InternLM-XComposer2**: This model introduces a sophisticated architecture that leverages a vision encoder and a Large Language Model (LLM), interconnected through a Partial Low-Rank Adaptation (LoRA) module. This innovative setup allows InternLM-XComposer2 to effectively process both images and text, employing visual tokens generated by the vision encoder alongside language tokens derived from the tokenized text. The vision encoder, pre-trained using CLIP for image-language contrastive learning, and InternLM-2, which serves as the LLM with multi-lingual capabilities, are key components of this architecture. **The Partial LoRA** module distinguishes itself by aligning visual and language tokens through low-rank adaptation applied specifically to visual tokens, enhancing the model's multimodal understanding and processing efficiency. The training methodology of InternLM-XComposer2 is multifaceted, focusing on fine-tuning the vision encoder and Partial LoRA to align visual tokens with the LLM across various datasets. This process involves general semantic alignment, world knowledge alignment, and vision capability enhancement to refine the model's ability to interpret image information and compose text-image content. Supervised fine-tuning further includes multi-task training and free-form text-image composition, aiming to optimize the model's performance in leveraging image information for comprehensive text-image generation and understanding. Alignment techniques and fusion methods in InternLM-XComposer2 utilize the Partial LoRA module for the effective integration of different modalities, thereby enriching the LLM with modality-specific knowledge while preserving its inherent capabilities. This selective enhancement of visual tokens through Partial LoRA enables the model to exhibit robust performance across visual and textual domains, facilitating detailed perception, logical reasoning, and extensive knowledge integration in multimodal understanding. The model employs a diverse array of datasets, including ShareGPT4V-PT, COCO, Nocaps, TextCaps, and many others, for pre-training and supervised fine-tuning. These datasets serve to equip InternLM-XComposer2 with a broad range of capabilities, including general semantic alignment, world knowledge alignment, vision capability enhancement, and the facilitation of free-form text-image composition, marking a significant advancement in the field of vision-language large models.
## **InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD**
InternLM-XComposer2-4KHD, building on its predecessor, pioneers high-resolution image handling in LVLMs by employing dynamic resolution with automatic patch configuration, adapting to resolutions from 336 pixels up to 4K HD for enhanced visual understanding without distortion.
[](https://arxiv.org/abs/2404.06512v1)
Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Songyang Zhang, Haodong Duan, Wenwei Zhang, Yining Li, Hang Yan, Yang Gao, Zhe Chen, Xinyue Zhang, Wei Li, Jingwen Li, Wenhai Wang, Kai Chen, Conghui He, Xingcheng Zhang, Jifeng Dai, Yu Qiao, Dahua Lin, Jiaqi Wang
ℹ️ More Information
**InternLM-XComposer2-4KHD**: Cutting-edge Large Vision-Language Model (LVLM) designed to handle ultra-high resolutions, up to 4K HD and beyond, while also supporting diverse resolutions from 336 pixels. The model builds upon the InternLM-XComposer2 architecture, incorporating a novel **dynamic resolution with automatic patch configuration** technique. This allows the model to dynamically adjust patch layouts and counts based on the input image's aspect ratio, enabling efficient processing of high-resolution images while preserving their original proportions. To address potential ambiguity arising from variable patch configurations, a newline token is introduced to delineate rows of patch tokens, significantly improving performance. InternLM-XComposer2-4KHD is pre-trained on a diverse dataset, including image-caption pairs, concept knowledge, and OCR datasets, focusing on enhancing high-resolution and structural image understanding. Supervised fine-tuning further incorporates a mixed-resolution strategy, employing higher resolution for tasks requiring fine-grained detail, like HD-OCR tasks, and dynamically adjusted resolution for other tasks. This approach enables the model to excel in both high-resolution scenarios and general vision-language understanding tasks.
## **InternLM-XComposer-2.5: A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output**
InternLM-XComposer-2.5 (IXC-2.5) is a versatile Large Vision Language Model (LVLM) designed to handle long-contextual input and output, excelling in various text-image comprehension and composition tasks. It achieves performance comparable to GPT-4V with a significantly smaller 7B LLM backend, demonstrating its efficiency and scalability.
[](https://arxiv.org/pdf/2407.03320) [](https://github.com/InternLM/InternLM-XComposer) [](https://huggingface.co/spaces/Willow123/InternLM-XComposer)
Pan Zhang, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Rui Qian, Lin Chen, Qipeng Guo, Haodong Duan, Bin Wang, Linke Ouyang, Songyang Zhang, Wenwei Zhang, Yining Li, Yang Gao, Peng Sun, Xinyue Zhang, Wei Li, Jingwen Li, Wenhai Wang, Hang Yan, Conghui He, Xingcheng Zhang, Kai Chen, Jifeng Dai, Yu Qiao, Dahua Lin, Jiaqi Wang

ℹ️ More Information
InternLM-XComposer-2.5 builds upon its previous iterations (IXC-2 and IXC-2-4KHD) and features a three-component architecture: a lightweight **OpenAI ViT-L/14 vision encoder**, a powerful InternLM2-7B LLM, and **Partial LoRA** for efficient alignment between the visual and language modalities. IXC-2.5 supports diverse input modalities, including text, single/multiple images, and videos. It utilizes a Unified Dynamic Image Partition strategy to handle high-resolution images and videos, resizing and padding them into smaller patches while preserving aspect ratios. For videos, frames are sampled and concatenated along the short side, creating a high-resolution composite image. The model is pre-trained in three stages: general semantic alignment, world knowledge alignment, and vision capability enhancement, using a diverse range of datasets. During pre-training, the LLM is frozen, and the vision encoder and Partial LoRA are fine-tuned to align visual tokens with the LLM. Supervised fine-tuning is then performed on a collection of datasets covering various tasks, including captioning, visual question answering, multi-turn QA, science QA, chart QA, math QA, OCR QA, video understanding, and conversation. This fine-tuning process involves jointly training all components with a weighted data sampling strategy and specific learning rate schedules for each component. IXC-2.5 also introduces two novel applications: crafting webpages and composing high-quality text-image articles. For webpage generation, the model is trained on a combination of synthetic and real-world web data, enabling it to generate HTML, CSS, and JavaScript code based on screenshots, instructions, or resume documents. For article composing, IXC-2.5 leverages Chain-of-Thought (CoT) and Direct Preference Optimization (DPO) techniques to enhance the quality of written content. This involves rewriting original prompts using CoT, generating diverse responses using different random seeds, and training a reward model to select preferred responses, ultimately leading to more creative and high-quality article generation.
## **InternVL 2.5: Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling**
InternVL 2.5 is an advanced Multimodal Large Language Model (MLLM) series that builds upon InternVL 2.0, maintaining its core architecture while enhancing training and testing strategies, and data quality, to rival leading commercial models like GPT-4o and Claude-3.5-Sonnet.
[](https://arxiv.org/abs/2412.05271)
[](https://github.com/OpenGVLab/InternVL)
[](https://huggingface.co/OpenGVLab/InternVL2_5-78B)
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, Lixin Gu, Xuehui Wang, Qingyun Li, Yimin Ren, Zixuan Chen, Jiapeng Luo, Jiahao Wang, Tan Jiang, Bo Wang, Conghui He, Botian Shi, Xingcheng Zhang, Han Lv, Yi Wang, Wenqi Shao, Pei Chu, Zhongying Tu, Tong He, Zhiyong Wu, Huipeng Deng, Jiaye Ge, Kai Chen, Kaipeng Zhang, Limin Wang, Min Dou, Lewei Lu, Xizhou Zhu, Tong Lu, Dahua Lin, Yu Qiao, Jifeng Dai, Wenhai Wang

ℹ️ More Information
**InternVL 2.5** retains the "ViT-MLP-LLM" architecture of its predecessors, combining a pre-trained InternViT (either InternViT-6B or InternViT-300M) with LLMs of varying sizes (InternLM 2.5, Qwen 2.5) via a 2-layer MLP projector. A key feature is the pixel unshuffle operation, reducing visual tokens from 1024 to 256 per 448x448 image tile, improving scalability for high-resolution processing. The model architecture supports dynamic resolution, adapting to image aspect ratios by dividing images into 448x448 tiles. Crucially, InternVL 2.0 and 2.5 incorporate multi-image and video data, in addition to single-image and text-only data. The training strategy involves a three-stage pipeline: (1) MLP warmup, where only the MLP projector is trained, (2) optional ViT incremental learning, where the vision encoder and MLP are trained to enhance visual feature extraction, particularly for domains rare in web-scale data, and (3) full model instruction tuning, where the entire model is trained on high-quality multimodal instruction datasets. A progressive scaling strategy is employed, starting with smaller LLMs and scaling up, allowing for efficient alignment of the vision encoder with larger LLMs. Training enhancements include random JPEG compression (for robustness to real-world image quality) and loss reweighting (to balance contributions from responses of different lengths). Data organization is optimized using parameters like `nmax` (maximum tile number) and a repeat factor (`r`) to control data sampling frequency. A data-packing strategy concatenates multiple samples into longer sequences to improve GPU utilization. A significant contribution is a data filtering pipeline to remove low-quality samples, particularly those with repetitive patterns, mitigating the risk of repetitive generation, a common issue in MLLMs. The data mixture includes a wide range of tasks (captioning, general QA, mathematics, charts, OCR, etc.) and modalities (single-image, multi-image, video, text). The model was evaluated comprehensively on diverse benchmarks including multi-discipline reasoning (MMMU, MMMU-Pro), document understanding (DocVQA), multi-image/video understanding, real-world comprehension, multimodal hallucination detection, visual grounding, multilingual capabilities, and pure language processing.
## **DeepSeek-VL: Towards Real-World Vision-Language Understanding**
DeepSeek-VL, utilizing a hybrid vision encoder combining SigLIP-L and SAM-B, excels in real-world vision-language understanding by efficiently processing high-resolution images and integrating extracted features with a DeepSeek LLM backbone through a two-layer hybrid MLP adapter.
[](https://arxiv.org/abs/2403.05525) [](https://github.com/deepseek-ai/DeepSeek-VL) [](https://huggingface.co/spaces/deepseek-ai/DeepSeek-VL-7B)
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, Yaofeng Sun, Chengqi Deng, Hanwei Xu, Zhenda Xie, Chong Ruan

ℹ️ More Information
**DeepSeek-VL**: Employs a hybrid vision encoder architecture, fusing a **SigLIP-L encoder** for semantic understanding with a **SAM-B encoder** for high-resolution detail extraction. This allows for efficient processing of 1024x1024 images while capturing both global and fine-grained visual features. **A two-layer hybrid MLP adapter** then integrates these features with the DeepSeek LLM backbone. The model is pre-trained on a diverse dataset encompassing web screenshots, PDFs, OCR, charts, and knowledge-based content from sources like Common Crawl, Web Code, E-books, and arXiv articles. This pretraining is further refined using a curated instruction-tuning dataset based on real user scenarios and categorized into a comprehensive taxonomy covering recognition, conversion, analysis, reasoning, evaluation, and safety tasks. By combining this diverse data with its unique architecture and fusion strategies, DeepSeek-VL aims to deliver robust performance across a wide range of real-world vision-language applications.
## **DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding**
DeepSeek-VL2 is an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, by incorporating a dynamic tiling vision encoding strategy for high-resolution images and leveraging DeepSeekMoE models with Multi-head Latent Attention for efficient inference. It is trained on a large vision-language dataset, shows top performance in tasks.
[](https://arxiv.org/abs/2412.10302)
[](https://github.com/deepseek-ai/DeepSeek-VL2)
[](https://huggingface.co/spaces/deepseek-ai/deepseek-vl2-small)
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, and et al.

ℹ️ More Information
DeepSeek-VL2 builds upon a LLaVA-style architecture. it consists of three core modules: (1) a vision encoder, (2) a vision-language adaptor, and (3) a Mixture-of-Experts language model. It introduces two major enhancements: a dynamic tiling strategy and it uses DeepSeekMOE language model that has Multi-head Latent Attention. The dynamic tiling strategy addresses the limitations of fixed-resolution encoders by splitting high-resolution images into tiles. It uses a single SigLIP-SO400M-384 vision encoder. A set of candidate resolutions CR = {(m· 384, η · 384) | m∈ N, n ∈ N, 1 ≤ m, n,mn ≤ 9} is defined, representing different aspect ratios. For an input image, the optimal resolution from CR that minimizes padding is selected. The resized image is then divided into m₁ × n₁ local tiles of 384 × 384 pixels, plus one global thumbnail tile. The SigLIP-SO400M-384 processes all (1 + m¡ × n₁) tiles, yielding 729 visual embeddings (27x27) of 1152 dimensions per tile. Dynamic tiling is disabled for multiple (>2) images for efficiency. A 2x2 pixel shuffle compresses each tile's visual tokens to 14x14 (196 tokens). Special tokens are added: 14 tokens at the end of each row in the global thumbnail (total 210 tokens); m₁ · 14 tokens at the end of the final column of the local tiles; and a token between the global thumbnail and local tiles. The total visual sequence length is 210 + 1 + m₁ · 14 × (nį · 14 + 1). This sequence is projected into the LLM's embedding space by a two-layer MLP. The language model utilizes DeepSeekMoE, featuring Multi-head Latent Attention (MLA) to compress the Key-Value (KV) cache, improving inference speed and throughput. The MoE architecture further enhances efficiency. A global bias term is used during MoE training for load balancing. DeepSeek-VL2 comes in three variants (Tiny, Small, and Base) with 1.0B, 2.8B, and 4.5B activated parameters, respectively. The training data is constructed in three stages: (1) VL alignment, (2) VL pretraining, and (3) supervised fine-tuning (SFT). The alignment stage uses ShareGPT4V (1.2M samples). Pretraining data combines VL and text-only data (70/30 ratio), including interleaved image-text data (WIT, WikiHow, OBELICS, Wanjuan, and in-house data), image captioning data (various open-source datasets with quality enhancements and filtering), OCR data (LaTeX OCR, 12M RenderedText, and in-house data), general VQA data, table/chart/document understanding data (PubTabNet, FinTabNet, Docmatix), web-to-code and plot-to-Python data (Websight, and Python plots), QA with visual prompts, visual grounding data and grounded conversation data. SFT data includes enhanced general visual question-answering data, cleaned OCR and document understanding data, enhanced table and chart understanding data, improved reasoning/logic/math data, textbook/academic questions, and expanded web-to-code and plot-to-Python data, visual grounding data, grounded conversation data. Text only datasets were used during SFT stage. The training methodology involves a three-stage pipeline. Stage 1 trains the vision encoder and vision-language adaptor MLP, keeping the language model fixed, using image-text paired data. Stage 2 performs vision-language pre-training with all parameters unlocked, using ~800B image-text tokens. Stage 3 conducts supervised fine-tuning. Visual understanding is emphasized, and the loss is computed only on text tokens. Unlike previous work, the fixed-resolution vision encoder is adapted during training.
## **MANTIS: Mastering Multi-Image Understanding Through Interleaved Instruction Tuning**
MANTIS is a family of open-source large multimodal models that demonstrate state-of-the-art performance on multi-image visual language tasks. By focusing on instruction tuning with a carefully curated multi-image dataset, MANTIS achieves superior results using significantly less data than models trained with massive web datasets. This efficient approach opens new avenues for developing powerful multi-image LMMs with limited resources.
[](https://arxiv.org/abs/2405.01483) [](https://github.com/TIGER-AI-Lab/Mantis) [](https://huggingface.co/spaces/TIGER-Lab/Mantis)
Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, Wenhu Chen

ℹ️ More Information
**Mantis**: a powerful and efficient multi-image Large Multimodal Models (LMMs), demonstrating that massive pre-training on noisy web data is not the only path towards achieving state-of-the-art performance in complex visual-language tasks. Instead, MANTIS focuses on instruction tuning using high-quality, academic-level data, achieving remarkable results on various multi-image benchmarks while using significantly less data than its counterparts. Central to MANTIS's success is the meticulously curated MANTIS-INSTRUCT dataset, a collection of 721K multi-image instruction data carefully designed to instill four crucial skills: co-reference, comparison, reasoning, and temporal understanding. These skills equip MANTIS with a comprehensive toolkit for tackling the challenges of multi-image understanding. Co-reference enables the model to understand references like "second image" in natural language and correctly identify the corresponding image within the input. Comparison fosters the ability to analyze and identify subtle differences and commonalities between multiple images, a skill crucial for tasks like visual similarity assessment and difference description. Reasoning empowers the model to go beyond simple comparisons and make complex inferences by combining its world knowledge with the information extracted from multiple images, allowing it to solve intricate logical reasoning puzzles and answer challenging multi-image questions. Finally, temporal understanding equips MANTIS with the capability to process and understand image sequences, capturing the dynamic aspects of videos, comics, and other temporal visual data. MANTIS leverages a simple yet effective architecture based on existing pre-trained LLMs like LLaMA-3 and vision transformer encoders from CLIP or SigLIP. A multimodal projector, similar to the one used in LLaVA, aligns the visual embeddings with the text embeddings, facilitating their seamless integration within the LLM. This streamlined approach avoids the complexity of previous architectures like Q-Former while retaining high performance. Extensive evaluations on five multi-image benchmarks, including NLVR2, QBench, BLINK, MVBench, and a newly curated Mantis-Eval dataset, demonstrate MANTIS's superior performance, exceeding existing open-source LMMs and even matching the results of the powerful GPT-4V. Notably, MANTIS surpasses Idefics2-8B, a model pre-trained on 200x larger interleaved multi-image data, showcasing the effectiveness of instruction tuning with high-quality academic-level data. Furthermore, MANTIS retains strong single-image performance on par with existing state-of-the-art models, demonstrating its versatility and adaptability. MANTIS's impressive results, combined with its efficient training and open-source nature, offer a compelling alternative to traditional pre-training-heavy approaches, opening new possibilities for researchers and practitioners seeking to develop powerful and versatile multi-image LMMs with minimal computational resources.
## **Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond**
Qwen-VL distinguishes itself by integrating a Vision Transformer with a large language model through a novel vision-language adapter, employing cross-attention mechanisms for precise alignment of visual and linguistic data, achieving high performance in various vision-language tasks.
[](https://arxiv.org/abs/2308.12966) [](https://github.com/qwenlm/qwen-vl) [](https://huggingface.co/spaces/Qwen/Qwen-VL-Plus)
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, Jingren Zhou

ℹ️ More Information
**Qwen-VL**: Represents an advanced architecture in the vision-language domain, constructed on a foundational large language model with the integration of a Vision Transformer (ViT) for visual encoding. This model stands out for its innovative approach to processing and aligning visual and linguistic data, featuring a **vision-language adapter equipped with cross-attention mechanisms**. These mechanisms enable the efficient compression and integration of image features into the language model, a critical component for achieving precise alignment between visual inputs and text. The architecture's design focuses on optimizing the handling of image features, employing a position-aware strategy to maintain spatial relevance of visual data when merged with textual information.The training methodology of Qwen-VL is meticulously structured into **three distinct phases**, starting with an **initial pre-training** on a diverse collection of weakly labeled image-text pairs. This is followed by **multi-task pre-training**, utilizing high-quality annotated datasets and larger input resolutions to refine the model's capabilities in various tasks such as instruction following and dialogue. The final phase involves **supervised fine-tuning**, further honing the model's performance across a spectrum of vision-language tasks. Special tokens and bounding box inputs are utilized for differentiating between image and text inputs and achieving fine-grained visual understanding, respectively.Qwen-VL's alignment techniques are innovative, employing a cross-attention mechanism within its vision-language adapter to fuse visual and textual features effectively. This approach ensures the preservation of spatial information post feature compression through the use of positional encodings. The model leverages an extensive suite of datasets for training, including LAION-en, LAION-zh, and various others for pre-training, alongside specialized datasets like GQA, VGQA, and VQAv2 for multi-task pre-training. These datasets are instrumental in supporting a broad array of vision-language tasks, emphasizing multilingual capabilities, fine-grained visual understanding, and the model's proficiency in captioning, visual question answering, grounding, and OCR tasks.
## **Qwen2-VL: A Powerful Open-Source Vision-Language Model for Image and Video Understanding**
Qwen2-VL is the latest iteration of the Qwen vision-language model family, building upon the Qwen-VL architecture and introducing significant enhancements for improved understanding of images and videos. It excels in various tasks, including visual question answering, dialogue, content creation, and even agent-based control of devices like mobile phones and robots.
[](https://github.com/QwenLM/Qwen2-VL) [](https://huggingface.co/collections/Qwen/qwen2-vl-66cee7455501d7126940800d)
Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren

