https://github.com/malteos/awesome-document-similarity
A curated list of resources on document similarity measures (papers, tutorials, code, ...)
https://github.com/malteos/awesome-document-similarity
List: awesome-document-similarity
Last synced: 4 months ago
JSON representation
A curated list of resources on document similarity measures (papers, tutorials, code, ...)
- Host: GitHub
- URL: https://github.com/malteos/awesome-document-similarity
- Owner: malteos
- License: mit
- Created: 2019-10-04T08:44:11.000Z (almost 7 years ago)
- Default Branch: master
- Last Pushed: 2022-07-13T08:17:04.000Z (about 4 years ago)
- Last Synced: 2026-03-01T19:30:38.847Z (5 months ago)
- Size: 65.4 KB
- Stars: 256
- Watchers: 5
- Forks: 24
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- ultimate-awesome - awesome-document-similarity - A curated list of resources on document similarity measures (papers, tutorials, code, .). (Other Lists / TeX Lists)
README
# Awesome Document Similarity Measures

A curated list of resources, such as papers, tutorials, code, etc., on the topic of document similarity measures.
**Please feel free to create a pull request if you would like to add other awesome papers.**
## Motivation
The goal of this repository is to provide a comprehensive overview for students and reseachers.
Document similarity measures are basis the several downstream applications in the area of natural language processing (NLP) and information retrieval (IR).
Among the most common applications are clustering, duplicate or plagirism detection and content-based recommender systems.
We selected the following content while having primarily the recommender systems application in mind.
In particular, we focus on literature recommender systems that need to assess the similarity of long-form and rich content documents. "Long-form" refers to the amount of document content from +100 sentences, whereas rich content means that documents contain aside from text also images, mathematical equations and citations/links.
### Dimensions of Similarity
Documents might be declared as similar, when they, e.g., cover the same topic, use a common set of words or are written in the same font.
In IR the dimension of similarity defines the understanding of similarity.
We distinguish between the following dimensions: lexical, structural and semantic document similarity.
Moreover, similarity is not a binary decision.
In many cases declaring two things as similar or not, is not suitable. Instead, the degree of similarity is measured. Similarity measures express therefore document similarity as normalised scalar score, which is within an interval of zero to one.
The highest degree of similarity is measured as one.
When two objects are dissimilar, the degree of similarity is zero.
- D. Lin, “An Information-Theoretic Definition of Similarity,” Proc. ICML, pp. 296–304, 1998.
### Lexical Similarity
The lexical document similarity of two documents depends on the words, which occur in the document text.
A total overlap between vocabularies would result in a lexical similarity of 1, whereas 0 means both documents share no words.
This dimension of similarity can be calculated by a simple word-to-word comparison.
Methods like stemming or stop word removal increase the effectiveness of lexical similarity.
- J. B. Lovins, “Development of a stemming algorithm,” Mech. Transl. Comput. Linguist., vol. 11, no. June, pp. 22–31, 1968.
- C. Fox, “A stop list for general text,” ACM SIGIR Forum, vol. 24, no. 1–2. pp. 19–21, 1989.
### Strutural Similarity
Whereas lexical similarity focuses on the vocabulary, structural similarity describes the conceptual composition of two documents.
Structural document similarity stretches from graphical components, like text layout, over similarities in the composition of text segments, e.g., paragraphs or sentences that are lexical similar, to the arrangement of citations and hyperlinks.
Structural similarity is mainly used for semi-structured document formats, such as XML or HTML.
A common, yet expensive in computing time, approach is to calculate the minimum cost edit distance between any two document structures.
The cost edit distance is the number of actions that are required to change a document so it is identical to another document
- C. Shin and D. Doermann, “Document image retrieval based on layout structural similarity,” Int. Conf. Image Process. Comput. Vision, Pattern Recognit., pp. 606–612, 2006.
- D. Buttler, “A short survey of document structure similarity algorithms,” Int. Conf. Internet Comput., pp. 3–9, 2004.
### Semantic Similarity
Two documents are considered as semantically similar when they cover related topics or have the same semantic meaning.
A proper determination of the semantic similarity is essential for many IR systems, since in many use cases the users information need is rather about the semantic meaning than the vocabulary or structure of a document.
However, measuring topical relatedness is a complex task.
Therefore, lexical or structural similarity is often used to approximate semantic similarity.
The example below shows that approximating semantic by lexical similarity is not always suitable.
