https://github.com/mikeroyal/Distributed-Systems-Guide
Distributed Systems Guide
https://github.com/mikeroyal/Distributed-Systems-Guide
List: Distributed-Systems-Guide
awesome awesome-distributed-computing distributed distributed-computing distributed-database distributed-storage distributed-systems high-availability high-performance-computing machine-learning
Last synced: 6 months ago
JSON representation
Distributed Systems Guide
- Host: GitHub
- URL: https://github.com/mikeroyal/Distributed-Systems-Guide
- Owner: mikeroyal
- Created: 2021-09-26T20:44:35.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2021-09-26T21:46:15.000Z (over 3 years ago)
- Last Synced: 2024-05-20T01:06:43.204Z (about 1 year ago)
- Topics: awesome, awesome-distributed-computing, distributed, distributed-computing, distributed-database, distributed-storage, distributed-systems, high-availability, high-performance-computing, machine-learning
- Homepage:
- Size: 538 KB
- Stars: 22
- Watchers: 3
- Forks: 2
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- ultimate-awesome - Distributed-Systems-Guide - Distributed Systems Guide. (Other Lists / Julia Lists)
README

Distributed Systems Guide
#### A guide covering Distributed Systems including the applications, libraries and tools that will make you better and more efficient with Distributed Systems development.
**Note: You can easily convert this markdown file to a PDF in [VSCode](https://code.visualstudio.com/) using this handy extension [Markdown PDF](https://marketplace.visualstudio.com/items?itemName=yzane.markdown-pdf).**


**Architecture of a Distributed Database System. Source: [ResearchGate](https://www.researchgate.net/figure/Architecture-of-a-Distributed-Database-System_fig1_330485258)**
# Table of Contents
1. [Distributed Systems Learning Resources](https://github.com/mikeroyal/Distributed-Systems-Guide#Distributed-Systems-learning-resources)
2. [Distributed Systems Tools, Libraries, and Frameworks](https://github.com/mikeroyal/Distributed-Systems-Guide#Distributed-Systems-tools-libraries-and-frameworks)
3. [Apache Spark Development](https://github.com/mikeroyal/Distributed-Systems-Guide#apache-spark-development)
4. [Databases](https://github.com/mikeroyal/Distributed-Systems-Guide#databases)
5. [Networking](https://github.com/mikeroyal/Distributed-Systems-Guide#networking)
6. [Telco 5G Development](https://github.com/mikeroyal/Distributed-Systems-Guide#telco-5g-development)
7. [Cloud Native Development](https://github.com/mikeroyal/Distributed-Systems-Guide#cloud-native)
8. [Machine Learning](https://github.com/mikeroyal/Distributed-Systems-Guide#machine-learning)
9. [Algorithms](https://github.com/mikeroyal/Distributed-Systems-Guide#Algorithms)
10. [Deep Learning Development](https://github.com/mikeroyal/Distributed-Systems-Guide#Deep-Learning-Development)
11. [Reinforcement Learning Development](https://github.com/mikeroyal/Distributed-Systems-Guide#Reinforcement-Learning-Development)
12. [Computer Vision Development](https://github.com/mikeroyal/Distributed-Systems-Guide#computer-vision-development)
13. [Natural Language Processing (NLP) Development](https://github.com/mikeroyal/Distributed-Systems-Guide#nlp-development)
14. [Bioinformatics](https://github.com/mikeroyal/Distributed-Systems-Guide#bioinformatics)
15. [CUDA Development](https://github.com/mikeroyal/Distributed-Systems-Guide#cuda-development)
16. [MATLAB Development](https://github.com/mikeroyal/Distributed-Systems-Guide#matlab-development)
17. [C/C++ Development](https://github.com/mikeroyal/Distributed-Systems-Guide#cc-development)
18. [Java Development](https://github.com/mikeroyal/Distributed-Systems-Guide#java-development)
19. [Python Development](https://github.com/mikeroyal/Distributed-Systems-Guide#python-development)
20. [Scala Development](https://github.com/mikeroyal/Distributed-Systems-Guide#scala-development)
21. [R Development](https://github.com/mikeroyal/Distributed-Systems-Guide#r-development)
22. [Julia Development](https://github.com/mikeroyal/Distributed-Systems-Guide#julia-development)
# Distributed Systems Learning Resources
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)
[Distributed System](https://www.splunk.com/en_us/data-insider/what-are-distributed-systems.html) is a computing environment in which various components are spread across multiple computers (or other computing devices) on a network. These devices split up the work, coordinating their efforts to complete the job more efficiently than if a single device had been responsible for the task. There are four different basic architecture models:
1. [Client-server](https://en.wikipedia.org/wiki/Client%E2%80%93server_model) is a system where clients contact the server for data, then format it and display it to the end-user. The end-user can also make a change from the client-side and commit it back to the server to make it permanent.
2. [Three-tier](https://www.ibm.com/cloud/learn/three-tier-architecture) is a software application architecture that organizes applications into three logical and physical computing tiers: the presentation tier, or user interface; the application tier, where data is processed; and the data tier, where the data associated with the application is stored and managed.
3. [n-tier](https://docs.microsoft.com/en-us/azure/architecture/guide/architecture-styles/n-tier) is a system that does separate processing into discrete tiers that are distributed between the client and the server. When you develop applications that access data, you should have a clear separation between the various tiers that make up the application.
4. [Peer-to-peer](https://en.wikipedia.org/wiki/Peer-to-peer) is a system where are no additional machines used to provide services or manage resources. Responsibilities are uniformly distributed among machines in the system, known as peers, which can serve as either client or server.
[Top Distributed Systems Courses Online | Coursera](https://www.coursera.org/courses?query=distributed%20systems)
[Distributed Systems Online | Stanford Online](https://online.stanford.edu/courses/cs244b-distributed-systems)
[Top Distributed Computing Courses Online | Udemy](https://www.udemy.com/topic/distributed-computing/)
[Distributed Systems & Cloud Computing with Java | Udemy](https://www.udemy.com/course/distributed-systems-cloud-computing-with-java/)
[Introduction to Distributed Systems | University of Washington](https://courses.cs.washington.edu/courses/cse490h/07wi/readings/IntroductionToDistributedSystems.pdf)
[Distributed Systems - University of Wisconsin-Madison](https://pages.cs.wisc.edu/~remzi/OSTEP/dist-intro.pdf)
[A Thorough Introduction to Distributed Systems | FreeCodeCamp](https://www.freecodecamp.org/news/a-thorough-introduction-to-distributed-systems-3b91562c9b3c/)
[Introduction to Distributed Systems | UPenn](https://www.cis.upenn.edu/~lee/03cse380/lectures/ln19-ds-v3.4pp.pdf)
[Distribution System Certificate Program Online | ASU](https://ce.arizona.edu/classes/distribution-system-certificate)
[Autonomous Systems - Microsoft AI](https://www.microsoft.com/en-us/ai/autonomous-systems)
[Introduction to Microsoft Project Bonsai](https://docs.microsoft.com/en-us/learn/autonomous-systems/intro-to-project-bonsai/)
[Machine teaching with the Microsoft Autonomous Systems platform](https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/autonomous-systems)
# Distributed Systems Tools, Libraries, and Frameworks
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)
[Apache Cassandra™](https://cassandra.apache.org/) is an open source NoSQL distributed database trusted by thousands of companies for scalability and high availability without compromising performance. Cassandra provides linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data.
[Apache Flume](https://flume.apache.org/) is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of streaming event data.
[Apache Mesos](http://mesos.apache.org/) is a cluster manager that provides efficient resource isolation and sharing across distributed applications, or frameworks. It can run Hadoop, Jenkins, Spark, Aurora, and other frameworks on a dynamically shared pool of nodes.
[Apache HBase™](https://hbase.apache.org/) is an open-source, NoSQL, distributed big data store. It enables random, strictly consistent, real-time access to petabytes of data. HBase is very effective for handling large, sparse datasets. HBase serves as a direct input and output to the Apache MapReduce framework for Hadoop, and works with Apache Phoenix to enable SQL-like queries over HBase tables.
[Hadoop Distributed File System (HDFS)](https://www.ibm.com/analytics/hadoop/hdfs) is a distributed file system that handles large data sets running on commodity hardware. It is used to scale a single Apache Hadoop cluster to hundreds (and even thousands) of nodes. HDFS is one of the major components of Apache Hadoop, the others being [MapReduce](https://www.ibm.com/analytics/hadoop/mapreduce) and [YARN](https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html).
[Apache Arrow](https://arrow.apache.org/) is a language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware like CPUs and GPUs.
[Apache Spark™](https://spark.apache.org/) is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.
[Apache PredictionIO](https://predictionio.apache.org/) is an open source machine learning framework for developers, data scientists, and end users. It supports event collection, deployment of algorithms, evaluation, querying predictive results via REST APIs. It is based on scalable open source services like Hadoop, HBase (and other DBs), Elasticsearch, Spark and implements what is called a Lambda Architecture.
[Microsoft Project Bonsai](https://azure.microsoft.com/en-us/services/project-bonsai/) is a low-code AI platform that speeds AI-powered automation development and part of the Autonomous Systems suite from Microsoft. Bonsai is used to build AI components that can provide operator guidance or make independent decisions to optimize process variables, improve production efficiency, and reduce downtime.
[Cluster Manager for Apache Kafka(CMAK)](https://github.com/yahoo/CMAK) is a tool for managing [Apache Kafka](https://kafka.apache.org/) clusters.
[BigDL](https://bigdl-project.github.io/) is a distributed deep learning library for Apache Spark. With BigDL, users can write their deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters.
[Apache Cassandra™](https://cassandra.apache.org/) is an open source NoSQL distributed database trusted by thousands of companies for scalability and high availability without compromising performance. Cassandra provides linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data.
[Apache Flume](https://flume.apache.org/) is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of streaming event data.
[Apache Mesos](http://mesos.apache.org/) is a cluster manager that provides efficient resource isolation and sharing across distributed applications, or frameworks. It can run Hadoop, Jenkins, Spark, Aurora, and other frameworks on a dynamically shared pool of nodes.
[Apache Beam](https://beam.apache.org/) is an open source, unified model and set of language-specific SDKs for defining and executing data processing workflows, and also data ingestion and integration flows, supporting Enterprise Integration Patterns (EIPs) and Domain Specific Languages (DSLs).
[Jupyter Notebook](https://jupyter.org/) is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Jupyter is used widely in industries that do data cleaning and transformation, numerical simulation, statistical modeling, data visualization, data science, and machine learning.
[Neo4j](https://neo4j.com/) is the only enterprise-strength graph database that combines native graph storage, advanced security, scalable speed-optimized architecture, and ACID compliance to ensure predictability and integrity of relationship-based queries.
[ElasticSearch](https://www.elastic.co/) is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java.
[Logstash](https://www.elastic.co/products/logstash) is a tool for managing events and logs. When used generically, the term encompasses a larger system of log collection, processing, storage and searching activities.
[Kibana](https://www.elastic.co/products/kibana) is an open source data visualization plugin for Elasticsearch. It provides visualization capabilities on top of the content indexed on an Elasticsearch cluster. Users can create bar, line and scatter plots, or pie charts and maps on top of large volumes of data.
[Trino](https://trino.io/) is a Distributed SQL query engine for big data. It is able to tremendously speed up [ETL processes](https://docs.microsoft.com/en-us/azure/architecture/data-guide/relational-data/etl), allow them all to use standard SQL statement, and work with numerous data sources and targets all in the same system.
[Extract, transform, and load (ETL)](https://docs.microsoft.com/en-us/azure/architecture/data-guide/relational-data/etl) is a data pipeline used to collect data from various sources, transform the data according to business rules, and load it into a destination data store.
[Redis(REmote DIctionary Server)](https://redis.io/) is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. It provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams.
[Apache OpenNLP](https://opennlp.apache.org/) is an open-source library for a machine learning based toolkit used in the processing of natural language text. It features an API for use cases like [Named Entity Recognition](https://en.wikipedia.org/wiki/Named-entity_recognition), [Sentence Detection](), [POS(Part-Of-Speech) tagging](https://en.wikipedia.org/wiki/Part-of-speech_tagging), [Tokenization](https://en.wikipedia.org/wiki/Tokenization_(data_security)) [Feature extraction](https://en.wikipedia.org/wiki/Feature_extraction), [Chunking](https://en.wikipedia.org/wiki/Chunking_(psychology)), [Parsing](https://en.wikipedia.org/wiki/Parsing), and [Coreference resolution](https://en.wikipedia.org/wiki/Coreference).
[Apache Airflow](https://airflow.apache.org) is an open-source workflow management platform created by the community to programmatically author, schedule and monitor workflows. Install. Principles. Scalable. Airflow has a modular architecture and uses a message queue to orchestrate an arbitrary number of workers. Airflow is ready to scale to infinity.
[Open Neural Network Exchange(ONNX)](https://github.com/onnx) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types.
[Apache MXNet](https://mxnet.apache.org/) is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scaling effectively to multiple GPUs and multiple machines. Support for Python, R, Julia, Scala, Go, Javascript and more.
[AutoGluon](https://autogluon.mxnet.io/index.html) is toolkit for Deep learning that automates machine learning tasks enabling you to easily achieve strong predictive performance in your applications. With just a few lines of code, you can train and deploy high-accuracy deep learning models on tabular, image, and text data.
# Apache Spark Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## Apache Spark Learning Resources
[Apache Spark™](https://spark.apache.org/) is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.
[Apache Spark Quick Start](https://spark.apache.org/docs/latest/quick-start.html)
[What is Apache Spark? | IBM](https://www.ibm.com/cloud/learn/apache-spark)
[Introduction to Apache Spark and Analytics | AWS](https://aws.amazon.com/big-data/what-is-spark/)
[Apache Spark 3.0: For Analytics & Machine Learning | NVIDIA](https://www.nvidia.com/en-us/deep-learning-ai/solutions/data-science/apache-spark-3/)
[.NET for Apache Spark™ | Big data analytics](https://dotnet.microsoft.com/apps/data/spark)
[Apache Spark Basics | MATLAB & Simulink](https://www.mathworks.com/help//compiler/spark/apache-spark-basics.html)
[MATLAB Hadoop and Spark | MATLAB & Simulink](https://www.mathworks.com/products/compiler/hadoop-and-spark.html)
[Top Apache Spark Courses Online | Coursera](https://www.coursera.org/courses?query=apache%20spark)
[Top Apache Spark Courses Online | Udemy](https://www.udemy.com/topic/apache-spark/)
[Apache Spark In-Depth (Spark with Scala) | Udemy](https://www.udemy.com/course/apache-spark-in-depth-spark-with-scala/)
[Learn Apache Spark with Online Courses | edX](https://www.edx.org/learn/apache-spark)
[Apache Spark Essential Training Online Class | LinkedIn Learning](https://www.linkedin.com/learning/apache-spark-essential-training)
[Cloudera Developer Training for Apache Spark™ and Hadoop | Cloudera](https://www.cloudera.com/about/training/courses/developer-training-for-spark-and-hadoop.html)
[Databricks Certified Associate Developer for Apache Spark 3.0 certification | Databricks](https://academy.databricks.com/exam/databricks-certified-associate-developer)
[Apache Spark Training Courses | NobleProg](https://www.nobleprog.com/apache-spark-training)
## Apache Spark Tools, Libraries, and Frameworks
[Spark SQL](https://spark.apache.org/sql/) is a Spark module for structured data processing. Unlike the basic Spark RDD API, the interfaces provided by Spark SQL provide Spark with more information about the structure of both the data and the computation being performed. Internally, Spark SQL uses this extra information to perform extra optimizations.
[Spark Streaming](https://spark.apache.org/streaming/) is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. It can express your streaming computation the same way you would express a batch computation on static data from various sources including [Apache Kafka](https://kafka.apache.org/), [Apache Flume](https://flume.apache.org/), and [Amazon Kinesis](https://aws.amazon.com/kinesis/).
[MLib](https://spark.apache.org/mllib/) is Spark’s machine learning (ML) library. Its goal is to make practical machine learning scalable and easy. It consists of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, dimensionality reduction, as well as lower-level optimization primitives and higher-level pipeline APIs.
[Graphx](https://spark.apache.org/graphx/) is the new Spark API for graphs and graph-parallel computation. At a high-level, GraphX extends the [Spark RDD](https://spark.apache.org/docs/latest/rdd-programming-guide.html) by introducing the Resilient Distributed Property Graph: a directed multigraph with properties attached to each vertex and edge.
[PySpark](https://spark.apache.org/docs/latest/api/python/index.html) is an interface for Apache Spark in Python. It not only allows you to write Spark applications using Python APIs, but also provides the PySpark shell for interactively analyzing your data in a distributed environment.
[Apache Spark Connector for SQL Server and Azure SQL](https://github.com/microsoft/sql-spark-connector) is a high-performance connector that enables you to use transactional data in big data analytics and persists results for ad-hoc queries or reporting. The connector allows you to use any SQL database, on-premises or in the cloud, as an input data source or output data sink for Spark jobs.
[Azure Databricks](https://azure.microsoft.com/en-us/services/databricks/) is a fast and collaborative Apache Spark-based big data analytics service designed for data science and data engineering. Azure Databricks, sets up your Apache Spark environment in minutes, autoscale, and collaborate on shared projects in an interactive workspace. Azure Databricks supports Python, Scala, R, Java, and SQL, as well as data science frameworks and libraries including TensorFlow, PyTorch, and scikit-learn.
[Koalas](https://github.com/databricks/koalas) is a project that makes data scientists more productive when interacting with big data, by implementing the [pandas DataFrame API](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html) on top of [Apache Spark](https://spark.apache.org/).
[MLflow](https://mlflow.org/)is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. It offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (notebooks, standalone applications or the cloud). MLflow has four main components:
- The [Tracking component](https://mlflow.org/docs/latest/tracking.html) that allows you to record machine model training sessions (called runs) and run queries using Java, Python, R, and REST APIs.
- The [Projects component](https://mlflow.org/docs/latest/projects.html) packages code that is used in data science projects to ensure it can easily be reused and experiments can be reproduced.
- The [Models component](https://mlflow.org/docs/latest/models.html) that provides a standard unit for packaging and reusing machine learning models.
- The [Model Registry](https://mlflow.org/docs/latest/model-registry.html) component that lets you centrally manage models and their lifecycle.
[Apache PredictionIO](https://predictionio.apache.org/) is an open source machine learning framework for developers, data scientists, and end users. It supports event collection, deployment of algorithms, evaluation, querying predictive results via REST APIs. It is based on scalable open source services like Hadoop, HBase (and other DBs), Elasticsearch, Spark and implements what is called a Lambda Architecture.
[Cluster Manager for Apache Kafka(CMAK)](https://github.com/yahoo/CMAK) is a tool for managing [Apache Kafka](https://kafka.apache.org/) clusters.
[BigDL](https://bigdl-project.github.io/) is a distributed deep learning library for Apache Spark. With BigDL, users can write their deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters.
[Apache Cassandra™](https://cassandra.apache.org/) is an open source NoSQL distributed database trusted by thousands of companies for scalability and high availability without compromising performance. Cassandra provides linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data.
[Apache Flume](https://flume.apache.org/) is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of streaming event data.
[Apache Mesos](http://mesos.apache.org/) is a cluster manager that provides efficient resource isolation and sharing across distributed applications, or frameworks. It can run Hadoop, Jenkins, Spark, Aurora, and other frameworks on a dynamically shared pool of nodes.
[Apache HBase™](https://hbase.apache.org/) is an open-source, NoSQL, distributed big data store. It enables random, strictly consistent, real-time access to petabytes of data. HBase is very effective for handling large, sparse datasets. HBase serves as a direct input and output to the Apache MapReduce framework for Hadoop, and works with Apache Phoenix to enable SQL-like queries over HBase tables.
[Hadoop Distributed File System (HDFS)](https://www.ibm.com/analytics/hadoop/hdfs) is a distributed file system that handles large data sets running on commodity hardware. It is used to scale a single Apache Hadoop cluster to hundreds (and even thousands) of nodes. HDFS is one of the major components of Apache Hadoop, the others being [MapReduce](https://www.ibm.com/analytics/hadoop/mapreduce) and [YARN](https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html).
[Apache Arrow](https://arrow.apache.org/) is a language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware like CPUs and GPUs.
[Jupyter Notebook](https://jupyter.org/) is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Jupyter is used widely in industries that do data cleaning and transformation, numerical simulation, statistical modeling, data visualization, data science, and machine learning.
[Neo4j](https://neo4j.com/) is the only enterprise-strength graph database that combines native graph storage, advanced security, scalable speed-optimized architecture, and ACID compliance to ensure predictability and integrity of relationship-based queries.
[ElasticSearch](https://www.elastic.co/) is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java.
[Logstash](https://www.elastic.co/products/logstash) is a tool for managing events and logs. When used generically, the term encompasses a larger system of log collection, processing, storage and searching activities.
[Kibana](https://www.elastic.co/products/kibana) is an open source data visualization plugin for Elasticsearch. It provides visualization capabilities on top of the content indexed on an Elasticsearch cluster. Users can create bar, line and scatter plots, or pie charts and maps on top of large volumes of data.
[Trino](https://trino.io/) is a Distributed SQL query engine for big data. It is able to tremendously speed up [ETL processes](https://docs.microsoft.com/en-us/azure/architecture/data-guide/relational-data/etl), allow them all to use standard SQL statement, and work with numerous data sources and targets all in the same system.
[Extract, transform, and load (ETL)](https://docs.microsoft.com/en-us/azure/architecture/data-guide/relational-data/etl) is a data pipeline used to collect data from various sources, transform the data according to business rules, and load it into a destination data store.
[Redis(REmote DIctionary Server)](https://redis.io/) is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. It provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams.
[Apache OpenNLP](https://opennlp.apache.org/) is an open-source library for a machine learning based toolkit used in the processing of natural language text. It features an API for use cases like [Named Entity Recognition](https://en.wikipedia.org/wiki/Named-entity_recognition), [Sentence Detection](), [POS(Part-Of-Speech) tagging](https://en.wikipedia.org/wiki/Part-of-speech_tagging), [Tokenization](https://en.wikipedia.org/wiki/Tokenization_(data_security)) [Feature extraction](https://en.wikipedia.org/wiki/Feature_extraction), [Chunking](https://en.wikipedia.org/wiki/Chunking_(psychology)), [Parsing](https://en.wikipedia.org/wiki/Parsing), and [Coreference resolution](https://en.wikipedia.org/wiki/Coreference).