ℹ️ More Information
Qwen2-VL continues to leverage the core architecture of Qwen-VL, combining a Vision Transformer (ViT) with approximately 600M parameters and Qwen2 language models. This ViT is designed to handle both image and video inputs seamlessly. The key architectural improvements in Qwen2-VL include Naive Dynamic Resolution support and Multimodal Rotary Position Embedding (M-ROPE). Naive Dynamic Resolution allows the model to handle arbitrary image resolutions by mapping them into a dynamic number of visual tokens. This ensures that the model input accurately reflects the information content of the image, regardless of its original resolution. This approach is more aligned with human visual perception, which adapts to different image sizes and resolutions. M-ROPE enhances the model's ability to capture positional information in multimodal inputs. It deconstructs the original rotary embedding into three parts, representing temporal, height, and width information. This allows the LLM to simultaneously process and integrate 1D textual, 2D visual (image), and 3D video positional information, leading to a more comprehensive understanding of the input sequence. These architectural enhancements, combined with a robust training process, enable Qwen2-VL to achieve state-of-the-art performance on various visual understanding benchmarks, including MathVista, DocVQA, RealWorldQA, and MTVQA. It can also understand videos over 20 minutes long, enabling high-quality video-based question answering, dialogue, and content creation. Furthermore, Qwen2-VL's capabilities in complex reasoning and decision-making allow it to be integrated with devices like mobile phones and robots for automatic operation based on visual input and text instructions. The model also supports multilingual understanding of text within images, including most European languages, Japanese, Korean, Arabic, and Vietnamese, broadening its applicability to a global user base.
## **Qwen2.5-VL: Enhanced Vision-Language Capabilities in the Qwen Series**
Qwen2.5-VL represents a significant advancement in the Qwen series of vision-language models, offering improved image recognition, precise object grounding, enhanced text recognition, document parsing, and video comprehension, while also functioning as a visual agent capable of computer and phone use.
[](https://qwenlm.github.io/blog/qwen2.5-vl/)
[](https://github.com/QwenLM/Qwen2.5-VL)
[](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct)
Qwen Team

ℹ️ More Information
Qwen2.5-VL builds upon its predecessor, Qwen2-VL, with substantial improvements in perception of temporal and spatial scales, as well as a simplified network structure for increased efficiency. **World-wide Image Recognition:** Expanded recognition capabilities covering a vast array of categories, including landmarks, objects, and even film/TV IPs. **Precise Object Grounding:** Uses bounding boxes and point-based representations for object localization, with standardized JSON output for coordinates and attributes, enabling hierarchical positioning. **Enhanced Text Recognition (OCR):** Improved multi-scenario, multi-language, and multi-orientation text recognition and localization, with enhanced information extraction for applications like document processing. **Powerful Document Parsing:** Introduces "QwenVL HTML" format, leveraging HTML for layout information extraction from documents, magazines, research papers, web pages, and mobile screenshots. **Enhanced Video Comprehension:** Supports understanding of ultra-long videos (hourly scale) with dynamic frame rate (FPS) training and absolute time encoding. Enables second-level event localization and key point summarization. **Visual Agent Capabilities:** Can function as a visual agent for computer and phone use, capable of reasoning and dynamically directing tools. Capable of tasks like booking flights. **Time and Image Size Perception** In the spatial dimension, the model is capable of adapting varying image sizes into tokens and directly represents coordinates by detection boxes. In the temporal dimension, the model can comprehend the pace of time through temporal dimension. **Visual Encoder** A native dynamic resolution ViT is trained from scratch. Window Attention is used to minimize computational load. The model comes in three sizes (3B, 7B, and 72B parameters), with both base and instruct-tuned versions available. The 72B-Instruct model achieves competitive performance on various benchmarks, excelling in document and diagram understanding. Smaller models also demonstrate strong performance, with the 7B-Instruct model outperforming GPT-4o-mini in several tasks and the 3B model exceeding the performance of the previous Qwen2-VL 7B model. The models is trained with 18 trillion tokens. Future developments aim to further enhance problem-solving, reasoning, and multi-modality integration.
## **moondream1 and moondream2**
moondream1 and moondream2 are vision-language models with moondream2 building upon moondream1's SigLIP vision encoder and Phi-1.5 language backbone by incorporating an MLP projector for enhanced visual and textual representation alignment.
[](https://github.com/vikhyat/moondream) [](https://huggingface.co/spaces/vikhyatk/moondream2)
@vikhyatk

ℹ️ More Information
**moondream1 and moondream2**: A series of vision-language models. moondream1 is a 1.6B parameter model that leverages **SigLIP** as the vision encoder and **Phi-1.5** as the language backbone, trained on the LLaVA dataset. moondream2 expands upon this foundation, utilizing a 1.86B parameter model initialized with weights from SigLIP and Phi-1.5. It incorporates **an MLP projector** to bridge the visual and textual representations, potentially leading to enhanced vision-language alignment and improved performance across various tasks.
## **Moondream-next: Compact Vision-Language Model with Enhanced Capabilities**
Moondream is a compact (1.9B parameters) vision-language model (VLM) that prioritizes practical usability and accessibility, offering features like structured output (JSON, XML, Markdown, CSV), improved OCR, and a novel experimental Gaze Detection capability, while maintaining fast performance and ease of deployment.
[](https://moondream.ai/)
[](https://github.com/vikhyat/moondream)
[](https://huggingface.co/vikhyatk/moondream-next)
ℹ️ More Information
Moondream distinguishes itself by being exceptionally small (1.9B parameters) while supporting a wide range of functionalities typically found in larger, more specialized models. The architecture is not explicitly detailed in the provided text, but it mentions improvements to the "vision layer" for better OCR performance. This suggests a structure where visual input is processed by a vision encoder, and then integrated with a language model. The key feature is its ability to perform multiple Vision AI tasks ("capabilities") within a single, unified model, including: object detection, captioning, visual querying, pointing (x,y coordinate retrieval), and the newly added gaze detection. The model also newly supports structured output formats, generating outputs directly as JSON, XML, Markdown, or CSV, making integration with applications much easier. The "Gaze Detection" capability is specifically highlighted as a novel and experimental feature, indicating a focus on real-world applications beyond standard benchmarks. The training data and process are not thoroughly described, although the text notes increased training on "document querying and understanding" for OCR enhancement. The model's creators express a cautious approach to benchmarks, acknowledging their limitations and potential for manipulation, yet also highlight improved benchmark scores in this release, suggesting a balance between practical utility and measurable performance. It does not rely on external apis.
## **SPHINX-X: Scaling Data and Parameters for a Family of Multi-modal Large Language Models**
SPHINX-X refines multi-modal large language models by streamlining its architecture to use two visual encoders, CLIP-ConvNeXt and DINOv2, and implementing an efficient single-stage training process for enhanced performance across diverse multi-modal tasks.
[](https://arxiv.org/abs/2402.05935) [](https://github.com/alpha-vllm/llama2-accessory) [](https://huggingface.co/Alpha-VLLM/SPHINX)
Peng Gao, Renrui Zhang, Chris Liu, Longtian Qiu, Siyuan Huang, Weifeng Lin, Shitian Zhao, Shijie Geng, Ziyi Lin, Peng Jin, Kaipeng Zhang, Wenqi Shao, Chao Xu, Conghui He, Junjun He, Hao Shao, Pan Lu, Hongsheng Li, Yu Qiao

ℹ️ More Information
**SPHINX-X**: Represents an advanced iteration in the development of Multi-modal Large Language Models (MLLM), building upon its predecessor, SPHINX, by optimizing both architecture and training efficiency. The core modifications introduced in SPHINX-X include the elimination of redundant visual encoders, the incorporation of **learnable skip tokens** to bypass **fully-padded sub-images**, and the simplification of the multi-stage training process into a singular, **all-in-one training** paradigm. This approach is designed to enhance the model's efficiency and effectiveness across a broad spectrum of multi-modal tasks. The architecture of SPHINX-X retains two key visual encoders, **CLIP-ConvNeXt and DINOv2**, ensuring robust text-image alignment capabilities, especially for high-resolution images and varied aspect ratios. This streamlined model architecture enables a unified encoding approach for both vision and text, emphasizing scalable and efficient training methodologies. The training strategy is comprehensive, directly engaging all model parameters across a wide-ranging multi-modal dataset, which encompasses public resources covering language, vision, and vision-language tasks. Additionally, SPHINX-X enriches this dataset with specially curated OCR-intensive and Set-of-Mark datasets to further extend the model's versatility and generalization capabilities. The datasets utilized in SPHINX-X aim to foster a deep, comprehensive understanding across multiple domains, enhancing the model's performance in OCR, document layout detection, and fine-grained multi-modal understanding. By training over various base Large Language Models (LLMs) with different parameter sizes and multilingual capabilities, SPHINX-X achieves a spectrum of MLLMs that showcase a strong correlation between multi-modal performance and the scales of data and parameters involved. This strategy allows SPHINX-X to set a new benchmark in multi-modal large language model performance, significantly advancing the field's capabilities in handling complex, multi-domain tasks.
## **BLIP: Bootstrapping Language-Image Pre-training**
BLIP introduces a versatile Multimodal Mixture of Encoder-Decoder (MED) architecture, integrating a visual transformer and a BERT-based text encoder with cross-attention layers, enabling unified vision-language understanding and generation across a wide range of tasks.
[](https://arxiv.org/abs/2201.12086) [](https://github.com/salesforce/BLIP)
Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi
ℹ️ More Information
**BLIP**: Introduces an innovative approach to unified vision-language understanding and generation through its Multimodal Mixture of Encoder-Decoder (MED) architecture. This architecture is designed to be highly versatile, capable of serving as a unimodal encoder, an image-grounded text encoder, or an image-grounded text decoder. This flexibility allows BLIP to adeptly handle a wide array of vision-language tasks, showcasing its adaptability across various applications. The MED architecture incorporates a Visual Transformer to encode images, a BERT-based text encoder for processing textual information, additional **cross-attention layers** to facilitate image-text interaction, and **causal self-attention layers** for generating text based on image inputs. These components enable BLIP to support three key functionalities: encoding of either modality on its own, encoding of text grounded in images, and decoding of text from images, thus covering a comprehensive range of tasks from understanding to generation.BLIP's training methodology is grounded in the joint optimization of three pre-training objectives: Image-Text Contrastive Learning (ITC), Image-Text Matching (ITM), and Image-Conditioned Language Modeling (LM). These objectives are designed to align visual and textual features, learn fine-grained image-text alignment, and enable text generation from images, respectively. The model utilizes a mix of human-annotated and web-collected noisy image-text pairs for training, balancing the precision of manually annotated data with the scale and diversity of data collected from the web. This approach ensures robustness and scalability in BLIP's performance across vision-language tasks.For alignment and fusion of multimodal information, BLIP employs ITC and ITM losses to achieve precise text-image alignment, utilizing a multimodal representation that accurately captures the nuanced relationship between visual and textual data. The architecture's cross-attention layers play a crucial role in incorporating visual information into the text encoder for image-grounded text encoding. Simultaneously, modifications to the self-attention layers in the decoder facilitate text generation, effectively merging vision and text for unified processing. BLIP's pre-training leverages a diverse set of datasets, including COCO, Visual Genome, Conceptual Captions, Conceptual 12M, SBU Captions, and LAION. These datasets are instrumental in learning a broad spectrum of vision-language tasks, with high-quality human-annotated pairs and extensive web datasets providing the necessary depth and breadth for comprehensive pre-training.
## **BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models**
BLIP-2 leverages the power of frozen pre-trained image encoders and large language models, connecting them through a lightweight Querying Transformer (Q-Former) to efficiently extract and integrate visual features for enhanced vision-language understanding and generation.
[](https://arxiv.org/abs/2301.12597) [](https://github.com/salesforce/LAVIS/tree/main/projects/blip2) [](https://huggingface.co/spaces/Salesforce/BLIP2)
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi
ℹ️ More Information
**BLIP-2**: The model architecture integrates frozen pre-trained image encoders and large language models (LLMs), employing a lightweight **Querying Transformer (Q-Former)** to facilitate the interaction between these modalities. The Q-Former plays a crucial role in extracting and integrating visual features relevant to textual queries, allowing for a more nuanced understanding and generation of language based on visual inputs.The training methodology of BLIP-2 is structured around a two-stage pre-training strategy. Initially, it focuses on learning vision-language representations utilizing the frozen image encoders. Subsequently, it advances to vision-to-language generative learning, leveraging the capabilities of frozen LLMs. This strategy, coupled with the use of **learnable query vectors within the Q-Former**, enables effective vision-language alignment. The alignment process is further enhanced through fusion methods that extract language-informative visual representations, which are then synthesized with the outputs of LLMs to generate pertinent textual descriptions. A diverse array of datasets including COCO, Visual Genome, CC3M, CC12M, SBU, and LAION400M underpins the comprehensive pre-training regime of BLIP-2. These datasets provide a rich variety of image-text pairs, essential for training the model across a broad spectrum of visual representations and language generation tasks. The model's architecture and training approaches are designed to address the prohibitive costs associated with vision-and-language pre-training, offering a more efficient pathway to developing multimodal understanding and generation capabilities.
## **xGen-MM (BLIP-3): An Open-Source Framework for Building Powerful and Responsible Large Multimodal Models**
xGen-MM (BLIP-3) is a comprehensive framework developed by Salesforce for training a series of open-source large multimodal models (LMMs) designed to excel in a variety of visual language tasks. It provides meticulously curated datasets, a streamlined training recipe, model architectures, and a suite of open LMMs capable of performing various visual language tasks. xGen-MM focuses on scalability, using a simplified architecture and a unified training objective to enable training on larger, more diverse datasets. The framework also includes a safety-tuned model to mitigate harmful behaviors and promote responsible AI development.
[](https://arxiv.org/abs/2408.08872) [](https://huggingface.co/collections/Salesforce/xgen-mm-1-models-and-datasets-662971d6cecbf3a7f80ecc2e)
Le Xue, Manli Shu, Anas Awadalla, Jun Wang, An Yan, Senthil Purushwalkam, Honglu Zhou, Viraj Prabhu, Yutong Dai, Michael S Ryoo, Shrikant Kendre, Jieyu Zhang, Can Qin, Shu Zhang, Chia-Chih Chen, Ning Yu, Juntao Tan, Tulika Manoj Awalgaonkar, Shelby Heinecke, Huan Wang, Yejin Choi, Ludwig Schmidt, Zeyuan Chen, Silvio Savarese, Juan Carlos Niebles, Caiming Xiong, Ran Xu

ℹ️ More Information
xGen-MM (BLIP-3), short for xGen-MultiModal, addresses limitations of previous open-source efforts by providing a complete ecosystem for LMM development. Central to its approach is the utilization of diverse, large-scale, and high-quality multimodal data, which enables xGen-MM to achieve competitive performance against both open-source and proprietary LMMs. Instead of relying on the intricate Q-Former architecture and multiple training objectives used in its predecessor, BLIP-2, xGen-MM streamlines the process by employing a more scalable vision token sampler (perceiver resampler) and unifying the training objective to a single auto-regressive loss on text tokens. This simplification enables larger-scale training and focuses the model on effectively learning from the rich multimodal context. Furthermore, xGen-MM incorporates safety measures, introducing a safety-tuned model with DPO to mitigate potential harmful behaviors like hallucinations and promote responsible AI development. By open-sourcing its models, datasets, and fine-tuning code, xGen-MM aims to empower the research community and foster advancements in the field of LMMs, making these powerful tools more accessible and encouraging further exploration of their capabilities.
## **InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning**
InstructBLIP enhances the BLIP-2 framework by introducing instruction tuning to its Query Transformer (Q-Former), enabling the model to extract instruction-aware visual features and achieve state-of-the-art zero-shot performance across diverse vision-language tasks.
[](https://arxiv.org/abs/2305.06500v2) [](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip) [](https://huggingface.co/spaces/hysts/InstructBLIP)
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi

ℹ️ More Information
**InstructBLIP**: represents an advanced step in the development of vision-language models through instruction tuning, building on the capabilities of the pre-trained BLIP-2 models. It integrates an image encoder, a large language model (LLM), and **a Query Transformer (Q-Former)**, which is specifically fine-tuned to bridge the visual and linguistic components while keeping the image encoder and LLM static. This architecture enables the extraction of instruction-aware visual features, enhancing the model's responsiveness to varied instructional contexts. Training InstructBLIP involves a careful selection of 26 datasets across 11 task categories, transformed into an instruction tuning format to foster the model's adaptability across a broad spectrum of vision-language tasks. The model employs a balanced sampling strategy and standard language modeling loss, augmented with OCR tokens for datasets involving scene texts, to fine-tune its instruction following capabilities. The unique approach of instruction-aware visual feature extraction through the Q-Former allows the model to tailor feature extraction to the specific requirements of the instruction, significantly improving performance across both seen and unseen tasks. Implementation details reveal the flexibility of InstructBLIP's architecture, which is easily adaptable to incorporate various LLMs, thanks to the modular design of the BLIP-2 framework. The model showcases state-of-the-art zero-shot performance across a wide range of vision-language tasks, outperforming previous models like BLIP-2 and Flamingo in zero-shot evaluations and achieving notable results when fine-tuned on specific downstream tasks. InstructBLIP's open-source availability and its performance across different benchmarks highlight its potential as a general-purpose vision-language model.
## **KOSMOS-1: Language Is Not All You Need: Aligning Perception with Language Models**
KOSMOS-1, a multimodal large language model, leverages a Transformer-based architecture enhanced with MAGNETO and XPOS to seamlessly process text and various modalities, aligning perception with language models through training on diverse web-scale multimodal corpora for enhanced zero-shot and few-shot learning capabilities.
[](https://arxiv.org/abs/2302.14045) [](https://github.com/microsoft/unilm)
Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Barun Patra, Qiang Liu, Kriti Aggarwal, Zewen Chi, Johan Bjorck, Vishrav Chaudhary, Subhojit Som, Xia Song, Furu Wei

ℹ️ More Information
**KOSMOS-1**: A transformative multimodal large language model, meticulously designed to harmonize the perception of general modalities with linguistic models, facilitating zero-shot learning, few-shot learning, and auto-regressive output generation. At its core, KOSMOS-1 employs a Transformer-based causal language model architecture, adept at processing both textual and various other modalities. This innovative approach is bolstered by key architectural components, including a Transformer-based decoder for input sequence handling, embedding modules for vector encoding of text and modalities, and the integration of **MAGNETO and XPOS** for architectural enhancements. These elements collectively enable the model to adeptly navigate and process multimodal information. The training regimen of KOSMOS-1 is distinguished by its comprehensive utilization of web-scale multimodal corpora, which encompasses monomodal data, cross-modal paired data, and interleaved multimodal data, emphasizing the next-token prediction tasks to optimize the log-likelihood of tokens. This methodology ensures a robust foundation for the model, enhancing its ability to understand and generate content across various modalities. Furthermore, the alignment techniques employed are particularly noteworthy; by leveraging interleaved image-text data, KOSMOS-1 aligns the perceptual capabilities of general modalities with language models in an unprecedented manner, thereby enriching the model's understanding and interpretative capacities. KOSMOS-1's training datasets, including The Pile, Common Crawl, English LAION-2B, LAION-400M, COYO-700M, and Conceptual Captions, are meticulously selected to serve dual purposes: fostering representation learning and language tasks through text corpora, and aligning perception with language models via image-caption pairs and interleaved data. This strategic selection of datasets not only bolsters the model's linguistic competencies but also significantly enhances its few-shot abilities, marking a significant milestone in the integration of perception and language models.
### **KOSMOS-2: Grounding Multimodal Large Language Models to the World**
KOSMOS-2, extending the KOSMOS-1 architecture, incorporates grounded image-text pairs using discrete location tokens linked to text spans, effectively anchoring text to specific image regions, thereby enhancing multimodal understanding and reference accuracy.
[](https://arxiv.org/abs/2306.14824) [](https://github.com/microsoft/unilm/tree/master/kosmos-2) [](https://huggingface.co/spaces/ydshieh/Kosmos-2)
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei

ℹ️ More Information
**KOSMOS-2**: Built upon the foundational architecture of KOSMOS-1, it retains the Transformer-based causal language model architecture and training objectives, while introducing a significant innovation by incorporating grounded image-text pairs into its training regimen. This addition seeks to bridge the gap between visual and textual information, enabling a more cohesive understanding of multimodal content. The model differentiates itself by training on a web-scale dataset of grounded image-text pairs, known as GRIT, which includes continuous coordinates of bounding boxes translated into discrete location tokens. These tokens are intricately linked with text spans, creating a unified input representation that seamlessly integrates visual and textual elements. The training of KOSMOS-2 is extensive and multifaceted, utilizing grounded image-text pairs, monomodal text corpora, image-caption pairs, and interleaved image-text data to foster a robust learning environment. The model's training leverages a large batch size and employs the AdamW optimizer, running on 256 V100 GPUs. This process is augmented by instruction tuning with both vision-language and language-only instruction datasets, aiming to refine the model's understanding and processing capabilities across different modalities. The grounding technique is a pivotal aspect of KOSMOS-2, where **continuous coordinates of bounding boxes** are converted into **discrete location tokens**. These tokens are then linked with corresponding text spans, anchoring the textual output to specific visual inputs, enhancing the model's ability to refer to and describe particular image regions or objects with precision. KOSMOS-2's alignment techniques and fusion methods play a critical role in its ability to understand and refer to specific parts of an image directly, employing a unified input representation that combines image embeddings with grounded text and location tokens. This approach not only improves the model's referential accuracy but also its overall multimodal comprehension. The model is trained using a variety of datasets, including the specially created GRIT dataset for grounding capabilities, along with monomodal text corpora, image-caption pairs, and interleaved image-text data to bolster its language understanding, multimodal perception, and in-context learning abilities. Through these innovations, KOSMOS-2 represents a significant advancement in grounding multimodal large language models, offering enhanced capabilities in linking textual and visual information cohesively.
## **ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models**
ConvLLaVA addresses the limitations of Vision Transformers (ViTs) in high-resolution Large Multimodal Models (LMMs) by replacing them with a hierarchical backbone, ConvNeXt, as the visual encoder. This architectural shift aims to reduce the computational burden caused by excessive visual tokens and quadratic complexity often associated with ViTs, especially when dealing with high-resolution images.
[](https://arxiv.org/abs/2405.15738) [](https://github.com/alibaba/conv-llava) [](https://huggingface.co/papers/2405.15738)
Chunjiang Ge, Sijie Cheng, Ziming Wang, Jiale Yuan, Yuan Gao, Jun Song, Shiji Song, Gao Huang, Bo Zheng

