https://github.com/kashiwabyte/awesome-llm-computational-argumentation
The Hub of Computational Argumentation in the Era of LLM
https://github.com/kashiwabyte/awesome-llm-computational-argumentation
List: awesome-llm-computational-argumentation
Last synced: 3 months ago
JSON representation
The Hub of Computational Argumentation in the Era of LLM
- Host: GitHub
- URL: https://github.com/kashiwabyte/awesome-llm-computational-argumentation
- Owner: KashiwaByte
- Created: 2024-08-15T02:13:31.000Z (10 months ago)
- Default Branch: main
- Last Pushed: 2024-08-28T14:28:11.000Z (10 months ago)
- Last Synced: 2025-03-10T20:51:49.731Z (3 months ago)
- Homepage:
- Size: 8.79 KB
- Stars: 3
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Contributing: Contributing.md
Awesome Lists containing this project
- ultimate-awesome - awesome-llm-computational-argumentation - The Hub of Computational Argumentation in the Era of LLM. (Other Lists / Julia Lists)
README
# Awesome-LLM-Computational-Argumentation
The Hub of Computational Argumentation in the Era of LLM, where you can find surveys, papers, datasets, benchmarks, and evaluations of commonly used LLMs on computational Argumentation tasks.
## Table of Contents
- [Awesome-LLM-Computational-Argumentation](#awesome-llm-computational-argumentation)
- [Table of Contents](#table-of-contents)
- [Evaluation](#evaluation)
- [Benchmark \& datasets](#benchmark--datasets)
- [Survey](#survey)
- [Papers](#papers)
- [Argument Mining](#argument-mining)
- [Argument Generation](#argument-generation)
- [Quality Assessment](#quality-assessment)
- [Debate For LLM](#debate-for-llm)
- [Contributing](#contributing)
## Evaluation
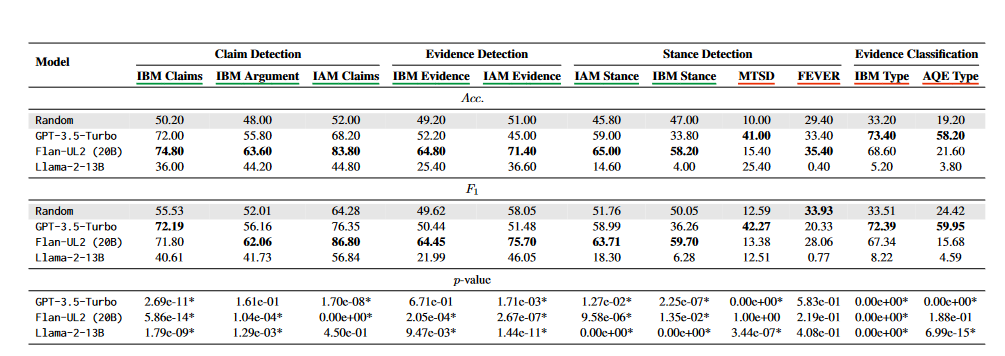
## Benchmark & datasets
| Date | Paper | Publication |
| :-----: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :---------: |
|2024-08|[DebateQA: Evaluating Question Answering on Debatable Knowledge](https://arxiv.org/abs/2408.01419)|Arxiv
|2024-06|[Assessing Good, Bad and Ugly Arguments Generated by ChatGPT: a New Dataset, its Methodology and Associated Tasks](https://arxiv.org/abs/2406.15130)|EPIA 2023
|2024-06|[Which Side Are You On? A Multi-task Dataset for End-to-End Argument Summarisation and Evaluation](https://arxiv.org/abs/2406.03151)|ACL 2024
|2024-06|[OpenDebateEvidence: A Massive-Scale Argument Mining and Summarization Dataset](https://arxiv.org/abs/2406.14657)|ACL 2024
|2024-02|[Can LLMs Speak For Diverse People? Tuning LLMs via Debate to Generate Controllable Controversial Statements](https://arxiv.org/abs/2402.10614)| ACL 2024
|2023-12|[FREDSum: A Dialogue Summarization Corpus for French Political Debates](https://arxiv.org/abs/2312.04843)|EMNLP2023
|2023-11|[Automatic Analysis of Substantiation in Scientific Peer Reviews](https://arxiv.org/abs/2311.11967)|EMNLP 2023
|2022-06|[QT30: A Corpus of Argument and Conflict in Broadcast Debate](https://aclanthology.org/2022.lrec-1.352/)|ACL 2022
|2022-04|[Single-Turn Debate Does Not Help Humans Answer Hard Reading-Comprehension Questions](https://arxiv.org/abs/2204.05212)|ACL 2022
| 2022-03| [IAM: A Comprehensive and Large-Scale Dataset for Integrated Argument Mining Tasks](https://arxiv.org/abs/2203.12257)|ACL
|2021-02|[SummEval: Re-evaluating Summarization Evaluation](https://arxiv.org/abs/2007.12626)|tacl
|2021-01|[Learning From Revisions: Quality Assessment of Claims in Argumentation at Scale](https://arxiv.org/abs/2101.10250)|EACL 2021
|2020-12|[Transformer-Based Argument Mining for Healthcare Applications](https://ecai2020.eu/papers/1470_paper.pdf)|ECAI 2020