[Apache Airflow](https://airflow.apache.org) is an open-source workflow management platform created by the community to programmatically author, schedule and monitor workflows. Install. Principles. Scalable. Airflow has a modular architecture and uses a message queue to orchestrate an arbitrary number of workers. Airflow is ready to scale to infinity.
[Open Neural Network Exchange(ONNX)](https://github.com/onnx) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types.
[Apache MXNet](https://mxnet.apache.org/) is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scaling effectively to multiple GPUs and multiple machines. Support for Python, R, Julia, Scala, Go, Javascript and more.
[AutoGluon](https://autogluon.mxnet.io/index.html) is toolkit for Deep learning that automates machine learning tasks enabling you to easily achieve strong predictive performance in your applications. With just a few lines of code, you can train and deploy high-accuracy deep learning models on tabular, image, and text data.
[Anaconda](https://www.anaconda.com/) is a very popular Data Science platform for machine learning and deep learning that enables users to develop models, train them, and deploy them.
[PlaidML](https://github.com/plaidml/plaidml) is an advanced and portable tensor compiler for enabling deep learning on laptops, embedded devices, or other devices where the available computing hardware is not well supported or the available software stack contains unpalatable license restrictions.
[OpenCV](https://opencv.org) is a highly optimized library with focus on real-time computer vision applications. The C++, Python, and Java interfaces support Linux, MacOS, Windows, iOS, and Android.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a Python module for machine learning built on top of SciPy, NumPy, and matplotlib, making it easier to apply robust and simple implementations of many popular machine learning algorithms.
[Weka](https://www.cs.waikato.ac.nz/ml/weka/) is an open source machine learning software that can be accessed through a graphical user interface, standard terminal applications, or a Java API. It is widely used for teaching, research, and industrial applications, contains a plethora of built-in tools for standard machine learning tasks, and additionally gives transparent access to well-known toolboxes such as scikit-learn, R, and Deeplearning4j.
[Caffe](https://github.com/BVLC/caffe) is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) and community contributors.
[Theano](https://github.com/Theano/Theano) is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently including tight integration with NumPy
# Databases
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)


## SQL/NoSQL Learning Resources
[SQL](https://en.wikipedia.org/wiki/SQL) is a standard language for storing, manipulating and retrieving data in relational databases.
[NoSQL](https://www.ibm.com/cloud/blog/sql-vs-nosql) is a database that is interchangeably referred to as "nonrelational, or "non-SQL" to highlight that the database can handle huge volumes of rapidly changing, unstructured data in different ways than a relational (SQL-based) database with rows and tables.
[Transact-SQL(T-SQL)](https://docs.microsoft.com/en-us/sql/t-sql/language-reference) is a Microsoft extension of SQL with all of the tools and applications communicating to a SQL database by sending T-SQL commands.
[Introduction to Transact-SQL](https://docs.microsoft.com/en-us/learn/modules/introduction-to-transact-sql/)
[SQL Tutorial by W3Schools](https://www.w3schools.com/sql/)
[Learn SQL Skills Online from Coursera](https://www.coursera.org/courses?query=sql)
[SQL Courses Online from Udemy](https://www.udemy.com/topic/sql/)
[SQL Online Training Courses from LinkedIn Learning](https://www.linkedin.com/learning/topics/sql)
[Learn SQL For Free from Codecademy](https://www.codecademy.com/learn/learn-sql)
[GitLab's SQL Style Guide](https://about.gitlab.com/handbook/business-ops/data-team/platform/sql-style-guide/)
[OracleDB SQL Style Guide Basics](https://oracle.readthedocs.io/en/latest/sql/basics/style-guide.html)
[Tableau CRM: BI Software and Tools](https://www.salesforce.com/products/crm-analytics/overview/)
[Databases on AWS](https://aws.amazon.com/products/databases/)
[Best Practices and Recommendations for SQL Server Clustering in AWS EC2.](https://docs.aws.amazon.com/AWSEC2/latest/WindowsGuide/aws-sql-clustering.html)
[Connecting from Google Kubernetes Engine to a Cloud SQL instance.](https://cloud.google.com/sql/docs/mysql/connect-kubernetes-engine)
[Educational Microsoft Azure SQL resources](https://docs.microsoft.com/en-us/sql/sql-server/educational-sql-resources?view=sql-server-ver15)
[MySQL Certifications](https://www.mysql.com/certification/)
[SQL vs. NoSQL Databases: What's the Difference?](https://www.ibm.com/cloud/blog/sql-vs-nosql)
[What is NoSQL?](https://aws.amazon.com/nosql/)
## SQL/NoSQL Tools and Databases
[Netdata](https://github.com/netdata/netdata) is high-fidelity infrastructure monitoring and troubleshooting, real-time monitoring Agent collects thousands of metrics from systems, hardware, containers, and applications with zero configuration. It runs permanently on all your physical/virtual servers, containers, cloud deployments, and edge/IoT devices, and is perfectly safe to install on your systems mid-incident without any preparation.
[Azure Data Studio](https://github.com/Microsoft/azuredatastudio) is an open source data management tool that enables working with SQL Server, Azure SQL DB and SQL DW from Windows, macOS and Linux.
[Azure SQL Database](https://azure.microsoft.com/en-us/services/sql-database/) is the intelligent, scalable, relational database service built for the cloud. It’s evergreen and always up to date, with AI-powered and automated features that optimize performance and durability for you. Serverless compute and Hyperscale storage options automatically scale resources on demand, so you can focus on building new applications without worrying about storage size or resource management.
[Azure SQL Managed Instance](https://azure.microsoft.com/en-us/services/azure-sql/sql-managed-instance/) is a fully managed SQL Server Database engine instance that's hosted in Azure and placed in your network. This deployment model makes it easy to lift and shift your on-premises applications to the cloud with very few application and database changes. Managed instance has split compute and storage components.
[Azure Synapse Analytics](https://azure.microsoft.com/en-us/services/synapse-analytics/) is a limitless analytics service that brings together enterprise data warehousing and Big Data analytics. It gives you the freedom to query data on your terms, using either serverless or provisioned resources at scale. It brings together the best of the SQL technologies used in enterprise data warehousing, Spark technologies used in big data analytics, and Pipelines for data integration and ETL/ELT.
[MSSQL for Visual Studio Code](https://marketplace.visualstudio.com/items?itemName=ms-mssql.mssql) is an extension for developing Microsoft SQL Server, Azure SQL Database and SQL Data Warehouse everywhere with a rich set of functionalities.
[SQL Server Data Tools (SSDT)](https://docs.microsoft.com/en-us/sql/ssdt/download-sql-server-data-tools-ssdt) is a development tool for building SQL Server relational databases, Azure SQL Databases, Analysis Services (AS) data models, Integration Services (IS) packages, and Reporting Services (RS) reports. With SSDT, a developer can design and deploy any SQL Server content type with the same ease as they would develop an application in Visual Studio or Visual Studio Code.
[Bulk Copy Program](https://docs.microsoft.com/en-us/sql/tools/bcp-utility) is a command-line tool that comes with Microsoft SQL Server. BCP, allows you to import and export large amounts of data in and out of SQL Server databases quickly snd efficeiently.
[SQL Server Migration Assistant](https://www.microsoft.com/en-us/download/details.aspx?id=54258) is a tool from Microsoft that simplifies database migration process from Oracle to SQL Server, Azure SQL Database, Azure SQL Database Managed Instance and Azure SQL Data Warehouse.
[SQL Server Integration Services](https://docs.microsoft.com/en-us/sql/integration-services/sql-server-integration-services?view=sql-server-ver15) is a development platform for building enterprise-level data integration and data transformations solutions. Use Integration Services to solve complex business problems by copying or downloading files, loading data warehouses, cleansing and mining data, and managing SQL Server objects and data.
[SQL Server Business Intelligence(BI)](https://www.microsoft.com/en-us/sql-server/sql-business-intelligence) is a collection of tools in Microsoft's SQL Server for transforming raw data into information businesses can use to make decisions.
[Tableau](https://www.tableau.com/) is a Data Visualization software used in relational databases, cloud databases, and spreadsheets. Tableau was acquired by [Salesforce in August 2019](https://investor.salesforce.com/press-releases/press-release-details/2019/Salesforce-Completes-Acquisition-of-Tableau/default.aspx).
[DataGrip](https://www.jetbrains.com/datagrip/) is a professional DataBase IDE developed by Jet Brains that provides context-sensitive code completion, helping you to write SQL code faster. Completion is aware of the tables structure, foreign keys, and even database objects created in code you're editing.
[RStudio](https://rstudio.com/) is an integrated development environment for R and Python, with a console, syntax-highlighting editor that supports direct code execution, and tools for plotting, history, debugging and workspace management.
[MySQL](https://www.mysql.com/) is a fully managed database service to deploy cloud-native applications using the world's most popular open source database.
[PostgreSQL](https://www.postgresql.org/) is a powerful, open source object-relational database system with over 30 years of active development that has earned it a strong reputation for reliability, feature robustness, and performance.
[Amazon DynamoDB](https://aws.amazon.com/dynamodb/) is a key-value and document database that delivers single-digit millisecond performance at any scale. It is a fully managed, multiregion, multimaster, durable database with built-in security, backup and restore, and in-memory caching for internet-scale applications.
[Apache Cassandra™](https://cassandra.apache.org/) is an open source NoSQL distributed database trusted by thousands of companies for scalability and high availability without compromising performance. Cassandra provides linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data.
[Apache HBase™](https://hbase.apache.org/) is an open-source, NoSQL, distributed big data store. It enables random, strictly consistent, real-time access to petabytes of data. HBase is very effective for handling large, sparse datasets. HBase serves as a direct input and output to the Apache MapReduce framework for Hadoop, and works with Apache Phoenix to enable SQL-like queries over HBase tables.
[Hadoop Distributed File System (HDFS)](https://www.ibm.com/analytics/hadoop/hdfs) is a distributed file system that handles large data sets running on commodity hardware. It is used to scale a single Apache Hadoop cluster to hundreds (and even thousands) of nodes. HDFS is one of the major components of Apache Hadoop, the others being [MapReduce](https://www.ibm.com/analytics/hadoop/mapreduce) and [YARN](https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html).
[Apache Mesos](http://mesos.apache.org/) is a cluster manager that provides efficient resource isolation and sharing across distributed applications, or frameworks. It can run Hadoop, Jenkins, Spark, Aurora, and other frameworks on a dynamically shared pool of nodes.
[Apache Spark](https://spark.apache.org/) is a unified analytics engine for big data processing, with built-in modules for streaming, SQL, machine learning and graph processing.
[ElasticSearch](https://www.elastic.co/) is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java.
[Logstash](https://www.elastic.co/products/logstash) is a tool for managing events and logs. When used generically, the term encompasses a larger system of log collection, processing, storage and searching activities.
[Kibana](https://www.elastic.co/products/kibana) is an open source data visualization plugin for Elasticsearch. It provides visualization capabilities on top of the content indexed on an Elasticsearch cluster. Users can create bar, line and scatter plots, or pie charts and maps on top of large volumes of data.
[Trino](https://trino.io/) is a Distributed SQL query engine for big data. It is able to tremendously speed up [ETL processes](https://docs.microsoft.com/en-us/azure/architecture/data-guide/relational-data/etl), allow them all to use standard SQL statement, and work with numerous data sources and targets all in the same system.
[Extract, transform, and load (ETL)](https://docs.microsoft.com/en-us/azure/architecture/data-guide/relational-data/etl) is a data pipeline used to collect data from various sources, transform the data according to business rules, and load it into a destination data store.
[Redis(REmote DIctionary Server)](https://redis.io/) is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. It provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams.
[FoundationDB](https://www.foundationdb.org/) is an open source distributed database designed to handle large volumes of structured data across clusters of commodity servers. It organizes data as an ordered key-value store and employs ACID transactions for all operations. It is especially well-suited for read/write workloads but also has excellent performance for write-intensive workloads. FoundationDB was acquired by [Apple in 2015](https://techcrunch.com/2015/03/24/apple-acquires-durable-database-company-foundationdb/).
[IBM DB2](https://www.ibm.com/analytics/db2) is a collection of hybrid data management products offering a complete suite of AI-empowered capabilities designed to help you manage both structured and unstructured data on premises as well as in private and public cloud environments. Db2 is built on an intelligent common SQL engine designed for scalability and flexibility.
[MongoDB](https://www.mongodb.com/) is a document database meaning it stores data in JSON-like documents.
[OracleDB](https://www.oracle.com/database/) is a powerful fully managed database helps developers manage business-critical data with the highest availability, reliability, and security.
[MariaDB](https://mariadb.com/) is an enterprise open source database solution for modern, mission-critical applications.
[SQLite](https://sqlite.org/index.html) is a C-language library that implements a small, fast, self-contained, high-reliability, full-featured, SQL database engine.SQLite is the most used database engine in the world. SQLite is built into all mobile phones and most computers and comes bundled inside countless other applications that people use every day.
[SQLite Database Browser](https://sqlitebrowser.org/) is an open source SQL tool that allows users to create, design and edits SQLite database files. It lets users show a log of all the SQL commands that have been issued by them and by the application itself.
[InfluxDB](https://www.influxdata.com/) is an open source time series platform. This includes APIs for storing and querying data, processing it in the background for [ETL](https://docs.microsoft.com/en-us/azure/architecture/data-guide/relational-data/etl) or monitoring and alerting purposes, user dashboards, Internet of Things sensor data, and visualizing and exploring the data and more. It also has support for processing data from [Graphite](http://graphiteapp.org/).
[Atlas](https://github.com/Netflix/atlas) is an in-memory dimensional [time series database](https://en.wikipedia.org/wiki/Time_series_database).
[CouchbaseDB](https://www.couchbase.com/) is an open source distributed [multi-model NoSQL document-oriented database](https://en.wikipedia.org/wiki/Multi-model_database). It creates a key-value store with managed cache for sub-millisecond data operations, with purpose-built indexers for efficient queries and a powerful query engine for executing SQL queries.
[dbWatch](https://www.dbwatch.com/) is a complete database monitoring/management solution for SQL Server, Oracle, PostgreSQL, Sybase, MySQL and Azure. Designed for proactive management and automation of routine maintenance in large scale on-premise, hybrid/cloud database environments.
[Cosmos DB Profiler](https://hibernatingrhinos.com/products/cosmosdbprof) is a real-time visual debugger allowing a development team to gain valuable insight and perspective into their usage of Cosmos DB database. It identifies over a dozen suspicious behaviors from your application’s interaction with Cosmos DB.
[Adminer](https://www.adminer.org/) is an SQL management client tool for managing databases, tables, relations, indexes, users. Adminer has support for all the popular database management systems such as MySQL, MariaDB, PostgreSQL, SQLite, MS SQL, Oracle, Firebird, SimpleDB, Elasticsearch and MongoDB.
[DBeaver](https://dbeaver.io/) is an open source database tool for developers and database administrators. It offers supports for JDBC compliant databases such as MySQL, Oracle, IBM DB2, SQL Server, Firebird, SQLite, Sybase, Teradata, Firebird, Apache Hive, Phoenix, and Presto.
[DbVisualizer](https://dbvis.com/) is a SQL management tool that allows users to manage a wide range of databases such as Oracle, Sybase, SQL Server, MySQL, H3, and SQLite.
[AppDynamics Database](https://www.appdynamics.com/supported-technologies/database) is a management product for Microsoft SQL Server. With AppDynamics you can monitor and trend key performance metrics such as resource consumption, database objects, schema statistics and more, allowing you to proactively tune and fix issues in a High-Volume Production Environment.
[Toad](https://www.quest.com/toad/) is a SQL Server DBMS toolset developed by Quest. It increases productivity by using extensive automation, intuitive workflows, and built-in expertise. This SQL management tool resolve issues, manage change and promote the highest levels of code quality for both relational and non-relational databases.
[Lepide SQL Server](https://www.lepide.com/sql-storage-manager/) is an open source storage manager utility to analyse the performance of SQL Servers. It provides a complete overview of all configuration and permission changes being made to your SQL Server environment through an easy-to-use, graphical user interface.
[Sequel Pro](https://sequelpro.com/) is a fast MacOS database management tool for working with MySQL. This SQL management tool helpful for interacting with your database by easily to adding new databases, new tables, and new rows.
# Networking
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## Network Learning Resources
[AWS Certified Security - Specialty Certification](https://aws.amazon.com/certification/certified-security-specialty/)
[Microsoft Certified: Azure Security Engineer Associate](https://docs.microsoft.com/en-us/learn/certifications/azure-security-engineer)
[Google Cloud Certified Professional Cloud Security Engineer](https://cloud.google.com/certification/cloud-security-engineer)
[Cisco Security Certifications](https://www.cisco.com/c/en/us/training-events/training-certifications/certifications/security.html)
[The Red Hat Certified Specialist in Security: Linux](https://www.redhat.com/en/services/training/ex415-red-hat-certified-specialist-security-linux-exam)
[Linux Professional Institute LPIC-3 Enterprise Security Certification](https://www.lpi.org/our-certifications/lpic-3-303-overview)
[Cybersecurity Training and Courses from IBM Skills](https://www.ibm.com/skills/topics/cybersecurity/)
[Cybersecurity Courses and Certifications by Offensive Security](https://www.offensive-security.com/courses-and-certifications/)
[Citrix Certified Associate – Networking(CCA-N)](http://training.citrix.com/cms/index.php/certification/networking/)
[Citrix Certified Professional – Virtualization(CCP-V)](https://www.globalknowledge.com/us-en/training/certification-prep/brands/citrix/section/virtualization/citrix-certified-professional-virtualization-ccp-v/)
[CCNP Routing and Switching](https://learningnetwork.cisco.com/s/ccnp-enterprise)
[Certified Information Security Manager(CISM)](https://www.isaca.org/credentialing/cism)
[Wireshark Certified Network Analyst (WCNA)](https://www.wiresharktraining.com/certification.html)
[Juniper Networks Certification Program Enterprise (JNCP)](https://www.juniper.net/us/en/training/certification/)
[Networking courses and specializations from Coursera](https://www.coursera.org/browse/information-technology/networking)
[Network & Security Courses from Udemy](https://www.udemy.com/courses/it-and-software/network-and-security/)
[Network & Security Courses from edX](https://www.edx.org/learn/cybersecurity)
## Networking Tools & Concepts
[cURL](https://curl.se/) is a computer software project providing a library and command-line tool for transferring data using various network protocols(HTTP, HTTPS, FTP, FTPS, SCP, SFTP, TFTP, DICT, TELNET, LDAP LDAPS, MQTT, POP3, POP3S, RTMP, RTMPS, RTSP, SCP, SFTP, SMB, SMBS, SMTP or SMTPS). cURL is also used in cars, television sets, routers, printers, audio equipment, mobile phones, tablets, settop boxes, media players and is the Internet transfer engine for thousands of software applications in over ten billion installations.
[cURL Fuzzer](https://github.com/curl/curl-fuzzer) is a quality assurance testing for the curl project.
[DoH](https://github.com/curl/doh) is a stand-alone application for DoH (DNS-over-HTTPS) name resolves and lookups.
[HTTPie](https://github.com/httpie/httpie) is a command-line HTTP client. Its goal is to make CLI interaction with web services as human-friendly as possible. HTTPie is designed for testing, debugging, and generally interacting with APIs & HTTP servers.
[HTTPStat](https://github.com/reorx/httpstat) is a tool that visualizes curl statistics in a simple layout.
[Wuzz](https://github.com/asciimoo/wuzz) is an interactive cli tool for HTTP inspection. It can be used to inspect/modify requests copied from the browser's network inspector with the "copy as cURL" feature.
[Websocat](https://github.com/vi/websocat) is a ommand-line client for WebSockets, like netcat (or curl) for ws:// with advanced socat-like functions.
• Connection: In networking, a connection refers to pieces of related information that are transferred through a network. This generally infers that a connection is built before the data transfer (by following the procedures laid out in a protocol) and then is deconstructed at the at the end of the data transfer.
• Packet: A packet is, generally speaking, the most basic unit that is transferred over a network. When communicating over a network, packets are the envelopes that carry your data (in pieces) from one end point to the other.
Packets have a header portion that contains information about the packet including the source and destination, timestamps, network hops. The main portion of a packet contains the actual data being transferred. It is sometimes called the body or the payload.
• Network Interface: A network interface can refer to any kind of software interface to networking hardware. For instance, if you have two network cards in your computer, you can control and configure each network interface associated with them individually.
A network interface may be associated with a physical device, or it may be a representation of a virtual interface. The "loop-back" device, which is a virtual interface to the local machine, is an example of this.
• LAN: LAN stands for "local area network". It refers to a network or a portion of a network that is not publicly accessible to the greater internet. A home or office network is an example of a LAN.
• WAN: WAN stands for "wide area network". It means a network that is much more extensive than a LAN. While WAN is the relevant term to use to describe large, dispersed networks in general, it is usually meant to mean the internet, as a whole.
If an interface is connected to the WAN, it is generally assumed that it is reachable through the internet.
• Protocol: A protocol is a set of rules and standards that basically define a language that devices can use to communicate. There are a great number of protocols in use extensively in networking, and they are often implemented in different layers.
Some low level protocols are TCP, UDP, IP, and ICMP. Some familiar examples of application layer protocols, built on these lower protocols, are HTTP (for accessing web content), SSH, TLS/SSL, and FTP.
• Port: A port is an address on a single machine that can be tied to a specific piece of software. It is not a physical interface or location, but it allows your server to be able to communicate using more than one application.
• Firewall: A firewall is a program that decides whether traffic coming into a server or going out should be allowed. A firewall usually works by creating rules for which type of traffic is acceptable on which ports. Generally, firewalls block ports that are not used by a specific application on a server.
• NAT: Network address translation is a way to translate requests that are incoming into a routing server to the relevant devices or servers that it knows about in the LAN. This is usually implemented in physical LANs as a way to route requests through one IP address to the necessary backend servers.