ℹ️ More Information
ConvLLaVA leverages the inherent information compression capabilities of ConvNeXt, a hierarchical convolutional neural network. ConvLLaVA, unlike traditional LMMs that rely on ViTs, employs a **five-stage ConvNeXt architecture** as its visual encoder. This encoder progressively compresses visual information across its stages, significantly reducing the number of visual tokens generated compared to ViT. The architecture mirrors other popular general LMMs like LLaVA, Qwen-VL, and VILA, consisting of a vision encoder (ConvNeXt), a large language model (LLM - Vicuna in this case), and a vision-language projector (a two-layer MLP). The ConvNeXt encoder processes the input image and generates latent visual embeddings. These embeddings are then projected into the embedding space of the LLM by the vision-language projector. Finally, the projected visual embeddings are concatenated with the text embeddings generated by the LLM's tokenizer, and this combined input is fed into the LLM. The entire model is trained using a language modeling loss. To further enhance ConvLLaVA's performance, the authors introduce two key optimizations: firstly, they update the pretrained ConvNeXt weights instead of freezing them, allowing the model to adapt to high-resolution inputs and improve the quality of visual representations. Secondly, they introduce an additional ConvNeXt stage, effectively creating a five-stage architecture (ConvNeXt†) that further compresses visual information, enabling the model to handle even higher resolutions (up to 1536x1536) while generating a manageable number of visual tokens (576). This hierarchical compression approach, combined with the linear spatial complexity of ConvNeXt, significantly reduces the computational burden on the LLM compared to ViT-based models, making ConvLLaVA a more efficient and scalable solution for high-resolution multimodal tasks.
## **Parrot: Multilingual Visual Instruction Tuning**
Parrot tackles the issue of "multilingual erosion" in Multimodal Large Language Models (MLLMs), where models trained primarily on English-centric data struggle to understand and respond in other languages. It achieves this by using textual guidance to align visual tokens with language-specific embeddings, effectively enhancing the model's multilingual capabilities.
[](https://arxiv.org/abs/2406.02539) [](https://github.com/AIDC-AI/Parrot)
Hai-Long Sun, Da-Wei Zhou, Yang Li, Shiyin Lu, Chao Yi, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, De-Chuan Zhan, Han-Jia Ye

ℹ️ More Information
Parrot builds upon the LLaVA framework, utilizing a pre-trained CLIP ViT-L/14 as the vision encoder and Qwen1.5-Chat as the LLM. The architecture consists of three main components: a vision encoder, a large language model (LLM), and a multilingual **Mixture-of-Experts (MoE)** module. The vision encoder processes the input image and generates visual features, which are then projected into the embedding space of the LLM using a learned projector. To address the multilingual challenge, Parrot introduces a novel textual guidance mechanism. It first calculates cross-attention between the class token of the visual features and the text embeddings derived from the input prompt. This cross-attention output is then fed into the MoE module's router, which predicts the probability of activating each language expert. Each expert is a specialized MLP trained to transform the English-biased visual embeddings into language-specific representations. The router selects the most relevant experts based on the input language, and their outputs are combined to generate the final language-specific visual embeddings. These embeddings are then combined with the original visual embeddings using a weighted sum, ensuring that the model retains its ability to process visual information effectively across different languages. This entire process allows Parrot to align visual tokens with textual embeddings at the language level, effectively mitigating multilingual erosion and enhancing the model's ability to understand and respond in multiple languages.
## **OMG-LLaVA: Bridging Image-level, Object-level, Pixel-level Reasoning and Understanding**
OMG-LLaVA presents a novel framework that unifies image-level, object-level, and pixel-level reasoning and understanding within a single Multimodal Large Language Model (MLLM). It leverages the power of a frozen universal segmentation model (OMG-Seg) for visual encoding and a Large Language Model (LLM) for text understanding and response generation, enabling a wide range of multimodal tasks within a single, elegant architecture.
[](https://arxiv.org/abs/2406.19389) [](https://github.com/lxtGH/OMG-Seg) [](https://huggingface.co/papers/2406.19389)
Tao Zhang, Xiangtai Li, Hao Fei, Haobo Yuan, Shengqiong Wu, Shunping Ji, Chen Change Loy, Shuicheng Yan

ℹ️ More Information
OMG-LLaVA consists of two main components: a frozen universal perception module (based on OMG-Seg) and a Large Language Model (LLM). The universal perception module is responsible for encoding the input image and visual prompts into three types of visual tokens: pixel-centric, object-centric, and object-centric derived from visual prompts. The pixel-centric tokens are generated by a **ConvNeXt-L based CLIP image encoder**, capturing dense image features. The object-centric tokens are generated by the OMG decoder, which takes learnable object queries and visual prompt queries as input and attends to the image features to extract object-level information. This decoder can handle point, box, and mask prompts by applying constraints on the attention masks. To bridge the gap between the frozen perception module and the LLM, a novel "perception prior embedding" strategy is introduced. This strategy fuses the image features with the object queries from the OMG decoder using a mask score derived from the segmentation masks and confidence scores. The resulting weighted object queries are then added to the image features to generate the pixel-centric visual tokens, providing the LLM with rich object-level information. The object-centric visual tokens are directly taken from the foreground object queries of the OMG decoder. Both types of visual tokens, along with the text instruction tokens, are fed into the LLM, which is responsible for understanding the user's intent and generating the appropriate response. The LLM outputs text responses and object-centric visual tokens, which are then decoded by the frozen OMG decoder to produce segmentation masks. This unified architecture allows OMG-LLaVA to perform a wide range of tasks, including image captioning, visual question answering, referring segmentation, reasoning segmentation, grounded conversation generation, and region captioning, all within a single model.
## **EVLM: An Efficient Vision-Language Model for Visual Understanding**
EVLM is an efficient multimodal language model designed to minimize computational costs while maximizing the model's ability to perceive visual signals comprehensively. It addresses the challenges of handling long sequences of visual signals, particularly in video data, by employing a cross-attention mechanism and hierarchical ViT features, achieving competitive performance in tasks like image and video captioning.
[](https://arxiv.org/abs/2407.14177) [](https://huggingface.co/papers/2407.14177)
Kaibing Chen, Dong Shen, Hanwen Zhong, Huasong Zhong, Kui Xia, Di Xu, Wei Yuan, Yifei Hu, Bin Wen, Tianke Zhang, Changyi Liu, Dewen Fan, Huihui Xiao, Jiahong Wu, Fan Yang, Size Li, Di Zhang

ℹ️ More Information
EVLM is built upon the Flamingo architecture, incorporating a visual encoder, a large language model, and a Gated Cross-Attention Layer. To enhance visual perception, EVLM utilizes the 4.4B EVA2-CLIP-E-Plus model as the visual encoder, extracting hierarchical visual features by uniformly sampling 8 feature sequences from the last 40 layers of the transformer. These features are then sequentially fed into different Gated Cross-Attention layers of the Flamingo model. Unlike Flamingo, which uses a single media token image, EVLM replaces it with a set of 16 learnable tokens, aiming to capture visual features similar to Q-former. The attention mechanism is designed to allow each set of learnable tokens to interact only with the corresponding image, while text sequences interact only with the previous image in the multimodal sequence. This approach ensures efficient interaction between visual and textual information. For the language model, EVLM employs the Qwen-14B-Chat 1.0, chosen for its strong performance in content understanding and logical reasoning. A gated cross-attention layer is inserted before every transformer layer of the language model to condition it on visual inputs. To further enhance model effectiveness and scale trainable parameters, a Mixture of Experts (MoE) mechanism is applied to the Cross Attention layer. This involves replicating and segmenting the FFN of the base model into multiple fine-grained experts, with a routing layer selecting the appropriate set of experts for each token. The model undergoes a three-stage training process: multi-modal pre-training, multi-task continual pre-training, and multi-modal instruction fine-tuning. Pre-training focuses on cross-modal alignment and modeling intrinsic relationships within multimodal data, using a large-scale dataset of bilingual image-text captions and web-type multimodal data. Continual pre-training further enhances the model's visual question-answering ability, while instruction fine-tuning activates its instruction-following capabilities using a diverse range of high-quality instruction tuning data.
## **SlowFast-LLaVA: A Strong Training-Free Baseline for Video Large Language Models**
SlowFast-LLaVA (SF-LLaVA) is a training-free video large language model that effectively captures both detailed spatial semantics and long-range temporal context in videos without requiring any additional fine-tuning on video data. It achieves this by leveraging a two-stream SlowFast design inspired by action recognition models, allowing it to process a larger number of frames and outperform existing training-free methods on various video benchmarks.
[](https://arxiv.org/abs/2407.15841) [](https://huggingface.co/papers/2407.15841)
Mingze Xu, Mingfei Gao, Zhe Gan, Hong-You Chen, Zhengfeng Lai, Haiming Gang, Kai Kang, Afshin Dehghan

ℹ️ More Information
SF-LLaVA builds upon the LLaVA-NeXT framework and utilizes a two-stream approach, similar to SlowFast networks in action recognition, to process video inputs. The model first uniformly samples N frames from the input video. These frames are then processed independently by a visual encoder, such as CLIP-L, followed by a visual-language adapter for feature alignment. The resulting frame features are then fed into two separate pathways: Slow and Fast. **The Slow pathway** focuses on capturing detailed spatial semantics by processing a smaller number of frames (Nslow) at a higher spatial resolution (e.g., 8 frames with 24x24 tokens). It applies spatial pooling with a small stride (e.g., 1x2) to aggregate features and reduce the number of tokens. **The Fast pathway** focuses on capturing temporal context and motion cues by processing all N frames (Nfast = N) at a lower spatial resolution (e.g., 64 frames with 4x4 tokens). It applies aggressive spatial pooling to each frame to prioritize temporal information. The features from both pathways are then flattened and concatenated, forming a comprehensive video representation that balances spatial details and temporal context. This aggregated feature vector, along with the text prompt and question, is then fed into the LLM (LLaVA-NeXT) to generate the final answer. This training-free approach eliminates the need for expensive fine-tuning on video datasets, making SF-LLaVA highly efficient and adaptable to various video scenarios. The authors demonstrate the effectiveness of SF-LLaVA on three different video question-answering tasks (Open-Ended VideoQA, Multiple Choice VideoQA, and Text Generation) across eight benchmarks, showcasing its superior performance compared to existing training-free methods and even surpassing some state-of-the-art supervised fine-tuned video LLMs.
## **INF-LLaVA: High-Resolution Image Perception for Multimodal Large Language Models**
INF-LLaVA is a novel Multimodal Large Language Model (MLLM) designed to effectively process high-resolution images. It addresses the limitations of existing cropping-based and dual-encoder methods by introducing two innovative modules: Dual-perspective Cropping Module (DCM) and Dual-perspective Enhancement Module (DEM). DCM segments high-resolution images into sub-images from both local and global perspectives, preserving detailed and contextual information. DEM facilitates efficient interaction between local and global features, enhancing the model's understanding of complex visual relationships. Extensive evaluations demonstrate INF-LLaVA's superior performance on various benchmarks, establishing a new state-of-the-art in vision-language tasks.
[](https://arxiv.org/abs/2407.16198) [](https://github.com/WeihuangLin/INF-LLaVA) [](https://huggingface.co/papers/2407.16198)
Yiwei Ma, Zhibin Wang, Xiaoshuai Sun, Weihuang Lin, Qiang Zhou, Jiayi Ji, Rongrong Ji

ℹ️ More Information
INF-LLaVA pushes the boundaries of Multimodal Large Language Models (MLLMs) by tackling the critical challenge of high-resolution image perception. It aims to leverage the richness of detail present in high-resolution images without succumbing to the computational limitations imposed by traditional MLLM architectures. INF-LLaVA achieves this through a sophisticated approach that combines innovative cropping and feature enhancement techniques, resulting in a model capable of simultaneously capturing fine-grained local details and comprehensive global context. At the core of INF-LLaVA lies the Dual-perspective Cropping Module (DCM), a strategic cropping strategy that surpasses conventional approaches by integrating both local and global perspectives. This dual-perspective approach ensures that each extracted sub-image retains not only the intricate details essential for accurate analysis but also the broader contextual information crucial for understanding the relationships between objects. While local-perspective cropping preserves continuous visual information at high resolution, capturing the essence of individual objects and regions, global-perspective cropping leverages a unique interleaving technique to preserve the overall spatial relationships between objects within the high-resolution image. This balanced combination ensures that the model can perceive both the "trees" and the "forest," enabling a holistic understanding of the visual scene. To further enhance the model's understanding, INF-LLaVA introduces the Dual-perspective Enhancement Module (DEM). This module facilitates efficient and effective interaction between the local and global features extracted by the vision encoder, enriching the representation with multi-scale information. Instead of relying on computationally expensive cross-attention directly on high-resolution features, DEM employs a more resource-efficient strategy. It leverages 2D positional priors to concatenate global-perspective sub-image features back into the original image's shape, effectively recreating a high-resolution representation of the global context. These recombined features are then re-cropped from a local perspective, and cross-attention is performed between corresponding local and global sub-images to enhance global features with fine-grained local details. A symmetrical process enhances local features with global context. This meticulously designed interaction between local and global features ensures that the resulting representation is not only rich in detail but also cognizant of the broader context. The dual-enhanced features are then projected into a format compatible with the LLM through a linear connector. The LLM then processes the combined visual and textual information to generate a coherent and contextually relevant response. Through extensive evaluations on a diverse set of benchmarks, including ScienceQA-img, OKVQA, SEEDBench, MMBench, AI2D, LLaVA-Bench-in-the-wild, and MMMU, INF-LLaVA demonstrates its superior performance over existing MLLMs. Its ability to effectively handle high-resolution images while maintaining computational efficiency establishes a new state-of-the-art in the field. The open-source release of INF-LLaVA, along with its pretrained model and code, paves the way for further research and exploration of high-resolution image perception in multimodal large language models, pushing the boundaries of multimodal understanding and enabling the development of more powerful and versatile AI systems.
## **VILA²: VILA Augmented VILA**
VILA² (VILA-augmented-VILA) introduces a novel approach to address the limitations of data quantity and quality in training Visual Language Models (VLMs). Instead of relying on costly human annotation or distillation from proprietary models, VILA² leverages the VLM itself to iteratively refine and augment its pretraining data, leading to significant performance improvements and achieving state-of-the-art results on the MMMU leaderboard among open-sourced models.
[](https://arxiv.org/abs/2407.17453) [](https://huggingface.co/papers/2407.17453)
Yunhao Fang, Ligeng Zhu, Yao Lu, Yan Wang, Pavlo Molchanov, Jang Hyun Cho, Marco Pavone, Song Han, Hongxu Yin

ℹ️ More Information
VILA² employs a two-step iterative process: self-augmenting and specialist-augmenting. The self-augmenting loop focuses on enhancing the general knowledge of the VLM by using the model itself to re-caption its pretraining data. This process starts with an initial VLM (VILA0) trained on a dataset with typically short and brief captions, like COYO. VILA0 is then used to generate longer and more detailed captions for the same images, creating a synthetic dataset. This augmented dataset, combined with the original data, is used to train the next iteration of the VLM (VILA1). This loop can be repeated multiple times, with each iteration improving the caption quality and subsequently the VLM's performance. However, this self-augmentation process eventually reaches saturation. To overcome this limitation, VILA² introduces the **specialist-augmenting loo**p. This involves fine-tuning the self-augmented VLM on specific downstream tasks, creating specialist VLMs with expertise in areas like spatial awareness, OCR, and grounding. These specialists are then used to re-caption the pretraining data, focusing on their specific domain knowledge. The self-augmented VLM is then retrained on this specialist-recaptioned data, further boosting its performance. This approach leverages the synergy between the vast amount of data in pretraining and the specialized knowledge acquired during fine-tuning. The architecture of VILA² follows the standard auto-regressive VLM design, consisting of a large language model (LLM), a visual encoder, and an image-text projector. The authors experiment with different LLMs (Llama2-7B, Llama3-8B-Instruct, and Yi-34B) and visual encoders (SigLIP and InternViT-6B). They also introduce a 4x downsampling of visual tokens to reduce computational cost. The training process follows the typical three-stage paradigm: projector initialization, vision-language pre-training, and visual instruction-tuning. VILA² demonstrates significant performance improvements over previous state-of-the-art methods on various benchmarks, including general VQA, text-oriented VQA, general multimodal benchmarks, and image captioning. This highlights the effectiveness of the proposed self- and specialist-augmentation techniques in enhancing VLM training and achieving state-of-the-art results.
## **MiniCPM-V: A GPT-4V Level MLLM on Your Phone**
MiniCPM-V is a series of efficient Multimodal Large Language Models (MLLMs) designed for deployment on end-side devices like mobile phones and personal computers. The latest iteration, MiniCPM-Llama3-V 2.5, achieves performance comparable to GPT-4V, Gemini Pro, and Claude 3 while being significantly smaller and more efficient, demonstrating the feasibility of deploying powerful MLLMs on resource-constrained devices.
[](https://arxiv.org/pdf/2408.01800) [](https://github.com/OpenBMB/MiniCPM-V) [](https://huggingface.co/openbmb/MiniCPM-V-2_6)
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, Qianyu Chen, Huarong Zhou, Zhensheng Zou, Haoye Zhang, Shengding Hu, Zhi Zheng, Jie Zhou, Jie Cai, Xu Han, Guoyang Zeng, Dahai Li, Zhiyuan Liu, Maosong Sun

ℹ️ More Information
MiniCPM-V focuses on achieving a balance between performance and efficiency, crucial for real-world applications on end-side devices. The model architecture consists of three key modules: a visual encoder, a compression layer, and an LLM. For the visual encoder, MiniCPM-V utilizes SigLIP SoViT-400m/14, chosen for its efficiency and effectiveness. To handle high-resolution images with varying aspect ratios, the model employs an adaptive visual encoding approach. This involves dividing the input image into slices that better match the ViT's pre-training settings in terms of resolution and aspect ratio. A score function is used to select the optimal partition of slices, ensuring a good match with the ViT's pre-training. Each slice is then resized proportionally and interpolated to fit the ViT's input size. After visual encoding, each slice is represented by 1024 tokens, resulting in a large number of tokens for multiple slices. To address this, a token compression module is employed, using one-layer cross-attention with a moderate number of queries to compress the visual tokens of each slice into 64 or 96 tokens. This significantly reduces the computational cost and memory footprint, making the model suitable for end-side deployment. A spatial schema is also introduced to indicate the position of each slice relative to the whole image, further enhancing the model's understanding of spatial relationships. The compressed visual tokens, along with the text input, are then fed into the LLM, which is based on MiniCPM 2B for earlier versions and Llama3-Instruct 8B for MiniCPM-Llama3-V 2.5. The training process consists of three phases: pre-training, supervised fine-tuning, and RLAIF-V (Reinforcement Learning from AI Feedback for Vision). Pre-training aims to align the visual modules with the LLM's input space and learn foundational multimodal knowledge. It involves three stages: warming up the compression layer, extending the input resolution of the visual encoder, and training the visual modules with the adaptive visual encoding strategy. Supervised fine-tuning further enhances the model's knowledge and interaction capabilities using high-quality visual question answering datasets. The SFT data is categorized into two parts: one focusing on basic recognition capabilities and the other on generating detailed responses and following instructions. Finally, RLAIF-V is employed to mitigate the hallucination problem common in MLLMs. This involves generating multiple responses for an instruction, evaluating their correctness using a divide-and-conquer strategy, and then optimizing the model using Direct Preference Optimization (DPO) on a preference dataset. MiniCPM-V demonstrates impressive performance on various benchmarks, including general multimodal benchmarks, OCR benchmarks, and multilingual multimodal interaction, while being efficient enough for deployment on mobile phones. This highlights the potential of pushing the boundaries of end-side MLLMs and bringing powerful AI capabilities to user devices.
## **MiniCPM-o-2.6: A GPT-4o Level MLLM for Vision, Speech and Multimodal Live Streaming**
MiniCPM-o-2.6 is a powerful 8B parameter multimodal large language model (MLLM) that excels in vision, speech, and multimodal live streaming, achieving performance comparable to GPT-4o in several benchmarks, while maintaining high efficiency for deployment on edge devices.
[](https://openbmb.notion.site/MiniCPM-o-2-6-A-GPT-4o-Level-MLLM-for-Vision-Speech-and-Multimodal-Live-Streaming-on-Your-Phone-185ede1b7a558042b5d5e45e6b237da9)
[](https://github.com/OpenBMB/MiniCPM-o)
[](https://huggingface.co/openbmb/MiniCPM-o-2_6)
OpenBMB