1. Our earth is round.
2. The world is a globe.
Even if both sentences are lexically different, because they have only one out of five words in common, the semantic meaning of the sentences is synonymous.
### Similarity concepts
Text similarity
- [Bär, D., Zesch, T., & Gurevych, I. (2011). A reflective view on text similarity. International Conference Recent Advances in Natural Language Processing, RANLP, (September), 515–520.](https://www.aclweb.org/anthology/R11-1071/)
- [Bär, D., Zesch, T., & Gurevych, I. (2015). Composing Measures for Computing Text Similarity. Technical Report TUD-CS-2015-0017, 1–30.](http://tuprints.ulb.tu-darmstadt.de/4342/)
Psychological
- [Tversky, A. (1977). Features of similarity. Psychological Review, 84(4), 327.](https://doi.org/10.1037/0033-295X.84.4.327)
- [Medin, D. L., Goldstone, R. L., & Gentner, D. (1993). Respects for Similarity. Psychological Review, 100(2), 254–278.](https://doi.org/10.1037/0033-295X.100.2.254)
Narratives
- [Nguyen, D., Trieschnigg, D., & Theune, M. (2014). Using crowdsourcing to investigate perception of narrative similarity. CIKM 2014 - Proceedings of the 2014 ACM International Conference on Information and Knowledge Management, 321–330.](https://doi.org/10.1145/2661829.2661918)
## Document Representations
In order to compute the similarity of two documents, a numeric representation of the documents must be derived.
These representations are usually vectors of real numbers, whereby the vectors can be either sparse or dense.
The terms "sparse" and "dense" refer to the number of zero vs. non-zero elements in the vectors. A sparse vector is one that contains mostly zeros and few non-zero entries. A dense vector contains mostly non-zeros.
[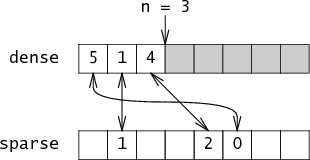](https://research.swtch.com/sparse)
In addition, we distinguish document representations based on the type of data that they rely on, e.g., text, topics, citations.
In the context of machine learning approaches that produce dense vector representations, the process is often refered to as learning of document features.
### Traditional Text-based
- Bag-of-Words
- VSM
- TF-IDF (IDF variants, BM25,)
### Word-level
- Word2Vec. [Paper](https://arxiv.org/pdf/1301.3781.pdf%5D)
- Glove. [Paper](https://www.aclweb.org/anthology/D14-1162). [Code](https://nlpython.com/implementing-glove-model-with-pytorch/)
- FastText [Paper](https://arxiv.org/pdf/1607.01759.pdf). [Code](https://fasttext.cc/)
### Word Context
- Contextualized Word Vectors (CoVe). [Paper](http://papers.nips.cc/paper/7209-learned-in-translation-contextualized-word-vectors.pdf), [Code](https://github.com/salesforce/cove)
- Embeddings from Language Models (ELMo). [Paper](https://arxiv.org/pdf/1802.05365.pdf)
- Contextual String Embeddings (Zalando Flair). [Paper](http://aclweb.org/anthology/C18-1139)
### From word to sentence level
- Average
- Weighted Average
- Smooth Inverse Frequency. [A Simple but Tough-to-Beat Baseline for Sentence Embeddings](https://openreview.net/pdf?id=SyK00v5xx)
### Sentence-level
- Skip-thoughts. [Paper](https://arxiv.org/pdf/1506.06726.pdf). [Code](https://github.com/ryankiros/skip-thoughts)
- Quick-Thoughts. [Paper](https://arxiv.org/pdf/1803.02893.pdf)
- Universal Sentence Encoder. [Paper](https://arxiv.org/abs/1803.11175)
> We find that using a similarity based on angular distance performs better on average than raw cosine similarity.
- InferSent. [Paper](https://arxiv.org/abs/1705.02364) [Code](https://github.com/facebookresearch/InferSent)
InferSent is a sentence embeddings method that provides semantic representations for English sentences. It is trained on natural language inference data and generalizes well to many different tasks.