• VPN: Virtual private network is a means of connecting separate LANs through the internet, while maintaining privacy. This is used as a means of connecting remote systems as if they were on a local network, often for security reasons.
## Network Layers
While networking is often discussed in terms of topology in a horizontal way, between hosts, its implementation is layered in a vertical fashion throughout a computer or network. This means is that there are multiple technologies and protocols that are built on top of each other in order for communication to function more easily. Each successive, higher layer abstracts the raw data a little bit more, and makes it simpler to use for applications and users. It also allows you to leverage lower layers in new ways without having to invest the time and energy to develop the protocols and applications that handle those types of traffic.
As data is sent out of one machine, it begins at the top of the stack and filters downwards. At the lowest level, actual transmission to another machine takes place. At this point, the data travels back up through the layers of the other computer. Each layer has the ability to add its own "wrapper" around the data that it receives from the adjacent layer, which will help the layers that come after decide what to do with the data when it is passed off.
One method of talking about the different layers of network communication is the OSI model. OSI stands for Open Systems Interconnect.This model defines seven separate layers. The layers in this model are:
• Application: The application layer is the layer that the users and user-applications most often interact with. Network communication is discussed in terms of availability of resources, partners to communicate with, and data synchronization.
• Presentation: The presentation layer is responsible for mapping resources and creating context. It is used to translate lower level networking data into data that applications expect to see.
• Session: The session layer is a connection handler. It creates, maintains, and destroys connections between nodes in a persistent way.
• Transport: The transport layer is responsible for handing the layers above it a reliable connection. In this context, reliable refers to the ability to verify that a piece of data was received intact at the other end of the connection. This layer can resend information that has been dropped or corrupted and can acknowledge the receipt of data to remote computers.
• Network: The network layer is used to route data between different nodes on the network. It uses addresses to be able to tell which computer to send information to. This layer can also break apart larger messages into smaller chunks to be reassembled on the opposite end.
• Data Link: This layer is implemented as a method of establishing and maintaining reliable links between different nodes or devices on a network using existing physical connections.
• Physical: The physical layer is responsible for handling the actual physical devices that are used to make a connection. This layer involves the bare software that manages physical connections as well as the hardware itself (like Ethernet).
The TCP/IP model, more commonly known as the Internet protocol suite, is another layering model that is simpler and has been widely adopted.It defines the four separate layers, some of which overlap with the OSI model:
• Application: In this model, the application layer is responsible for creating and transmitting user data between applications. The applications can be on remote systems, and should appear to operate as if locally to the end user.
The communication takes place between peers network.
• Transport: The transport layer is responsible for communication between processes. This level of networking utilizes ports to address different services. It can build up unreliable or reliable connections depending on the type of protocol used.
• Internet: The internet layer is used to transport data from node to node in a network. This layer is aware of the endpoints of the connections, but does not worry about the actual connection needed to get from one place to another. IP addresses are defined in this layer as a way of reaching remote systems in an addressable manner.
• Link: The link layer implements the actual topology of the local network that allows the internet layer to present an addressable interface. It establishes connections between neighboring nodes to send data.
## Interfaces
**Interfaces** are networking communication points for your computer. Each interface is associated with a physical or virtual networking device. Typically, your server will have one configurable network interface for each Ethernet or wireless internet card you have. In addition, it will define a virtual network interface called the "loopback" or localhost interface. This is used as an interface to connect applications and processes on a single computer to other applications and processes. You can see this referenced as the "lo" interface in many tools.
## Network Protocols
Networking works by piggybacks on a number of different protocols on top of each other. In this way, one piece of data can be transmitted using multiple protocols encapsulated within one another.
**Media Access Control(MAC)** is a communications protocol that is used to distinguish specific devices. Each device is supposed to get a unique MAC address during the manufacturing process that differentiates it from every other device on the internet. Addressing hardware by the MAC address allows you to reference a device by a unique value even when the software on top may change the name for that specific device during operation. Media access control is one of the only protocols from the link layer that you are likely to interact with on a regular basis.
**The IP protocol** is one of the fundamental protocols that allow the internet to work. IP addresses are unique on each network and they allow machines to address each other across a network. It is implemented on the internet layer in the IP/TCP model. Networks can be linked together, but traffic must be routed when crossing network boundaries. This protocol assumes an unreliable network and multiple paths to the same destination that it can dynamically change between. There are a number of different implementations of the protocol. The most common implementation today is IPv4, although IPv6 is growing in popularity as an alternative due to the scarcity of IPv4 addresses available and improvements in the protocols capabilities.
**ICMP: internet control message protocol** is used to send messages between devices to indicate the availability or error conditions. These packets are used in a variety of network diagnostic tools, such as ping and traceroute. Usually ICMP packets are transmitted when a packet of a different kind meets some kind of a problem. Basically, they are used as a feedback mechanism for network communications.
**TCP: Transmission control protocol** is implemented in the transport layer of the IP/TCP model and is used to establish reliable connections. TCP is one of the protocols that encapsulates data into packets. It then transfers these to the remote end of the connection using the methods available on the lower layers. On the other end, it can check for errors, request certain pieces to be resent, and reassemble the information into one logical piece to send to the application layer. The protocol builds up a connection prior to data transfer using a system called a three-way handshake. This is a way for the two ends of the communication to acknowledge the request and agree upon a method of ensuring data reliability. After the data has been sent, the connection is torn down using a similar four-way handshake. TCP is the protocol of choice for many of the most popular uses for the internet, including WWW, FTP, SSH, and email. It is safe to say that the internet we know today would not be here without TCP.
**UDP: User datagram protocol** is a popular companion protocol to TCP and is also implemented in the transport layer. The fundamental difference between UDP and TCP is that UDP offers unreliable data transfer. It does not verify that data has been received on the other end of the connection. This might sound like a bad thing, and for many purposes, it is. However, it is also extremely important for some functions. It’s not required to wait for confirmation that the data was received and forced to resend data, UDP is much faster than TCP. It does not establish a connection with the remote host, it simply fires off the data to that host and doesn't care if it is accepted or not. Since UDP is a simple transaction, it is useful for simple communications like querying for network resources. It also doesn't maintain a state, which makes it great for transmitting data from one machine to many real-time clients. This makes it ideal for VOIP, games, and other applications that cannot afford delays.
**HTTP: Hypertext transfer protocol** is a protocol defined in the application layer that forms the basis for communication on the web. HTTP defines a number of functions that tell the remote system what you are requesting. For instance, GET, POST, and DELETE all interact with the requested data in a different way.
**FTP: File transfer protocol** is in the application layer and provides a way of transferring complete files from one host to another. It is inherently insecure, so it is not recommended for any externally facing network unless it is implemented as a public, download-only resource.
**DNS: Domain name system** is an application layer protocol used to provide a human-friendly naming mechanism for internet resources. It is what ties a domain name to an IP address and allows you to access sites by name in your browser.
**SSH: Secure shell** is an encrypted protocol implemented in the application layer that can be used to communicate with a remote server in a secure way. Many additional technologies are built around this protocol because of its end-to-end encryption and ubiquity. There are many other protocols that we haven't covered that are equally important. However, this should give you a good overview of some of the fundamental technologies that make the internet and networking possible.
[JSON Web Token (JWT)](https://jwt.io) is a compact URL-safe means of representing claims to be transferred between two parties. The claims in a JWT are encoded as a JSON object that is digitally signed using JSON Web Signature (JWS).
[OAuth 2.0](https://oauth.net/2/) is an open source authorization framework that enables applications to obtain limited access to user accounts on an HTTP service, such as Amazon, Google, Facebook, Microsoft, Twitter GitHub, and DigitalOcean. It works by delegating user authentication to the service that hosts the user account, and authorizing third-party applications to access the user account.
## Virtualization
[HVM (Hardware Virtual Machine)](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/virtualization_types.html) is a virtualization type that provides the ability to run an operating system directly on top of a virtual machine without any modification, as if it were run on the bare-metal hardware.
[PV(ParaVirtualization)](https://wiki.xenproject.org/wiki/Paravirtualization_(PV)) is an efficient and lightweight virtualization technique introduced by the Xen Project team, later adopted by other virtualization solutions. PV does not require virtualization extensions from the host CPU and thus enables virtualization on hardware architectures that do not support Hardware-assisted virtualization.
[KVM (for Kernel-based Virtual Machine)](https://www.linux-kvm.org/page/Main_Page) is a full virtualization solution for Linux on x86 hardware containing virtualization extensions (Intel VT or AMD-V). It consists of a loadable kernel module, kvm.ko, that provides the core virtualization infrastructure and a processor specific module, kvm-intel.ko or kvm-amd.ko.
[QEMU](https://www.qemu.org) is a fast processor emulator using a portable dynamic translator. QEMU emulates a full system, including a processor and various peripherals. It can be used to launch a different Operating System without rebooting the PC or to debug system code.
[Hyper-V](https://docs.microsoft.com/en-us/virtualization/hyper-v-on-windows/) enables running virtualized computer systems on top of a physical host. These virtualized systems can be used and managed just as if they were physical computer systems, however they exist in virtualized and isolated environment. Special software called a hypervisor manages access between the virtual systems and the physical hardware resources. Virtualization enables quick deployment of computer systems, a way to quickly restore systems to a previously known good state, and the ability to migrate systems between physical hosts.
[VirtManager](https://github.com/virt-manager/virt-manager) is a graphical tool for managing virtual machines via libvirt. Most usage is with QEMU/KVM virtual machines, but Xen and libvirt LXC containers are well supported. Common operations for any libvirt driver should work.
[oVirt](https://www.ovirt.org) is an open-source distributed virtualization solution, designed to manage your entire enterprise infrastructure. oVirt uses the trusted KVM hypervisor and is built upon several other community projects, including libvirt, Gluster, PatternFly, and Ansible.Founded by Red Hat as a community project on which Red Hat Enterprise Virtualization is based allowing for centralized management of virtual machines, compute, storage and networking resources, from an easy-to-use web-based front-end with platform independent access.
[HyperKit](https://github.com/moby/hyperkit) is a toolkit for embedding hypervisor capabilities in your application. It includes a complete hypervisor, based on [xhyve](https://github.com/mist64/xhyve)/[bhyve](https://bhyve.org/), which is optimized for lightweight virtual machines and container deployment. It is designed to be interfaced with higher-level components such as the [VPNKit](https://github.com/moby/vpnkit) and [DataKit](https://github.com/moby/datakit). HyperKit currently only supports macOS using the [Hypervisor.framework](https://developer.apple.com/library/mac/documentation/DriversKernelHardware/Reference/Hypervisor/index.html) making it a core component of Docker Desktop for Mac.
[Intel® Graphics Virtualization Technology (Intel® GVT)](https://github.com/intel/gvt-linux) is a full GPU virtualization solution with mediated pass-through, starting from 4th generation Intel Core (TM) processors with Intel processor graphics(Broadwell and newer). It can be used to virtualize the GPU for multiple guest virtual machines, effectively providing near-native graphics performance in the virtual machine and still letting your host use the virtualized GPU normally.
[Apple Hypervisor](https://developer.apple.com/documentation/hypervisor) is a frameowrk that builds virtualization solutions on top of a lightweight hypervisor, without third-party kernel extensions. Hypervisor provides C APIs so you can interact with virtualization technologies in user space, without writing kernel extensions (KEXTs). As a result, the apps you create using this framework are suitable for distribution on the [Mac App Store](https://www.appstore.com/).
[Apple Virtualization Framework](https://developer.apple.com/documentation/virtualization) is a framework that provides high-level APIs for creating and managing virtual machines on Apple silicon and Intel-based Mac computers. This framework is used to boot and run a Linux-based operating system in a custom environment that you define. It also supports the [Virtio specification](https://www.redhat.com/en/virtio-networking-series), which defines standard interfaces for many device types, including network, socket, serial port, storage, entropy, and memory-balloon devices.
[Apple Paravirtualized Graphics Framework](https://developer.apple.com/documentation/paravirtualizedgraphics) is a framework that implements hardware-accelerated graphics for macOS running in a virtual machine, hereafter known as the guest. The operating system provides a graphics driver that runs inside the guest, communicating with the framework in the host operating system to take advantage of Metal-accelerated graphics.
[Cloud Hypervisor](https://github.com/cloud-hypervisor/cloud-hypervisor) is an open source Virtual Machine Monitor (VMM) that runs on top of [KVM](https://www.kernel.org/doc/Documentation/virtual/kvm/api.txt). The project focuses on exclusively running modern, cloud workloads, on top of a limited set of hardware architectures and platforms. Cloud workloads refers to those that are usually run by customers inside a cloud provider. Cloud Hypervisor is implemented in [Rust](https://www.rust-lang.org/) and is based on the [rust-vmm](https://github.com/rust-vmm) crates.
[VMware vSphere Hypervisor](https://www.vmware.com/products/vsphere-hypervisor.html) is a bare-metal hypervisor that virtualizes servers; allowing you to consolidate your applications while saving time and money managing your IT infrastructure.
[Xen](https://github.com/xen-project/xen) is focused on advancing virtualization in a number of different commercial and open source applications, including server virtualization, Infrastructure as a Services (IaaS), desktop virtualization, security applications, embedded and hardware appliances, and automotive/aviation.
[Ganeti](https://github.com/ganeti/ganeti) is a virtual machine cluster management tool built on top of existing virtualization technologies such as Xen or KVM and other open source software. Once installed, the tool assumes management of the virtual instances (Xen DomU).
[Packer](https://www.packer.io/) is an open source tool for creating identical machine images for multiple platforms from a single source configuration. Packer is lightweight, runs on every major operating system, and is highly performant, creating machine images for multiple platforms in parallel. Packer does not replace configuration management like Chef or Puppet. In fact, when building images, Packer is able to use tools like Chef or Puppet to install software onto the image.
[Vagrant](https://www.vagrantup.com/) is a tool for building and managing virtual machine environments in a single workflow. With an easy-to-use workflow and focus on automation, Vagrant lowers development environment setup time, increases production parity, and makes the "works on my machine" excuse a relic of the past. It provides easy to configure, reproducible, and portable work environments built on top of industry-standard technology and controlled by a single consistent workflow to help maximize the productivity and flexibility of you and your team.
[Parallels Desktop](https://www.parallels.com) is a Desktop Hypervisor that delivers the fastest, easiest and most powerful application for running Windows/Linux on Mac (including the new [Apple M1 chip](https://www.apple.com/newsroom/2020/11/apple-unleashes-m1/)) and ChromeOS.
[VMware Fusion](https://www.vmware.com/products/fusion.html) is a Desktop Hypervisor that deliver desktop and ‘server’ virtual machines, containers and [Kubernetes clusters](https://www.vmware.com/topics/glossary/content/kubernetes-cluster) to developers, and IT professionals on the Mac.
[VMware Workstation](https://www.vmware.com/products/workstation-pro.html) is a hosted hypervisor that runs on x64 versions of Windows and Linux operating systems; it enables users to set up virtual machines on a single physical machine, and use them simultaneously along with the actual machine.
## File systems & Storage
[NAS (Network Attached Storage)](https://www.synology.com/en-us/solution/what_is_nas) is an intelligent storage device connected to your home or office network. You can store all your family and colleagues' files on the NAS, from important documents to precious photos, music and video collections.
[GlusterFS](https://www.gluster.org/) is a free and open source scalable network filesystem. Gluster is a scalable network filesystem. Using common off-the-shelf hardware, you can create large, distributed storage solutions for media streaming, data analysis, and other data- and bandwidth-intensive tasks.
[Ceph](https://ceph.io/) is a software-defined storage solution designed to address the object, block, and file storage needs of data centers adopting open source as the new norm for high-growth block storage, object stores and data lakes. Ceph provides enterprise scalable storage while keeping [CAPEX](https://corporatefinanceinstitute.com/resources/knowledge/modeling/how-to-calculate-capex-formula/) and [OPEX](https://www.investopedia.com/terms/o/operating_expense.asp) costs in line with underlying bulk commodity disk prices.
[ZFS](https://docs.oracle.com/cd/E19253-01/819-5461/zfsover-2/) is an enterprise-ready open source file system and volume manager with unprecedented flexibility and an uncompromising commitment to data integrity.
[OpenZFS](https://openzfs.org/wiki/Main_Page )is an open-source storage platform. It includes the functionality of both traditional file systems and volume manager. It has many advanced features including:
- Protection against data corruption.
- Integrity checking for both data and metadata.
- Continuous integrity verification and automatic "self-healing" repair.
[Btrfs](https://btrfs.wiki.kernel.org/index.php/Main_Page) is a modern copy on write (CoW) filesystem for Linux aimed at implementing advanced features while also focusing on fault tolerance, repair and easy administration. Its main features and benefits are:
- Snapshots which do not make the full copy of files
- RAID - support for software-based RAID 0, RAID 1, RAID 10
- Self-healing - checksums for data and metadata, automatic detection of silent data corruptions
[Apple File System (APFS)](https://support.apple.com/guide/disk-utility/file-system-formats-available-in-disk-utility-dsku19ed921c/mac) is the default file system for Mac computers using macOS 10.13 or later, features strong encryption, space sharing, snapshots, fast directory sizing, and improved file system fundamentals.
[NTFS(New Technology File System)](https://docs.microsoft.com/en-us/windows-server/storage/file-server/ntfs-overview) is the primary file system for recent versions of Windows and Windows Server—provides a full set of features including security descriptors, encryption, disk quotas, and rich metadata, and can be used with Cluster Shared Volumes (CSV) to provide continuously available volumes that can be accessed simultaneously from multiple nodes of a failover cluster.
[exFAT(Extended File Allocation Table )](https://docs.microsoft.com/en-us/windows/win32/fileio/exfat-specification) is the file system that was the successor to FAT32 in the FAT family of file systems. It was optimized for flash memory such as USB flash drives and SD cards.
# Telco 5G Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

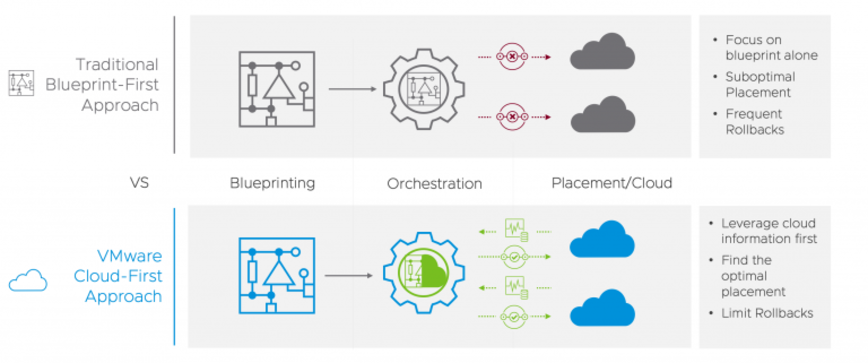
**VMware Cloud First Approach. Source: [VMware](https://www.vmware.com/products/telco-cloud-automation.html).**

**VMware Telco Cloud Automation Components. Source: [VMware](https://www.vmware.com/products/telco-cloud-automation.html).**
## Telco 5G Learning Resources
[HPE(Hewlett Packard Enterprise) Telco Blueprints overview](https://techhub.hpe.com/eginfolib/servers/docs/Telco/Blueprints/infocenter/index.html#GUID-9906A227-C1FB-4FD5-A3C3-F3B72EC81CAB.html)
[Network Functions Virtualization Infrastructure (NFVI) by Cisco](https://www.cisco.com/c/en/us/solutions/service-provider/network-functions-virtualization-nfv-infrastructure/index.html)
[Introduction to vCloud NFV Telco Edge from VMware](https://docs.vmware.com/en/VMware-vCloud-NFV-OpenStack-Edition/3.1/vloud-nfv-edge-reference-arch-31/GUID-744C45F1-A8D5-4523-9E5E-EAF6336EE3A0.html)
[VMware Telco Cloud Automation(TCA) Architecture Overview](https://docs.vmware.com/en/VMware-Telco-Cloud-Platform-5G-Edition/1.0/telco-cloud-platform-5G-edition-reference-architecture/GUID-C19566B3-F42D-4351-BA55-DE70D55FB0DD.html)
[5G Telco Cloud from VMware](https://telco.vmware.com/)
[Maturing OpenStack Together To Solve Telco Needs from Red Hat](https://www.redhat.com/cms/managed-files/4.Nokia%20CloudBand%20&%20Red%20Hat%20-%20Maturing%20Openstack%20together%20to%20solve%20Telco%20needs%20Ehud%20Malik,%20Senior%20PLM,%20Nokia%20CloudBand.pdf)
[Red Hat telco ecosystem program](https://connect.redhat.com/en/programs/telco-ecosystem)
[OpenStack for Telcos by Canonical](https://ubuntu.com/blog/openstack-for-telcos-by-canonical)
[Open source NFV platform for 5G from Ubuntu](https://ubuntu.com/telco)
[Understanding 5G Technology from Verizon](https://www.verizon.com/5g/)
[Verizon and Unity partner to enable 5G & MEC gaming and enterprise applications](https://www.verizon.com/about/news/verizon-unity-partner-5g-mec-gaming-enterprise)
[Understanding 5G Technology from Intel](https://www.intel.com/content/www/us/en/wireless-network/what-is-5g.html)
[Understanding 5G Technology from Qualcomm](https://www.qualcomm.com/invention/5g/what-is-5g)
[Telco Acceleration with Xilinx](https://www.xilinx.com/applications/wired-wireless/telco.html)
[VIMs on OSM Public Wiki](https://osm.etsi.org/wikipub/index.php/VIMs)
[Amazon EC2 Overview and Networking Introduction for Telecom Companies](https://docs.aws.amazon.com/whitepapers/latest/ec2-networking-for-telecom/ec2-networking-for-telecom.pdf)
[Citrix Certified Associate – Networking(CCA-N)](http://training.citrix.com/cms/index.php/certification/networking/)
[Citrix Certified Professional – Virtualization(CCP-V)](https://www.globalknowledge.com/us-en/training/certification-prep/brands/citrix/section/virtualization/citrix-certified-professional-virtualization-ccp-v/)
[CCNP Routing and Switching](https://learningnetwork.cisco.com/s/ccnp-enterprise)
[Certified Information Security Manager(CISM)](https://www.isaca.org/credentialing/cism)
[Wireshark Certified Network Analyst (WCNA)](https://www.wiresharktraining.com/certification.html)
[Juniper Networks Certification Program Enterprise (JNCP)](https://www.juniper.net/us/en/training/certification/)
[Cloud Native Computing Foundation Training and Certification Program](https://www.cncf.io/certification/training/)
## Telco 5G Tools and Frameworks
[Open Stack](https://www.openstack.org/) is an open source cloud platform, deployed as infrastructure-as-a-service (IaaS) to orchestrate data center operations on bare metal, private cloud hardware, public cloud resources, or both (hybrid/multi-cloud architecture). OpenStack includes advance use of virtualization & SDN for network traffic optimization to handle the core cloud-computing services of compute, networking, storage, identity, and image services.