ℹ️ More Information
MiniCPM-o-2.6 employs an end-to-end omni-modal architecture. It integrates several pre-trained components: **Vision Encoder:** SigLip-400M **Audio Encoder:** Whisper-medium-300M **Text-to-Speech (TTS):** ChatTTS-200M **Large Language Model (LLM):** Qwen2.5-7B. These components are connected and trained end-to-end. A key innovation is the "Omni-modal Live Streaming Mechanism." This involves: **Online Modality Encoders/Decoders:** The offline encoders and decoders are transformed into online versions to handle streaming inputs and outputs. **Time-Division Multiplexing (TDM):** A TDM mechanism within the LLM backbone processes omni-modal streams. It divides parallel streams (video, audio) into sequential information within short time slices. **Configurable Speech Modeling:** A multimodal system prompt (including text and audio prompts) allows for flexible voice configuration during inference, enabling voice cloning and description-based voice creation.
## **LLaVA-OneVision: Easy Visual Task Transfer**
LLaVA-OneVision is a family of open large multimodal models (LMMs) designed to excel in various computer vision scenarios, including single-image, multi-image, and video understanding. It pushes the performance boundaries of open LMMs by consolidating insights from the LLaVA-NeXT blog series, focusing on data, models, and visual representations. Notably, LLaVA-OneVision demonstrates strong transfer learning capabilities, enabling it to excel in video understanding tasks by leveraging knowledge learned from image data.
[](https://arxiv.org/abs/2408.03326) [](https://llava-vl.github.io/blog/2024-08-05-llava-onevision/) [](https://huggingface.co/papers/2408.03326)
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, Chunyuan Li

ℹ️ More Information
LLaVA-OneVision inherits the minimalist design of the LLaVA series, aiming to effectively leverage pre-trained capabilities of both the LLM and the visual model while facilitating strong scaling. The architecture consists of three key components: a large language model (LLM), a vision encoder, and a projector. The authors choose Qwen-2 as the LLM due to its strong language capabilities and various model sizes available. For the vision encoder, they opt for SigLIP, which has shown to yield higher LMM performance among open vision encoders. A 2-layer MLP is used as the projector to map image features into the word embedding space, creating a sequence of visual tokens. The model utilizes a flexible visual representation strategy called Higher AnyRes, which builds upon the original AnyRes strategy introduced in LLaVA-NeXT. This strategy involves dividing the input image into crops, each with a resolution suitable for the vision encoder, and then applying bilinear interpolation to reduce the number of tokens per crop if needed. This allows the model to handle high-resolution images and videos efficiently while preserving important visual details. The specific configuration of **Higher AnyRes** is adapted for different scenarios: single-image, multi-image, and video. For single-image data, a large maximum spatial configuration is used to maintain the original image resolution and a large number of visual tokens are allocated to effectively represent the visual signal. For multi-image data, only the base image resolution is considered, eliminating the need for multi-crop and saving computational resources. For video data, each frame is resized to the base image resolution and bilinear interpolation is used to reduce the number of tokens per frame, allowing for the processing of a larger number of frames. The training process follows a three-stage curriculum learning approach: language-image alignment, high-quality knowledge learning, and visual instruction tuning. The first stage focuses on aligning visual features with the LLM's embedding space using the LLaVA align dataset. The second stage refines and enhances the model's knowledge base using high-quality data from three major categories: re-captioned detailed description data, document/OCR data, and Chinese and language data. The final stage involves visual instruction tuning, where the model is trained on a diverse set of visual tasks with preferred responses. This stage is further divided into two phases: single-image training and OneVision training. Single-image training focuses on single-image scenarios, while OneVision training expands the model's capabilities to multi-image and video scenarios, enabling task transfer and emerging capabilities. LLaVA-OneVision demonstrates state-of-the-art performance on various benchmarks, including single-image, multi-image, and video tasks, showcasing its effectiveness and versatility in handling diverse visual scenarios.
## **VITA: Towards Open-Source Interactive Omni Multimodal LLM**
VITA is the first open-source Multimodal Large Language Model (MLLM) capable of simultaneously processing and analyzing video, image, text, and audio modalities while offering an advanced multimodal interactive experience. It addresses the limitations of existing open-source models, which often excel in either understanding or interaction but rarely both, by integrating architectural innovations with advanced training and development strategies.
[](https://arxiv.org/pdf/2408.05211) [](https://github.com/VITA-MLLM/VITA) [](https://huggingface.co/VITA-MLLM)
Chaoyou Fu, Haojia Lin, Zuwei Long, Yunhang Shen, Meng Zhao, Yifan Zhang, Xiong Wang, Di Yin, Long Ma, Xiawu Zheng, Ran He, Rongrong Ji, Yunsheng Wu, Caifeng Shan, Xing Sun

ℹ️ More Information
VITA starts with the Mixtral 8x7B model as its language foundation, chosen for its strong performance and sparse mixture of experts (SMoE) architecture. To enhance its Chinese language capabilities, the vocabulary is expanded with Chinese terms, and the model undergoes bilingual instruction tuning using a high-quality bilingual text corpus. This ensures proficiency in both Chinese and English. For visual modality, VITA employs InternViT-300M-448px as the visual encoder, processing images at 448x448 resolution and generating 256 tokens after passing through a two-layer MLP visual connector. High-resolution images are handled using a dynamic patching strategy, while videos are treated as special cases of images, with frame sampling based on video length. For audio modality, a Mel Filter Bank block is used to process the input audio, followed by 4xCNN downsampling layers and a 24-layer transformer, resulting in 25 tokens for every 2 seconds of audio. A two-layer MLP serves as the audio-text modality connector. The training pipeline consists of three stages: LLM instruction tuning, multimodal alignment, and multimodal instruction tuning. LLM instruction tuning focuses on enhancing the base LLM's bilingual capabilities. Multimodal alignment aims to bridge the representation gap between text and other modalities by training individual encoders and connectors for each modality. This involves collecting and curating a large-scale, high-quality multimodal dataset, including image descriptions, general image QA, OCR and diagram data, general video descriptions, general video QA, and pure text data. Multimodal instruction tuning further refines the model's ability to follow instructions and understand different modalities. A specially designed state token is introduced to distinguish the type of input query (effective audio, noisy audio, or text), enabling non-awakening interaction during inference. To achieve natural multimodal human-computer interaction, VITA introduces two key innovations: non-awakening interaction and audio interrupt interaction. These are implemented using a duplex pipeline during deployment. Two VITA models run concurrently: one for generating responses to user queries (Generation model) and the other for monitoring environmental audio (Monitoring model). The Monitoring model uses SileroVAD for voice activity detection and filters out noisy audio based on the state token. If an effective audio query is detected, the Monitoring model interrupts the Generation model, consolidates the historical context, and responds to the latest query. The two models then swap identities, ensuring continuous monitoring and seamless interaction.VITA demonstrates strong performance on various unimodal and multimodal benchmarks, showcasing its robust foundational capabilities in multilingual, vision, and audio understanding. While still lagging behind closed-source counterparts in certain areas, VITA represents a significant step towards open-source interactive omni-modal LLMs, paving the way for future research and development in this field.
## **EAGLE: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders**
EAGLE is a family of open-source Multimodal Large Language Models (MLLMs) that leverage a mixture of vision encoders to achieve state-of-the-art performance on various benchmarks, particularly in tasks involving OCR and document understanding. The study focuses on systematically exploring the design space of MLLMs with multiple vision encoders, aiming to identify optimal design choices and improve MLLM perception.
[](https://arxiv.org/pdf/2408.15998) [](https://github.com/NVlabs/EAGLE) [](https://huggingface.co/spaces/NVEagle/Eagle-X5-13B-Chat)
Min Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, De-An Huang, Hongxu Yin, Karan Sapra, Yaser Yacoob, Humphrey Shi, Bryan Catanzaro, Andrew Tao, Jan Kautz, Zhiding Yu, Guilin Liu

ℹ️ More Information
EAGLE builds upon the LLaVA architecture, consisting of a large language model, a vision encoder, and a projection layer. The core innovation lies in integrating multiple vision experts, each pre-trained on different tasks and resolutions, to enhance the model's ability to perceive and comprehend diverse visual information. The study explores various aspects of this design space, including high-resolution adaptation, fusion paradigms, and optimal encoder combinations. It introduces a Pre-Alignment training stage to address representational inconsistencies between vision-focused encoders and language tokens. The training process consists of three progressive stages: vision-language pre-alignment, joint-projector training, and supervised fine-tuning. EAGLE achieves state-of-the-art performance on various benchmarks, demonstrating significant advantages in OCR and document understanding tasks. The study highlights the importance of systematic design space exploration and the effectiveness of combining multiple vision experts with a streamlined fusion strategy and a pre-alignment training stage for building high-performing MLLMs.
## **Eagle 2: Building Post-Training Data Strategies from Scratch for Frontier Vision-Language Models**
Eagle 2 is a family of vision-language models (VLMs) developed with a data-centric approach, focusing on post-training data strategies to achieve state-of-the-art performance. The models build upon open-source components and prioritize data diversity and quality, using a three-stage training recipe and a tiled mixture of vision encoders (MoVE) architecture, achieving results that match or surpass those of larger, proprietary models.
[](https://arxiv.org/abs/2501.14818)
[](https://github.com/NVlabs/EAGLE)
[](https://huggingface.co/nvidia/Eagle2-9B)
Zhiqi Li, Guo Chen, Shilong Liu, Shihao Wang, Yilin Zhao, Subhashree Radhakrishnan, Nadine Chang, Matthieu Le, De-An Huang, Ilia Karmanov, Lukas Voegtle, Jose M. Alvarez, Bryan Catanzaro, Jan Kautz, Andrew Tao, Vibashan VS, Yishen Ji, Shiyi Lan, Hao Zhang, Karan Sapra, Amala Deshmukh, Tuomas Rintamaki, Philipp Fischer, Timo Roman, Tong Lu, Guilin Liu, Zhiding Yu

ℹ️ More Information
**Eagle 2** adopts a "diversity first, then quality" data strategy, beginning with a large, diverse pool of over 180 data sources, followed by rigorous filtering and selection. The architecture uses a tiled mixture of vision encoders (MoVE), specifically SigLIP and ConvNeXt-XXLarge, with image tiling to handle high resolutions. Each image tile is encoded by channel-concatenated MoVE. The vision encoder outputs are concatenated and aligned with the LLM (Qwen2.5) via a simple MLP connector. A three-stage training recipe is used: Stage 1 trains the connector to align modalities; Stage 1.5 trains the full model on a large, diverse dataset; and Stage 2 fine-tunes on a high-quality instruction-tuning dataset. Crucially, *all* available visual instruction data is used in Stage 1.5, not just captioning/knowledge data. Balanced data packing addresses limitations in existing open-source frameworks. The core contribution is the detailed data strategy. This involves: (1) **Data Collection**: Building a highly diverse data pool (180+ sources) through both passive gathering (monitoring arXiv, HuggingFace) and proactive searching (addressing "bucket effect" via error analysis). (2) **Data Filtering**: Removing low-quality samples based on criteria like mismatched question-answer pairs, irrelevant image-question pairs, repeated text, and numeric formatting issues. (3) **Data Selection**: Choosing optimal subsets based on data source diversity, distribution, and K-means clustering on SSCD image embeddings to ensure balance across types (especially useful for chart data, etc.). (4) **Data Augmentation**: Mining information from input images through techniques like Chain-of-Thought (CoT) explanation generation, rule-based QA generation, and expanding short answers into longer ones. (5) **Data Formating:** remove unnecessary decorations. Training uses a three-stage approach:
**Stage 1:** Aligns language and image modalities by training the MLP connector.
**Stage 1.5:** Trains the *full* model using a large-scale, diverse dataset (21.6M samples). *All* available visual instruction data is used here, unlike common two-stage approaches, leading to substantial improvements.
**Stage 2:** Fine-tunes the full model on a carefully curated, high-quality visual instruction tuning dataset (4.6M samples). The model is trained with AdamW. Eagle 2 demonstrates strong performance across a wide range of multimodal benchmarks, matching or outperforming frontier open-source and some closed-source VLMs.
## **Florence-2: A Deep Dive into its Unified Architecture and Multi-Task Capabilities**
Florence-2 presents a significant advancement in vision foundation models, aiming to achieve a single, versatile representation capable of handling a wide spectrum of vision and vision-language tasks through a unified, prompt-based approach. Unlike previous models that often specialize in specific tasks, Florence-2 is designed to be a generalist, adept at performing tasks with simple text instructions, similar to how Large Language Models (LLMs) operate.
[](https://arxiv.org/pdf/2311.06242) [](https://huggingface.co/spaces/gokaygokay/Florence-2)
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, Lu Yuan

ℹ️ More Information
Florence-2 lies a sophisticated architecture comprised of two key components: an image encoder and a multi-modality encoder-decoder. The image encoder, powered by the powerful DaViT architecture, transforms the input image into a sequence of visual token embeddings, effectively capturing the visual information. These visual embeddings are then combined with text embeddings derived from task-specific prompts. This fusion of visual and linguistic information is processed by a standard transformer-based multi-modality encoder-decoder. This component acts as the brain of the model, meticulously analyzing the combined input and generating the desired output in textual form. This unified architecture, with a single set of parameters governing various tasks, eliminates the need for task-specific modifications, leading to a streamlined and efficient model. This design philosophy mirrors the trend in the NLP community, where models with consistent underlying structures are preferred for their versatility and ease of development. Florence-2's capabilities span a multitude of tasks, showcasing its remarkable adaptability. It excels at generating detailed image captions, capturing the essence of an image through rich textual descriptions. Its prowess extends to visual grounding, accurately pinpointing specific objects or regions within an image based on textual phrases. Florence-2 also demonstrates impressive performance in open-vocabulary object detection, identifying objects by their names, even if those objects were not part of its training data. This capability highlights the model's ability to generalize its knowledge and understand novel visual concepts. Furthermore, Florence-2 tackles dense region captioning, providing detailed descriptions for multiple regions within an image, and even performs optical character recognition (OCR), extracting text from images. This broad range of capabilities makes Florence-2 a powerful tool for numerous applications, pushing the boundaries of multimodal understanding in AI.
## **MULTIINSTRUCT: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning**
MULTIINSTRUCT leverages the OFA model as its foundation, employing a Transformer-based sequence-to-sequence architecture and instruction tuning techniques on a diverse dataset, effectively aligning text and image tokens within a unified space for enhanced multi-modal zero-shot learning.
[](https://arxiv.org/abs/2212.10773) [](https://github.com/vt-nlp/multiinstruct)
Zhiyang Xu, Ying Shen, Lifu Huang

ℹ️ More Information
**MULTIINSTRUCT**: introduces a novel approach to enhance multi-modal zero-shot learning by leveraging instruction tuning, built upon the foundation of the **OFA (Omnipotent Fast Adapters)** as its core pre-trained multi-modal model. This model adopts a Transformer-based sequence-to-sequence architecture that efficiently encodes a mix of instructions, text, images, and bounding boxes within a unified token space. Such a design enables MULTIINSTRUCT to process and interpret a wide range of input types, including optional images, through a comprehensive encoder-decoder framework. The encoder component is dedicated to processing the diverse inputs and instructions, while the decoder is tasked with generating the corresponding outputs. At the heart of MULTIINSTRUCT's training methodology is the innovative use of the model-specific MULTIINSTRUCT dataset, alongside instruction tuning techniques that incorporate instances from multiple tasks. This approach involves a combination of random shuffling and sampling of instruction templates for batch training, significantly enriching the learning process. Furthermore, the model explores advanced transfer learning strategies through Mixed Instruction Tuning and Sequential Instruction Tuning, utilizing the NATURAL INSTRUCTIONS dataset. This strategy not only enhances the model's adaptability across a wide spectrum of multi-modal tasks but also boosts its performance in zero-shot learning scenarios. The alignment techniques employed by MULTIINSTRUCT, such as byte-pair encoding and VQ-GAN, play a crucial role in aligning text and image tokens within a unified vocabulary. This seamless integration allows the model to effectively process and interpret various types of inputs and outputs. The use of a unified sequence-to-sequence architecture facilitates a deeper integration and alignment of vision and language modalities, underscoring the model's innovative approach to bridging the gap between different types of data. The datasets used for training and fine-tuning, namely MULTIINSTRUCT and NATURAL INSTRUCTIONS, are specifically chosen to bolster the model's capabilities in handling multi-modal tasks and instructions, showcasing its versatility and effectiveness in enhancing multi-modal zero-shot learning.
## **MouSi: Poly-Visual-Expert Vision-Language Models**
MouSi pushes the boundaries of VLMs by incorporating multiple visual experts like CLIP and SAM, utilizing a poly-expert fusion network to combine their outputs and interface with powerful LLMs like Vicuna, thereby enabling a more comprehensive understanding and processing of visual information.
[](https://arxiv.org/abs/2401.17221) [](https://github.com/fudannlplab/mousi)
Xiaoran Fan, Tao Ji, Changhao Jiang, Shuo Li, Senjie Jin, Sirui Song, Junke Wang, Boyang Hong, Lu Chen, Guodong Zheng, Ming Zhang, Caishuang Huang, Rui Zheng, Zhiheng Xi, Yuhao Zhou, Shihan Dou, Junjie Ye, Hang Yan, Tao Gui, Qi Zhang, Xipeng Qiu, Xuanjing Huang, Zuxuan Wu, Yu-Gang Jiang

ℹ️ More Information
**MouSi**: Represents an innovative approach to Vision-Language Models (VLMs) by integrating multiple visual experts into a unified architecture, aiming to surpass the limitations inherent to models reliant on a singular visual component. This architecture leverages a poly-expert fusion network, which incorporates outputs from varied visual experts, such as CLIP for image-text matching and SAM for image segmentation. This network facilitates an efficient interface with pre-trained Large Language Models (LLMs), notably utilizing a model like Vicuna v1.5. MouSi distinguishes itself by employing a multi-expert visual encoder that selects relevant experts from a pool, and it features two types of **poly-expert fusion networks: a projection fusion method and a Q-Former fusion method.** The training methodology of MouSi is characterized by a two-phase approach. Initially, during the pre-training phase, both the text-only LLM and the multi-expert encoder are kept static, with the training focus squarely on the poly-visual fusion network. Subsequently, in the fine-tuning phase, the LLM is activated for training in conjunction with the poly-visual fusion network, using high-quality supervised datasets. This methodology ensures that MouSi benefits from robust pre-existing language models while simultaneously enhancing its capability to process and integrate complex visual information. For alignment and fusion of the multimodal inputs, MouSi employs its poly-expert fusion network to amalgamate the outputs from the various visual experts, aligning them with the vision input tokens. This alignment is critical for encoding vision and text cohesively, a process facilitated by either the projection fusion method or the more complex Q-Former fusion method. These methods allow for the effective compression of multi-channel visual information into a format that can be efficiently processed alongside textual data. The datasets used in MouSi's training regimen include LCS-558K and the LAION-CC-SBU collection for pre-training, aimed at aligning text and image representation spaces, and diverse, high-quality SFT datasets for fine-tuning, enhancing the model's performance across a broad spectrum of multimodal tasks.
## **LaVIN: Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models**
LaVIN offers an efficient and cost-effective approach to vision-language instruction tuning by employing a Mixture-of-Modality Adapter (MM-Adapter), significantly reducing trainable parameters and enabling a streamlined optimization process for LLMs without extensive pre-training.
[](https://arxiv.org/abs/2305.15023v3) [](https://github.com/luogen1996/lavin)
Gen Luo, Yiyi Zhou, Tianhe Ren, Shengxin Chen, Xiaoshuai Sun, Rongrong Ji