- ERCNN: Enhanced Recurrent Convolutional Neural Networks for Learning Sentence Similarity [Paper](https://link.springer.com/chapter/10.1007/978-3-030-32381-3_10). [Code](https://github.com/daviddwlee84/SentenceSimilarity) [Code II](https://github.com/guqian/eRCNN)
- DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations [Paper](https://arxiv.org/abs/2006.03659) [Code](https://github.com/JohnGiorgi/DeCLUTR)
### BERT and other Transformer Language Models
- BERT [Paper](https://arxiv.org/abs/1810.04805)
- GPT [Paper](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)
- Generative Pre-Training-2 (GPT-2) [Paper](https://www.techbooky.com/wp-content/uploads/2019/02/Better-Language-Models-and-Their-Implications.pdf)
- Universal Language Model Fine-tuning (ULMFiT) [Paper](https://arxiv.org/pdf/1801.06146.pdf)
- XLNet
- Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. [Paper](https://arxiv.org/abs/1901.02860) [Code](https://github.com/kimiyoung/transformer-xl)
- [Sentence Transformers](https://github.com/UKPLab/sentence-transformers)
- [Li, B., Zhou, H., He, J., Wang, M., Yang, Y., & Li, L. (2020). On the Sentence Embeddings from Pre-trained Language Models. EMNLP 2020.](http://arxiv.org/abs/2011.05864) ([Code](https://github.com/bohanli/BERT-flow))
BERT pooling strategies:
> Bert is amazing at encoding texts, just pool the contextualized embeddings. If not pre-training, use the 2nd to last layer as it usually gets better results (see the research in the bert-as-a-service github repo). [Reddit](https://www.reddit.com/r/MachineLearning/comments/dkjlq2/d_im_looking_for_successfailure_stories_applying/)
- https://github.com/hanxiao/bert-as-service#q-what-are-the-available-pooling-strategies
Better BERT embeddings (fix anisotropic problem):
- [SimCSE: Simple Contrastive Learning of Sentence Embeddings](https://arxiv.org/abs/2104.08821)
- [WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach](https://arxiv.org/abs/2104.01767)
Overcoming BERT's 512 token limit:
> The Transformer self-attention mechanism imposes a quadratic cost with respect to sequence length, limiting its wider application, especially for long text.
- Long-form document classification with BERT. [Blogpost](https://andriymulyar.com/blog/bert-document-classification), [Code](https://github.com/AndriyMulyar/bert_document_classification)
- See ICLR 2020 reviews:
- [BERT-AL: BERT for Arbitrarily Long Document Understanding](https://openreview.net/forum?id=SklnVAEFDB)
- [Blockwise Self-Attention for Long Document Understanding](https://openreview.net/forum?id=H1gpET4YDB)
- [Easy-to-use interface to fine-tuned BERT models for computing semantic similarity](https://github.com/AndriyMulyar/semantic-text-similarity)
- Ye, Z. et al. 2019. BP-Transformer: Modelling Long-Range Context via Binary Partitioning. (2019). [Paper](https://arxiv.org/pdf/1911.04070.pdf) [Code](https://github.com/yzh119/BPT)
- Longformer: The Long-Document Transformer [Code](https://github.com/allenai/longformer) [Paper](https://arxiv.org/abs/2004.05150)
- [Natural Language Recommendations: A novel research paper search engine developed entirely with embedding and transformer models.](https://github.com/Santosh-Gupta/NaturalLanguageRecommendations)
### Document-level
- Doc2Vec [Paper](http://arxiv.org/abs/1507.07998), [Paper 2](http://www.jmlr.org/proceedings/papers/v32/le14.pdf)
- Fuzzy Bag-of-Words Model for Document Representation. [Paper](http://www.msrprojectshyd.com/upload/academicprojects/122b84310415012104464a741f5b6f9116.pdf)
### Topic-oriented
- LSA/LSI
- LDA
- LDA2Vec
### Citations
**Classical**
- Bibliographic coupling. [Martyn, J (1964)](https://doi.org/10.1108%2Feb026352)
- Co-Citation. [Small, Henry (1973)](https://doi.org/10.1002%2Fasi.4630240406)
- Co-Citation Proximity Analysis. [Gipp, Bela; Beel, Joeran (2006)](http://sciplore.org/wp-content/papercite-data/pdf/gipp09a.pdf)
- [Evaluating the CC-IDF citation-weighting scheme: How effectively can ‘Inverse Document Frequency’ (IDF) be applied to references?](https://doi.org/10.9776/17210)
#### Citation Graph Embeddings (Dense representations)
- Cite2vec: Citation-Driven Document Exploration via Word Embeddings. [Paper](http://hdc.cs.arizona.edu/papers/tvcg_cite2vec_2017.pdf)