[StarlingX](https://www.starlingx.io/) is a complete cloud infrastructure software stack for the edge used by the most demanding applications in industrial IOT, telecom, video delivery and other ultra-low latency use cases.
[Airship](https://www.airshipit.org/) is a collection of open source tools for automating cloud provisioning and management. Airship provides a declarative framework for defining and managing the life cycle of open infrastructure tools and the underlying hardware.
[Network functions virtualization (NFV)](https://www.vmware.com/topics/glossary/content/network-functions-virtualization-nfv) is the replacement of network appliance hardware with virtual machines. The virtual machines use a hypervisor to run networking software and processes such as routing and load balancing. NFV allows for the separation of communication services from dedicated hardware, such as routers and firewalls. This separation means network operations can provide new services dynamically and without installing new hardware. Deploying network components with network functions virtualization only takes hours compared to months like with traditional networking solutions.
[Software Defined Networking (SDN)](https://www.vmware.com/topics/glossary/content/software-defined-networking) is an approach to networking that uses software-based controllers or application programming interfaces (APIs) to communicate with underlying hardware infrastructure and direct traffic on a network. This model differs from that of traditional networks, which use dedicated hardware devices (routers and switches) to control network traffic.
[Virtualized Infrastructure Manager (VIM)](https://www.cisco.com/c/en/us/td/docs/net_mgmt/network_function_virtualization_Infrastructure/3_2_2/install_guide/Cisco_VIM_Install_Guide_3_2_2/Cisco_VIM_Install_Guide_3_2_2_chapter_00.html) is a service delivery and reduce costs with high performance lifecycle management Manage the full lifecycle of the software and hardware comprising your NFV infrastructure (NFVI), and maintaining a live inventory and allocation plan of both physical and virtual resources.
[Management and Orchestration(MANO)](https://www.etsi.org/technologies/open-source-mano) is an ETSI-hosted initiative to develop an Open Source NFV Management and Orchestration (MANO) software stack aligned with ETSI NFV. Two of the key components of the ETSI NFV architectural framework are the NFV Orchestrator and VNF Manager, known as NFV MANO.
[Magma](https://www.magmacore.org/) is an open source software platform that gives network operators an open, flexible and extendable mobile core network solution. Their mission is to connect the world to a faster network by enabling service providers to build cost-effective and extensible carrier-grade networks. Magma is 3GPP generation (2G, 3G, 4G or upcoming 5G networks) and access network agnostic (cellular or WiFi). It can flexibly support a radio access network with minimal development and deployment effort.
[OpenRAN](https://open-ran.org/) is an intelligent Radio Access Network(RAN) integrated on general purpose platforms with open interface between software defined functions. Open RANecosystem enables enormous flexibility and interoperability with a complete openess to multi-vendor deployments.
[Open vSwitch(OVS)](https://www.openvswitch.org/)is an open source production quality, multilayer virtual switch licensed under the open source Apache 2.0 license. It is designed to enable massive network automation through programmatic extension, while still supporting standard management interfaces and protocols (NetFlow, sFlow, IPFIX, RSPAN, CLI, LACP, 802.1ag).
[Edge](https://www.ibm.com/cloud/what-is-edge-computing) is a distributed computing framework that brings enterprise applications closer to data sources such as IoT devices or local edge servers. This proximity to data at its source can deliver strong business benefits, including faster insights, improved response times and better bandwidth availability.
[Multi-access edge computing (MEC)](https://www.etsi.org/technologies/multi-access-edge-computing) is an Industry Specification Group (ISG) within ETSI to create a standardized, open environment which will allow the efficient and seamless integration of applications from vendors, service providers, and third-parties across multi-vendor Multi-access Edge Computing platforms.
[Virtualized network functions(VNFs)](https://www.juniper.net/documentation/en_US/cso4.1/topics/concept/nsd-vnf-overview.html) is a software application used in a Network Functions Virtualization (NFV) implementation that has well defined interfaces, and provides one or more component networking functions in a defined way. For example, a security VNF provides Network Address Translation (NAT) and firewall component functions.
[Cloud-Native Network Functions(CNF)](https://www.cncf.io/announcements/2020/11/18/cloud-native-network-functions-conformance-launched-by-cncf/) is a network function designed and implemented to run inside containers. CNFs inherit all the cloud native architectural and operational principles including Kubernetes(K8s) lifecycle management, agility, resilience, and observability.
[Physical Network Function(PNF)](https://www.mpirical.com/glossary/pnf-physical-network-function) is a physical network node which has not undergone virtualization. Both PNFs and VNFs (Virtualized Network Functions) can be used to form an overall Network Service.
[Network functions virtualization infrastructure(NFVI)](https://docs.vmware.com/en/VMware-vCloud-NFV/2.0/vmware-vcloud-nfv-reference-architecture-20/GUID-FBEA6C6B-54D8-4A37-87B1-D825F9E0DBC7.html) is the foundation of the overall NFV architecture. It provides the physical compute, storage, and networking hardware that hosts the VNFs. Each NFVI block can be thought of as an NFVI node and many nodes can be deployed and controlled geographically.
# Cloud Native
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## Cloud Native Development
## DevOps
**Application Framework**
[Spring Boot](https://spring.io/projects/spring-boot) is an open-source micro framework maintained by Pivotal, which was acquired by VMware in 2019. It provides Java developers with a platform to get started with an auto configurable production-grade Spring application.
[Apache Mesos](http://mesos.apache.org/) is a cluster manager that provides efficient resource isolation and sharing across distributed applications, or frameworks. It can run Hadoop, Jenkins, Spark, Aurora, and other frameworks on a dynamically shared pool of nodes.
[Apache Spark](https://spark.apache.org/) is a unified analytics engine for big data processing, with built-in modules for streaming, SQL, machine learning and graph processing.
[Apache Hadoop](http://hadoop.apache.org/) is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
**Runtime Platform**
[BOSH](https://www.cloudfoundry.org/bosh/) is a tool that prepares your infrastructure for what needs to be managed. BOSH espouses software engineering best practices, such as continuous delivery, by making it easy to create software releases that automatically update complex distributed systems with simple commands.Due to the flexibility and power of BOSH, Google and VMware made it the heart of the Kubo project, now called the Cloud Foundry Container Runtime, based on Kubernetes.
**Infrastructure Automatation**
[Maven](https://maven.apache.org/) is a build automation tool used primarily for Java projects. Maven can also be used to build and manage projects written in C#, Ruby, Scala, and other languages. The Maven project is hosted by the Apache Software Foundation.
[Gradle](https://gradle.org/) is an open-source build-automation system that builds upon the concepts of Apache Ant and Apache Maven and introduces a Groovy-based domain-specific language instead of the XML form used by Apache Maven for declaring the project configuration.
[Chef](https://www.chef.io/) is an effortless Infrastructure Suite offers visibility into security and compliance status across all infrastructure and makes it easy to detect and correct issues long before they reach production.
[Puppet](https://puppet.com/) is an open source tool that makes continuous integration and delivery of your software on traditional or containerized infrastructure easy by pulling together all your existing tools and giving you flexibility to deploy your way.
[Ansible](https://www.ansible.com/) is an open-source software provisioning, configuration management, and application-deployment tool. It runs on many Unix-like systems, and can configure both Unix-like systems as well as Microsoft Windows.
[Salt](https://www.saltstack.com/) is Python-based, open-source software for event-driven IT automation, remote task execution, and configuration management. Supporting the "Infrastructure as Code" approach to data center system and network deployment and management, configuration automation, SecOps orchestration, vulnerability remediation, and hybrid cloud control.
[Terraform](https://www.terraform.io/) is an open-source infrastructure as code software tool created by HashiCorp.It enables users to define and provision a datacenter infrastructure using a high-level configuration language known as Hashicorp Configuration Language (HCL), or optionally JSON.
**Cloud Infrastructure**
[Amazon web service(AWS)](https://aws.amazon.com) is a platform that offers flexible, reliable, scalable, easy-to-use and cost-effective cloud computing solutions. The AWS platform is developed with a combination of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS) offerings.
[Microsoft Azure](https://azure.microsoft.com/en-us/) is a cloud computing service created by Microsoft for building, testing, deploying, and managing applications and services through Microsoft-managed data centers.
[Azure DevOps](https://azure.microsoft.com/en-us/services/devops/?nav=min) is a set of services for teams to share code, track work, and ship software; CLIs Build, deploy, diagnose, and manage multi-platform, scalable apps and services; Azure Pipelines Continuously build, test, and deploy to any platform and cloud; Azure Lab Services Set up labs for classrooms, trials, development and testing, and other scenarios.
[Azure Draft](https://draft.sh/) is a tool for developers to create cloud-native applications on Kubernetes.
[Google Cloud Platform](https://cloud.google.com/) integrates industry-leading tools(data management, hybrid & multi-cloud, and AI & ML) with Cloud Storage for enhanced support with everything from security and data transfer, to data backup and archive. Expand all . Backup, archival, and disaster recovery. Along with File systems and gateways.
[OpenStack](https://www.openstack.org/) is a free and open-source software platform for cloud computing, mostly deployed as infrastructure-as-a-service that controls large pools of compute, storage, and networking resources throughout a datacenter, managed through a dashboard or via the OpenStack API. OpenStack works with popular enterprise and open source technologies making it ideal for heterogeneous infrastructure.
[Cloud Foundry](https://www.cloudfoundry.org/) is an open source, multi cloud application platform as a service that makes it faster and easier to build, test, deploy and scale applications, providing a choice of clouds, developer frameworks, and application services. It is an open source project and is available through a variety of private cloud distributions and public cloud instances.
## Continuous Integration/Continuous Delivery
[Bamboo](https://www.atlassian.com/software/bamboo) is a continuous integration (CI) server that can be used to automate the release management for a software application, creating a continuous delivery pipeline.
[Drone](https://drone.io/) is a Continuous Delivery system built on container technology. Drone uses a simple YAML configuration file, a superset of docker-compose, to define and execute Pipelines inside Docker containers.
[Travis CI](https://travis-ci.org/) is a hosted continuous integration service used to build and test software projects hosted at GitHub.
[Circle CI](https://circleci.com/) is a continuous integration and continuous delivery platform that helps software teams work smarter, faster.
[Team City](https://www.jetbrains.com/teamcity/) is a build management and continuous integration server from JetBrains.
[Shippable](https://www.shippable.com/) simplifies DevOps and makes it systematic with an Assembly Line platform that is heterogeneous, flexible, and provides complete visibility across your DevOps workflows.
[Spinnaker](https://www.spinnaker.io/) is an open source, multi-cloud continuous delivery platform for releasing software changes with high velocity and confidence.
[Prow](https://jenkins-x.io/docs/reference/components/prow/) is a Kubernetes based CI/CD system. Jobs can be triggered by various types of events and report their status to many different services. In addition to job execution, Prow provides GitHub automation in the form of policy enforcement, chat-ops via /foo style commands, and automatic PR merging. Prow has a microservice architecture implemented as a collection of container images that run as Kubernetes deployments.
## Microservices
[AWS ECS](https://aws.amazon.com/ecs/) is a highly scalable, high-performance container orchestration service that supports Docker containers and allows you to easily run and scale containerized applications on AWS. Amazon ECS eliminates the need for you to install and operate your own container orchestration software, manage and scale a cluster of virtual machines, or schedule containers on those virtual machines.
[AWS CodeBuild](https://aws.amazon.com/codebuild/) is a fully managed continuous integration service that compiles source code, runs tests, and produces software packages that are ready to deploy. With CodeBuild, you don't need to provision, manage, and scale your own build servers.
[CFEngine](https://cfengine.com/) is an open-source configuration management system, written by Mark Burgess.Its primary function is to provide automated configuration and maintenance of large-scale computer systems, including the unified management of servers, desktops, consumer and industrial devices, embedded networked devices, mobile smartphones, and tablet computers.
[Octpus Deploy](https://octopus.com/) is the deployment automation server for your entire team, designed to make it easy to orchestrate releases and deploy applications, whether on-premises or in the cloud.
[AWS CodeDeploy](https://aws.amazon.com/codedeploy/) is a fully managed deployment service that automates software deployments to a variety of compute services such as Amazon EC2, AWS Fargate, AWS Lambda, and your on-premises servers. AWS CodeDeploy makes it easier for you to rapidly release new features, helps you avoid downtime during application deployment, and handles the complexity of updating your applications.
[AWS Lambda](https://aws.amazon.com/lambda/) is an event-driven, serverless computing platform provided by Amazon as a part of the Amazon Web Services. It is a computing service that runs code in response to events and automatically manages the computing resources required by that code.
[Traefik](https://traefik.io/traefik/) is an open-source Edge Router that makes publishing your services a fun and easy experience. It receives requests on behalf of your system and finds out which components are responsible for handling them. What sets Traefik apart, besides its many features, is that it automatically discovers the right configuration for your services.
## Containers
[Kubernetes](https://kubernetes.io/) is an open-source container-orchestration system for automating application deployment, scaling, and management. It was originally designed by Google, and is now maintained by the Cloud Native Computing Foundation.
[Google Kubernetes Engine (GKE)](https://cloud.google.com/kubernetes-engine/) is a managed, production-ready environment for deploying containerized applications.
[OpenShift](https://www.openshift.com/) is focused on security at every level of the container stack and throughout the application lifecycle. It includes long-term, enterprise support from one of the leading Kubernetes contributors and open source software companies.
[Rancher](https://rancher.com/) is a complete software stack for teams adopting containers. It addresses the operational and security challenges of managing multiple Kubernetes clusters, while providing DevOps teams with integrated tools for running containerized workloads.
[Docker](https://www.docker.com/) is a set of platform as a service products that use OS-level virtualization to deliver software in packages called containers. Containers are isolated from one another and bundle their own software, libraries and configuration files; they can communicate with each other through well-defined channels. All containers are run by a single operating-system kernel and are thus more lightweight than virtual machines.
[Rook](https://rook.io/) is an open source cloud-native storage orchestrator for Kubernetes that turns distributed storage systems into self-managing, self-scaling, self-healing storage services. It automates the tasks of a storage administrator: deployment, bootstrapping, configuration, provisioning, scaling, upgrading, migration, disaster recovery, monitoring, and resource management.
[Rkt](https://coreos.com/rkt/) is a pod-native container engine for Linux. It is composable, secure, and built on standards.
[Open Container Initiative](https://opencontainers.org/about/overview/) is an open governance structure for the express purpose of creating open industry standards around container formats and runtimes.
[Buildah](https://buildah.io/) is a command line tool to build Open Container Initiative (OCI) images. It can be used with Docker, Podman, Kubernetes.
[Podman](https://podman.io/) is a daemonless, open source, Linux native tool designed to make it easy to find, run, build, share and deploy applications using Open Containers Initiative (OCI) Containers and Container Images. Podman provides a command line interface (CLI) familiar to anyone who has used the Docker Container Engine.
[Containerd](https://containerd.io) is a daemon that manages the complete container lifecycle of its host system, from image transfer and storage to container execution and supervision to low-level storage to network attachments and beyond. It is available for Linux and Windows.

**Container Architecture. Source: [Containerd.io](https://containerd.io)**
## Cloud Native Learning Resources
[CNCF Cloud Native Interactive Landscape](https://landscape.cncf.io/)
[Build Cloud-Native applications in Microsoft Azure](https://azure.microsoft.com/en-us/overview/cloudnative/)
[Cloud-Native application development for Google Cloud](https://cloud.google.com/solutions/cloud-native-app-development?hl=he)
[Cloud-Native development for Amazon Web Services](https://aws.amazon.com/blogs/apn/journey-to-being-cloud-native-how-and-where-should-you-start/)
[Cloud Native Computing Foundation Training and Certification Program](https://www.cncf.io/certification/training/)
[Cloud Foundry Developer Training and Certification Program](https://www.cloudfoundry.org/get-started/)
[Cloud-Native Architecture Course on Pluralsight](https://www.pluralsight.com/courses/cloud-native-architecture-big-picture)
[AWS Fundamentals: Going Cloud-Native on Coursera](https://www.coursera.org/learn/aws-fundamentals-going-cloud-native)
[Developing Cloud-Native Apps w/ Microservices Architectures course on Udemy](https://www.udemy.com/course/developing-cloud-native-applications-microservices-architectures/)
[How load balancing works for cloud native applications with Azure Application Gateway on Linkedin Learning](https://www.linkedin.com/learning/azure-for-developers-optimize-with-azure-application-gateway/how-load-balancing-works-for-cloud-native-applications)
[Developing Cloud Native Applications course on edX](https://www.edx.org/course/developing-cloud-native-applications)
[Cloud Native courses from IBM](https://www.ibm.com/cloud/learn/cloud-native)
# Machine Learning
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## Learning Resources for ML
[Machine Learning](https://www.ibm.com/cloud/learn/machine-learning) is a branch of artificial intelligence (AI) focused on building apps using algorithms that learn from data models and improve their accuracy over time without needing to be programmed.
[Machine Learning by Stanford University from Coursera](https://www.coursera.org/learn/machine-learning)
[AWS Training and Certification for Machine Learning (ML) Courses](https://aws.amazon.com/training/learning-paths/machine-learning/)
[Machine Learning Scholarship Program for Microsoft Azure from Udacity](https://www.udacity.com/scholarships/machine-learning-scholarship-microsoft-azure)
[Microsoft Certified: Azure Data Scientist Associate](https://docs.microsoft.com/en-us/learn/certifications/azure-data-scientist)
[Microsoft Certified: Azure AI Engineer Associate](https://docs.microsoft.com/en-us/learn/certifications/azure-ai-engineer)
[Azure Machine Learning training and deployment](https://docs.microsoft.com/en-us/azure/devops/pipelines/targets/azure-machine-learning)
[Learning Machine learning and artificial intelligence from Google Cloud Training](https://cloud.google.com/training/machinelearning-ai)
[Machine Learning Crash Course for Google Cloud](https://developers.google.com/machine-learning/crash-course/)
[JupyterLab](https://jupyterlab.readthedocs.io/)
[Scheduling Jupyter notebooks on Amazon SageMaker ephemeral instances](https://aws.amazon.com/blogs/machine-learning/scheduling-jupyter-notebooks-on-sagemaker-ephemeral-instances/)
[How to run Jupyter Notebooks in your Azure Machine Learning workspace](https://docs.microsoft.com/en-us/azure/machine-learning/how-to-run-jupyter-notebooks)
[Machine Learning Courses Online from Udemy](https://www.udemy.com/topic/machine-learning/)
[Machine Learning Courses Online from Coursera](https://www.coursera.org/courses?query=machine%20learning&)
[Learn Machine Learning with Online Courses and Classes from edX](https://www.edx.org/learn/machine-learning)
## ML Frameworks, Libraries, and Tools
[TensorFlow](https://www.tensorflow.org) is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML powered applications.
[Keras](https://keras.io) is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano.It was developed with a focus on enabling fast experimentation. It is capable of running on top of TensorFlow, Microsoft Cognitive Toolkit, R, Theano, or PlaidML.
[PyTorch](https://pytorch.org) is a library for deep learning on irregular input data such as graphs, point clouds, and manifolds. Primarily developed by Facebook's AI Research lab.
[Amazon SageMaker](https://aws.amazon.com/sagemaker/) is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models.
[Azure Databricks](https://azure.microsoft.com/en-us/services/databricks/) is a fast and collaborative Apache Spark-based big data analytics service designed for data science and data engineering. Azure Databricks, sets up your Apache Spark environment in minutes, autoscale, and collaborate on shared projects in an interactive workspace. Azure Databricks supports Python, Scala, R, Java, and SQL, as well as data science frameworks and libraries including TensorFlow, PyTorch, and scikit-learn.
[Microsoft Cognitive Toolkit (CNTK)](https://docs.microsoft.com/en-us/cognitive-toolkit/) is an open-source toolkit for commercial-grade distributed deep learning. It describes neural networks as a series of computational steps via a directed graph. CNTK allows the user to easily realize and combine popular model types such as feed-forward DNNs, convolutional neural networks (CNNs) and recurrent neural networks (RNNs/LSTMs). CNTK implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers.
[Apple CoreML](https://developer.apple.com/documentation/coreml) is a framework that helps integrate machine learning models into your app. Core ML provides a unified representation for all models. Your app uses Core ML APIs and user data to make predictions, and to train or fine-tune models, all on the user's device. A model is the result of applying a machine learning algorithm to a set of training data. You use a model to make predictions based on new input data.
[Tensorflow_macOS](https://github.com/apple/tensorflow_macos) is a Mac-optimized version of TensorFlow and TensorFlow Addons for macOS 11.0+ accelerated using Apple's ML Compute framework.
[Apache OpenNLP](https://opennlp.apache.org/) is an open-source library for a machine learning based toolkit used in the processing of natural language text. It features an API for use cases like [Named Entity Recognition](https://en.wikipedia.org/wiki/Named-entity_recognition), [Sentence Detection](), [POS(Part-Of-Speech) tagging](https://en.wikipedia.org/wiki/Part-of-speech_tagging), [Tokenization](https://en.wikipedia.org/wiki/Tokenization_(data_security)) [Feature extraction](https://en.wikipedia.org/wiki/Feature_extraction), [Chunking](https://en.wikipedia.org/wiki/Chunking_(psychology)), [Parsing](https://en.wikipedia.org/wiki/Parsing), and [Coreference resolution](https://en.wikipedia.org/wiki/Coreference).