ℹ️ More Information
**LaVIN**: This model introduces the Mixture-of-Modality Adaptation (MMA) learning regime, a pioneering method that leverages **lightweight adapters** to fine-tune LLMs for vision-language (VL) instruction tasks. The core of LaVIN's architecture is the **Mixture-of-Modality Adapter (MM-Adapter)**, which connects the image encoder to the LLM using minimal adaptation modules, allowing for a streamlined optimization of the multimodal LLM through a relatively small number of parameters. The training methodology of LaVIN is notably efficient, employing the MMA strategy to fine-tune only the inserted adapters, thus significantly reducing the optimized parameter count to between three to five million. This method substantially lowers both training time and storage requirements, circumventing the need for additional VL pre-training. The MM-Adapter is instrumental in facilitating the seamless transition between single- and multi-modal instructions, thereby enhancing the model's adaptability to various VL tasks. Additionally, it employs a dynamic routing function that adjusts adaptations for input features, enabling an effective integration of vision and text embeddings. LaVIN's performance and versatility are further demonstrated through its application on diverse datasets, including ScienceQA, Alphaca-52k, and LLaVA-158k. ScienceQA is utilized to assess the model's multimodal question-answering capabilities, while the Alphaca-52k (text-only) and LLaVA-158k (text-image pairs) datasets are leveraged to refine and expand LaVIN's functionality as a multimodal chatbot. This strategic use of datasets underscores LaVIN's advanced vision-language understanding, illustrating its potential to significantly contribute to the field of multimodal learning and interaction.
## **Nous-Hermes-2-Vision - Mistral 7B**
Nous-Hermes-2-Vision builds upon OpenHermes-2.5 by integrating the efficient SigLIP-400M vision encoder and incorporating a custom dataset with function calling capabilities, enabling it to not only understand visual and textual information but also extract specific text from images, advancing its functionality as a Vision-Language Action Model.
[](https://huggingface.co/NousResearch/Nous-Hermes-2-Vision-Alpha)
This project is led by qnguyen3 and teknium.
ℹ️ More Information
**Nous-Hermes-2-Vision**: Represents a notable advancement in the realm of Vision-Language Models, marking its distinction through the integration of two key enhancements that elevate its capabilities beyond traditional models. This model is an evolution from its predecessor, **OpenHermes-2.5-Mistral-7B**, and distinguishes itself by incorporating the **SigLIP-400M** for significantly improved performance and efficiency, moving away from the standard reliance on larger 3B vision encoders. Additionally, it introduces a custom dataset that includes function calling capabilities, transforming it into a more dynamic Vision-Language Action Model. The training of Nous-Hermes-2-Vision utilized a diverse dataset comprising 220K images from LVIS-INSTRUCT4V, 60K from ShareGPT4V, 150K private function calling data, and 50K conversations from teknium's OpenHermes-2.5. Such a varied dataset ensures the model's proficiency across a broad spectrum of vision-language tasks, including object recognition, instruction following, and conversational understanding. The model's innovative approach to integrating vision and language, particularly through the use of custom datasets for function calling, allows for encoding vision and text together in a way that supports action-oriented tasks and automation. A key feature of Nous-Hermes-2-Vision is its ability to interact with images to extract valuable text information from visual content, thus enabling detailed analyses and responses in natural language. This capability is underscored by the model's utilization of the SigLIP-400M, opting for a more lightweight and efficient architecture while enhancing performance in vision-language tasks. The model is further enriched with a custom dataset that includes **function calling**, allowing for the extraction of written information from images through specific tags, thus broadening its application scope for developers and researchers alike. Despite its innovative features, early usage of Nous-Hermes-2-Vision has revealed some challenges, such as hallucinations and spamming of EOS tokens. Recognizing these issues, the research team, led by Quan Nguyen and Teknium, has committed to releasing an updated version to address these problems, demonstrating their dedication to refining the model's capabilities.
## **TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones**
TinyGPT-V prioritizes efficiency in multimodal large language models by combining a compact EVA-ViT visual encoder with linear projection layers and the powerful Phi-2 language model, achieving robust performance in vision-language tasks despite its smaller size.
[](https://arxiv.org/abs/2312.16862v1) [](https://github.com/DLYuanGod/TinyGPT-V) [](https://huggingface.co/spaces/llizhx/TinyGPT-V)
Zhengqing Yuan, Zhaoxu Li, Lichao Sun

ℹ️ More Information
**TinyGPT-V**: introduces a compact yet powerful architecture tailored for efficient multimodal large language model applications, leveraging small backbones for streamlined processing. This model integrates a visual encoder, specifically EVA of Vision Transformer (ViT), with **linear projection layers** and the Phi-2 language model, constituting its core components. The visual encoder remains inactive during training, focusing on image resolution adjustments across various stages to enhance image understanding. The **linear projection layers**, particularly with the incorporation of the **Q-Former layer** from BLIP-2, aim to efficiently embed visual features into the language model, reducing the number of parameters needing training. The Phi-2 large language model backbone, a 2.7 billion-parameter model, excels in reasoning and language comprehension, effectively handling vision-language operations including spatial location tasks through textual bounding box depictions. The training of TinyGPT-V unfolds across four stages: warm-up, pre-training, instruction fine-tuning, and multi-task learning. Each stage is meticulously designed to progressively enhance the model's capabilities in understanding and generating language based on visual inputs, with a special emphasis on human-like learning and conversation abilities in later stages. The use of datasets such as LAION, CC3M, SBU, and more, across these stages, supports the model's development in vision-language understanding, generation, and task execution like visual question answering and image captioning. A noteworthy aspect of TinyGPT-V's architecture is the implementation of normalization techniques and LoRA (Low-Rank Adaptation) to stabilize training and optimize the model's performance across different modalities. Addressing challenges like NaN or INF values in multimodal data computation, these mechanisms enhance training stability and efficiency. Furthermore, the model employs a multi-task instruction template to manage task ambiguity, utilizing MiniGPT-v2 tokens for task-specific instructions, facilitating precise and accurate task execution.
## **CoVLM: Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding**
CoVLM distinguishes itself by using novel communication tokens to enable dynamic interaction between its CLIP ViT-L image encoder, YOLOX detection network, and Pythia language model, facilitating sophisticated communication for superior compositional reasoning in vision-language tasks.
[](https://arxiv.org/abs/2311.03354v1)
Junyan Li, Delin Chen, Yining Hong, Zhenfang Chen, Peihao Chen, Yikang Shen, Chuang Gan

ℹ️ More Information
**CoVLM**: This model is distinct in its approach, employing a novel set of **communication tokens** that facilitate dynamic interaction between a vision encoder, detection network, and a language model (LLM). The architecture of CoVLM integrates a CLIP ViT-L image encoder and a YOLOX detection network, alongside a pre-trained Pythia model for language processing. These components work in tandem to guide the LLM in composing visual entities and relationships within the textual context, enhancing the model's ability to dynamically communicate with the vision encoder and detection network. CoVLM is pre-trained on a diverse and extensive image-text dataset comprising 97 million image-text pairs, drawn from a variety of sources. This extensive dataset supports the model's grounding pipeline, which is crucial for associating text spans with their corresponding visual entities in images. The model utilizes special communication tokens for facilitating iterative communication between its vision and language components, enabling a sophisticated form of top-down and bottom-up communication. This communication is key to achieving high performance in vision-language tasks, as it allows the model to seamlessly integrate and interact between language tokens and visual embeddings. The datasets employed for pre-training, such as COCO, CC3M, CC12M, Visual Genome, SBU, and LAION400M, are meticulously selected to enhance the model's ability to ground image-text pairs effectively. This strategic choice is aimed at facilitating the association of textual descriptions with their corresponding visual entities, thereby improving the model's overall performance across a range of multimodal tasks. CoVLM's innovative approach to integrating visual detection networks with LLMs enables a new level of compositional reasoning, setting it apart from previous vision-language models.
## **GLaMM: Pixel Grounding Large Multimodal Model**
GLaMM excels in pixel-level grounding by utilizing a five-component architecture encompassing global and regional image encoders, an LLM, a grounding image encoder, and a pixel decoder, allowing for comprehensive visual understanding and precise object localization within images.
[](https://arxiv.org/abs/2311.03356) [](https://github.com/mbzuai-oryx/groundingLMM)
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji Mullappilly, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M. Anwer, Erix Xing, Ming-Hsuan Yang, Fahad S. Khan

ℹ️ More Information
**GLaMM**: At its core, GLaMM comprises five essential components: the **Global Image Encoder, Region Encoder, Language Model (LLM), Grounding Image Encoder, and Pixel Decoder**. This architecture is designed to facilitate a wide range of interactions with visual content, from scene-level understanding through the Global Image Encoder, to detailed region-level interpretations via the Region Encoder, and down to precise pixel-level object grounding with the Grounding Image Encoder. The Pixel Decoder component further enriches the model's capabilities by generating **segmentation masks**, enabling GLaMM to respond to both textual and visual prompts with high fidelity. The training methodology of GLaMM involves a dual-pathway approach, encompassing both automated and manual data annotation pipelines to create the Grounding-anything Dataset (GranD). GranD is pivotal for the model's training, especially for its Grounded Conversation Generation (GCG) task, offering a rich set of 7.5 million unique concepts grounded in 810 million regions, complete with segmentation masks. This dataset not only supports the pretraining and fine-tuning phases of GLaMM but also underlines its unique ability to generate grounded conversations that are contextually relevant to the visual stimuli. Alignment techniques within GLaMM utilize a vision-to-language (V-L) projection layer, facilitating the mapping of image features into the language space, thereby ensuring effective text-image alignment. Furthermore, the model employs a language-to-prompt (L-P) projection layer, transforming text embeddings related to segmentation into the decoder space. This dual-projection system allows for an integrated encoding of vision and text, bolstering GLaMM's capacity for pixel-level grounding and positioning it as a significant advancement in the field of multimodal interactions.
## **COSMO: COntrastive Streamlined MultimOdal Model with Interleaved Pre-Training**
COSMO presents a streamlined multimodal framework by combining a Vision Transformer with a partitioned Large Language Model, optimizing the processing of interleaved data sequences through a combination of language modeling and contrastive loss functions.
[](https://arxiv.org/abs/2401.00849v1) [](http://fingerrec.github.io/cosmo)
Alex Jinpeng Wang, Linjie Li, Kevin Qinghong Lin, Jianfeng Wang, Kevin Lin, Zhengyuan Yang, Lijuan Wang, Mike Zheng Shou

ℹ️ More Information
**COSMO**: This framework is distinctive for its architecture that merges a visual encoder, leveraging the Vision Transformer (ViT) from Open-CLIP, with a partitioned Large Language Model (LLM). The LLM is systematically divided into segments dedicated to unimodal text processing and multimodal data handling, aiming to streamline the overall processing of interleaved data sequences. The introduction of an additional contrastive loss component stands out as a strategy to improve performance across both classification and generation tasks. Training of COSMO is carried out through a unique combination of language modeling loss and contrastive loss, focusing on the efficient management of interleaved text and visual sequences. This process is optimized with the use of the AdamW optimizer, a cosine learning rate schedule, and the implementation of DeepSpeed fp16 precision, distributed across 128 NVIDIA V100 GPUs. The partitioning strategy of the LLM into dedicated components is a testament to the framework's commitment to computational efficiency and efficacy in handling extensive data sequences. The model's alignment techniques are notably advanced, featuring a learnable query that facilitates global attention across all tokens, alongside an additional query for **Text Fusion Layers**, optimizing the model's understanding of token sets and enhancing image-text alignment through contrastive loss. **The gated cross-attention layers** for multimodal fusion introduce a significant reduction in learnable parameters by introducing bottlenecks in input and output feature channels. This method of lightweight fusion is pivotal in integrating visual information for precise next-token prediction. COSMO's training leverages a diverse array of datasets including CC3M, SBU, LAION400M, DataComp1B, MMC4, WebVid, and Howto-Interlink7M. The introduction of Howto-Interlink7M, in particular, underscores the model's innovative approach to improving video-language understanding through high-quality annotated captions, demonstrating its effectiveness across 14 diverse downstream tasks.
## **FireLLaVA**
FireLLaVA breaks new ground by combining the CodeLlama 34B Instruct model for advanced language understanding with a CLIP-ViT-based visual interpretation component, training on a unique dataset incorporating bounding box labels and captions to excel in visual language conversations.
[](https://huggingface.co/fireworks-ai/FireLLaVA-13b)
ℹ️ More Information
**FireLLaVA**: As the first of its kind within the LLaVA lineage, FireLLaVA integrates a dual-component architecture that leverages the CodeLlama 34B Instruct model for nuanced language understanding and a visual interpretation component akin to OpenAI's CLIP-ViT. This model is distinctive for its use of bounding box labels and captions to generate visual language conversations, a method that underscores its innovative approach to multi-modal training. The training regimen for FireLLaVA is meticulously crafted, utilizing 588K lines of visual question answering and conversation data. This dataset amalgamates permissive original LLaVA data with newly generated data from Fireworks.ai, demonstrating a unique approach to instruction fine-tuning that enhances the model's ability to comprehend and articulate responses that bridge textual and visual inputs. The integration of bounding box labels and captions not only serves as a mechanism for generating training data but also facilitates the alignment of text and image data, a crucial step in achieving coherent multi-modal understanding. Although the specific methods employed for alignment fusion within FireLLaVA's architecture remain under-described, it is inferred that embedding fusion plays a critical role in synthesizing vision and text inputs. By drawing on original LLaVA training materials and Fireworks.ai's proprietary data, FireLLaVA sets a precedent for the development of VLMs capable of navigating the complexities of commercial applications. This model embodies a significant advancement in the field of visual language modeling, offering insights into the potential of OSS models to contribute to the evolving landscape of multi-modal AI research and deployment.
## **u-LLaVA: Unifying Multi-Modal Tasks via Large Language Model**
u-LLaVA introduces a novel projector-based architecture that unifies multi-modal tasks by connecting specialized expert models with a central Large Language Model (LLM), enabling seamless modality alignment and efficient multi-task learning through a two-stage training approach.
[](https://arxiv.org/abs/2311.05348) [](https://github.com/OPPOMKLab/u-LLaVA)
Jinjin Xu, Liwu Xu, Yuzhe Yang, Xiang Li, Yanchun Xie, Yi-Jie Huang, Yaqian Li

ℹ️ More Information
**u-LLaVA**: Represents a pioneering approach in the integration of Large Language Models (LLMs) with specialized expert models to address a wide array of multi-modal tasks. This architecture is designed to leverage the strengths of LLMs as a central hub, facilitating seamless modality alignment and multi-task learning. Through a novel **projector-based structure** that incorporates CLIP's Vision Transformer (ViT-L/14) and LLaMA2, u-LLaVA introduces a flexible framework capable of handling diverse modalities and tasks. The system integrates special tokens for modality and task expressions, alongside dedicated modules for segmentation, grounding, and in-painting, to enrich its multi-modal capabilities. The training methodology of u-LLaVA is executed in two distinct stages, beginning with a coarse-grained alignment to ensure the alignment of representation spaces across different modalities. This foundational step is crucial for establishing a common ground for further, more nuanced task-specific adaptations. Following this, a fine-grained alignment phase focuses on the refinement of task-specific instruction data, optimizing the model's performance for targeted applications. This dual-stage training approach ensures that u-LLaVA can efficiently adapt to a variety of tasks with minimal additional training requirements. Central to u-LLaVA's effectiveness is its innovative use of projector-based alignment techniques and fusion methods, which enable the integration of visual and textual representations within the LLM's framework. By mapping hidden states and text embeddings through projectors, u-LLaVA facilitates modality fusion, leveraging the extensive knowledge embedded within LLMs for complex task solving. The datasets utilized for training, including LLaVA CC3M, Conversation-58K, Detail-23K, and others, are meticulously curated to support the model's versatile capabilities across tasks such as image captioning, video captioning, visual question answering (VQA), referential expression comprehension (RES), semantic segmentation, and salient object detection/segmentation. This strategic selection and organization of datasets underscore u-LLaVA's commitment to advancing multi-modal task unification through Large Language Models.
## **MoE-LLaVA: Mixture of Experts for Large Vision-Language Models**
MoE-LLaVA introduces a novel approach by incorporating Mixture of Experts (MoE) within a large vision-language model, using learnable routers to selectively activate expert modules for processing specific tokens, thereby enhancing efficiency and enabling nuanced understanding of multimodal inputs.
[](https://arxiv.org/abs/2401.15947) [](https://github.com/PKU-YuanGroup/MoE-LLaVA) [](https://huggingface.co/spaces/LanguageBind/MoE-LLaVA)
Bin Lin, Zhenyu Tang, Yang Ye, Jiaxi Cui, Bin Zhu, Peng Jin, Jinfa Huang, Junwu Zhang, Munan Ning, Li Yuan

ℹ️ More Information
**MoE-LLaVA**: Represents an innovative leap in the development of large vision-language models through the integration of **Mixture of Experts (MoE)** within a sophisticated architectural framework. This model is characterized by its sparse design, wherein individual tokens are directed towards a selection of experts based on **learnable routers**, ensuring that only the top-k experts are activated for any given token's processing. Such an approach not only enhances the model's efficiency but also its capability to handle diverse and complex data inputs by leveraging specialized processing paths for different types of information. At the heart of MoE-LLaVA's architecture are several critical components, including a vision encoder, **a visual projection MLP layer**, **word embedding layers**, **multi-head self-attention blocks**, **feed-forward neural networks**, and notably, **the MoE blocks** themselves. These elements are seamlessly integrated through the use of layer normalization and residual connections, establishing a robust and adaptable framework capable of deep multimodal understanding. The training methodology for MoE-LLaVA is meticulously structured in three stages, each designed to gradually enhance the model's proficiency in integrating and processing visual and textual data. This includes initial adaptation of image tokens, training of all LLM parameters excluding the vision encoder, and specialized training of the MoE layers, with the latter utilizing initialization weights from previous stages for optimal performance. Alignment techniques and fusion methods employed by MoE-LLaVA are pivotal in achieving a harmonious integration of text and image modalities. By utilizing learnable routers to dynamically allocate tokens to the most apt experts and subsequently processing these through a combination of LLM and MoE blocks, the model achieves a nuanced understanding of multimodal inputs. The datasets employed throughout the training phases—ranging from LLaVA-PT for pretraining to Hybrid-FT for multimodal instruction tuning, and LLaVA-FT for fine-tuning the MoE layers—further underscore the model's ability to refine its understanding across a broad spectrum of multimodal tasks. This strategic deployment of diverse datasets not only facilitates a comprehensive tuning of the model's capabilities but also underscores its potential in advancing the field of vision-language processing.
## **BLIVA: A Simple Multimodal LLM for Better Handling of Text-rich Visual Questions**
BLIVA augments the InstructBLIP model with a Visual Assistant, incorporating encoded patch embeddings alongside learned query embeddings to enhance the LLM's understanding of text-rich visual contexts, thereby excelling in handling complex visual questions.
[](https://arxiv.org/abs/2308.09936v3) [](https://github.com/mlpc-ucsd/bliva)
Wenbo Hu, Yifan Xu, Yi Li, Weiyue Li, Zeyuan Chen, Zhuowen Tu