- hyperdoc2vec: Distributed Representations of Hypertext Documents. [Paper](https://arxiv.org/abs/1805.03793)
- Graph Embedding for Citation Recommendation. [Paper](https://arxiv.org/abs/1812.03835)
General graph embedding methods:
- DeepWalk: Online Learning of Social Representations. [Paper](https://arxiv.org/abs/1403.6652)
- LINE: Large-scale Information Network Embedding. [Paper](https://arxiv.org/abs/1503.03578). [Code](https://github.com/tangjianpku/LINE)
- node2vec. [Paper](https://www.kdd.org/kdd2016/papers/files/rfp0218-groverA.pdf)
- Poincare Embeddings. [Nickel and Kiela (2017)](https://arxiv.org/pdf/1705.08039.pdf) [Gensim Implementation](https://radimrehurek.com/gensim/models/poincare.html#gensim.models.poincare.PoincareKeyedVectors.closest_child)
Various implementations:
- [GraphVite - graph embedding at high speed and large scale](https://github.com/DeepGraphLearning/graphvite)
- [Karate Club is an unsupervised machine learning extension library for NetworkX.](https://github.com/benedekrozemberczki/karateclub)
### Mathematical
### Hybird
- Concatenate Text + Citation Embeddings: [Evaluating Document Representations for Content-based Legal Literature Recommendations](https://arxiv.org/abs/2104.13841)
- Citation Prediction as Training Objective: [SPECTER: Document-level Representation Learning using Citation-informed Transformers](https://arxiv.org/abs/2004.07180)
## Similarity / Distance Measures
Nearest neighbours in embedding space are considered to be similar.
- Euclidean Distance
- Jaccard Similarity
- Jensen-Shannon distance
- Cosine similarity: Cosine-similarity treats all dimensions equally.
- Soft cosine
- Manhatten distance = L1 norm (see also [Manhattan LSTM](http://www.mit.edu/~jonasm/info/MuellerThyagarajan_AAAI16.pdf))
- Edit distance
- Levenshtein Distance
- Word Mover Distance [Paper](http://proceedings.mlr.press/v37/kusnerb15.pdf), [Paper 2](http://arxiv.org/abs/1811.01713)
- Supervised Word Moving Distance (S-WMD)
Implementations
- [textdistance (Python, many algorithms)](https://github.com/life4/textdistance)
### Siamese Networks
Siamese networks [(Bromley, Jane, et al. "Signature verification using a siamese time delay neural network". Advances in neural information processing systems. 1994.)](http://papers.nips.cc/paper/769-signature-verification-using-a-siamese-time-delay-neural-network.pdf) are neural networks containing two or more identical subnetwork components.
> It is important that not only the architecture of the subnetworks is identical, but the weights have to be shared among them as well for the network to be called "siamese". The main idea behind siamese networks is that they can learn useful data descriptors that can be further used to compare between the inputs of the respective subnetworks. Hereby, inputs can be anything from numerical data (in this case the subnetworks are usually formed by fully-connected layers), image data (with CNNs as subnetworks) or even sequential data such as sentences or time signals (with RNNs as subnetworks).
- Siamese LSTM
- SMASH-RNN: [Jiang, J. et al. 2019. Semantic Text Matching for Long-Form Documents. The World Wide Web Conference on - WWW ’19 (New York, New York, USA, 2019), 795–806.](http://dl.acm.org/citation.cfm?doid=3308558.3313707)
- [Liu, B. et al. 2018. Matching Article Pairs with Graphical Decomposition and Convolutions. (Feb. 2018).](http://arxiv.org/abs/1802.07459) [(Code)](https://github.com/BangLiu/ArticlePairMatching)
- [Siamese Neural Networks built upon multihead attention mechanism for text semantic similarity task](https://github.com/tlatkowski/multihead-siamese-nets)
### Text matching
- [Simple and Effective Text Matching with Richer Alignment Features](https://www.aclweb.org/anthology/P19-1465/) [(Code)](https://github.com/alibaba-edu/simple-effective-text-matching-pytorch)
#### Tasks
Binary classifcation
Multi-label classification
#### Loss functions
- (Binary) Cross Entropy
- Mean Square Error
- ...
#### Concatenations
The two Siamese subnetworks encode input data into *u* and *v*. Various approaches exist to then concatenate the encoded input.
- Reimers, N. and Gurevych, I. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. The 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP 2019) (2019).