[Apache Airflow](https://airflow.apache.org) is an open-source workflow management platform created by the community to programmatically author, schedule and monitor workflows. Install. Principles. Scalable. Airflow has a modular architecture and uses a message queue to orchestrate an arbitrary number of workers. Airflow is ready to scale to infinity.
[Open Neural Network Exchange(ONNX)](https://github.com/onnx) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types.
[Apache MXNet](https://mxnet.apache.org/) is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scaling effectively to multiple GPUs and multiple machines. Support for Python, R, Julia, Scala, Go, Javascript and more.
[AutoGluon](https://autogluon.mxnet.io/index.html) is toolkit for Deep learning that automates machine learning tasks enabling you to easily achieve strong predictive performance in your applications. With just a few lines of code, you can train and deploy high-accuracy deep learning models on tabular, image, and text data.
[Anaconda](https://www.anaconda.com/) is a very popular Data Science platform for machine learning and deep learning that enables users to develop models, train them, and deploy them.
[PlaidML](https://github.com/plaidml/plaidml) is an advanced and portable tensor compiler for enabling deep learning on laptops, embedded devices, or other devices where the available computing hardware is not well supported or the available software stack contains unpalatable license restrictions.
[OpenCV](https://opencv.org) is a highly optimized library with focus on real-time computer vision applications. The C++, Python, and Java interfaces support Linux, MacOS, Windows, iOS, and Android.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a Python module for machine learning built on top of SciPy, NumPy, and matplotlib, making it easier to apply robust and simple implementations of many popular machine learning algorithms.
[Weka](https://www.cs.waikato.ac.nz/ml/weka/) is an open source machine learning software that can be accessed through a graphical user interface, standard terminal applications, or a Java API. It is widely used for teaching, research, and industrial applications, contains a plethora of built-in tools for standard machine learning tasks, and additionally gives transparent access to well-known toolboxes such as scikit-learn, R, and Deeplearning4j.
[Caffe](https://github.com/BVLC/caffe) is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) and community contributors.
[Theano](https://github.com/Theano/Theano) is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently including tight integration with NumPy.
[nGraph](https://github.com/NervanaSystems/ngraph) is an open source C++ library, compiler and runtime for Deep Learning. The nGraph Compiler aims to accelerate developing AI workloads using any deep learning framework and deploying to a variety of hardware targets.It provides the freedom, performance, and ease-of-use to AI developers.
[NVIDIA cuDNN](https://developer.nvidia.com/cudnn) is a GPU-accelerated library of primitives for [deep neural networks](https://developer.nvidia.com/deep-learning). cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN accelerates widely used deep learning frameworks, including [Caffe2](https://caffe2.ai/), [Chainer](https://chainer.org/), [Keras](https://keras.io/), [MATLAB](https://www.mathworks.com/solutions/deep-learning.html), [MxNet](https://mxnet.incubator.apache.org/), [PyTorch](https://pytorch.org/), and [TensorFlow](https://www.tensorflow.org/).
[Jupyter Notebook](https://jupyter.org/) is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Jupyter is used widely in industries that do data cleaning and transformation, numerical simulation, statistical modeling, data visualization, data science, and machine learning.
[Apache Spark](https://spark.apache.org/) is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.
[Apache Spark Connector for SQL Server and Azure SQL](https://github.com/microsoft/sql-spark-connector) is a high-performance connector that enables you to use transactional data in big data analytics and persists results for ad-hoc queries or reporting. The connector allows you to use any SQL database, on-premises or in the cloud, as an input data source or output data sink for Spark jobs.
[Apache PredictionIO](https://predictionio.apache.org/) is an open source machine learning framework for developers, data scientists, and end users. It supports event collection, deployment of algorithms, evaluation, querying predictive results via REST APIs. It is based on scalable open source services like Hadoop, HBase (and other DBs), Elasticsearch, Spark and implements what is called a Lambda Architecture.
[Cluster Manager for Apache Kafka(CMAK)](https://github.com/yahoo/CMAK) is a tool for managing [Apache Kafka](https://kafka.apache.org/) clusters.
[BigDL](https://bigdl-project.github.io/) is a distributed deep learning library for Apache Spark. With BigDL, users can write their deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters.
[Eclipse Deeplearning4J (DL4J)](https://deeplearning4j.konduit.ai/) is a set of projects intended to support all the needs of a JVM-based(Scala, Kotlin, Clojure, and Groovy) deep learning application. This means starting with the raw data, loading and preprocessing it from wherever and whatever format it is in to building and tuning a wide variety of simple and complex deep learning networks.
[Tensorman](https://github.com/pop-os/tensorman) is a utility for easy management of Tensorflow containers by developed by [System76]( https://system76.com).Tensorman allows Tensorflow to operate in an isolated environment that is contained from the rest of the system. This virtual environment can operate independent of the base system, allowing you to use any version of Tensorflow on any version of a Linux distribution that supports the Docker runtime.
[Numba](https://github.com/numba/numba) is an open source, NumPy-aware optimizing compiler for Python sponsored by Anaconda, Inc. It uses the LLVM compiler project to generate machine code from Python syntax. Numba can compile a large subset of numerically-focused Python, including many NumPy functions. Additionally, Numba has support for automatic parallelization of loops, generation of GPU-accelerated code, and creation of ufuncs and C callbacks.
[Chainer](https://chainer.org/) is a Python-based deep learning framework aiming at flexibility. It provides automatic differentiation APIs based on the define-by-run approach (dynamic computational graphs) as well as object-oriented high-level APIs to build and train neural networks. It also supports CUDA/cuDNN using [CuPy](https://github.com/cupy/cupy) for high performance training and inference.
[XGBoost](https://xgboost.readthedocs.io/) is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solve many data science problems in a fast and accurate way. It supports distributed training on multiple machines, including AWS, GCE, Azure, and Yarn clusters. Also, it can be integrated with Flink, Spark and other cloud dataflow systems.
[cuML](https://github.com/rapidsai/cuml) is a suite of libraries that implement machine learning algorithms and mathematical primitives functions that share compatible APIs with other RAPIDS projects. cuML enables data scientists, researchers, and software engineers to run traditional tabular ML tasks on GPUs without going into the details of CUDA programming. In most cases, cuML's Python API matches the API from scikit-learn.
# Algorithms
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)
[Fuzzy logic](https://www.investopedia.com/terms/f/fuzzy-logic.asp) is a heuristic approach that allows for more advanced decision-tree processing and better integration with rules-based programming.
**Architecture of a Fuzzy Logic System. Source: [ResearchGate](https://www.researchgate.net/figure/Architecture-of-a-fuzzy-logic-system_fig2_309452475)**
[Support Vector Machine (SVM)](https://web.stanford.edu/~hastie/MOOC-Slides/svm.pdf) is a supervised machine learning model that uses classification algorithms for two-group classification problems.

**Support Vector Machine (SVM). Source:[OpenClipArt](https://openclipart.org/detail/182977/svm-support-vector-machines)**
[Neural networks](https://www.ibm.com/cloud/learn/neural-networks) are a subset of machine learning and are at the heart of deep learning algorithms. The name/structure is inspired by the human brain copying the process that biological neurons/nodes signal to one another.
**Deep neural network. Source: [IBM](https://www.ibm.com/cloud/learn/neural-networks)**
[Convolutional Neural Networks (R-CNN)](https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks) is an object detection algorithm that first segments the image to find potential relevant bounding boxes and then run the detection algorithm to find most probable objects in those bounding boxes.
**Convolutional Neural Networks. Source:[CS231n](https://cs231n.github.io/convolutional-networks/#conv)**
[Recurrent neural networks (RNNs)](https://www.ibm.com/cloud/learn/recurrent-neural-networks) is a type of artificial neural network which uses sequential data or time series data.

**Recurrent Neural Networks. Source: [Slideteam](https://www.slideteam.net/recurrent-neural-networks-rnns-ppt-powerpoint-presentation-file-templates.html)**
[Multilayer Perceptrons (MLPs)](https://deepai.org/machine-learning-glossary-and-terms/multilayer-perceptron) is multi-layer neural networks composed of multiple layers of [perceptrons](https://en.wikipedia.org/wiki/Perceptron) with a threshold activation.

**Multilayer Perceptrons. Source: [DeepAI](https://deepai.org/machine-learning-glossary-and-terms/multilayer-perceptron)**
[Random forest](https://www.ibm.com/cloud/learn/random-forest) is a commonly-used machine learning algorithm, which combines the output of multiple decision trees to reach a single result. A decision tree in a forest cannot be pruned for sampling and therefore, prediction selection. Its ease of use and flexibility have fueled its adoption, as it handles both classification and regression problems.

**Random forest. Source: [wikimedia](https://community.tibco.com/wiki/random-forest-template-tibco-spotfirer-wiki-page)**
[Decision trees](https://www.cs.cmu.edu/~bhiksha/courses/10-601/decisiontrees/) are tree-structured models for classification and regression.

***Decision Trees. Source: [CMU](http://www.cs.cmu.edu/~bhiksha/courses/10-601/decisiontrees/)*
[Naive Bayes](https://en.wikipedia.org/wiki/Naive_Bayes_classifier) is a machine learning algorithm that is used solved calssification problems. It's based on applying [Bayes' theorem](https://www.mathsisfun.com/data/bayes-theorem.html) with strong independence assumptions between the features.

**Bayes' theorem. Source:[mathisfun](https://www.mathsisfun.com/data/bayes-theorem.html)**
# Deep Learning Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## Deep Learning Learning Resources
[Deep Learning](https://www.ibm.com/cloud/learn/deep-learning) is a subset of machine learning, which is essentially a neural network with three or more layers. These neural networks attempt to simulate the behavior of the human brain,though, far from matching its ability. This allows the neural networks to "learn" from large amounts of data. The Learning can be [supervised](https://en.wikipedia.org/wiki/Supervised_learning), [semi-supervised](https://en.wikipedia.org/wiki/Semi-supervised_learning) or [unsupervised](https://en.wikipedia.org/wiki/Unsupervised_learning).
[Deep Learning Online Courses | NVIDIA](https://www.nvidia.com/en-us/training/online/)
[Top Deep Learning Courses Online | Coursera](https://www.coursera.org/courses?query=deep%20learning)
[Top Deep Learning Courses Online | Udemy](https://www.udemy.com/topic/deep-learning/)
[Learn Deep Learning with Online Courses and Lessons | edX](https://www.edx.org/learn/deep-learning)
[Deep Learning Online Course Nanodegree | Udacity](https://www.udacity.com/course/deep-learning-nanodegree--nd101)
[Machine Learning Course by Andrew Ng | Coursera](https://www.coursera.org/learn/machine-learning?)
[Machine Learning Engineering for Production (MLOps) course by Andrew Ng | Coursera](https://www.coursera.org/specializations/machine-learning-engineering-for-production-mlops)
[Data Science: Deep Learning and Neural Networks in Python | Udemy](https://www.udemy.com/course/data-science-deep-learning-in-python/)
[Understanding Machine Learning with Python | Pluralsight ](https://www.pluralsight.com/courses/python-understanding-machine-learning)
[How to Think About Machine Learning Algorithms | Pluralsight](https://www.pluralsight.com/courses/machine-learning-algorithms)
[Deep Learning Courses | Stanford Online](https://online.stanford.edu/courses/cs230-deep-learning)
[Deep Learning - UW Professional & Continuing Education](https://www.pce.uw.edu/courses/deep-learning)
[Deep Learning Online Courses | Harvard University](https://online-learning.harvard.edu/course/deep-learning-0)
[Machine Learning for Everyone Courses | DataCamp](https://www.datacamp.com/courses/introduction-to-machine-learning-with-r)
[Artificial Intelligence Expert Course: Platinum Edition | Udemy](https://www.udemy.com/course/artificial-intelligence-exposed-future-10-extreme-edition/)
[Top Artificial Intelligence Courses Online | Coursera](https://www.coursera.org/courses?query=artificial%20intelligence)
[Learn Artificial Intelligence with Online Courses and Lessons | edX](https://www.edx.org/learn/artificial-intelligence)
[Professional Certificate in Computer Science for Artificial Intelligence | edX](https://www.edx.org/professional-certificate/harvardx-computer-science-for-artifical-intelligence)
[Artificial Intelligence Nanodegree program](https://www.udacity.com/course/ai-artificial-intelligence-nanodegree--nd898)
[Artificial Intelligence (AI) Online Courses | Udacity](https://www.udacity.com/school-of-ai)
[Intro to Artificial Intelligence Course | Udacity](https://www.udacity.com/course/intro-to-artificial-intelligence--cs271)
[Edge AI for IoT Developers Course | Udacity](https://www.udacity.com/course/intel-edge-ai-for-iot-developers-nanodegree--nd131)
[Reasoning: Goal Trees and Rule-Based Expert Systems | MIT OpenCourseWare](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-034-artificial-intelligence-fall-2010/lecture-videos/lecture-3-reasoning-goal-trees-and-rule-based-expert-systems/)
[Expert Systems and Applied Artificial Intelligence](https://www.umsl.edu/~joshik/msis480/chapt11.htm)
[Autonomous Systems - Microsoft AI](https://www.microsoft.com/en-us/ai/autonomous-systems)
[Introduction to Microsoft Project Bonsai](https://docs.microsoft.com/en-us/learn/autonomous-systems/intro-to-project-bonsai/)
[Machine teaching with the Microsoft Autonomous Systems platform](https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/autonomous-systems)
[Autonomous Maritime Systems Training | AMC Search](https://www.amcsearch.com.au/ams-training)
[Top Autonomous Cars Courses Online | Udemy](https://www.udemy.com/topic/autonomous-cars/)
[Applied Control Systems 1: autonomous cars: Math + PID + MPC | Udemy](https://www.udemy.com/course/applied-systems-control-for-engineers-modelling-pid-mpc/)
[Learn Autonomous Robotics with Online Courses and Lessons | edX](https://www.edx.org/learn/autonomous-robotics)
[Artificial Intelligence Nanodegree program](https://www.udacity.com/course/ai-artificial-intelligence-nanodegree--nd898)
[Autonomous Systems Online Courses & Programs | Udacity](https://www.udacity.com/school-of-autonomous-systems)
[Edge AI for IoT Developers Course | Udacity](https://www.udacity.com/course/intel-edge-ai-for-iot-developers-nanodegree--nd131)
[Autonomous Systems MOOC and Free Online Courses | MOOC List](https://www.mooc-list.com/tags/autonomous-systems)
[Robotics and Autonomous Systems Graduate Program | Standford Online](https://online.stanford.edu/programs/robotics-and-autonomous-systems-graduate-program)
[Mobile Autonomous Systems Laboratory | MIT OpenCourseWare](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-186-mobile-autonomous-systems-laboratory-january-iap-2005/lecture-notes/)
## Deep Learning Tools, Libraries, and Frameworks
[NVIDIA cuDNN](https://developer.nvidia.com/cudnn) is a GPU-accelerated library of primitives for [deep neural networks](https://developer.nvidia.com/deep-learning). cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN accelerates widely used deep learning frameworks, including [Caffe2](https://caffe2.ai/), [Chainer](https://chainer.org/), [Keras](https://keras.io/), [MATLAB](https://www.mathworks.com/solutions/deep-learning.html), [MxNet](https://mxnet.incubator.apache.org/), [PyTorch](https://pytorch.org/), and [TensorFlow](https://www.tensorflow.org/).
[NVIDIA DLSS (Deep Learning Super Sampling)](https://developer.nvidia.com/dlss) is a temporal image upscaling AI rendering technology that increases graphics performance using dedicated Tensor Core AI processors on GeForce RTX™ GPUs. DLSS uses the power of a deep learning neural network to boost frame rates and generate beautiful, sharp images for your games.
[AMD FidelityFX Super Resolution (FSR)](https://www.amd.com/en/technologies/radeon-software-fidelityfx) is an open source, high-quality solution for producing high resolution frames from lower resolution inputs. It uses a collection of cutting-edge Deep Learning algorithms with a particular emphasis on creating high-quality edges, giving large performance improvements compared to rendering at native resolution directly. FSR enables “practical performance” for costly render operations, such as hardware ray tracing for the AMD RDNA™ and AMD RDNA™ 2 architectures.
[Intel Xe Super Sampling (XeSS)](https://www.youtube.com/watch?v=Y9hfpf-SqEg) is a temporal image upscaling AI rendering technology that increases graphics performance similar to NVIDIA's [DLSS (Deep Learning Super Sampling)](https://developer.nvidia.com/dlss). Intel's Arc GPU architecture (early 2022) will have GPUs that feature dedicated Xe-cores to run XeSS. The GPUs will have Xe Matrix eXtenstions matrix (XMX) engines for hardware-accelerated AI processing. XeSS will be able to run on devices without XMX, including integrated graphics, though, the performance of XeSS will be lower on non-Intel graphics cards because it will be powered by [DP4a instruction](https://www.intel.com/content/dam/www/public/us/en/documents/reference-guides/11th-gen-quick-reference-guide.pdf).
[Jupyter Notebook](https://jupyter.org/) is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Jupyter is used widely in industries that do data cleaning and transformation, numerical simulation, statistical modeling, data visualization, data science, and machine learning.
[Apache Spark](https://spark.apache.org/) is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.
[Apache Spark Connector for SQL Server and Azure SQL](https://github.com/microsoft/sql-spark-connector) is a high-performance connector that enables you to use transactional data in big data analytics and persists results for ad-hoc queries or reporting. The connector allows you to use any SQL database, on-premises or in the cloud, as an input data source or output data sink for Spark jobs.
[Apache PredictionIO](https://predictionio.apache.org/) is an open source machine learning framework for developers, data scientists, and end users. It supports event collection, deployment of algorithms, evaluation, querying predictive results via REST APIs. It is based on scalable open source services like Hadoop, HBase (and other DBs), Elasticsearch, Spark and implements what is called a Lambda Architecture.
[Cluster Manager for Apache Kafka(CMAK)](https://github.com/yahoo/CMAK) is a tool for managing [Apache Kafka](https://kafka.apache.org/) clusters.
[BigDL](https://bigdl-project.github.io/) is a distributed deep learning library for Apache Spark. With BigDL, users can write their deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters.
[Eclipse Deeplearning4J (DL4J)](https://deeplearning4j.konduit.ai/) is a set of projects intended to support all the needs of a JVM-based(Scala, Kotlin, Clojure, and Groovy) deep learning application. This means starting with the raw data, loading and preprocessing it from wherever and whatever format it is in to building and tuning a wide variety of simple and complex deep learning networks.
[Deep Learning Toolbox™](https://www.mathworks.com/products/deep-learning.html) is a tool that provides a framework for designing and implementing deep neural networks with algorithms, pretrained models, and apps. You can use convolutional neural networks (ConvNets, CNNs) and long short-term memory (LSTM) networks to perform classification and regression on image, time-series, and text data. You can build network architectures such as generative adversarial networks (GANs) and Siamese networks using automatic differentiation, custom training loops, and shared weights. With the Deep Network Designer app, you can design, analyze, and train networks graphically. It can exchange models with TensorFlow™ and PyTorch through the ONNX format and import models from TensorFlow-Keras and Caffe. The toolbox supports transfer learning with DarkNet-53, ResNet-50, NASNet, SqueezeNet and many other pretrained models.
[Reinforcement Learning Toolbox™](https://www.mathworks.com/products/reinforcement-learning.html) is a tool that provides an app, functions, and a Simulink® block for training policies using reinforcement learning algorithms, including DQN, PPO, SAC, and DDPG. You can use these policies to implement controllers and decision-making algorithms for complex applications such as resource allocation, robotics, and autonomous systems.
[Deep Learning HDL Toolbox™](https://www.mathworks.com/products/deep-learning-hdl.html) is a tool that provides functions and tools to prototype and implement deep learning networks on FPGAs and SoCs. It provides pre-built bitstreams for running a variety of deep learning networks on supported Xilinx® and Intel® FPGA and SoC devices. Profiling and estimation tools let you customize a deep learning network by exploring design, performance, and resource utilization tradeoffs.
[Parallel Computing Toolbox™](https://www.mathworks.com/products/matlab-parallel-server.html) is a tool that lets you solve computationally and data-intensive problems using multicore processors, GPUs, and computer clusters. High-level constructs such as parallel for-loops, special array types, and parallelized numerical algorithms enable you to parallelize MATLAB® applications without CUDA or MPI programming. The toolbox lets you use parallel-enabled functions in MATLAB and other toolboxes. You can use the toolbox with Simulink® to run multiple simulations of a model in parallel. Programs and models can run in both interactive and batch modes.
[XGBoost](https://xgboost.readthedocs.io/) is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solve many data science problems in a fast and accurate way. It supports distributed training on multiple machines, including AWS, GCE, Azure, and Yarn clusters. Also, it can be integrated with Flink, Spark and other cloud dataflow systems.
[LIBSVM](https://www.csie.ntu.edu.tw/~cjlin/libsvm/) is an integrated software for support vector classification, (C-SVC, nu-SVC), regression (epsilon-SVR, nu-SVR) and distribution estimation (one-class SVM). It supports multi-class classification.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a simple and efficient tool for data mining and data analysis. It is built on NumPy,SciPy, and mathplotlib.
[TensorFlow](https://www.tensorflow.org) is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML powered applications.
[Keras](https://keras.io) is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano.It was developed with a focus on enabling fast experimentation. It is capable of running on top of TensorFlow, Microsoft Cognitive Toolkit, R, Theano, or PlaidML.
[PyTorch](https://pytorch.org) is a library for deep learning on irregular input data such as graphs, point clouds, and manifolds. Primarily developed by Facebook's AI Research lab.
[Azure Databricks](https://azure.microsoft.com/en-us/services/databricks/) is a fast and collaborative Apache Spark-based big data analytics service designed for data science and data engineering. Azure Databricks, sets up your Apache Spark environment in minutes, autoscale, and collaborate on shared projects in an interactive workspace. Azure Databricks supports Python, Scala, R, Java, and SQL, as well as data science frameworks and libraries including TensorFlow, PyTorch, and scikit-learn.