ℹ️ More Information
**BLIVA**: This model builds upon the foundation of InstructBLIP, incorporating a Visual Assistant to enhance its understanding and processing of text-rich visual contexts. BLIVA's architecture is designed to capture the intricacies of visual content that may be overlooked during the query decoding process by melding learned query embeddings from InstructBLIP with directly projected encoded patch embeddings. The core components of BLIVA include a vision tower, responsible for encoding visual inputs into patch embeddings; a **Q-former**, which refines query embeddings; and a **projection layer** that bridges the visual and linguistic domains, enabling the LLM to access a rich tapestry of visual knowledge. The training methodology of BLIVA is structured around a two-stage scheme: initial pre-training on image-text pairs derived from captioning datasets, followed by instruction tuning using Visual Question Answering (VQA) data. This process begins with the pre-training of the projection layer for patch embeddings, succeeded by the fine-tuning of both the Q-former and the projection layer, while the image encoder and LLM remain static to prevent catastrophic forgetting. This approach ensures that BLIVA is finely attuned to visual information, enhancing its ability to handle complex visual questions. BLIVA's alignment techniques and fusion methods stand out for their integration of learned query embeddings with an additional visual assistant branch that utilizes encoded patch embeddings. By concatenating these embeddings and feeding them directly into the LLM, BLIVA significantly improves the model's text-image visual perception capabilities. This enhanced multimodal understanding is further demonstrated through the use of diverse datasets, including image captioning datasets for pre-training, instruction tuning VQA data for performance enhancement, and YTTB-VQA (YouTube Thumbnail Visual Question-Answer pairs) to showcase BLIVA's proficiency in processing text-rich images and its suitability for real-world applications.
## **MobileVLM: A Fast, Strong and Open Vision Language Assistant for Mobile Devices**
MobileVLM offers a mobile-optimized vision-language model that combines a CLIP ViT-L/14 visual encoder with the efficient MobileLLaMA language model and a Lightweight Downsample Projector (LDP), enabling effective multimodal processing and alignment within the constraints of mobile devices.
[](https://arxiv.org/abs/2312.16886) [](https://github.com/meituan-automl/mobilevlm)
Xiangxiang Chu, Limeng Qiao, Xinyang Lin, Shuang Xu, Yang Yang, Yiming Hu, Fei Wei, Xinyu Zhang, Bo Zhang, Xiaolin Wei, Chunhua Shen
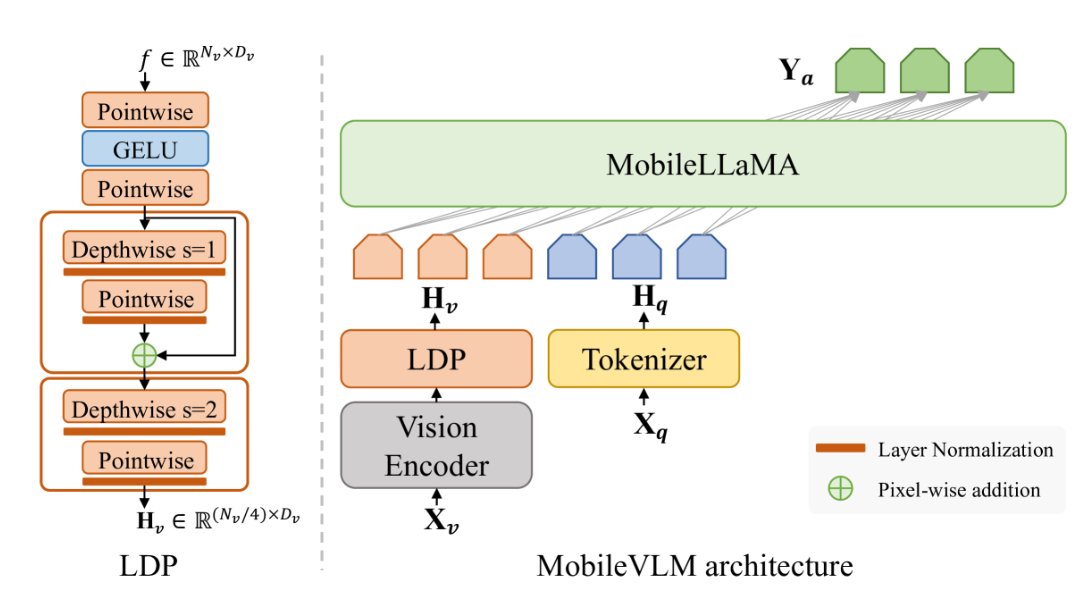
ℹ️ More Information
**MobileVLM**: Introduces a compact yet robust architecture designed to facilitate efficient vision-language tasks on mobile devices, distinguishing itself through a blend of specialized components and a streamlined training methodology tailored for edge computing environments. At its core, MobileVLM integrates a visual encoder based on the CLIP ViT-L/14 model with a resolution of 336x336, MobileLLaMA—a language model optimized for mobile devices, and a **Lightweight Downsample Projector (LDP)** that bridges the gap between visual and textual data with minimal computational overhead. This synergy between components ensures that MobileVLM can process and align multimodal inputs effectively, making it well-suited for mobile applications where resource efficiency is paramount. The training regimen for MobileVLM unfolds in three distinct phases, each contributing uniquely to the model's development. Initially, the language model undergoes pre-training using the text-centric RedPajama v1 dataset, laying a solid linguistic foundation. Subsequent supervised fine-tuning leverages multi-turn dialogues between humans and ChatGPT, refining the model's conversational abilities. The final stage involves training the integrated vision-language model on diverse multimodal datasets, equipping MobileVLM with the capacity to interpret and respond to both visual and textual stimuli. This comprehensive training approach ensures that MobileVLM achieves a balance between performance and efficiency, making it adept at handling complex vision-language interactions on mobile platforms. Central to MobileVLM's effectiveness is the Lightweight Downsample Projector (LDP), a novel component designed for the efficient alignment of visual and textual features. By employing mobile-friendly operations such as depth-wise convolution, LDP manages to downsample visual tokens to match the language model's input dimensions, preserving spatial information while minimizing computational demands. This alignment mechanism, in conjunction with the efficient fusion of vision and text embeddings, enables MobileVLM to maintain high levels of accuracy and responsiveness in mobile environments. Through the use of carefully selected datasets, including RedPajama v1 for linguistic pre-training and various multimodal datasets for comprehensive vision-language modeling, MobileVLM showcases its capability to navigate the challenges of mobile-based vision-language tasks with remarkable efficiency.
## **FROZEN: Multimodal Few-Shot Learning with Frozen Language Models**
FROZEN enables multimodal few-shot learning by pairing a pre-trained, frozen language model with a trainable vision encoder (NF-ResNet-50) that converts images into a dynamic visual prefix, allowing the model to process and generate language in context with visual data without altering its core language capabilities.
[](https://arxiv.org/abs/2106.13884)
Maria Tsimpoukelli, Jacob Menick, Serkan Cabi, S. M. Ali Eslami, Oriol Vinyals, Felix Hill

ℹ️ More Information
**FROZEN**: Presents an innovative approach to extending the few-shot learning capabilities of pre-existing language models into the multimodal domain, specifically targeting the integration of visual and linguistic elements without the need to alter the foundational language model parameters. This methodology introduces a vision encoder, specifically an **NF-ResNet-50**, designed to translate images into a continuous sequence of embeddings. These embeddings serve as a visual prefix to the input for a pre-trained autoregressive language model based on the Transformer architecture, enabling the language model to process and generate content relevant to the given visual context. The core innovation lies in the system's modularity, achieved by keeping the language model's weights static while **only updating the vision encoder** during training. This approach leverages the Conceptual Captions dataset, focusing on the alignment of image-caption pairs to train the vision encoder, thereby simplifying the integration of visual data into language models. The architecture of FROZEN is distinguished by its use of a dynamic visual prefix, a departure from the conventional static text prompts typical in prefix tuning. This dynamic prefix is achieved by linearly mapping and reshaping the vision encoder's output into a sequence of embeddings, mirroring the functionality of text-based prefix tokens in traditional language model tuning. This mechanism allows the model to adapt more fluidly to multimodal inputs, enhancing its ability to interpret and generate language that is contextually aligned with visual data. The employment of a dynamic visual prefix is a key factor in FROZEN's ability to improve task performance across multimodal settings through in-context learning, providing a novel solution to the challenge of incorporating visual information into the language generation process. The utilization of the Conceptual Captions dataset is central to FROZEN's training methodology, enabling the **vision encoder to adeptly convert images** into a format that the language model can process. This dataset serves the dual purpose of enhancing the model's understanding of visual content and its associated linguistic descriptions, thereby facilitating the generation of accurate and contextually relevant captions. The strategic combination of a static language model with a trainable vision encoder encapsulates FROZEN's approach to multimodal few-shot learning, offering a streamlined and effective pathway to integrating visual data into linguistic models.
## **Flamingo: a Visual Language Model for Few-Shot Learning**
Flamingo pioneers a Perceiver-based VLM architecture that utilizes a Perceiver Resampler and gated cross-attention dense layers, enabling it to process interleaved text and visual sequences for impressive few-shot learning performance across a variety of multimodal tasks.
[](https://arxiv.org/abs/2204.14198v2)
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, Karen Simonyan

ℹ️ More Information
**Flamingo**: Represents an innovative approach in the realm of Visual Language Models (VLMs), specifically designed to excel in few-shot learning tasks. This model is distinguished by its capacity to process sequences of text tokens that are interwoven with visual data, such as images or videos, to generate textual outputs. At the core of Flamingo's architecture is the adoption of a Perceiver-based framework that adeptly manages high-resolution visual inputs. This design choice enables the handling of complex, multimodal information streams by transforming large visual feature maps into a concise number of visual tokens through the **Perceiver Resampler**. Further refining its architecture, Flamingo incorporates **gated cross-attention dense (GATED XATTN-DENSE) layers**, which play a pivotal role in conditioning the language model on visual inputs, thereby facilitating a nuanced understanding and generation of language based on the visual context. The training regimen of Flamingo is both extensive and diverse, encompassing a wide array of datasets culled from the web. This includes a rich mixture of interleaved image and text data, image-text pairs, and video-text pairs, which collectively contribute to the model's robust few-shot learning capabilities. A distinctive aspect of Flamingo's training is its strategy to minimize a weighted sum of per-dataset expected negative log-likelihoods of text given visual inputs. This approach, combined with a gradient accumulation strategy across all datasets, ensures comprehensive learning from varied multimodal contexts. The datasets employed in training, namely MultiModal MassiveWeb (M3W), ALIGN dataset, Long Text & Image Pairs (LTIP), and Video & Text Pairs (VTP), each serve a specific purpose. M3W facilitates training on interleaved text and image data, ALIGN on image-text pairs, LTIP on high-quality image-text pairs, and VTP on video-text pairs, ensuring Flamingo's adeptness across different visual language tasks. In its alignment techniques, Flamingo introduces an image-causal modeling approach to manage text-to-image cross-attention effectively, allowing the model to attend selectively to visual tokens of the image that immediately precede the given text token in the sequence. This capability is further enhanced by the gated cross-attention layers, which employ a tanh-gating mechanism to merge the output of these layers with the input representation from the residual connection. Such an alignment fusion method ensures that Flamingo can seamlessly integrate vision and text embeddings, underscoring its innovative architecture and the breadth of its training. Through these mechanisms, Flamingo stands out as a significant advancement in the integration of visual and textual data for language model training, showcasing its versatility and effectiveness in few-shot learning scenarios.
## **OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models**
OpenFlamingo, an open-source adaptation of DeepMind's Flamingo, combines a CLIP ViT-L/14 visual encoder with a 7B parameter language model, utilizing frozen cross-attention modules for efficient and effective multimodal fusion during the decoding process, resulting in impressive performance on various vision-language tasks.
[](https://arxiv.org/abs/2308.01390) [](https://github.com/mlfoundations/open_flamingo)
Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Wortsman, Ludwig Schmidt
ℹ️ More Information
**OpenFlamingo**: Represents an innovative leap in the integration of vision and language models, providing an open-source adaptation of DeepMind's Flamingo framework. This model is structured around a powerful combination of a CLIP Vision Transformer Large (ViT-L/14) for encoding visual inputs and a 7-billion parameter Multimodal Pretrained Transformer (MPT-7B) for language processing. The architecture is distinctive for its inclusion of cross-attention modules within every fourth decoder block of the language model, which remains frozen during training. These modules are pivotal for the model's ability to attentively merge visual information with textual context during the decoding process, thereby enhancing its multimodal understanding. The training methodology for OpenFlamingo is grounded in a comprehensive strategy that harnesses the vast data landscape of the internet. It utilizes a rich dataset amalgam comprising LAION-2B and the Multimodal version of the Common Crawl (C4) dataset, focusing on image-text pair sequences. This approach is facilitated by DistributedDataParallel training across an impressive array of 64 A100 80GB GPUs, leveraging automatic BF16 mixed precision for optimized performance. The model's alignment techniques are inspired by the original Flamingo's design philosophy, which emphasizes the importance of keeping the core vision and language models static while dynamically training the connecting **cross-attention modules** for decoding. This selective training process ensures that OpenFlamingo can effectively fuse visual and textual data, thereby significantly improving its proficiency in generating relevant text based on visual cues. Furthermore, the datasets used are instrumental in refining OpenFlamingo's capacity for understanding complex visual-textual interactions. Trained specifically on image-text sequences, the model demonstrates superior performance in tasks requiring nuanced interpretation of visual content, such as captioning, visual question answering, and image classification. This strategic focus on multimodal datasets underscores the model's purpose to bridge the gap between visual perception and linguistic expression, marking a substantial advancement in the field of multimodal AI. Through these architectural innovations and training strategies, OpenFlamingo sets a new standard for open-source models in the domain of visual-language tasks.
## **IDEFICS**
IDEFICS, an 80B parameter vision-language model inspired by Flamingo, processes interleaved image and text sequences, utilizing a GPT-4 and Flamingo-based architecture to achieve robust multimodal understanding, trained on a diverse range of web-based datasets, including the specialized OBELICS dataset.
[](https://huggingface.co/HuggingFaceM4/idefics-80b)
ℹ️ More Information
**IDEFICS**: stands for "an 80 billion parameters vision and language model," distinguishing itself as a robust model designed to mimic Flamingo's capabilities while integrating substantial advancements in handling multimodal inputs. This model is crafted to accept sequences of images and text, generating text outputs that reflect a deep understanding of both visual and textual information. The architecture of IDEFICS builds on the foundations laid by GPT-4 and Flamingo, showcasing a harmonious blend of vision and language processing capabilities within a singular model framework. This strategic design allows IDEFICS to process and interpret complex multimodal inputs efficiently, setting a new precedent in the field of integrated vision-language models. During its development, IDEFICS faced challenges related to loss spikes, which were effectively mitigated through rollback strategies and precise adjustments in the learning rate. An auxiliary z-loss was introduced to normalize logits, significantly enhancing training stability. The model adopts Flamingo's methodological approach for alignment, utilizing pretrained vision and language backbones to foster a nuanced cross-modal understanding. Although specific details on fusion techniques for vision and text embeddings remain under wraps, it is inferred that the model employs **cross-attention mechanisms** akin to Flamingo's, facilitating a sophisticated integration of visual and textual data. Training on OBELICS—a meticulously curated collection of interleaved image-text web documents—and other web-scraped datasets, IDEFICS aims to excel in multimodal tasks. The OBELICS dataset, in particular, is designed to augment the model's performance by providing access to longer text contexts and a diverse array of web document types. This strategic dataset selection underscores IDEFICS's commitment to enhancing its proficiency across a spectrum of multimodal applications, leveraging the rich, varied content found in web documents to refine its understanding and output generation capabilities.
## **PaLI: A Jointly-Scaled Multilingual Language-Image Model**
PaLI distinguishes itself as a jointly-scaled multilingual language-image model that utilizes a unified interface to process both unimodal and multimodal tasks, integrating a powerful ViT-e visual encoder with an mT5-based text encoder-decoder Transformer for comprehensive language and vision understanding.
[](https://arxiv.org/abs/2209.06794) [](https://github.com/google-research/big_vision)
Xi Chen, Xiao Wang, Lucas Beyer, Alexander Kolesnikov, Jialin Wu, Paul Voigtlaender, Basil Mustafa, Sebastian Goodman, Ibrahim Alabdulmohsin, Piotr Padlewski, Daniel Salz, Xi Xiong, Daniel Vlasic, Filip Pavetic, Keran Rong, Tianli Yu, Daniel Keysers, Xiaohua Zhai, Radu Soricut

ℹ️ More Information
**PALI**: This model stands out by its ability to handle both unimodal (language or vision) and multimodal (language and vision together) tasks through a unified interface that accepts images and text as inputs, subsequently generating text as the output. The architecture of PALI ingeniously integrates a text encoder-decoder Transformer, based on pre-trained mT5 models, with visual tokens processed by a Vision Transformer (ViT) named ViT-e. ViT-e marks a significant advancement in visual processing with up to 4 billion parameters, setting a new precedent for the integration of visual components within language models. The PALI model utilizes pre-trained unimodal checkpoints, optimizing the efficiency of its training processes. Training methodologies for PALI are robust and diverse, incorporating a mixture of pre-training tasks aimed at enhancing the model's capability across a broad spectrum of downstream applications. Leveraging the expansive image-language dataset WebLI, which encompasses 10 billion images and texts across over 100 languages, PALI undergoes a comprehensive two-phase training regime. This includes a specific focus on high-resolution training for its largest model variant, PALI-17B. Such an approach ensures that PALI is not just multilingual but also highly adept at processing and understanding complex visual and textual data. The alignment and fusion techniques employed by PALI are particularly noteworthy. By adopting a unified modeling interface, the model treats various tasks with a task-agnostic perspective, allowing it to seamlessly transition between different types of vision and language tasks. The fusion of vision and text is achieved through **a cross-attention mechanism**, where a sequence of visual tokens from the Vision Transformer is integrated with the text encoder-decoder Transformer. This method enables an efficient and effective blending of multimodal information. The use of datasets such as WebLI, Conceptual Captions, and OCR data from WebLI, along with others like VQ2A-CC3M and Open Images, further enriches PALI's training, equipping it with a vast and versatile multimodal proficiency. This proficiency spans across multilingual settings, captioning, OCR, and visual question answering (VQA), ensuring PALI's comprehensive understanding and generation capabilities across a wide array of languages and tasks.
## **PaLI-3 Vision Language Models: Smaller, Faster, Stronger**
PaLI-3 presents a powerful yet efficient vision-language model that integrates a contrastively pretrained 2B SigLIP vision model with a 3B UL2 Transformer, achieving impressive performance in tasks like captioning and visual question answering through a multi-stage training process that emphasizes scalability and robustness.
[](https://arxiv.org/abs/2310.09199) [](https://github.com/kyegomez/PALI3)
Xi Chen, Xiao Wang, Lucas Beyer, Alexander Kolesnikov, Jialin Wu, Paul Voigtlaender, Basil Mustafa, Sebastian Goodman, Ibrahim Alabdulmohsin, Piotr Padlewski, Daniel Salz, Xi Xiong, Daniel Vlasic, Filip Pavetic, Keran Rong, Tianli Yu, Daniel Keysers, Xiaohua Zhai, Radu Soricut
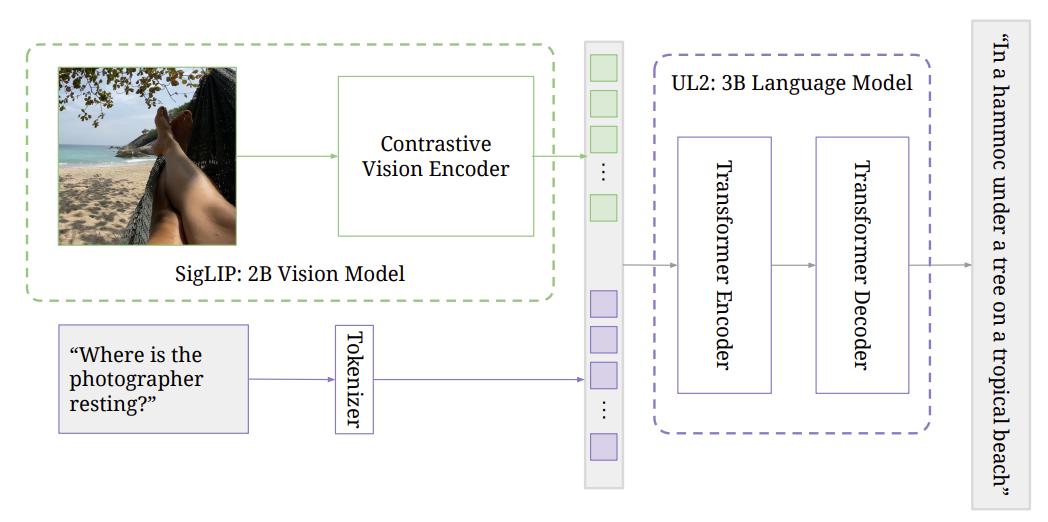
ℹ️ More Information
**PaLI-3** :Its architecture integrates a contrastively pretrained 2B **SigLIP vision model** with a 3B encoder-decoder UL2 Transformer, focusing on the efficient processing of visual and textual data. The training methodology of PaLI-3 includes **contrastive pretraining of the image encoder** on a vast scale of image-text data, subsequent multimodal training, and resolution increase stages to refine its performance further. These stages ensure that PaLI-3 achieves a nuanced understanding of visually-situated text and object localization, supported by datasets such as Web-scale image-text data, RefCOCO, WebLI, CC3M-35L, and various VQA datasets. The visual component of PaLI-3 utilizes a vision transformer pretrained in a contrastive manner, emphasizing efficiency, scalability, and robustness. This approach allows for a more nuanced pretraining of the image embedding component, which, when combined with text embeddings, enhances the model's ability to understand and generate text based on visual inputs. The full model employs these visual tokens alongside embedded input text tokens within a UL2 encoder-decoder framework, demonstrating its capability in generating text outputs for tasks such as captioning and visual question answering (VQA). PaLI-3's training process involves several key stages, starting with unimodal pretraining of the image encoder using image-text pairs from the web. This is followed by multimodal training, where the image encoder and text encoder-decoder are combined and trained on a mixture of tasks and data, focusing on visually-situated text and object detection. The resolution increase stage further enhances performance by fine-tuning the model with high-resolution inputs. Finally, task specialization involves fine-tuning PaLI-3 on individual benchmark tasks, optimizing its performance across a wide range of applications.
## **PaLM-E: An Embodied Multimodal Language Model**
PaLM-E innovates by embedding continuous sensory data, including images and sensor readings, into the language representation space of a pre-trained PaLM model, enabling it to process and generate text that reflects embodied reasoning and understanding of the physical world.
[](https://arxiv.org/abs/2303.03378) [](https://palm-e.github.io)
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, Pete Florence
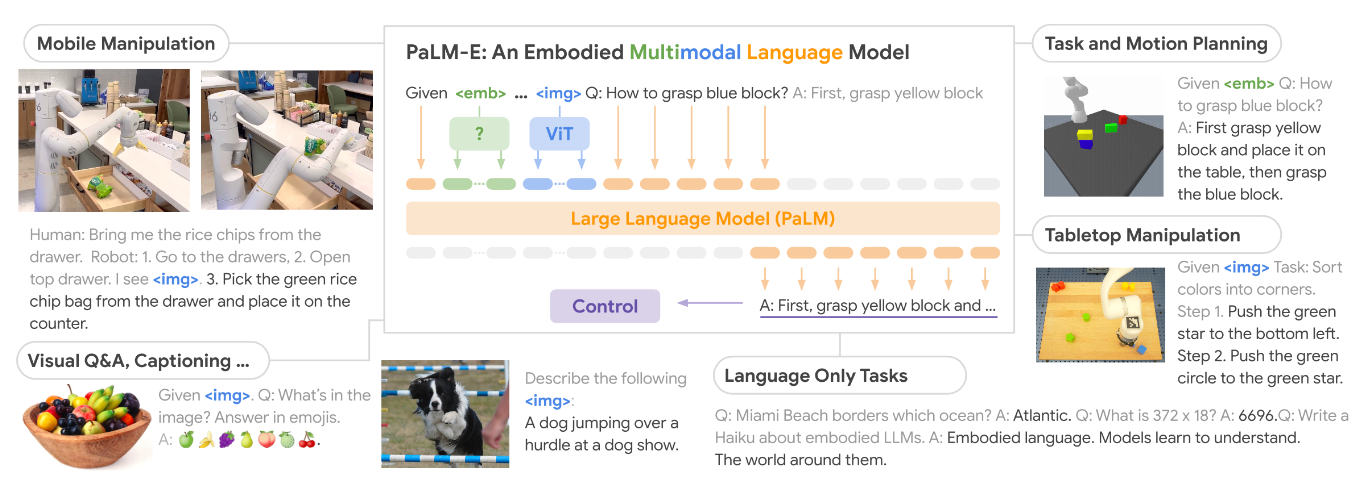
ℹ️ More Information
**PaLM-E**: Represents an innovative step in the development of multimodal language models by integrating continuous embodied observations—ranging from images and state estimates to various sensor modalities—into the linguistic embedding space of a pre-trained language model. It utilizes a decoder-only large language model (LLM) architecture that generates textual completions autoregressively, taking multimodal inputs into account. The core architecture of PaLM-E leverages a pre-trained PaLM as its language backbone, enhancing it with encoders that transform sensor modalities into a **sequence of vectors** compatible with the language model's embedding dimensions. This integration allows for the seamless combination of continuous sensor information with textual data, crafting multimodal sentences that the model processes. Training methodologies for PaLM-E are comprehensive and end-to-end, utilizing datasets composed of both continuous observations and textual information. The model employs a cross-entropy loss function for non-prefix tokens, with a training regimen that includes pre-trained Vision Transformers (ViTs) for image feature extraction alongside novel and pre-trained input encoders. The approach allows for flexibility in model training, including options for freezing pre-trained components or co-training them across varied data sets. This strategy ensures that PaLM-E benefits from both the depth of pre-trained models and the specificity of tailored encoders for continuous data. PaLM-E's alignment techniques and fusion methods are pivotal for its operation, employing encoders to integrate continuous sensor data into the linguistic embedding space effectively. This integration facilitates an understanding and generation of responses that reflect a blend of textual and sensor input, mimicking embodied reasoning. The model processes multimodal sentences—interleaved sequences of sensor observations and text—through its **self-attention layers**, similar to how it handles traditional text tokens. This methodology ensures a cohesive encoding of vision and text information. PaLM-E's training leverages a diverse array of datasets, including large-scale vision-and-language data and specialized robotics tasks datasets, aiming to excel across a broad spectrum of embodied reasoning tasks. This diverse training background enables PaLM-E to harness cross-domain transfer learning, enhancing its capabilities in specific robotics applications and general vision-language tasks alike.
## **MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models**
MiniGPT-4 seamlessly blends visual and language processing by connecting a pretrained Vision Transformer and Q-Former to a frozen Vicuna LLM using a single linear projection layer, achieving impressive vision-language understanding through a two-stage training approach focused on efficient alignment and enhanced generation quality.
[](https://arxiv.org/abs/2304.10592v2) [](https://github.com/vision-cair/minigpt-4)
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, Mohamed Elhoseiny