|2020-10|[Detecting Attackable Sentences in Arguments](https://arxiv.org/abs/2010.02660)|EMNLP 2020
|2020-10|[Unsupervised Expressive Rules Provide Explainability and Assist Human Experts Grasping New Domains](https://arxiv.org/abs/2010.09459)|EMNLP
|2020-06|[Rhetoric, Logic, and Dialectic: Advancing Theory-based Argument Quality Assessment in Natural Language Processing](https://arxiv.org/abs/2006.00843)|COLING
|2020-05|[USR: An Unsupervised and Reference Free Evaluation Metric for Dialog Generation](https://arxiv.org/abs/2005.00456)|ACL 2020
|2019-09|[A Dataset of General-Purpose Rebuttal](https://arxiv.org/abs/1909.00393)|EMNLP 2019
|2019-06|[Exploring the Role of Prior Beliefs for Argument Persuasion](https://arxiv.org/abs/1906.11301)|ACL 2018
|2019-06 |[A Corpus for Modeling User and Language Effects in Argumentation on Online Debating](https://arxiv.org/abs/1906.11310)|ACL
|2018-02|[Cross-topic Argument Mining from Heterogeneous Sources Using Attention-based Neural Networks](https://arxiv.org/abs/1802.05758)|EMNLP
|2017-04|[Recognizing Insufficiently Supported Arguments in Argumentative Essays](https://aclanthology.org/E17-1092/)|EACL
|2016-04|[Parsing Argumentation Structures in Persuasive Essays](https://arxiv.org/abs/1604.07370)|Computational Linguistics
## Survey
| Date | Paper | Publication |
| :-----: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :---------: |
| 2023-11 | [Exploring the Potential of Large Language Models in Computational Argumentation](https://arxiv.org/abs/2311.09022) | ACL
## Papers
### Argument Mining
| Date | Paper | Publication |
| :-----: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :---------: |
|2024-07|[Argument Mining in Data Scarce Settings: Cross-lingual Transfer and Few-shot Techniques](https://arxiv.org/abs/2407.03748)|ACL 2024
|2024-06|[In-Context Learning and Fine-Tuning GPT for Argument Mining](https://arxiv.org/abs/2406.06699)|Arxiv
|2024-05|[WIBA: What Is Being Argued? A Comprehensive Approach to Argument Mining](https://arxiv.org/abs/2405.00828)|ASONAM
|2024-05|[DMON: A Simple yet Effective Approach for Argument Structure Learning](https://arxiv.org/abs/2405.01216)| COLING 2024
|2024-04|[Exploring Key Point Analysis with Pairwise Generation and Graph Partitioning](https://arxiv.org/abs/2404.11384)|NAACL 2024
|2024-04|[A School Student Essay Corpus for Analyzing Interactions of Argumentative Structure and Quality](https://arxiv.org/abs/2404.02529)|NAACL 2024
|2024-04|[TACO -- Twitter Arguments from COnversations](https://arxiv.org/abs/2404.00406)|Arxiv
|2024-02|[Can Large Language Models perform Relation-based Argument Mining?](https://arxiv.org/abs/2402.11243)|ACL 2024
|2024-01|[End-to-End Argument Mining over Varying Rhetorical Structures](https://arxiv.org/abs/2401.11218)|Arxiv
|2023-12|[Hi-ArG: Exploring the Integration of Hierarchical Argumentation Graphs in Language Pretraining](https://arxiv.org/abs/2312.00874)|EMNLP 2023
|2023-10|[Overview of ImageArg-2023: The First Shared Task in Multimodal Argument Mining](https://arxiv.org/abs/2310.12172)|EMNLP
|2023-10|[TILFA: A Unified Framework for Text, Image, and Layout Fusion in Argument Mining](https://arxiv.org/abs/2310.05210)|EMNLP 2023
|2023-06|[Detecting Check-Worthy Claims in Political Debates, Speeches, and Interviews Using Audio Data](https://arxiv.org/abs/2306.05535)|ICASSP
|2023-05|[AQE: Argument Quadruplet Extraction via a Quad-Tagging Augmented Generative Approach](https://arxiv.org/abs/2305.19902)|ACL 2023
|2023-02|[VivesDebate-Speech: A Corpus of Spoken Argumentation to Leverage Audio Features for Argument Mining](https://arxiv.org/abs/2302.12584)|EMNLP 2023