[Microsoft Cognitive Toolkit (CNTK)](https://docs.microsoft.com/en-us/cognitive-toolkit/) is an open-source toolkit for commercial-grade distributed deep learning. It describes neural networks as a series of computational steps via a directed graph. CNTK allows the user to easily realize and combine popular model types such as feed-forward DNNs, convolutional neural networks (CNNs) and recurrent neural networks (RNNs/LSTMs). CNTK implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers.
[Tensorflow_macOS](https://github.com/apple/tensorflow_macos) is a Mac-optimized version of TensorFlow and TensorFlow Addons for macOS 11.0+ accelerated using Apple's ML Compute framework.
[Apache Airflow](https://airflow.apache.org) is an open-source workflow management platform created by the community to programmatically author, schedule and monitor workflows. Install. Principles. Scalable. Airflow has a modular architecture and uses a message queue to orchestrate an arbitrary number of workers. Airflow is ready to scale to infinity.
[Open Neural Network Exchange(ONNX)](https://github.com/onnx) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types.
[Apache MXNet](https://mxnet.apache.org/) is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scaling effectively to multiple GPUs and multiple machines. Support for Python, R, Julia, Scala, Go, Javascript and more.
[AutoGluon](https://autogluon.mxnet.io/index.html) is toolkit for Deep learning that automates machine learning tasks enabling you to easily achieve strong predictive performance in your applications. With just a few lines of code, you can train and deploy high-accuracy deep learning models on tabular, image, and text data.
[Anaconda](https://www.anaconda.com/) is a very popular Data Science platform for machine learning and deep learning that enables users to develop models, train them, and deploy them.
[PlaidML](https://github.com/plaidml/plaidml) is an advanced and portable tensor compiler for enabling deep learning on laptops, embedded devices, or other devices where the available computing hardware is not well supported or the available software stack contains unpalatable license restrictions.
[OpenCV](https://opencv.org) is a highly optimized library with focus on real-time computer vision applications. The C++, Python, and Java interfaces support Linux, MacOS, Windows, iOS, and Android.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a Python module for machine learning built on top of SciPy, NumPy, and matplotlib, making it easier to apply robust and simple implementations of many popular machine learning algorithms.
[Weka](https://www.cs.waikato.ac.nz/ml/weka/) is an open source machine learning software that can be accessed through a graphical user interface, standard terminal applications, or a Java API. It is widely used for teaching, research, and industrial applications, contains a plethora of built-in tools for standard machine learning tasks, and additionally gives transparent access to well-known toolboxes such as scikit-learn, R, and Deeplearning4j.
[Caffe](https://github.com/BVLC/caffe) is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) and community contributors.
[Theano](https://github.com/Theano/Theano) is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently including tight integration with NumPy.
[Microsoft Project Bonsai](https://azure.microsoft.com/en-us/services/project-bonsai/) is a low-code AI platform that speeds AI-powered automation development and part of the Autonomous Systems suite from Microsoft. Bonsai is used to build AI components that can provide operator guidance or make independent decisions to optimize process variables, improve production efficiency, and reduce downtime.
[Microsoft AirSim](https://microsoft.github.io/AirSim/lidar.html) is a simulator for drones, cars and more, built on Unreal Engine (with an experimental Unity release). AirSim is open-source, cross platform, and supports [software-in-the-loop simulation](https://www.mathworks.com/help///ecoder/software-in-the-loop-sil-simulation.html) with popular flight controllers such as PX4 & ArduPilot and [hardware-in-loop](https://www.ni.com/en-us/innovations/white-papers/17/what-is-hardware-in-the-loop-.html) with PX4 for physically and visually realistic simulations. It is developed as an Unreal plugin that can simply be dropped into any Unreal environment. AirSim is being developed as a platform for AI research to experiment with deep learning, computer vision and reinforcement learning algorithms for autonomous vehicles.
[CARLA](https://github.com/carla-simulator/carla) is an open-source simulator for autonomous driving research. CARLA has been developed from the ground up to support development, training, and validation of autonomous driving systems. In addition to open-source code and protocols, CARLA provides open digital assets (urban layouts, buildings, vehicles) that were created for this purpose and can be used freely.
[ROS/ROS2 bridge for CARLA(package)](https://github.com/carla-simulator/ros-bridge) is a bridge that enables two-way communication between ROS and CARLA. The information from the CARLA server is translated to ROS topics. In the same way, the messages sent between nodes in ROS get translated to commands to be applied in CARLA.
[ROS Toolbox](https://www.mathworks.com/products/ros.html) is a tool that provides an interface connecting MATLAB® and Simulink® with the Robot Operating System (ROS and ROS 2), enabling you to create a network of ROS nodes. The toolbox includes MATLAB functions and Simulink blocks to import, analyze, and play back ROS data recorded in rosbag files. You can also connect to a live ROS network to access ROS messages.
[Robotics Toolbox™](https://www.mathworks.com/products/robotics.html) provides a toolbox that brings robotics specific functionality(designing, simulating, and testing manipulators, mobile robots, and humanoid robots) to MATLAB, exploiting the native capabilities of MATLAB (linear algebra, portability, graphics). The toolbox also supports mobile robots with functions for robot motion models (bicycle), path planning algorithms (bug, distance transform, D*, PRM), kinodynamic planning (lattice, RRT), localization (EKF, particle filter), map building (EKF) and simultaneous localization and mapping (EKF), and a Simulink model a of non-holonomic vehicle. The Toolbox also including a detailed Simulink model for a quadrotor flying robot.
[Image Processing Toolbox™](https://www.mathworks.com/products/image.html) is a tool that provides a comprehensive set of reference-standard algorithms and workflow apps for image processing, analysis, visualization, and algorithm development. You can perform image segmentation, image enhancement, noise reduction, geometric transformations, image registration, and 3D image processing.
[Computer Vision Toolbox™](https://www.mathworks.com/products/computer-vision.html) is a tool that provides algorithms, functions, and apps for designing and testing computer vision, 3D vision, and video processing systems. You can perform object detection and tracking, as well as feature detection, extraction, and matching. You can automate calibration workflows for single, stereo, and fisheye cameras. For 3D vision, the toolbox supports visual and point cloud SLAM, stereo vision, structure from motion, and point cloud processing.
[Robotics Toolbox™](https://www.mathworks.com/products/robotics.html) is a tool that provides a toolbox that brings robotics specific functionality(designing, simulating, and testing manipulators, mobile robots, and humanoid robots) to MATLAB, exploiting the native capabilities of MATLAB (linear algebra, portability, graphics). The toolbox also supports mobile robots with functions for robot motion models (bicycle), path planning algorithms (bug, distance transform, D*, PRM), kinodynamic planning (lattice, RRT), localization (EKF, particle filter), map building (EKF) and simultaneous localization and mapping (EKF), and a Simulink model a of non-holonomic vehicle. The Toolbox also including a detailed Simulink model for a quadrotor flying robot.
[Model Predictive Control Toolbox™](https://www.mathworks.com/products/model-predictive-control.html) is a tool that provides functions, an app, and Simulink® blocks for designing and simulating controllers using linear and nonlinear model predictive control (MPC). The toolbox lets you specify plant and disturbance models, horizons, constraints, and weights. By running closed-loop simulations, you can evaluate controller performance.
[Predictive Maintenance Toolbox™](https://www.mathworks.com/products/predictive-maintenance.html) is a tool that lets you manage sensor data, design condition indicators, and estimate the remaining useful life (RUL) of a machine. The toolbox provides functions and an interactive app for exploring, extracting, and ranking features using data-based and model-based techniques, including statistical, spectral, and time-series analysis.
[Vision HDL Toolbox™](https://www.mathworks.com/products/vision-hdl.html) is a tool that provides pixel-streaming algorithms for the design and implementation of vision systems on FPGAs and ASICs. It provides a design framework that supports a diverse set of interface types, frame sizes, and frame rates. The image processing, video, and computer vision algorithms in the toolbox use an architecture appropriate for HDL implementations.
[Automated Driving Toolbox™](https://www.mathworks.com/products/automated-driving.html) is a MATLAB tool that provides algorithms and tools for designing, simulating, and testing ADAS and autonomous driving systems. You can design and test vision and lidar perception systems, as well as sensor fusion, path planning, and vehicle controllers. Visualization tools include a bird’s-eye-view plot and scope for sensor coverage, detections and tracks, and displays for video, lidar, and maps. The toolbox lets you import and work with HERE HD Live Map data and OpenDRIVE® road networks. It also provides reference application examples for common ADAS and automated driving features, including FCW, AEB, ACC, LKA, and parking valet. The toolbox supports C/C++ code generation for rapid prototyping and HIL testing, with support for sensor fusion, tracking, path planning, and vehicle controller algorithms.
[UAV Toolbox](https://www.mathworks.com/products/uav.html) is an application that provides tools and reference applications for designing, simulating, testing, and deploying unmanned aerial vehicle (UAV) and drone applications. You can design autonomous flight algorithms, UAV missions, and flight controllers. The Flight Log Analyzer app lets you interactively analyze 3D flight paths, telemetry information, and sensor readings from common flight log formats.
[Navigation Toolbox™](https://www.mathworks.com/products/navigation.html) is a tool that provides algorithms and analysis tools for motion planning, simultaneous localization and mapping (SLAM), and inertial navigation. The toolbox includes customizable search and sampling-based path planners, as well as metrics for validating and comparing paths. You can create 2D and 3D map representations, generate maps using SLAM algorithms, and interactively visualize and debug map generation with the SLAM map builder app.
[Lidar Toolbox™](https://www.mathworks.com/products/lidar.html) is a tool that provides algorithms, functions, and apps for designing, analyzing, and testing lidar processing systems. You can perform object detection and tracking, semantic segmentation, shape fitting, lidar registration, and obstacle detection. Lidar Toolbox supports lidar-camera cross calibration for workflows that combine computer vision and lidar processing.
[Mapping Toolbox™](https://www.mathworks.com/products/mapping.html) is a tool that provides algorithms and functions for transforming geographic data and creating map displays. You can visualize your data in a geographic context, build map displays from more than 60 map projections, and transform data from a variety of sources into a consistent geographic coordinate system.
# Reinforcement Learning Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## Reinforcement Learning Learning Resources
[Reinforcement Learning](https://www.ibm.com/cloud/learn/deep-learning#toc-deep-learn-md_Q_Of3) is a subset of machine learning, which is a neural network with three or more layers. These neural networks attempt to simulate the behavior of the human brain,though, far from matching its ability. This allows the neural networks to "learn" from a process in which a model learns to become more accurate for performing an action in an environment based on feedback in order to maximize the reward. The Learning can be [supervised](https://en.wikipedia.org/wiki/Supervised_learning), [semi-supervised](https://en.wikipedia.org/wiki/Semi-supervised_learning) or [unsupervised](https://en.wikipedia.org/wiki/Unsupervised_learning).
[Top Reinforcement Learning Courses | Coursera](https://www.coursera.org/courses?query=reinforcement%20learning)
[Top Reinforcement Learning Courses | Udemy](https://www.udemy.com/topic/reinforcement-learning/)
[Top Reinforcement Learning Courses | Udacity](https://www.udacity.com/course/reinforcement-learning--ud600)
[Reinforcement Learning Courses | Stanford Online](https://online.stanford.edu/courses/xcs234-reinforcement-learning)
[Deep Learning Online Courses | NVIDIA](https://www.nvidia.com/en-us/training/online/)
[Top Deep Learning Courses Online | Coursera](https://www.coursera.org/courses?query=deep%20learning)
[Top Deep Learning Courses Online | Udemy](https://www.udemy.com/topic/deep-learning/)
[Learn Deep Learning with Online Courses and Lessons | edX](https://www.edx.org/learn/deep-learning)
[Deep Learning Online Course Nanodegree | Udacity](https://www.udacity.com/course/deep-learning-nanodegree--nd101)
[Machine Learning Course by Andrew Ng | Coursera](https://www.coursera.org/learn/machine-learning?)
[Machine Learning Engineering for Production (MLOps) course by Andrew Ng | Coursera](https://www.coursera.org/specializations/machine-learning-engineering-for-production-mlops)
[Data Science: Deep Learning and Neural Networks in Python | Udemy](https://www.udemy.com/course/data-science-deep-learning-in-python/)
[Understanding Machine Learning with Python | Pluralsight ](https://www.pluralsight.com/courses/python-understanding-machine-learning)
[How to Think About Machine Learning Algorithms | Pluralsight](https://www.pluralsight.com/courses/machine-learning-algorithms)
[Deep Learning Courses | Stanford Online](https://online.stanford.edu/courses/cs230-deep-learning)
[Deep Learning - UW Professional & Continuing Education](https://www.pce.uw.edu/courses/deep-learning)
[Deep Learning Online Courses | Harvard University](https://online-learning.harvard.edu/course/deep-learning-0)
[Machine Learning for Everyone Courses | DataCamp](https://www.datacamp.com/courses/introduction-to-machine-learning-with-r)
[Artificial Intelligence Expert Course: Platinum Edition | Udemy](https://www.udemy.com/course/artificial-intelligence-exposed-future-10-extreme-edition/)
[Top Artificial Intelligence Courses Online | Coursera](https://www.coursera.org/courses?query=artificial%20intelligence)
[Learn Artificial Intelligence with Online Courses and Lessons | edX](https://www.edx.org/learn/artificial-intelligence)
[Professional Certificate in Computer Science for Artificial Intelligence | edX](https://www.edx.org/professional-certificate/harvardx-computer-science-for-artifical-intelligence)
[Artificial Intelligence Nanodegree program](https://www.udacity.com/course/ai-artificial-intelligence-nanodegree--nd898)
[Artificial Intelligence (AI) Online Courses | Udacity](https://www.udacity.com/school-of-ai)
[Intro to Artificial Intelligence Course | Udacity](https://www.udacity.com/course/intro-to-artificial-intelligence--cs271)
[Edge AI for IoT Developers Course | Udacity](https://www.udacity.com/course/intel-edge-ai-for-iot-developers-nanodegree--nd131)
[Reasoning: Goal Trees and Rule-Based Expert Systems | MIT OpenCourseWare](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-034-artificial-intelligence-fall-2010/lecture-videos/lecture-3-reasoning-goal-trees-and-rule-based-expert-systems/)
[Expert Systems and Applied Artificial Intelligence](https://www.umsl.edu/~joshik/msis480/chapt11.htm)
[Autonomous Systems - Microsoft AI](https://www.microsoft.com/en-us/ai/autonomous-systems)
[Introduction to Microsoft Project Bonsai](https://docs.microsoft.com/en-us/learn/autonomous-systems/intro-to-project-bonsai/)
[Machine teaching with the Microsoft Autonomous Systems platform](https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/autonomous-systems)
[Autonomous Maritime Systems Training | AMC Search](https://www.amcsearch.com.au/ams-training)
[Top Autonomous Cars Courses Online | Udemy](https://www.udemy.com/topic/autonomous-cars/)
[Applied Control Systems 1: autonomous cars: Math + PID + MPC | Udemy](https://www.udemy.com/course/applied-systems-control-for-engineers-modelling-pid-mpc/)
[Learn Autonomous Robotics with Online Courses and Lessons | edX](https://www.edx.org/learn/autonomous-robotics)
[Artificial Intelligence Nanodegree program](https://www.udacity.com/course/ai-artificial-intelligence-nanodegree--nd898)
[Autonomous Systems Online Courses & Programs | Udacity](https://www.udacity.com/school-of-autonomous-systems)
[Edge AI for IoT Developers Course | Udacity](https://www.udacity.com/course/intel-edge-ai-for-iot-developers-nanodegree--nd131)
[Autonomous Systems MOOC and Free Online Courses | MOOC List](https://www.mooc-list.com/tags/autonomous-systems)
[Robotics and Autonomous Systems Graduate Program | Standford Online](https://online.stanford.edu/programs/robotics-and-autonomous-systems-graduate-program)
[Mobile Autonomous Systems Laboratory | MIT OpenCourseWare](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-186-mobile-autonomous-systems-laboratory-january-iap-2005/lecture-notes/)
## Reinforcement Learning Tools, Libraries, and Frameworks
[OpenAI](https://gym.openai.com/) is an open source Python library for developing and comparing reinforcement learning algorithms by providing a standard API to communicate between learning algorithms and environments, as well as a standard set of environments compliant with that API.
[ReinforcementLearning.jl](https://juliareinforcementlearning.org/) is a collection of tools for doing reinforcement learning research in Julia.
[Reinforcement Learning Toolbox™](https://www.mathworks.com/products/reinforcement-learning.html) is a tool that provides an app, functions, and a Simulink® block for training policies using reinforcement learning algorithms, including DQN, PPO, SAC, and DDPG. You can use these policies to implement controllers and decision-making algorithms for complex applications such as resource allocation, robotics, and autonomous systems.
[Amazon SageMaker](https://aws.amazon.com/robomaker/) is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning (ML) models quickly.
[AWS RoboMaker](https://aws.amazon.com/robomaker/) is a service that provides a fully-managed, scalable infrastructure for simulation that customers use for multi-robot simulation and CI/CD integration with regression testing in simulation.
[TensorFlow](https://www.tensorflow.org) is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML powered applications.
[Keras](https://keras.io) is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano.It was developed with a focus on enabling fast experimentation. It is capable of running on top of TensorFlow, Microsoft Cognitive Toolkit, R, Theano, or PlaidML.
[PyTorch](https://pytorch.org) is a library for deep learning on irregular input data such as graphs, point clouds, and manifolds. Primarily developed by Facebook's AI Research lab.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a simple and efficient tool for data mining and data analysis. It is built on NumPy,SciPy, and mathplotlib.
[NVIDIA cuDNN](https://developer.nvidia.com/cudnn) is a GPU-accelerated library of primitives for [deep neural networks](https://developer.nvidia.com/deep-learning). cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN accelerates widely used deep learning frameworks, including [Caffe2](https://caffe2.ai/), [Chainer](https://chainer.org/), [Keras](https://keras.io/), [MATLAB](https://www.mathworks.com/solutions/deep-learning.html), [MxNet](https://mxnet.incubator.apache.org/), [PyTorch](https://pytorch.org/), and [TensorFlow](https://www.tensorflow.org/).
[Jupyter Notebook](https://jupyter.org/) is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Jupyter is used widely in industries that do data cleaning and transformation, numerical simulation, statistical modeling, data visualization, data science, and machine learning.
[Apache Spark](https://spark.apache.org/) is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.
[Apache Spark Connector for SQL Server and Azure SQL](https://github.com/microsoft/sql-spark-connector) is a high-performance connector that enables you to use transactional data in big data analytics and persists results for ad-hoc queries or reporting. The connector allows you to use any SQL database, on-premises or in the cloud, as an input data source or output data sink for Spark jobs.
[Apache PredictionIO](https://predictionio.apache.org/) is an open source machine learning framework for developers, data scientists, and end users. It supports event collection, deployment of algorithms, evaluation, querying predictive results via REST APIs. It is based on scalable open source services like Hadoop, HBase (and other DBs), Elasticsearch, Spark and implements what is called a Lambda Architecture.
[Cluster Manager for Apache Kafka(CMAK)](https://github.com/yahoo/CMAK) is a tool for managing [Apache Kafka](https://kafka.apache.org/) clusters.
[BigDL](https://bigdl-project.github.io/) is a distributed deep learning library for Apache Spark. With BigDL, users can write their deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters.
[Eclipse Deeplearning4J (DL4J)](https://deeplearning4j.konduit.ai/) is a set of projects intended to support all the needs of a JVM-based(Scala, Kotlin, Clojure, and Groovy) deep learning application. This means starting with the raw data, loading and preprocessing it from wherever and whatever format it is in to building and tuning a wide variety of simple and complex deep learning networks.
[Deep Learning Toolbox™](https://www.mathworks.com/products/deep-learning.html) is a tool that provides a framework for designing and implementing deep neural networks with algorithms, pretrained models, and apps. You can use convolutional neural networks (ConvNets, CNNs) and long short-term memory (LSTM) networks to perform classification and regression on image, time-series, and text data. You can build network architectures such as generative adversarial networks (GANs) and Siamese networks using automatic differentiation, custom training loops, and shared weights. With the Deep Network Designer app, you can design, analyze, and train networks graphically. It can exchange models with TensorFlow™ and PyTorch through the ONNX format and import models from TensorFlow-Keras and Caffe. The toolbox supports transfer learning with DarkNet-53, ResNet-50, NASNet, SqueezeNet and many other pretrained models.
[Deep Learning HDL Toolbox™](https://www.mathworks.com/products/deep-learning-hdl.html) is a tool that provides functions and tools to prototype and implement deep learning networks on FPGAs and SoCs. It provides pre-built bitstreams for running a variety of deep learning networks on supported Xilinx® and Intel® FPGA and SoC devices. Profiling and estimation tools let you customize a deep learning network by exploring design, performance, and resource utilization tradeoffs.
[Parallel Computing Toolbox™](https://www.mathworks.com/products/matlab-parallel-server.html) is a tool that lets you solve computationally and data-intensive problems using multicore processors, GPUs, and computer clusters. High-level constructs such as parallel for-loops, special array types, and parallelized numerical algorithms enable you to parallelize MATLAB® applications without CUDA or MPI programming. The toolbox lets you use parallel-enabled functions in MATLAB and other toolboxes. You can use the toolbox with Simulink® to run multiple simulations of a model in parallel. Programs and models can run in both interactive and batch modes.
[XGBoost](https://xgboost.readthedocs.io/) is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solve many data science problems in a fast and accurate way. It supports distributed training on multiple machines, including AWS, GCE, Azure, and Yarn clusters. Also, it can be integrated with Flink, Spark and other cloud dataflow systems.
[LIBSVM](https://www.csie.ntu.edu.tw/~cjlin/libsvm/) is an integrated software for support vector classification, (C-SVC, nu-SVC), regression (epsilon-SVR, nu-SVR) and distribution estimation (one-class SVM). It supports multi-class classification.
[Azure Databricks](https://azure.microsoft.com/en-us/services/databricks/) is a fast and collaborative Apache Spark-based big data analytics service designed for data science and data engineering. Azure Databricks, sets up your Apache Spark environment in minutes, autoscale, and collaborate on shared projects in an interactive workspace. Azure Databricks supports Python, Scala, R, Java, and SQL, as well as data science frameworks and libraries including TensorFlow, PyTorch, and scikit-learn.