ℹ️ More Information
**MiniGPT-4**: presents an advanced integration of vision and language processing capabilities through a meticulously designed architecture that marries a frozen visual encoder with a frozen advanced Large Language Model (LLM), specifically Vicuna. At the heart of MiniGPT-4 is its novel approach to aligning visual and linguistic modalities: it employs **a single linear projection layer** to bridge the pretrained Vision Transformer (ViT) and **Q-Former** with the Vicuna LLM. This design choice underscores a commitment to efficiency, focusing on leveraging existing, robust components to achieve a seamless integration of visual features with sophisticated language capabilities. The training methodology for MiniGPT-4 is bifurcated into two distinct stages, optimizing both the initial alignment of visual and language features and the subsequent enhancement of generation reliability and naturalness. Initially, MiniGPT-4 undergoes training for 20,000 steps with a batch size of 256 on 4 A100 GPUs, utilizing a combined dataset from sources like Conceptual Captions, SBU, and LAION for foundational vision-language knowledge. This stage is crucial for establishing the basic alignment between the visual encoder and the Vicuna LLM. The second stage of finetuning, leveraging a curated dataset of 3,500 detailed image descriptions, is pivotal for refining the model's output, focusing on generating more detailed, reliable, and naturally flowing text. The strategic use of datasets in MiniGPT-4's training regimen underscores its dual objectives: foundational vision-language alignment and the enhancement of output naturalness and detail. Initial datasets facilitate the basic integration of visual and linguistic elements, while the curated dataset of detailed image descriptions serves to significantly improve the model's capability in generating nuanced and accurate natural language descriptions. Through this comprehensive and staged training approach, MiniGPT-4 achieves a refined balance between efficient visual-language alignment and the production of high-quality, detailed textual outputs, marking a significant step forward in the field of vision-language understanding.
## **MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning**
MiniGPT-v2 acts as a unified interface for vision-language multi-task learning by connecting a static Visual Transformer to a 7B parameter LLaMA-2-chat language model through a linear projection layer, efficiently processing high-resolution images and excelling in various tasks through a three-stage training approach.
[](https://arxiv.org/abs/2310.09478v3)
Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, Mohamed Elhoseiny

ℹ️ More Information
**MiniGPT-v2**: A sophisticated model designed to serve as a unified interface for vision-language multi-task learning, leveraging the innovative integration of a visual backbone with a large language model. At its core, the architecture combines a Visual Transformer (ViT) as its visual backbone, which is kept static during training, with **a linear projection layer** that effectively merges every four neighboring visual tokens into one. These consolidated tokens are then projected into the feature space of LLaMA-2-chat, a 7-billion parameter language model, facilitating the processing of high-resolution images (448x448 pixels). This structure allows MiniGPT-v2 to efficiently bridge the gap between visual input and language model processing, catering to a wide array of vision-language tasks. The training methodology employed by MiniGPT-v2 is particularly noteworthy, encompassing a three-stage strategy to comprehensively cover the spectrum of knowledge acquisition and task-specific performance enhancement. Initially, the model is exposed to a mix of weakly-labeled and fine-grained datasets, focusing on broad vision-language understanding. The training progressively shifts towards more fine-grained data to hone in on specific task improvements. In the final stage, MiniGPT-v2 is trained on multi-modal instruction and language datasets, aiming to refine its response to multi-modal instructions. The use of task-specific identifier tokens during training plays a crucial role in reducing ambiguity and sharpening task distinction, enabling the model to adeptly navigate the complexities of vision-language tasks. To support its extensive training and operational capabilities, MiniGPT-v2 utilizes a diverse array of datasets, including LAION, CC3M, SBU, GRIT-20M, COCO caption, and several others, each selected to fulfill distinct stages of the training process—from broad knowledge acquisition to task-specific improvements and sophisticated multi-modal instruction handling. This strategic dataset employment underscores MiniGPT-v2's capacity to assimilate and apply knowledge across a broad range of vision-language contexts, positioning it as a versatile tool in the evolving landscape of multi-task learning interfaces.
## **LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents**
LLaVA-Plus pioneers the creation of multimodal agents by integrating diverse vision and vision-language models into a skill repository, enabling the agent to learn and use tools effectively through end-to-end training on comprehensive multimodal instruction-following data.
[](https://arxiv.org/abs/2311.05437) [](https://github.com/LLaVA-VL/LLaVA-Plus-Codebase)
Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang, Jianfeng Gao, Chunyuan Li
ℹ️ More Information
**LLaVA-Plus**: Represents an innovative leap in the design of multimodal agents, integrating a diverse array of vision and vision-language pre-trained models into a comprehensive skill repository. This integration enables LLaVA-Plus to leverage end-to-end training to systematically expand its capabilities, allowing it to activate and combine relevant tools based on the users' multimodal inputs. The architecture of LLaVA-Plus is centered around a unified scheme for representing **multimodal instruction-following data**, which is essential for its advanced end-to-end trained multimodal instruction-following capabilities. The model is distinguished by its training methods, which utilize curated multimodal instruction-following data covering a broad spectrum of tasks, including visual understanding, generation, external knowledge retrieval, and their combinations. This approach allows LLaVA-Plus to incorporate new tools through instruction tuning, thereby expanding its abilities by learning to use these tools effectively. The training datasets—COCO, HierText, InfoSeek, JourneyDB, and Instruct P2P—are meticulously selected to enhance the model's training on visual understanding skills such as detection, segmentation, captioning, OCR, and external knowledge retrieval, alongside generation tasks and skill compositions. LLaVA-Plus employs unique alignment techniques and fusion methods that utilize raw visual signals during human-AI interaction sessions to improve tool use performance, planning, and reasoning. These techniques enable the seamless integration of vision and text embeddings by combining user inputs, tool activation prompts, and execution results into a unified dialogue format. This strategic approach not only facilitates enhanced interaction between the model and its users but also significantly boosts the model's overall performance and versatility in handling complex multimodal tasks.
## **BakLLaVA**
BakLLaVA elevates the LLaVA framework by employing a Mistral 7B base enhanced with LLaVA 1.5 architecture, undergoing a meticulous two-stage training process on a diverse dataset to achieve superior performance in multimodal benchmarks, outperforming competitors like Llama 2 13B.
[](https://github.com/skunkworksai/bakllava) [](https://huggingface.co/SkunkworksAI/BakLLaVA-1)
ℹ️ More Information
**BakLLaVA**: Represents an innovative advancement in the realm of AI models, distinguishing itself with significant architectural enhancements over its predecessor, LLaVA. Developed with a strong focus on integrating multimodal capabilities into language models, BakLLaVA leverages a **Mistral 7B** base, augmented with the advanced **LLaVA 1.5 architecture**, to push the boundaries of performance in various benchmarks. This model has been meticulously designed to outperform notable predecessors, such as Llama 2 13B, across several benchmarks, showcasing the efficiency and effectiveness of its underlying architecture .The training methodology of BakLLaVA is particularly noteworthy, employing a feature alignment stage that utilizes 600K filtered CC3M images for establishing a robust vision-language connection. This process is complemented by a visual instruction tuning stage, where 150K GPT-generated multimodal instructions are utilized, signifying a tailored approach towards encoding vision and text together. Such a methodological approach not only enhances feature alignment but also optimizes the model for a broad spectrum of conceptual coverage, efficiency in training, and overall performance. BakLLaVA's architecture benefits from a diverse dataset compilation including 558K filtered image-text pairs from LAION/CC/SBU, captioned by BLIP, alongside 158K GPT-generated multimodal instruction-following data, 450K academic-task-oriented VQA data, and 40K ShareGPT data, among others. This extensive dataset collection is pivotal for the model's training, ensuring broad concept coverage and reinforcing the model's capabilities in feature alignment and visual instruction tuning. The strategic selection of datasets underscores BakLLaVA's commitment to advancing AI's understanding and processing of complex visual and textual information, setting a new standard for multimodal AI models.
## **CogVLM: Visual Expert for Pretrained Language Models**
CogVLM enhances pretrained language models with a dedicated visual expert module, incorporating a QKV matrix and MLP within each layer to achieve deep visual-language feature alignment, enabling superior performance in multimodal tasks such as image captioning and visual question answering.
[](https://arxiv.org/abs/2311.03079v2) [](https://github.com/thudm/cogvlm)
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, Jiazheng Xu, Bin Xu, Juanzi Li, Yuxiao Dong, Ming Ding, Jie Tang

ℹ️ More Information
**CogVLM**: This approach enables the model to deeply fuse vision-language features, enhancing its ability to process and understand multimodal inputs. The architecture of CogVLM is built around several key components: a Vision Transformer (ViT) encoder, **an MLP adapter**, a pretrained large language model akin to GPT, and the innovative visual expert module. These components work in tandem to facilitate the model's advanced capabilities in handling complex visual and textual information. The training methodology for CogVLM is comprehensive, encompassing both pretraining and fine-tuning phases. During pretraining, the model undergoes learning with a focus on image captioning loss and Referring Expression Comprehension (REC) across an extensive dataset comprising over 1.5 billion image-text pairs and a visual grounding dataset featuring 40 million images. The fine-tuning phase employs a unified instruction-supervised approach across a variety of visual question-answering datasets, further refining the model's performance. CogVLM's alignment techniques are particularly noteworthy, employing **a visual expert module** in each layer that leverages a **QKV (Query, Key, Value) matrix** and an **MLP (Multilayer Perceptron)** to achieve deep visual-language feature alignment. This method not only allows for the seamless integration of image features into the language model's processing layers but also significantly enhances the model's overall multimodal processing capabilities. The datasets employed in training and refining CogVLM include LAION-2B, COYO-700M, a visual grounding dataset of 40 million images, and several visual question-answering datasets like VQAv2, OKVQA, TextVQA, OCRVQA, and ScienceQA. These datasets serve multiple purposes, from pretraining and instruction alignment to enhancing the model's proficiency in tasks such as image captioning and referring expression comprehension. Through this strategic use of diverse datasets, CogVLM is positioned to excel in a wide array of multimodal tasks, marking a significant advancement in the field of vision-language models.
## **CogVLM2: Enhanced Vision-Language Models for Image and Video Understanding**
CogVLM2 is a family of open-source visual language models designed to push the boundaries of image and video understanding. This new generation builds upon the success of previous CogVLM models, focusing on enhanced vision-language fusion, efficient high-resolution architecture, and broader modalities and applications.
[](https://arxiv.org/abs/2408.16500) [](https://github.com/THUDM/CogVLM2) [](https://huggingface.co/collections/THUDM/cogvlm2-6645f36a29948b67dc4eef75)
Wenyi Hong, Weihan Wang, Ming Ding, Wenmeng Yu, Qingsong Lv, Yan Wang, Yean Cheng, Shiyu Huang, Junhui Ji, Zhao Xue, Lei Zhao, Zhuoyi Yang, Xiaotao Gu, Xiaohan Zhang, Guanyu Feng, Da Yin, Zihan Wang, Ji Qi, Xixuan Song, Peng Zhang, Debing Liu, Bin Xu, Juanzi Li, Yuxiao Dong, Jie Tang

ℹ️ More Information
CogVLM2 is a new generation visual language model designed for comprehensive image and video understanding. It leverages a powerful ViT encoder to extract visual features from high-resolution images or video sequences, which are then downsampled by a convolutional layer and aligned with linguistic representations through a SwiGLU module. This adapter efficiently bridges the visual and language modalities while preserving critical image information. The model then utilizes a visual expert architecture, integrating visual features into both the attention and FFN modules of the language decoder. This approach allows for deep vision-language fusion without compromising the model's inherent language capabilities. Notably, CogVLM2-Video extends this architecture to handle videos, incorporating timestamps alongside multi-frame inputs to enable temporal localization and question-answering capabilities. The CogVLM2 family has achieved state-of-the-art results on various benchmarks, including MMBench, MM-Vet, TextVQA, MVBench, and VCG-Bench, showcasing its versatility and effectiveness across a wide range of image and video understanding tasks.
## **Ferret: Refer and Ground Anything Anywhere at Any Granularity**
FERRET, a multimodal large language model, excels in spatial referencing and grounding by using a hybrid region representation that combines discrete coordinates with continuous features, allowing it to precisely pinpoint objects and regions within images, regardless of their complexity.
[](https://arxiv.org/abs/2310.07704v1) [](https://github.com/apple/ml-ferret)
Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, Yinfei Yang
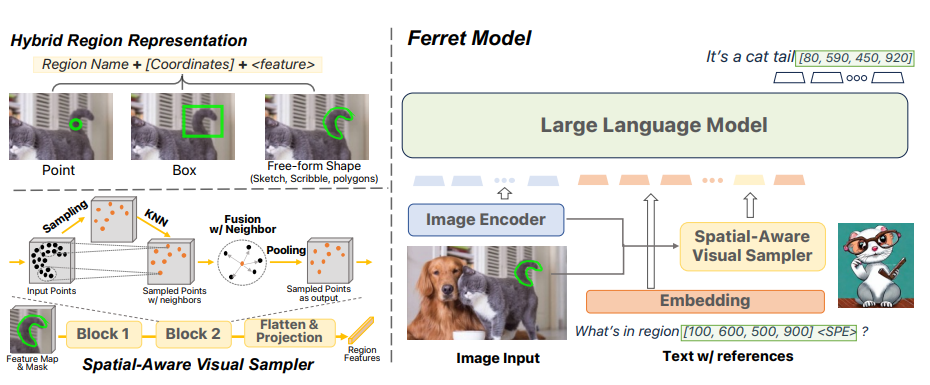
ℹ️ More Information
**FERRET**: stands as a multimodal large language model (MLLM) that pioneers in spatially referring to any object within an image, irrespective of its shape or granularity, and grounding open-vocabulary descriptions with precision. The architecture of FERRET is distinguished by its hybrid region representation, which marries discrete coordinates with continuous features to depict image regions. This novel approach enables the model to handle a wide range of spatial referring tasks, from pinpointing precise locations to addressing more abstract, shapeless areas within images. At the core of FERRET's architecture are several key components: an image encoder tasked with deriving image embeddings, **a spatial-aware visual sampler** designed to extract regional continuous features, and a language model that integrates image, text, and region features. This intricate setup facilitates the model's unique ability to understand and generate language that refers to spatial elements in images with unprecedented accuracy. The training of FERRET is conducted on the GRIT dataset, which includes over 1.1 million samples imbued with hierarchical spatial knowledge. This process is augmented by spatial-aware visual sampling techniques that cater to the diverse shapes and densities found in spatial data, allowing for the simultaneous generation of text and coordinates for objects within images.FERRET's alignment techniques and fusion methods are particularly noteworthy. By blending discrete coordinates with continuous visual features, the model can process inputs of freely formed regions and ground descriptions in its outputs accurately. This capability is supported by a diverse dataset portfolio, including GRIT for its rich spatial annotations, and Visual Genome, RefCOCOs, and Flickr30k for tasks such as object detection, phrase grounding, and evaluating the model's proficiency in referring and grounding. Through these methodologies, FERRET advances the field of multimodal language models by providing a versatile framework for spatial reasoning and language grounding in visual contexts.
## **Fuyu-8B: A Multimodal Architecture for AI Agents**
Fuyu-8B introduces a streamlined architecture for AI agents by directly projecting image patches into a decoder-only transformer, simplifying multimodal processing by treating image and text tokens uniformly, and achieving efficient performance in vision-language tasks despite its straightforward design.
[](https://www.adept.ai/blog/fuyu-8b) [](https://huggingface.co/adept/fuyu-8b)
Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar

ℹ️ More Information
**Fuyu-8B**: A streamlined multimodal model tailored for digital agents, distinguished by its unique approach to handling visual data and its integration with textual information. At the core of Fuyu-8B's architecture is a decoder-only transformer, a departure from traditional models that rely on separate image encoders. This design facilitates the direct projection of image patches into the transformer's initial layer with **a linear projection**, allowing Fuyu-8B to process images of any resolution without the need for complex training stages or the integration of resolution-specific mechanisms. The simplicity of this architecture does not only lie in its unified processing of image and text data but also in its elimination of the need for cross-attention mechanisms or adapters, streamlining the model's training and inference processes. In terms of alignment techniques, Fuyu-8B employs a novel approach by treating image tokens on par with text tokens from the inception of the model's processing pipeline. This method does away with separate position embeddings for images, thereby simplifying the alignment process between textual and visual data. The model's ability to support arbitrary image resolutions and perform fine-grained localization is particularly advantageous for applications requiring detailed visual understanding alongside textual interaction. The datasets utilized in Fuyu-8B's development, including VQAv2, OKVQA, COCO Captions, and AI2D, are instrumental in benchmarking the model against standard image understanding tasks such as visual question answering and caption generation. Despite Fuyu-8B's primary focus on applications within digital agents, the selection of these datasets ensures a comprehensive evaluation of its capabilities in broader contexts of image understanding and multimodal interaction. Through its innovative architecture and methodological simplicity, Fuyu-8B sets a new direction for the development of AI agents capable of sophisticated multimodal reasoning.
## **OtterHD: A High-Resolution Multi-modality Model**
OtterHD-8B, inspired by Fuyu-8B, directly integrates pixel-level information from high-resolution images (up to 1024x1024 pixels) into its language model using position embeddings, eliminating the need for a separate vision encoder and enabling precise interpretation of detailed visual inputs alongside textual instructions.
[](https://arxiv.org/abs/2311.04219v1) [](https://github.com/luodian/otter) [](https://huggingface.co/spaces/Otter-AI/OtterHD-Demo)
Bo Li, Peiyuan Zhang, Jingkang Yang, Yuanhan Zhang, Fanyi Pu, Ziwei Liu
ℹ️ More Information
**OtterHD-8B**: Represents an evolutionary step in multi-modality model design, building on the foundation of the **Fuyu-8B architecture** to interpret high-resolution visual inputs with exceptional precision. Unlike traditional models limited by fixed-size vision encoders, OtterHD-8B is equipped to handle flexible input dimensions, allowing for enhanced versatility across a variety of inference requirements. This model integrates pixel-level visual information directly into the language model without the need for a separate vision encoder, employing position embeddings to comprehend varying image sizes and enabling the processing of high-resolution images up to 1024x1024 pixels. Instruction tuning in OtterHD-8B is tailored towards accommodating various image resolutions, with the model being trained on a diverse dataset mixture including LLaVA-Instruct, VQAv2, GQA, OKVQA, OCRVQA, A-OKVQA, COCO-GOI, COCO-Caption, TextQA, RefCOCO, COCO-ITM, ImageNet, and LLaVA-RLHF. This training employs FlashAttention-2 and other fused operators for optimization, leveraging PyTorch and HuggingFace transformers. The direct integration of pixel-level information into the language model, facilitated by position embeddings, enables OtterHD-8B to understand and generate responses to high-resolution images alongside textual instructions without conventional vision and text embedding fusion methods. The datasets chosen for training OtterHD-8B underscore its focus on a broad array of vision and language tasks, including question answering, object recognition, and text-image alignment, aiming to enhance the model's capabilities in these areas. By directly processing image patches alongside textual instructions, OtterHD-8B eschews traditional fusion methods, leveraging its architecture to interpret and respond to complex multimodal inputs. This approach not only marks a significant advancement in handling high-resolution images but also in the model's overall ability to comprehend and interact with visual and textual data, positioning OtterHD-8B as a notable development in the field of multi-modality models.
## **SPHINX: The Joint Mixing of Weights, Tasks, and Visual Embeddings for Multi-modal Large Language Models**
SPHINX pushes the boundaries of multi-modal LLMs by jointly mixing model weights, tasks, and visual embeddings during training, utilizing a two-stage approach that unfreezes the LLM (LLaMA-2) during pre-training for enhanced cross-modal learning and achieving impressive performance on a variety of vision-language tasks.
[](https://arxiv.org/abs/2311.07575v1) [](https://github.com/alpha-vllm/)
Ziyi Lin, Chris Liu, Renrui Zhang, Peng Gao, Longtian Qiu, Han Xiao, Han Qiu, Chen Lin, Wenqi Shao, Keqin Chen, Jiaming Han, Siyuan Huang, Yichi Zhang, Xuming He, Hongsheng Li, Yu Qiao

ℹ️ More Information
**SPHINX**: stands out as a multi-modal large language model (MLLM) designed to enhance the integration of language and vision through an innovative approach that includes the **joint mixing of model weights**, tuning tasks, and visual embeddings. This model is particularly distinguished by its methodology of unfreezing the large language model during pre-training to foster more effective cross-modal learning. The architecture of SPHINX is built upon a foundation that combines vision encoders, **two linear projection layers**, and leverages LLaMA-2 as the language model backbone. It adopts a two-stage training paradigm that emphasizes pre-training for vision-language alignment followed by fine-tuning aimed at visual instruction-following tasks. In the realm of training methodologies, SPHINX employs a strategy that emphasizes **the joint mixing of model weights**, tuning tasks, and visual embeddings, setting a precedent for robust cross-modal knowledge acquisition. This approach is complemented by a pre-training regimen that utilizes both real-world and synthetic data, thereby ensuring a comprehensive understanding across various visual instruction tasks. The model introduces an efficient strategy for processing high-resolution images, utilizing mixed scales and sub-images to accommodate diverse visual inputs. Moreover, SPHINX achieves vision-language alignment by integrating comprehensive visual embeddings, unfreezing the LLM during pre-training, and employing a weight-mixing strategy that bridges domain-specific knowledge across different network architectures and training paradigms. The datasets utilized in training SPHINX, including LAION-400M, LAION-COCO, RefinedWeb, VQAV2, GQA, OKVQA, A-OKVQA, OCRVQA, TextCaps, COCO, LVIS, RefCOCO, VG, and Flickr30k, serve a multifaceted purpose. They are instrumental in achieving multi-modal alignment, language-only tuning, and addressing a wide spectrum of visual question answering and general vision tasks. These tasks range from object detection and human pose estimation to referring object localization and understanding descriptions within the context of image regions. SPHINX, through its meticulous design and strategic training approach, sets a new benchmark in the field of multi-modal large language models, advancing the capabilities in vision-language integration.
## **CLIP: Contrastive Language-Image Pre-training**
CLIP leverages a contrastive learning approach, training separate image and text encoders on a massive dataset of 400 million image-text pairs to predict the most relevant captions for images, enabling impressive zero-shot transfer capabilities to various downstream tasks without requiring task-specific training data.
[](https://arxiv.org/abs/2103.00020) [](https://github.com/openai/CLIP)
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
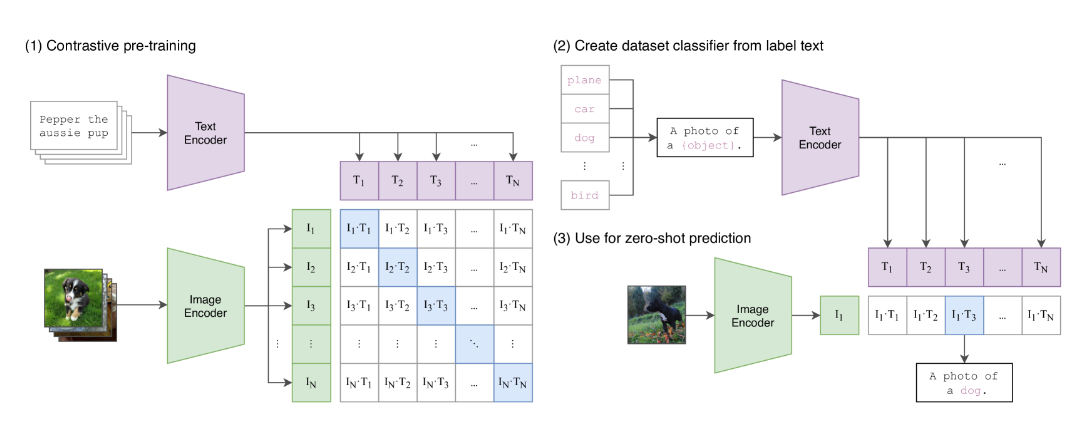
ℹ️ More Information
**CLIP**: model represents a groundbreaking approach in the field of machine learning, aiming to bridge the gap between visual and textual information through natural language supervision. Its architecture is designed to understand and predict **the most fitting captions for given images**, a methodology that stems from its training on a vast dataset of 400 million image-text pairs. This extensive training enables CLIP to learn state-of-the-art (SOTA) image representations and apply this knowledge to a wide range of downstream tasks without the need for task-specific training data, facilitating zero-shot transfer capabilities. At the core of CLIP are two primary components: **an image encoder** and **a text encoder**. These encoders are trained using a contrastive learning approach, optimizing for a contrastive objective that seeks to maximize the cosine similarity between correct image-text pairs while minimizing it for incorrect ones. This process is achieved through **a symmetric cross-entropy loss over the similarity scores between the embeddings of images and texts**, enabling the model to effectively link visual concepts with their linguistic descriptions. The model's ability to generalize across various tasks is further enhanced by its training methodology and the specific datasets it utilizes. By covering a broad spectrum of visual concepts and leveraging natural language for supervision, CLIP is adept at learning representations that are highly transferable to new tasks and domains. The custom dataset of 400 million image-text pairs, curated from the internet, plays a pivotal role in this process, providing the diverse and extensive visual and textual information necessary for the model to learn effectively. Through these innovations, CLIP sets a new standard for learning transferable visual models, showcasing the power of natural language in facilitating robust and versatile visual understanding.
## **MetaCLIP: Demystifying CLIP Data**
MetaCLIP refines the data curation process for training vision-language models by employing algorithms that leverage CLIP-derived metadata to create a balanced and high-quality dataset from vast sources like CommonCrawl, resulting in improved performance and diversity compared to models trained on CLIP's original dataset.
[](https://arxiv.org/abs/2309.16671) [](https://github.com/facebookresearch/MetaCLIP)
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, Christoph Feichtenhofer

ℹ️ More Information
**MetaCLIP**: Represents an innovative approach in the realm of data curation for machine learning, specifically targeting the **enhancement of training datasets** through metadata utilization derived from CLIP's concepts. This model is designed to sift through extensive raw data pools, such as the CommonCrawl dataset, to curate a high-quality, balanced subset that significantly betters the diversity and performance metrics of the data used for training machine learning models. The essence of MetaCLIP lies in its unique architecture that incorporates data curation algorithms, which are adept at leveraging metadata for the purpose of balancing and enriching the training dataset both in terms of quality and diversity. The architecture of MetaCLIP is structured around these **data curation algorithms**, which play a pivotal role in the framework by identifying and assembling a balanced and high-quality dataset from a vast collection of 400 million image-text pairs initially sourced from CommonCrawl. This process is instrumental in MetaCLIP's ability to demonstrate superior performance on various benchmarks, including zero-shot ImageNet classification, when compared to datasets curated using CLIP's original methodologies. The training methods employed by MetaCLIP, therefore, are not just about processing and learning from data but also about intelligently selecting the data that is most beneficial for the training process, ensuring that the model is trained on a dataset that is representative, diverse, and of high quality. The purpose behind employing datasets like CommonCrawl within the MetaCLIP framework is to address and overcome the limitations observed in CLIP's original dataset. By curating a balanced and high-quality dataset of 400 million image-text pairs, MetaCLIP sets a new precedent in the field of machine learning data curation. This strategic selection and enhancement of the training dataset enable MetaCLIP to significantly improve performance on standard benchmarks compared to its predecessor, highlighting the importance of dataset quality and diversity in achieving high performance in machine learning tasks. Through its innovative approach to data curation, MetaCLIP offers a promising avenue for enhancing the capabilities of machine learning models, particularly in applications requiring robust image-text understanding and classification.
## **Alpha-CLIP: A CLIP Model Focusing on Wherever You Want**
Alpha-CLIP builds upon the CLIP model by incorporating region awareness through the addition of an alpha channel to the image encoder, trained on millions of RGBA region-text pairs, enabling precise control over image emphasis and enhancing performance across various tasks requiring detailed spatial understanding.
[](https://arxiv.org/abs/2312.03818) [](https://github.com/SunzeY/AlphaCLIP)
Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, Jiaqi Wang
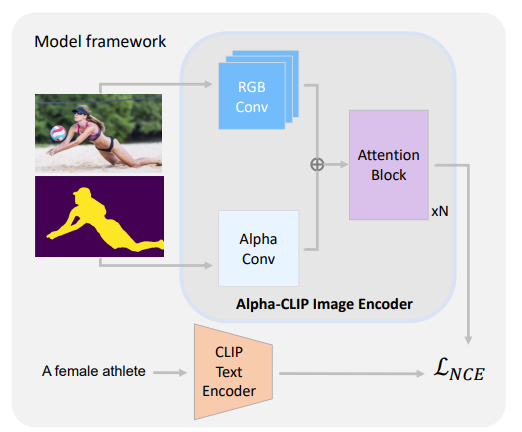
ℹ️ More Information
**Alpha-CLIP**: Introduces a significant enhancement to the original CLIP model, incorporating region awareness to its repertoire of capabilities. This model is fine-tuned on millions of RGBA region-text pairs, enabling it to maintain CLIP's visual recognition prowess while offering precise control over the emphasis of image content. By integrating an additional **alpha channel into the CLIP image encoder**, Alpha-CLIP allows for detailed segmentation and region-specific processing without modifying the foundational CLIP weights, thus facilitating a nuanced approach to image understanding that respects the spatial dynamics of visual data.
The training of Alpha-CLIP leverages a novel data generation pipeline designed to produce a vast array of RGBA-region text pairs. This process involves the creation of natural images equipped with foreground alpha channels and their corresponding referring expressions for specific regions. Such a methodology not only enables the fine-tuning of the model with an additional alpha channel input but also underpins its ability to perform with heightened specificity across various tasks. These tasks range from image recognition to multimodal large language models, and extend into both 2D and 3D generation domains, showcasing Alpha-CLIP's versatility and broad applicability. Datasets like LAION-400M, LAION-5B, and GRIT play a crucial role in training Alpha-CLIP, providing a wide spectrum of images for initial training and fine-grained mask-level labels for enhancing local perception capabilities. This strategic choice of datasets ensures that Alpha-CLIP is not only well-equipped for general visual recognition tasks but also capable of nuanced, region-specific processing and understanding, setting a new standard for models at the intersection of language and vision.
## **GLIP: Grounded Language-Image Pre-training**
GLIP revolutionizes language-image pre-training by unifying object detection and phrase grounding, allowing it to understand and execute tasks requiring object-level precision and language awareness through a deep integration of visual and textual information during training.
[](https://arxiv.org/abs/2112.03857) [](https://github.com/microsoft/GLIP)
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, Jianfeng Gao

ℹ️ More Information
**GLIP**: A novel approach that innovatively unifies the tasks of object detection and phrase grounding by redefining object detection as a phrase grounding challenge. This strategic reformation allows the model to exploit extensive image-text paired datasets for pre-training, equipping it with the capability to comprehend and execute tasks that require object-level precision, language awareness, and semantically rich visual representations. At its core, GLIP's architecture is designed to deeply integrate visual and textual information, enhancing its understanding of complex visual scenes in conjunction with textual prompts. The architecture of GLIP is composed of several critical components, including a visual encoder that can either be a Convolutional Neural Network (CNN) or a Transformer, tasked with extracting features from regions or bounding boxes within images. It also includes a language encoder dedicated to processing text prompts and prediction heads (box classifier and box regressor) that are trained using **classification** and **localization loss**. A distinctive feature of GLIP is its method of deep fusion between image and text, specifically in the latter stages of encoding, which merges visual and textual information more comprehensively than traditional methods. GLIP's training methodology is as innovative as its architecture, employing a unified formulation that amalgamates detection and grounding tasks into a singular workflow. This model is trained end-to-end, optimizing losses defined for **both detection** (focusing on localization and classification) and **grounding** (centering on alignment scores between image regions and corresponding words in the prompt). Such deep integration of visual and language features during training is pivotal, facilitating the model's ability to learn effectively from paired image-text data. The datasets utilized for training GLIP, including COCO, OpenImages, Objects365, Visual Genome, Flickr30k-entities, LVIS, and PhraseCut, are meticulously selected to cover a wide array of object classes and scenarios, each serving a unique purpose from object detection and phrase grounding to instance segmentation and referring expression segmentation. Through this comprehensive training, GLIP sets a new precedent in the realm of language-image pre-training, demonstrating advanced capabilities in interpreting and interacting with both visual and textual data.
## **ImageBind: One Embedding Space To Bind Them All**
ImageBind revolutionizes multimodal learning by creating a single, joint embedding space that integrates six modalities – images, text, audio, depth, thermal, and IMU data – through image-paired data as a central binding agent, allowing for zero-shot classification and retrieval across diverse data types.
[](https://arxiv.org/abs/2305.05665) [](https://github.com/facebookresearch/imagebind)
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, Ishan Misra

ℹ️ More Information
**ImageBind**: Introduces an innovative approach to multimodal learning by creating **a joint embedding space** that encompasses six different modalities: **images, text, audio, depth, thermal, and IMU (Inertial Measurement Unit)** data. This model uniquely employs image-paired data as a central binding agent, enabling it to leverage the capabilities of large-scale vision-language models to extend zero-shot capabilities to new, previously unlinked modalities. By doing so, ImageBind not only facilitates a deeper integration of diverse data types but also opens up new avenues for zero-shot classification and retrieval across a wide range of applications. At the heart of ImageBind's architecture lies a transformer-based design, adapted for each specific modality to ensure optimal processing and representation. For instance, it utilizes a Vision Transformer for image data, with each modality encoder being augmented by **modality-specific linear projection heads**. These adaptations are crucial for maintaining a uniform embedding size across the disparate data types, ensuring that the model can effectively learn from and link together the various modalities. This uniformity is key to ImageBind's ability to create a cohesive and comprehensive embedding space that captures the nuances of each data type. The training methodology behind ImageBind is particularly noteworthy. It employs contrastive learning, utilizing both web-scale image-text data and naturally occurring paired data from various modalities, such as video-audio and image-depth pairs. This strategy allows the model to learn a single joint embedding space without requiring all modalities to co-occur, a significant advantage that enhances its flexibility and applicability. The use of datasets like Audioset, SUN RGB-D, LLVIP, and Ego4D, which provide naturally paired data across the model's target modalities, is critical to this process. These datasets enable ImageBind to achieve emergent zero-shot classification and retrieval performance on tasks tailored to each modality, showcasing the model's ability to seamlessly navigate and leverage the complex interplay between different forms of data.
## **SigLIP: Sigmoid Loss for Language Image Pre-Training**
SigLIP introduces a simple pairwise sigmoid loss for language-image pre-training, allowing for scalable training with large batch sizes without compromising performance, enabling efficient alignment between image and text representations.
[](https://arxiv.org/abs/2303.15343)
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer

ℹ️ More Information
**SigLIP**: A novel approach to language-image pre-training by proposing **a simple pairwise sigmoid loss**. This method contrasts with standard contrastive learning that utilizes softmax normalization, as it operates directly on image-text pairs without necessitating a global view of pairwise similarities for normalization. The primary advantage of this approach is its scalability, allowing for the use of larger batch sizes without compromising performance. The architecture leverages a vision transformer for image processing and a conventional transformer for text, with the sigmoid loss facilitating independent processing of image-text pairs. This design enables more efficient training dynamics, particularly in the context of large batch sizes, by examining the effects of varying the negative to positive ratio and the selection of example pairs. Training methodologies focus on exploiting large batch sizes, delving into the dynamics of how batch size variations influence model performance. The introduction of sigmoid loss is pivotal, enabling the model to train effectively with these large batches by investigating the relationship between the ratio of negative to positive examples and the optimization of example pair selection. The use of the LiT image-text dataset and the WebLI dataset is integral to the model's training, aiming to achieve aligned representational spaces between images and texts. These datasets are chosen for their utility in assessing zero-shot transfer capabilities, as well as in exploring the scalability and efficiency of the model's sigmoid loss-based training. In essence, SigLIP marks a significant stride in language-image pre-training through its innovative use of sigmoid loss, enhancing scalability and training efficiency. This approach not only simplifies the training process by eliminating the need for global normalization but also showcases the model's adaptability to large-scale data handling. The strategic selection of datasets further underscores the model's capability to forge aligned representational spaces, paving the way for advanced zero-shot learning and efficient multimodal integration.
## **ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale**
The Vision Transformer (ViT) revolutionizes image recognition by applying the Transformer architecture to images, processing them as a sequence of fixed-size patches, thereby demonstrating that image recognition can benefit from the power of transformers, surpassing traditional convolutional neural network (CNN) approaches with the aid of large-scale training datasets.
[](https://arxiv.org/abs/2010.11929v2) [](https://github.com/google-research/vision_transformer)
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby

ℹ️ More Information
**The Vision Transformer (ViT)**: A paradigm shift in image recognition by applying the transformer architecture, predominantly used in natural language processing, directly to images. It innovatively processes images as **a sequence of fixed-size patches**, akin to how tokens are treated in **text applications**. This approach is facilitated through minimal modifications to the standard transformer components, emphasizing the model's adaptability to visual tasks without relying on the convolutional neural networks' (CNNs) inductive biases. ViT's architecture is distinguished by its use of linear embedding for **image patches** and **position embeddings**, which are crucial for maintaining the spatial hierarchy of image data. The core of ViT is a standard Transformer encoder that includes multiheaded self-attention (MSA) and multilayer perceptron (MLP) blocks, complemented by layer normalization and residual connections, underscoring its efficiency and robustness in handling visual data. Training methodologies for ViT are characterized by its scalability and the significant impact of dataset size on its performance. Initially, ViT exhibits modest accuracies without strong regularization techniques. However, its performance escalates with the scale of training, showcasing its potential to outperform traditional CNN approaches through extensive pre-training on large datasets. This process highlights the critical role of dataset selection in ViT's training regimen. It is fine-tuned on smaller datasets following a comprehensive pre-training phase that leverages large datasets like ImageNet-21k and JFT-300M to enhance model generalization and performance across a wide range of tasks. The datasets employed, including ImageNet, CIFAR-100, VTAB, ImageNet-21k, and JFT-300M, serve dual purposes: benchmarking the model's image classification capabilities and evaluating its transferability to diverse tasks with limited data, thereby establishing ViT's versatility and effectiveness in advancing image recognition tasks.
## Important References
- [Guide to Vision-Language Models (VLMs) by Görkem Polat](https://encord.com/blog/vision-language-models-guide/)
- [VLM Primer by Aman Chadha](https://aman.ai/primers/ai/VLM/#google_vignette)
- [Generalized Visual Language Models by Lilian Weng](https://lilianweng.github.io/posts/2022-06-09-vlm/)