Variations
| Paper | Concatenation | Comment |
|-------|---------------|---------|
| InferSent | `(u;v;\|u-v\|;u*v)` | no evaluation |
| Sentence-BERT | `(u;v;\|u-v\|)` | The most important component is the element-wise difference `\|u−v\|` ... The element-wise difference measures the distance between the dimensions of the two sentence embeddings, ensuring that similar pairs are closer and dissimilar pairs are. |
| Universal Sentence Encoder | | |
| Pairwise Document Classification | `(u;v;\|u-v\|;u*v)` | Performaning concatenation ([Paper](https://arxiv.org/abs/2003.09881))|
- https://www.reddit.com/r/MachineLearning/comments/e525c6/d_what_beats_concatenation/
- [FiLM](https://arxiv.org/abs/1709.07871)
- [Feature-wise transformations (Distill)](https://distill.pub/2018/feature-wise-transformations/)
#### MLP on top of Siamese sub networks
> A matching network with multi-layer perceptron (MLP) is a standard way to mix multi-dimensions of information [(Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks)](https://doi.org/10.1145/2766462.2767738)
#### Applications
- Mueller, J. and Thyagarajan, A. 2014. Siamese Recurrent Architectures for Learning Sentence Similarity. Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16). 2012 (2014), 1386–1393. DOI:https://doi.org/10.1109/CVPR.2014.180.
## Benchmarks & Datasets
- Large expert-curated database for benchmarking document similarity detection in biomedical literature search. [Paper](https://academic.oup.com/database/article/doi/10.1093/database/baz085/5608006), [Data](https://relishdb.ict.griffith.edu.au/data)
- [SciDocs - The Dataset Evaluation Suite for SPECTER (for classification, citation prediction, user activity, recommendation)](https://github.com/allenai/scidocs)
- [CSFCube -- A Test Collection of Computer Science Research Articles for Faceted Query by Example](https://arxiv.org/abs/2103.12906)
- [STSbenchmark](https://ixa2.si.ehu.eus/stswiki/index.php/STSbenchmark)
- [A Heterogeneous Benchmark for Information Retrieval. Easy to use, evaluate your models across 15+ diverse IR datasets.](https://github.com/UKPLab/beir)
- [A Benchmark Corpus for the Detection of Automatically Generated Text in Academic Publications](https://arxiv.org/abs/2202.02013)
## Performance measures
- [Chen, Mingang, and Pan Liu. "Performance Evaluation of Recommender Systems." International Journal of Performability Engineering 13.8 (2017).](https://pdfs.semanticscholar.org/7d60/90ef21f15f9f1210b6f96664e6a3a0e6b507.pdf)
- [Bobadilla, Jesus, et al. "Reliability quality measures for recommender systems." Information Sciences 442 (2018): 145-157.](https://doi.org/10.1016/j.ins.2018.02.030)
## Surveys
- [Evolution of Semantic Similarity - A Survey](https://dl.acm.org/doi/abs/10.1145/3440755)
- [Text Classification Algorithms: A Survey](https://github.com/kk7nc/Text_Classification) [(Paper)](https://www.mdpi.com/2078-2489/10/4/150)
## Tutorials
- [Training State-of-the-Art Text Embedding & Neural Search Models](https://www.youtube.com/watch?v=XHY-3FzaLGc)
## See also
- [Text Similarities: Estimate the degree of similarity between two texts](https://medium.com/@adriensieg/text-similarities-da019229c894) [Repo](https://github.com/adsieg/text_similarity)
- [Michael J. Pazzani, Daniel Billsus. Content-Based Recommendation Systems](https://link.springer.com/chapter/10.1007/978-3-540-72079-9_10) [(PDF)](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.130.8327&rep=rep1&type=pdf)
- [Charu C. Aggarwal. Content-Based Recommender Systems](https://link.springer.com/chapter/10.1007/978-3-319-29659-3_4)
- [Sentence Similarity Calculator (ELMo, BERT and Universal Sentence Encoder, and different similarity measures)](https://github.com/Huffon/sentence-similarity)
Awesome:
- [Awesome Sentence Embeddings](https://github.com/Separius/awesome-sentence-embedding)
- [Awesome Neural Models for Semantic Match](https://github.com/NTMC-Community/awesome-neural-models-for-semantic-match)
- [Awesome Network Embedding](https://github.com/chihming/awesome-network-embedding)