[Microsoft Cognitive Toolkit (CNTK)](https://docs.microsoft.com/en-us/cognitive-toolkit/) is an open-source toolkit for commercial-grade distributed deep learning. It describes neural networks as a series of computational steps via a directed graph. CNTK allows the user to easily realize and combine popular model types such as feed-forward DNNs, convolutional neural networks (CNNs) and recurrent neural networks (RNNs/LSTMs). CNTK implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers.
[Tensorflow_macOS](https://github.com/apple/tensorflow_macos) is a Mac-optimized version of TensorFlow and TensorFlow Addons for macOS 11.0+ accelerated using Apple's ML Compute framework.
[Apache Airflow](https://airflow.apache.org) is an open-source workflow management platform created by the community to programmatically author, schedule and monitor workflows. Install. Principles. Scalable. Airflow has a modular architecture and uses a message queue to orchestrate an arbitrary number of workers. Airflow is ready to scale to infinity.
[Open Neural Network Exchange(ONNX)](https://github.com/onnx) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types.
[Apache MXNet](https://mxnet.apache.org/) is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scaling effectively to multiple GPUs and multiple machines. Support for Python, R, Julia, Scala, Go, Javascript and more.
[AutoGluon](https://autogluon.mxnet.io/index.html) is toolkit for Deep learning that automates machine learning tasks enabling you to easily achieve strong predictive performance in your applications. With just a few lines of code, you can train and deploy high-accuracy deep learning models on tabular, image, and text data.
[Anaconda](https://www.anaconda.com/) is a very popular Data Science platform for machine learning and deep learning that enables users to develop models, train them, and deploy them.
[PlaidML](https://github.com/plaidml/plaidml) is an advanced and portable tensor compiler for enabling deep learning on laptops, embedded devices, or other devices where the available computing hardware is not well supported or the available software stack contains unpalatable license restrictions.
[OpenCV](https://opencv.org) is a highly optimized library with focus on real-time computer vision applications. The C++, Python, and Java interfaces support Linux, MacOS, Windows, iOS, and Android.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a Python module for machine learning built on top of SciPy, NumPy, and matplotlib, making it easier to apply robust and simple implementations of many popular machine learning algorithms.
[Weka](https://www.cs.waikato.ac.nz/ml/weka/) is an open source machine learning software that can be accessed through a graphical user interface, standard terminal applications, or a Java API. It is widely used for teaching, research, and industrial applications, contains a plethora of built-in tools for standard machine learning tasks, and additionally gives transparent access to well-known toolboxes such as scikit-learn, R, and Deeplearning4j.
[Caffe](https://github.com/BVLC/caffe) is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) and community contributors.
[Theano](https://github.com/Theano/Theano) is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently including tight integration with NumPy.
[Microsoft Project Bonsai](https://azure.microsoft.com/en-us/services/project-bonsai/) is a low-code AI platform that speeds AI-powered automation development and part of the Autonomous Systems suite from Microsoft. Bonsai is used to build AI components that can provide operator guidance or make independent decisions to optimize process variables, improve production efficiency, and reduce downtime.
[Microsoft AirSim](https://microsoft.github.io/AirSim/lidar.html) is a simulator for drones, cars and more, built on Unreal Engine (with an experimental Unity release). AirSim is open-source, cross platform, and supports [software-in-the-loop simulation](https://www.mathworks.com/help///ecoder/software-in-the-loop-sil-simulation.html) with popular flight controllers such as PX4 & ArduPilot and [hardware-in-loop](https://www.ni.com/en-us/innovations/white-papers/17/what-is-hardware-in-the-loop-.html) with PX4 for physically and visually realistic simulations. It is developed as an Unreal plugin that can simply be dropped into any Unreal environment. AirSim is being developed as a platform for AI research to experiment with deep learning, computer vision and reinforcement learning algorithms for autonomous vehicles.
[CARLA](https://github.com/carla-simulator/carla) is an open-source simulator for autonomous driving research. CARLA has been developed from the ground up to support development, training, and validation of autonomous driving systems. In addition to open-source code and protocols, CARLA provides open digital assets (urban layouts, buildings, vehicles) that were created for this purpose and can be used freely.
[ROS/ROS2 bridge for CARLA(package)](https://github.com/carla-simulator/ros-bridge) is a bridge that enables two-way communication between ROS and CARLA. The information from the CARLA server is translated to ROS topics. In the same way, the messages sent between nodes in ROS get translated to commands to be applied in CARLA.
[ROS Toolbox](https://www.mathworks.com/products/ros.html) is a tool that provides an interface connecting MATLAB® and Simulink® with the Robot Operating System (ROS and ROS 2), enabling you to create a network of ROS nodes. The toolbox includes MATLAB functions and Simulink blocks to import, analyze, and play back ROS data recorded in rosbag files. You can also connect to a live ROS network to access ROS messages.
[Robotics Toolbox™](https://www.mathworks.com/products/robotics.html) provides a toolbox that brings robotics specific functionality(designing, simulating, and testing manipulators, mobile robots, and humanoid robots) to MATLAB, exploiting the native capabilities of MATLAB (linear algebra, portability, graphics). The toolbox also supports mobile robots with functions for robot motion models (bicycle), path planning algorithms (bug, distance transform, D*, PRM), kinodynamic planning (lattice, RRT), localization (EKF, particle filter), map building (EKF) and simultaneous localization and mapping (EKF), and a Simulink model a of non-holonomic vehicle. The Toolbox also including a detailed Simulink model for a quadrotor flying robot.
[Image Processing Toolbox™](https://www.mathworks.com/products/image.html) is a tool that provides a comprehensive set of reference-standard algorithms and workflow apps for image processing, analysis, visualization, and algorithm development. You can perform image segmentation, image enhancement, noise reduction, geometric transformations, image registration, and 3D image processing.
[Computer Vision Toolbox™](https://www.mathworks.com/products/computer-vision.html) is a tool that provides algorithms, functions, and apps for designing and testing computer vision, 3D vision, and video processing systems. You can perform object detection and tracking, as well as feature detection, extraction, and matching. You can automate calibration workflows for single, stereo, and fisheye cameras. For 3D vision, the toolbox supports visual and point cloud SLAM, stereo vision, structure from motion, and point cloud processing.
[Robotics Toolbox™](https://www.mathworks.com/products/robotics.html) is a tool that provides a toolbox that brings robotics specific functionality(designing, simulating, and testing manipulators, mobile robots, and humanoid robots) to MATLAB, exploiting the native capabilities of MATLAB (linear algebra, portability, graphics). The toolbox also supports mobile robots with functions for robot motion models (bicycle), path planning algorithms (bug, distance transform, D*, PRM), kinodynamic planning (lattice, RRT), localization (EKF, particle filter), map building (EKF) and simultaneous localization and mapping (EKF), and a Simulink model a of non-holonomic vehicle. The Toolbox also including a detailed Simulink model for a quadrotor flying robot.
[Model Predictive Control Toolbox™](https://www.mathworks.com/products/model-predictive-control.html) is a tool that provides functions, an app, and Simulink® blocks for designing and simulating controllers using linear and nonlinear model predictive control (MPC). The toolbox lets you specify plant and disturbance models, horizons, constraints, and weights. By running closed-loop simulations, you can evaluate controller performance.
[Predictive Maintenance Toolbox™](https://www.mathworks.com/products/predictive-maintenance.html) is a tool that lets you manage sensor data, design condition indicators, and estimate the remaining useful life (RUL) of a machine. The toolbox provides functions and an interactive app for exploring, extracting, and ranking features using data-based and model-based techniques, including statistical, spectral, and time-series analysis.
[Vision HDL Toolbox™](https://www.mathworks.com/products/vision-hdl.html) is a tool that provides pixel-streaming algorithms for the design and implementation of vision systems on FPGAs and ASICs. It provides a design framework that supports a diverse set of interface types, frame sizes, and frame rates. The image processing, video, and computer vision algorithms in the toolbox use an architecture appropriate for HDL implementations.
[Automated Driving Toolbox™](https://www.mathworks.com/products/automated-driving.html) is a MATLAB tool that provides algorithms and tools for designing, simulating, and testing ADAS and autonomous driving systems. You can design and test vision and lidar perception systems, as well as sensor fusion, path planning, and vehicle controllers. Visualization tools include a bird’s-eye-view plot and scope for sensor coverage, detections and tracks, and displays for video, lidar, and maps. The toolbox lets you import and work with HERE HD Live Map data and OpenDRIVE® road networks. It also provides reference application examples for common ADAS and automated driving features, including FCW, AEB, ACC, LKA, and parking valet. The toolbox supports C/C++ code generation for rapid prototyping and HIL testing, with support for sensor fusion, tracking, path planning, and vehicle controller algorithms.
[Navigation Toolbox™](https://www.mathworks.com/products/navigation.html) is a tool that provides algorithms and analysis tools for motion planning, simultaneous localization and mapping (SLAM), and inertial navigation. The toolbox includes customizable search and sampling-based path planners, as well as metrics for validating and comparing paths. You can create 2D and 3D map representations, generate maps using SLAM algorithms, and interactively visualize and debug map generation with the SLAM map builder app.
[UAV Toolbox](https://www.mathworks.com/products/uav.html) is an application that provides tools and reference applications for designing, simulating, testing, and deploying unmanned aerial vehicle (UAV) and drone applications. You can design autonomous flight algorithms, UAV missions, and flight controllers. The Flight Log Analyzer app lets you interactively analyze 3D flight paths, telemetry information, and sensor readings from common flight log formats.
[Lidar Toolbox™](https://www.mathworks.com/products/lidar.html) is a tool that provides algorithms, functions, and apps for designing, analyzing, and testing lidar processing systems. You can perform object detection and tracking, semantic segmentation, shape fitting, lidar registration, and obstacle detection. Lidar Toolbox supports lidar-camera cross calibration for workflows that combine computer vision and lidar processing.
[Mapping Toolbox™](https://www.mathworks.com/products/mapping.html) is a tool that provides algorithms and functions for transforming geographic data and creating map displays. You can visualize your data in a geographic context, build map displays from more than 60 map projections, and transform data from a variety of sources into a consistent geographic coordinate system.
# Computer Vision Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)
## Computer Vision Learning Resources
[Computer Vision](https://azure.microsoft.com/en-us/overview/what-is-computer-vision/) is a field of Artificial Intelligence (AI) that focuses on enabling computers to identify and understand objects and people in images and videos.
[OpenCV Courses](https://opencv.org/courses/)
[Exploring Computer Vision in Microsoft Azure](https://docs.microsoft.com/en-us/learn/paths/explore-computer-vision-microsoft-azure/)
[Top Computer Vision Courses Online | Coursera](https://www.coursera.org/courses?languages=en&query=computer%20vision)
[Top Computer Vision Courses Online | Udemy](https://www.udemy.com/topic/computer-vision/)
[Learn Computer Vision with Online Courses and Lessons | edX](https://www.edx.org/learn/computer-vision)
[Computer Vision and Image Processing Fundamentals | edX](https://www.edx.org/course/computer-vision-and-image-processing-fundamentals)
[Introduction to Computer Vision Courses | Udacity](https://www.udacity.com/course/introduction-to-computer-vision--ud810)
[Computer Vision Nanodegree program | Udacity](https://www.udacity.com/course/computer-vision-nanodegree--nd891)
[Machine Vision Course |MIT Open Courseware ](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-801-machine-vision-fall-2004/)
[Computer Vision Training Courses | NobleProg](https://www.nobleprog.com/computer-vision-training)
[Visual Computing Graduate Program | Stanford Online](https://online.stanford.edu/programs/visual-computing-graduate-program)
## Computer Vision Tools, Libraries, and Frameworks
[OpenCV](https://opencv.org) is a highly optimized library with focus on real-time computer vision applications. The C++, Python, and Java interfaces support Linux, MacOS, Windows, iOS, and Android.
[Microsoft Cognitive Toolkit (CNTK)](https://docs.microsoft.com/en-us/cognitive-toolkit/) is an open-source toolkit for commercial-grade distributed deep learning. It describes neural networks as a series of computational steps via a directed graph. CNTK allows the user to easily realize and combine popular model types such as feed-forward DNNs, convolutional neural networks (CNNs) and recurrent neural networks (RNNs/LSTMs). CNTK implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a Python module for machine learning built on top of SciPy, NumPy, and matplotlib, making it easier to apply robust and simple implementations of many popular machine learning algorithms.
[NVIDIA cuDNN](https://developer.nvidia.com/cudnn) is a GPU-accelerated library of primitives for [deep neural networks](https://developer.nvidia.com/deep-learning). cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN accelerates widely used deep learning frameworks, including [Caffe2](https://caffe2.ai/), [Chainer](https://chainer.org/), [Keras](https://keras.io/), [MATLAB](https://www.mathworks.com/solutions/deep-learning.html), [MxNet](https://mxnet.incubator.apache.org/), [PyTorch](https://pytorch.org/), and [TensorFlow](https://www.tensorflow.org/).
[Automated Driving Toolbox™](https://www.mathworks.com/products/automated-driving.html) is a MATLAB tool that provides algorithms and tools for designing, simulating, and testing ADAS and autonomous driving systems. You can design and test vision and lidar perception systems, as well as sensor fusion, path planning, and vehicle controllers. Visualization tools include a bird’s-eye-view plot and scope for sensor coverage, detections and tracks, and displays for video, lidar, and maps. The toolbox lets you import and work with HERE HD Live Map data and OpenDRIVE® road networks. It also provides reference application examples for common ADAS and automated driving features, including FCW, AEB, ACC, LKA, and parking valet. The toolbox supports C/C++ code generation for rapid prototyping and HIL testing, with support for sensor fusion, tracking, path planning, and vehicle controller algorithms.
[LRSLibrary](https://github.com/andrewssobral/lrslibrary) is a Low-Rank and Sparse Tools for Background Modeling and Subtraction in Videos. The library was designed for moving object detection in videos, but it can be also used for other computer vision and machine learning problems.
[Image Processing Toolbox™](https://www.mathworks.com/products/image.html) is a tool that provides a comprehensive set of reference-standard algorithms and workflow apps for image processing, analysis, visualization, and algorithm development. You can perform image segmentation, image enhancement, noise reduction, geometric transformations, image registration, and 3D image processing.
[Computer Vision Toolbox™](https://www.mathworks.com/products/computer-vision.html) is a tool that provides algorithms, functions, and apps for designing and testing computer vision, 3D vision, and video processing systems. You can perform object detection and tracking, as well as feature detection, extraction, and matching. You can automate calibration workflows for single, stereo, and fisheye cameras. For 3D vision, the toolbox supports visual and point cloud SLAM, stereo vision, structure from motion, and point cloud processing.
[Statistics and Machine Learning Toolbox™](https://www.mathworks.com/products/statistics.html) is a tool that provides functions and apps to describe, analyze, and model data. You can use descriptive statistics, visualizations, and clustering for exploratory data analysis; fit probability distributions to data; generate random numbers for Monte Carlo simulations, and perform hypothesis tests. Regression and classification algorithms let you draw inferences from data and build predictive models either interactively, using the Classification and Regression Learner apps, or programmatically, using AutoML.
[Lidar Toolbox™](https://www.mathworks.com/products/lidar.html) is a tool that provides algorithms, functions, and apps for designing, analyzing, and testing lidar processing systems. You can perform object detection and tracking, semantic segmentation, shape fitting, lidar registration, and obstacle detection. Lidar Toolbox supports lidar-camera cross calibration for workflows that combine computer vision and lidar processing.
[Mapping Toolbox™](https://www.mathworks.com/products/mapping.html) is a tool that provides algorithms and functions for transforming geographic data and creating map displays. You can visualize your data in a geographic context, build map displays from more than 60 map projections, and transform data from a variety of sources into a consistent geographic coordinate system.
[UAV Toolbox](https://www.mathworks.com/products/uav.html) is an application that provides tools and reference applications for designing, simulating, testing, and deploying unmanned aerial vehicle (UAV) and drone applications. You can design autonomous flight algorithms, UAV missions, and flight controllers. The Flight Log Analyzer app lets you interactively analyze 3D flight paths, telemetry information, and sensor readings from common flight log formats.
[Parallel Computing Toolbox™](https://www.mathworks.com/products/matlab-parallel-server.html) is a tool that lets you solve computationally and data-intensive problems using multicore processors, GPUs, and computer clusters. High-level constructs such as parallel for-loops, special array types, and parallelized numerical algorithms enable you to parallelize MATLAB® applications without CUDA or MPI programming. The toolbox lets you use parallel-enabled functions in MATLAB and other toolboxes. You can use the toolbox with Simulink® to run multiple simulations of a model in parallel. Programs and models can run in both interactive and batch modes.
[Partial Differential Equation Toolbox™](https://www.mathworks.com/products/pde.html) is a tool that provides functions for solving structural mechanics, heat transfer, and general partial differential equations (PDEs) using finite element analysis.
[ROS Toolbox](https://www.mathworks.com/products/ros.html) is a tool that provides an interface connecting MATLAB® and Simulink® with the Robot Operating System (ROS and ROS 2), enabling you to create a network of ROS nodes. The toolbox includes MATLAB functions and Simulink blocks to import, analyze, and play back ROS data recorded in rosbag files. You can also connect to a live ROS network to access ROS messages.
[Robotics Toolbox™](https://www.mathworks.com/products/robotics.html) provides a toolbox that brings robotics specific functionality(designing, simulating, and testing manipulators, mobile robots, and humanoid robots) to MATLAB, exploiting the native capabilities of MATLAB (linear algebra, portability, graphics). The toolbox also supports mobile robots with functions for robot motion models (bicycle), path planning algorithms (bug, distance transform, D*, PRM), kinodynamic planning (lattice, RRT), localization (EKF, particle filter), map building (EKF) and simultaneous localization and mapping (EKF), and a Simulink model a of non-holonomic vehicle. The Toolbox also including a detailed Simulink model for a quadrotor flying robot.
[Deep Learning Toolbox™](https://www.mathworks.com/products/deep-learning.html) is a tool that provides a framework for designing and implementing deep neural networks with algorithms, pretrained models, and apps. You can use convolutional neural networks (ConvNets, CNNs) and long short-term memory (LSTM) networks to perform classification and regression on image, time-series, and text data. You can build network architectures such as generative adversarial networks (GANs) and Siamese networks using automatic differentiation, custom training loops, and shared weights. With the Deep Network Designer app, you can design, analyze, and train networks graphically. It can exchange models with TensorFlow™ and PyTorch through the ONNX format and import models from TensorFlow-Keras and Caffe. The toolbox supports transfer learning with DarkNet-53, ResNet-50, NASNet, SqueezeNet and many other pretrained models.
[Reinforcement Learning Toolbox™](https://www.mathworks.com/products/reinforcement-learning.html) is a tool that provides an app, functions, and a Simulink® block for training policies using reinforcement learning algorithms, including DQN, PPO, SAC, and DDPG. You can use these policies to implement controllers and decision-making algorithms for complex applications such as resource allocation, robotics, and autonomous systems.
[Deep Learning HDL Toolbox™](https://www.mathworks.com/products/deep-learning-hdl.html) is a tool that provides functions and tools to prototype and implement deep learning networks on FPGAs and SoCs. It provides pre-built bitstreams for running a variety of deep learning networks on supported Xilinx® and Intel® FPGA and SoC devices. Profiling and estimation tools let you customize a deep learning network by exploring design, performance, and resource utilization tradeoffs.
[Model Predictive Control Toolbox™](https://www.mathworks.com/products/model-predictive-control.html) is a tool that provides functions, an app, and Simulink® blocks for designing and simulating controllers using linear and nonlinear model predictive control (MPC). The toolbox lets you specify plant and disturbance models, horizons, constraints, and weights. By running closed-loop simulations, you can evaluate controller performance.
[Vision HDL Toolbox™](https://www.mathworks.com/products/vision-hdl.html) is a tool that provides pixel-streaming algorithms for the design and implementation of vision systems on FPGAs and ASICs. It provides a design framework that supports a diverse set of interface types, frame sizes, and frame rates. The image processing, video, and computer vision algorithms in the toolbox use an architecture appropriate for HDL implementations.
[Data Acquisition Toolbox™](https://www.mathworks.com/products/data-acquisition.html) is a tool that provides apps and functions for configuring data acquisition hardware, reading data into MATLAB® and Simulink®, and writing data to DAQ analog and digital output channels. The toolbox supports a variety of DAQ hardware, including USB, PCI, PCI Express®, PXI®, and PXI Express® devices, from National Instruments® and other vendors.
[Microsoft AirSim](https://microsoft.github.io/AirSim/lidar.html) is a simulator for drones, cars and more, built on Unreal Engine (with an experimental Unity release). AirSim is open-source, cross platform, and supports [software-in-the-loop simulation](https://www.mathworks.com/help///ecoder/software-in-the-loop-sil-simulation.html) with popular flight controllers such as PX4 & ArduPilot and [hardware-in-loop](https://www.ni.com/en-us/innovations/white-papers/17/what-is-hardware-in-the-loop-.html) with PX4 for physically and visually realistic simulations. It is developed as an Unreal plugin that can simply be dropped into any Unreal environment. AirSim is being developed as a platform for AI research to experiment with deep learning, computer vision and reinforcement learning algorithms for autonomous vehicles.
# NLP Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## NLP Learning Resources
[Natural Language Processing (NLP)](https://www.ibm.com/cloud/learn/natural-language-processing) is a branch of artificial intelligence (AI) focused on giving computers the ability to understand text and spoken words in much the same way human beings can. NLP combines computational linguistics rule-based modeling of human language with statistical, machine learning, and deep learning models.