|2022-09|[Perturbations and Subpopulations for Testing Robustness in Token-Based Argument Unit Recognition](https://arxiv.org/abs/2209.14780)|COLING 2022
|2022-09 |[ImageArg: A Multi-modal Tweet Dataset for Image Persuasiveness Mining](https://arxiv.org/abs/2209.06416)|COLING
|2022-05|[A Holistic Framework for Analyzing the COVID-19 Vaccine Debate](https://arxiv.org/abs/2205.01817)| NAACL 2022
|2022-04|[Echoes through Time: Evolution of the Italian COVID-19 Vaccination Debate](https://arxiv.org/abs/2204.12943)|AAAI
|2022-03 |[Can Unsupervised Knowledge Transfer from Social Discussions Help Argument Mining?](https://arxiv.org/abs/2203.12881)|ACL 2022
### Argument Generation
| Date | Paper | Publication |
| :-----: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :---------: |
| 2024-06 | [Persuasiveness of Generated Free-Text Rationales in Subjective Decisions: A Case Study on Pairwise Argument Ranking](https://arxiv.org/abs/2406.13905) | Arxiv
|2023-12|[Argue with Me Tersely: Towards Sentence-Level Counter-Argument Generation](https://arxiv.org/abs/2312.13608)|EMNLP 2023
|2023-10|[From Values to Opinions: Predicting Human Behaviors and Stances Using Value-Injected Large Language Models](https://arxiv.org/abs/2310.17857)| EMNLP 2023
|2023-09|[Claim Optimization in Computational Argumentation](https://arxiv.org/abs/2212.08913)| INLG 2023
|2023-07|[DebateKG: Automatic Policy Debate Case Creation with Semantic Knowledge Graphs](https://arxiv.org/abs/2307.04090)|EMNLP 2023
|2023-01|[Conclusion-based Counter-Argument Generation](https://arxiv.org/abs/2301.09911)|eacl-23
|2022-10|[MOCHA: A Multi-Task Training Approach for Coherent Text Generation from Cognitive Perspective](https://arxiv.org/abs/2210.14650)|EMNLP 2022
|2022-05 |[RSTGen: Imbuing Fine-Grained Interpretable Control into Long-FormText Generators](https://arxiv.org/abs/2205.12590) |NAACL 2022
|2022-03|[The Moral Debater: A Study on the Computational Generation of Morally Framed Arguments](https://arxiv.org/abs/2203.14563)| ACL 2022
### Quality Assessment
| Date | Paper | Publication |
| :-----: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :---------: |
|2024-06|[Assessing Good, Bad and Ugly Arguments Generated by ChatGPT: a New Dataset, its Methodology and Associated Tasks](https://arxiv.org/abs/2406.15130)|EPIA 2023
| 2024-04 | [Can Language Models Recognize Convincing Arguments?](https://arxiv.org/abs/2404.00750) | Arxiv
|2024-03|[Argument Quality Assessment in the Age of Instruction-Following Large Language Models](https://arxiv.org/abs/2403.16084)|COLING 2024
|2023-11|[Automatic Analysis of Substantiation in Scientific Peer Reviews](https://arxiv.org/abs/2311.11967)|EMNLP 2023
|2023-05|[Contextualizing Argument Quality Assessment with Relevant Knowledge](https://arxiv.org/abs/2305.12280)|NAACL 2024
|2023-01|[Conclusion-based Counter-Argument Generation](https://arxiv.org/abs/2301.09911)|eacl-23
|2022-12|[Claim Optimization in Computational Argumentation](https://arxiv.org/abs/2212.08913)| INLG 2023
|2022-03|[Automatic Debate Evaluation with Argumentation Semantics and Natural Language Argument Graph Networks](https://arxiv.org/abs/2203.14647)|EMNLP 2023
|2021-10|[Assessing the Sufficiency of Arguments through Conclusion Generation](https://arxiv.org/abs/2110.13495)|EMNLP 2021
|2020-12|[Rhetoric, Logic, and Dialectic: Advancing Theory-based Argument Quality Assessment in Natural Language Processing](https://arxiv.org/abs/2006.00843)|COLING 20
|2020-10|[Exploring the Role of Argument Structure in Online Debate Persuasion](https://arxiv.org/abs/2010.03538)|EMNLP 2020
|2019-09|[A Large-scale Dataset for Argument Quality Ranking: Construction and Analysis](https://arxiv.org/abs/1911.11408)| AAAI 2020
|2019-09|[Automatic Argument Quality Assessment -- New Datasets and Methods](https://arxiv.org/abs/1909.01007)|EMNLP 2019
### Debate For LLM
| Date | Paper | Publication |
| :-----: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :---------: |
|2024-08|[Can LLMs Beat Humans in Debating? A Dynamic Multi-agent Framework for Competitive Debate](https://arxiv.org/abs/2408.04472)|Arxiv
|2024-06|[An Empirical Analysis on Large Language Models in Debate Evaluation](https://arxiv.org/abs/2406.00050)|ACL 2024
| 2024-05 |[DEBATE: Devil's Advocate-Based Assessment and Text Evaluation](https://arxiv.org/abs/2405.09935)|Arxiv
|2024-03|[Debatrix: Multi-dimensional Debate Judge with Iterative Chronological Analysis Based on LLM](https://arxiv.org/abs/2403.08010)|ACL 2024
|2024-03|[A Picture Is Worth a Graph: A Blueprint Debate Paradigm for Multimodal Reasoning](https://arxiv.org/abs/2403.14972)|ACM Multimedia
| 2024-02 | [Debating with More Persuasive LLMs Leads to More Truthful Answers](https://arxiv.org/abs/2402.06782) | ICML 2024
|2024-02|[Can LLMs Speak For Diverse People? Tuning LLMs via Debate to Generate Controllable Controversial Statements](https://arxiv.org/abs/2402.10614)| ACL 2024
|2024-01|[Can Large Language Models be Trusted for Evaluation? Scalable Meta-Evaluation of LLMs as Evaluators via Agent Debate](https://arxiv.org/abs/2401.16788)|Arxiv
|2024-01|[Combating Adversarial Attacks with Multi-Agent Debate](https://arxiv.org/abs/2401.05998)|Arxiv
|2024-01|[Towards Explainable Harmful Meme Detection through Multimodal Debate between Large Language Models](https://arxiv.org/abs/2401.13298)|ACM Web
|2023-12|[Learning to Break: Knowledge-Enhanced Reasoning in Multi-Agent Debate System](https://github.com/FutureForMe/MADKE)|Arxiv
|2023-12|[Recourse under Model Multiplicity via Argumentative Ensembling (Technical Report)](https://arxiv.org/abs/2312.15097)|AAMAS 2024
|2023-11|[Should we be going MAD? A Look at Multi-Agent Debate Strategies for LLMs](https://arxiv.org/abs/2311.17371)|Arixv
|2023-11|[Debate Helps Supervise Unreliable Experts](https://arxiv.org/abs/2311.08702)|Arxiv
|2023-11|[Scalable AI Safety via Doubly-Efficient Debate](https://arxiv.org/abs/2311.14125)|Arxiv
|2023-10|[From Values to Opinions: Predicting Human Behaviors and Stances Using Value-Injected Large Language Models](https://arxiv.org/abs/2310.17857)|EMNLP 2023
|2023-10|[Let Models Speak Ciphers: Multiagent Debate through Embeddings](https://arxiv.org/abs/2310.06272)|ICLR 2024
|2023-08|[ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate](https://arxiv.org/abs/2308.07201)| ICLR 2024
|2023-05|[Can ChatGPT Defend its Belief in Truth? Evaluating LLM Reasoning via Debate](https://arxiv.org/abs/2305.13160)|EMNLP 2023
|2023-05|[Improving Factuality and Reasoning in Language Models through Multiagent Debate](https://arxiv.org/abs/2305.14325)|ICML 2024
|2023-05|[Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate](https://arxiv.org/abs/2305.19118)|Arxiv
|2023-05|[Examining Inter-Consistency of Large Language Models Collaboration: An In-depth Analysis via Debate](https://arxiv.org/abs/2305.11595)| EMNLP 2023
|2022-10|[The Debate Over Understanding in AI's Large Language Models](https://arxiv.org/abs/2210.13966)|Arixv
|2022-03|[The Moral Debater: A Study on the Computational Generation of Morally Framed Arguments](https://arxiv.org/abs/2203.14563)|ACL 2022
|2021-10|[Project Debater APIs: Decomposing the AI Grand Challenge](https://arxiv.org/abs/2110.01029)|EMNLP 2021
## Contributing