[Natural Language Processing With Python's NLTK Package](https://realpython.com/nltk-nlp-python/)
[Cognitive Services—APIs for AI Developers | Microsoft Azure](https://azure.microsoft.com/en-us/services/cognitive-services/)
[Artificial Intelligence Services - Amazon Web Services (AWS)](https://aws.amazon.com/machine-learning/ai-services/)
[Google Cloud Natural Language API](https://cloud.google.com/natural-language/docs/reference/rest)
[Top Natural Language Processing Courses Online | Udemy](https://www.udemy.com/topic/natural-language-processing/)
[Introduction to Natural Language Processing (NLP) | Udemy](https://www.udemy.com/course/natural-language-processing/)
[Top Natural Language Processing Courses | Coursera](https://www.coursera.org/courses?=&query=natural%20language%20processing)
[Natural Language Processing | Coursera](https://www.coursera.org/learn/language-processing)
[Natural Language Processing in TensorFlow | Coursera](https://www.coursera.org/learn/natural-language-processing-tensorflow)
[Learn Natural Language Processing with Online Courses and Lessons | edX](https://www.edx.org/learn/natural-language-processing)
[Build a Natural Language Processing Solution with Microsoft Azure | Pluralsight](https://www.pluralsight.com/courses/build-natural-language-processing-solution-microsoft-azure)
[Natural Language Processing (NLP) Training Courses | NobleProg](https://www.nobleprog.com/nlp-training)
[Natural Language Processing with Deep Learning Course | Standford Online](https://online.stanford.edu/courses/cs224n-natural-language-processing-deep-learning)
[Advanced Natural Language Processing - MIT OpenCourseWare](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-864-advanced-natural-language-processing-fall-2005/)
[Certified Natural Language Processing Expert Certification | IABAC](https://iabac.org/artificial-intelligence-certification/certified-natural-language-processing-expert/)
[Natural Language Processing Course - Intel](https://software.intel.com/content/www/us/en/develop/training/course-natural-language-processing.html)
## NLP Tools, Libraries, and Frameworks
[Natural Language Toolkit (NLTK)](https://www.nltk.org/) is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over [50 corpora and lexical resources](https://nltk.org/nltk_data/) such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries.
[spaCy](https://spacy.io) is a library for advanced Natural Language Processing in Python and Cython. It's built on the very latest research, and was designed from day one to be used in real products. spaCy comes with pretrained pipelines and currently supports tokenization and training for 60+ languages. It also features neural network models for tagging, parsing, named entity recognition, text classification and more, multi-task learning with pretrained transformers like BERT.
[CoreNLP](https://stanfordnlp.github.io/CoreNLP/) is a set of natural language analysis tools written in Java. CoreNLP enables users to derive linguistic annotations for text, including token and sentence boundaries, parts of speech, named entities, numeric and time values, dependency and constituency parses, coreference, sentiment, quote attributions, and relations.
[NLPnet](https://github.com/erickrf/nlpnet) is a Python library for Natural Language Processing tasks based on neural networks. It performs part-of-speech tagging, semantic role labeling and dependency parsing.
[Flair](https://github.com/flairNLP/flair) is a simple framework for state-of-the-art Natural Language Processing (NLP) models to your text, such as named entity recognition (NER), part-of-speech tagging (PoS), special support for biomedical data, sense disambiguation and classification, with support for a rapidly growing number of languages.
[Catalyst](https://github.com/curiosity-ai/catalyst) is a C# Natural Language Processing library built for speed. Inspired by [spaCy's design](https://spacy.io/), it brings pre-trained models, out-of-the box support for training word and document embeddings, and flexible entity recognition models.
[Apache OpenNLP](https://opennlp.apache.org/) is an open-source library for a machine learning based toolkit used in the processing of natural language text. It features an API for use cases like [Named Entity Recognition](https://en.wikipedia.org/wiki/Named-entity_recognition), [Sentence Detection](), [POS(Part-Of-Speech) tagging](https://en.wikipedia.org/wiki/Part-of-speech_tagging), [Tokenization](https://en.wikipedia.org/wiki/Tokenization_(data_security)) [Feature extraction](https://en.wikipedia.org/wiki/Feature_extraction), [Chunking](https://en.wikipedia.org/wiki/Chunking_(psychology)), [Parsing](https://en.wikipedia.org/wiki/Parsing), and [Coreference resolution](https://en.wikipedia.org/wiki/Coreference).
[Microsoft Cognitive Toolkit (CNTK)](https://docs.microsoft.com/en-us/cognitive-toolkit/) is an open-source toolkit for commercial-grade distributed deep learning. It describes neural networks as a series of computational steps via a directed graph. CNTK allows the user to easily realize and combine popular model types such as feed-forward DNNs, convolutional neural networks (CNNs) and recurrent neural networks (RNNs/LSTMs). CNTK implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers.
[NVIDIA cuDNN](https://developer.nvidia.com/cudnn) is a GPU-accelerated library of primitives for [deep neural networks](https://developer.nvidia.com/deep-learning). cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN accelerates widely used deep learning frameworks, including [Caffe2](https://caffe2.ai/), [Chainer](https://chainer.org/), [Keras](https://keras.io/), [MATLAB](https://www.mathworks.com/solutions/deep-learning.html), [MxNet](https://mxnet.incubator.apache.org/), [PyTorch](https://pytorch.org/), and [TensorFlow](https://www.tensorflow.org/).
[TensorFlow](https://www.tensorflow.org) is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML powered applications.
[Tensorflow_macOS](https://github.com/apple/tensorflow_macos) is a Mac-optimized version of TensorFlow and TensorFlow Addons for macOS 11.0+ accelerated using Apple's ML Compute framework.
[Keras](https://keras.io) is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano.It was developed with a focus on enabling fast experimentation. It is capable of running on top of TensorFlow, Microsoft Cognitive Toolkit, R, Theano, or PlaidML.
[PyTorch](https://pytorch.org) is a library for deep learning on irregular input data such as graphs, point clouds, and manifolds. Primarily developed by Facebook's AI Research lab.
[Eclipse Deeplearning4J (DL4J)](https://deeplearning4j.konduit.ai/) is a set of projects intended to support all the needs of a JVM-based(Scala, Kotlin, Clojure, and Groovy) deep learning application. This means starting with the raw data, loading and preprocessing it from wherever and whatever format it is in to building and tuning a wide variety of simple and complex deep learning networks.
[Chainer](https://chainer.org/) is a Python-based deep learning framework aiming at flexibility. It provides automatic differentiation APIs based on the define-by-run approach (dynamic computational graphs) as well as object-oriented high-level APIs to build and train neural networks. It also supports CUDA/cuDNN using [CuPy](https://github.com/cupy/cupy) for high performance training and inference.
[Anaconda](https://www.anaconda.com/) is a very popular Data Science platform for machine learning and deep learning that enables users to develop models, train them, and deploy them.
[PlaidML](https://github.com/plaidml/plaidml) is an advanced and portable tensor compiler for enabling deep learning on laptops, embedded devices, or other devices where the available computing hardware is not well supported or the available software stack contains unpalatable license restrictions.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a Python module for machine learning built on top of SciPy, NumPy, and matplotlib, making it easier to apply robust and simple implementations of many popular machine learning algorithms.
[Caffe](https://github.com/BVLC/caffe) is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) and community contributors.
[Theano](https://github.com/Theano/Theano) is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently including tight integration with NumPy.
[Apache Spark](https://spark.apache.org/) is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.
[Apache Spark Connector for SQL Server and Azure SQL](https://github.com/microsoft/sql-spark-connector) is a high-performance connector that enables you to use transactional data in big data analytics and persists results for ad-hoc queries or reporting. The connector allows you to use any SQL database, on-premises or in the cloud, as an input data source or output data sink for Spark jobs.
[Apache PredictionIO](https://predictionio.apache.org/) is an open source machine learning framework for developers, data scientists, and end users. It supports event collection, deployment of algorithms, evaluation, querying predictive results via REST APIs. It is based on scalable open source services like Hadoop, HBase (and other DBs), Elasticsearch, Spark and implements what is called a Lambda Architecture.
[Apache Airflow](https://airflow.apache.org) is an open-source workflow management platform created by the community to programmatically author, schedule and monitor workflows. Airflow has a modular architecture and uses a message queue to orchestrate an arbitrary number of workers. Airflow is ready to scale to infinity.
[Open Neural Network Exchange(ONNX)](https://github.com/onnx) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types.
[BigDL](https://bigdl-project.github.io/) is a distributed deep learning library for Apache Spark. With BigDL, users can write their deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters.
[Numba](https://github.com/numba/numba) is an open source, NumPy-aware optimizing compiler for Python sponsored by Anaconda, Inc. It uses the LLVM compiler project to generate machine code from Python syntax. Numba can compile a large subset of numerically-focused Python, including many NumPy functions. Additionally, Numba has support for automatic parallelization of loops, generation of GPU-accelerated code, and creation of ufuncs and C callbacks.
# Bioinformatics
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## Bioinformatics Learning Resources
[Bioinformatics](https://www.genome.gov/genetics-glossary/Bioinformatics) is a field of computational science that has to do with the analysis of sequences of biological molecules. This usually refers to genes, DNA, RNA, or protein, and is particularly useful in comparing genes and other sequences in proteins and other sequences within an organism or between organisms, looking at evolutionary relationships between organisms, and using the patterns that exist across DNA and protein sequences to figure out what their function is.
[European Bioinformatics Institute](https://www.ebi.ac.uk/)
[National Center for Biotechnology Information](https://www.ncbi.nlm.nih.gov)
[Online Courses in Bioinformatics |ISCB - International Society for Computational Biology](https://www.iscb.org/cms_addon/online_courses/index.php)
[Bioinformatics | Coursera](https://www.coursera.org/specializations/bioinformatics)
[Top Bioinformatics Courses | Udemy](https://www.udemy.com/topic/Bioinformatics/)
[Biometrics Courses | Udemy](https://www.udemy.com/course/biometrics/)
[Learn Bioinformatics with Online Courses and Lessons | edX](https://www.edx.org/learn/bioinformatics)
[Bioinformatics Graduate Certificate | Harvard Extension School](https://extension.harvard.edu/academics/programs/bioinformatics-graduate-certificate/)
[Bioinformatics and Biostatistics | UC San Diego Extension](https://extension.ucsd.edu/courses-and-programs/bioinformatics-and-biostatistics)
[Bioinformatics and Proteomics - Free Online Course Materials | MIT](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-092-bioinformatics-and-proteomics-january-iap-2005/)
[Introduction to Biometrics course - Biometrics Institute](https://www.biometricsinstitute.org/event/introduction-to-biometrics-short-course/)
## Bioinformatics Tools, Libraries, and Frameworks
[Bioconductor](https://bioconductor.org/) is an open source project that provides tools for the analysis and comprehension of high-throughput genomic data. Bioconductor uses the [R statistical programming language](https://www.r-project.org/about.html), and is open source and open development. It has two releases each year, and an active user community. Bioconductor is also available as an [AMI (Amazon Machine Image)](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AMIs.html) and [Docker images](https://docs.docker.com/engine/reference/commandline/images/).
[Bioconda](https://bioconda.github.io) is a channel for the conda package manager specializing in bioinformatics software. It has a repository of packages containing over 7000 bioinformatics packages ready to use with conda install.
[UniProt](https://www.uniprot.org/) is a freely accessible database that provide users with a comprehensive, high-quality and freely accessible set of protein sequences annotated with functional information.
[Bowtie 2](https://bio.tools/bowtie2#!) is an ultrafast and memory-efficient tool for aligning sequencing reads to long reference sequences. It is particularly good at aligning reads of about 50 up to 100s or 1,000s of characters, and particularly good at aligning to relatively long (mammalian) genomes.
[Biopython](https://biopython.org/) is a set of freely available tools for biological computation written in Python by an international team of developers. It is a distributed collaborative effort to develop Python libraries and applications which address the needs of current and future work in bioinformatics.
[BioRuby](https://bioruby.open-bio.org/) is a toolkit that has components for sequence analysis, pathway analysis, protein modelling and phylogenetic analysis; it supports many widely used data formats and provides easy access to databases, external programs and public web services, including BLAST, KEGG, GenBank, MEDLINE and GO.
[BioJava](https://biojava.org/) is a toolkit that provides an API to maintain local installations of the PDB, load and manipulate structures, perform standard analysis such as sequence and structure alignments and visualize them in 3D.
[BioPHP](https://biophp.org/) is an open source project that provides a collection of open source PHP code, with classes for DNA and protein sequence analysis, alignment, database parsing, and other bioinformatics tools.
[Avogadro](https://avogadro.cc/) is an advanced molecule editor and visualizer designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, and related areas. It offers flexible high quality rendering and a powerful plugin architecture.
[Ascalaph Designer](https://www.biomolecular-modeling.com/Ascalaph/Ascalaph_Designer.html) is a program for molecular dynamic simulations. Under a single graphical environment are represented as their own implementation of molecular dynamics as well as the methods of classical and quantum mechanics of popular programs.
[Anduril](https://www.anduril.org/site/) is a workflow platform for analyzing large data sets. Anduril provides facilities for analyzing high-thoughput data in biomedical research, and the platform is fully extensible by third parties. Ready-made tools support data visualization, DNA/RNA/ChIP-sequencing, DNA/RNA microarrays, cytometry and image analysis.
[Galaxy](https://melbournebioinformatics.github.io/MelBioInf_docs/tutorials/galaxy_101/galaxy_101/) is an open source, web-based platform for accessible, reproducible, and transparent computational biomedical research. It allows users without programming experience to easily specify parameters and run individual tools as well as larger workflows. It also captures run information so that any user can repeat and understand a complete computational analysis.
[PathVisio](https://pathvisio.github.io/) is a free open-source pathway analysis and drawing software which allows drawing, editing, and analyzing biological pathways. It is developed in Java and can be extended with plugins.
[Orange](https://orangedatamining.com/) is a powerful data mining and machine learning toolkit that performs data analysis and visualization.
[Basic Local Alignment Search Tool](https://blast.ncbi.nlm.nih.gov/Blast.cgi) is a tool that finds regions of similarity between biological sequences. The program compares nucleotide or protein sequences to sequence databases and calculates the statistical significance.
[OSIRIS](https://www.ncbi.nlm.nih.gov/osiris/) is public-domain, free, and open source STR analysis software designed for clinical, forensic, and research use, and has been validated for use as an expert system for single-source samples.
[NCBI BioSystems](https://www.ncbi.nlm.nih.gov/biosystems/) is a Database that provides integrated access to biological systems and their component genes, proteins, and small molecules, as well as literature describing those biosystems and other related data throughout Entrez.
# CUDA Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)


**CUDA Toolkit. Source: [NVIDIA Developer CUDA](https://developer.nvidia.com/cuda-zone)**
## CUDA Learning Resources
[CUDA](https://developer.nvidia.com/cuda-zone) is a parallel computing platform and programming model developed by NVIDIA for general computing on graphical processing units (GPUs). With CUDA, developers are able to dramatically speed up computing applications by harnessing the power of GPUs. In GPU-accelerated applications, the sequential part of the workload runs on the CPU, which is optimized for single-threaded. The compute intensive portion of the application runs on thousands of GPU cores in parallel. When using CUDA, developers can program in popular languages such as C, C++, Fortran, Python and MATLAB.
[CUDA Toolkit Documentation](https://docs.nvidia.com/cuda/index.html)
[CUDA Quick Start Guide](https://docs.nvidia.com/cuda/cuda-quick-start-guide/index.html)
[CUDA on WSL](https://docs.nvidia.com/cuda/wsl-user-guide/index.html)
[CUDA GPU support for TensorFlow](https://www.tensorflow.org/install/gpu)
[NVIDIA Deep Learning cuDNN Documentation](https://docs.nvidia.com/deeplearning/cudnn/api/index.html)
[NVIDIA GPU Cloud Documentation](https://docs.nvidia.com/ngc/ngc-introduction/index.html)
[NVIDIA NGC](https://ngc.nvidia.com/) is a hub for GPU-optimized software for deep learning, machine learning, and high-performance computing (HPC) workloads.
[NVIDIA NGC Containers](https://www.nvidia.com/en-us/gpu-cloud/containers/) is a registry that provides researchers, data scientists, and developers with simple access to a comprehensive catalog of GPU-accelerated software for AI, machine learning and HPC. These containers take full advantage of NVIDIA GPUs on-premises and in the cloud.
## CUDA Tools Libraries, and Frameworks
[CUDA Toolkit](https://developer.nvidia.com/cuda-downloads) is a collection of tools & libraries that provide a development environment for creating high performance GPU-accelerated applications. The CUDA Toolkit allows you can develop, optimize, and deploy your applications on GPU-accelerated embedded systems, desktop workstations, enterprise data centers, cloud-based platforms and HPC supercomputers. The toolkit includes GPU-accelerated libraries, debugging and optimization tools, a C/C++ compiler, and a runtime library to build and deploy your application on major architectures including x86, Arm and POWER.
[NVIDIA cuDNN](https://developer.nvidia.com/cudnn) is a GPU-accelerated library of primitives for [deep neural networks](https://developer.nvidia.com/deep-learning). cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN accelerates widely used deep learning frameworks, including [Caffe2](https://caffe2.ai/), [Chainer](https://chainer.org/), [Keras](https://keras.io/), [MATLAB](https://www.mathworks.com/solutions/deep-learning.html), [MxNet](https://mxnet.incubator.apache.org/), [PyTorch](https://pytorch.org/), and [TensorFlow](https://www.tensorflow.org/).
[CUDA-X HPC](https://www.nvidia.com/en-us/technologies/cuda-x/) is a collection of libraries, tools, compilers and APIs that help developers solve the world's most challenging problems. CUDA-X HPC includes highly tuned kernels essential for high-performance computing (HPC).
[NVIDIA Container Toolkit](https://github.com/NVIDIA/nvidia-docker) is a collection of tools & libraries that allows users to build and run GPU accelerated Docker containers. The toolkit includes a container runtime [library](https://github.com/NVIDIA/libnvidia-container) and utilities to automatically configure containers to leverage NVIDIA GPUs.
[Minkowski Engine](https://nvidia.github.io/MinkowskiEngine) is an auto-differentiation library for sparse tensors. It supports all standard neural network layers such as convolution, pooling, unpooling, and broadcasting operations for sparse tensors.
[CUTLASS](https://github.com/NVIDIA/cutlass) is a collection of CUDA C++ template abstractions for implementing high-performance matrix-multiplication (GEMM) at all levels and scales within CUDA. It incorporates strategies for hierarchical decomposition and data movement similar to those used to implement cuBLAS.
[CUB](https://github.com/NVIDIA/cub) is a cooperative primitives for CUDA C++ kernel authors.
[Tensorman](https://github.com/pop-os/tensorman) is a utility for easy management of Tensorflow containers by developed by [System76]( https://system76.com).Tensorman allows Tensorflow to operate in an isolated environment that is contained from the rest of the system. This virtual environment can operate independent of the base system, allowing you to use any version of Tensorflow on any version of a Linux distribution that supports the Docker runtime.
[Numba](https://github.com/numba/numba) is an open source, NumPy-aware optimizing compiler for Python sponsored by Anaconda, Inc. It uses the LLVM compiler project to generate machine code from Python syntax. Numba can compile a large subset of numerically-focused Python, including many NumPy functions. Additionally, Numba has support for automatic parallelization of loops, generation of GPU-accelerated code, and creation of ufuncs and C callbacks.
[Chainer](https://chainer.org/) is a Python-based deep learning framework aiming at flexibility. It provides automatic differentiation APIs based on the define-by-run approach (dynamic computational graphs) as well as object-oriented high-level APIs to build and train neural networks. It also supports CUDA/cuDNN using [CuPy](https://github.com/cupy/cupy) for high performance training and inference.
[CuPy](https://cupy.dev/) is an implementation of NumPy-compatible multi-dimensional array on CUDA. CuPy consists of the core multi-dimensional array class, cupy.ndarray, and many functions on it. It supports a subset of numpy.ndarray interface.
[CatBoost](https://catboost.ai/) is a fast, scalable, high performance [Gradient Boosting](https://en.wikipedia.org/wiki/Gradient_boosting) on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
[cuDF](https://rapids.ai/) is a GPU DataFrame library for loading, joining, aggregating, filtering, and otherwise manipulating data. cuDF provides a pandas-like API that will be familiar to data engineers & data scientists, so they can use it to easily accelerate their workflows without going into the details of CUDA programming.
[cuML](https://github.com/rapidsai/cuml) is a suite of libraries that implement machine learning algorithms and mathematical primitives functions that share compatible APIs with other RAPIDS projects. cuML enables data scientists, researchers, and software engineers to run traditional tabular ML tasks on GPUs without going into the details of CUDA programming. In most cases, cuML's Python API matches the API from scikit-learn.
[ArrayFire](https://arrayfire.com/) is a general-purpose library that simplifies the process of developing software that targets parallel and massively-parallel architectures including CPUs, GPUs, and other hardware acceleration devices.
[Thrust](https://github.com/NVIDIA/thrust) is a C++ parallel programming library which resembles the C++ Standard Library. Thrust's high-level interface greatly enhances programmer productivity while enabling performance portability between GPUs and multicore CPUs.
[AresDB](https://eng.uber.com/aresdb/) is a GPU-powered real-time analytics storage and query engine. It features low query latency, high data freshness and highly efficient in-memory and on disk storage management.
[Arraymancer](https://mratsim.github.io/Arraymancer/) is a tensor (N-dimensional array) project in Nim. The main focus is providing a fast and ergonomic CPU, Cuda and OpenCL ndarray library on which to build a scientific computing ecosystem.
[Kintinuous](https://github.com/mp3guy/Kintinuous) is a real-time dense visual SLAM system capable of producing high quality globally consistent point and mesh reconstructions over hundreds of metres in real-time with only a low-cost commodity RGB-D sensor.
[GraphVite](https://graphvite.io/) is a general graph embedding engine, dedicated to high-speed and large-scale embedding learning in various applications.
# MATLAB Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## MATLAB Learning Resources
[MATLAB](https://www.mathworks.com/products/matlab.html) is a programming language that does numerical computing such as expressing matrix and array mathematics directly.
[MATLAB Documentation](https://www.mathworks.com/help/matlab/)
[Getting Started with MATLAB ](https://www.mathworks.com/help/matlab/getting-started-with-matlab.html)
[MATLAB and Simulink Training from MATLAB Academy](https://matlabacademy.mathworks.com)
[MathWorks Certification Program](https://www.mathworks.com/services/training/certification.html)
[Apache Spark Basics | MATLAB & Simulink](https://www.mathworks.com/help//compiler/spark/apache-spark-basics.html)
[MATLAB Hadoop and Spark | MATLAB & Simulink](https://www.mathworks.com/products/compiler/hadoop-and-spark.html)
[MATLAB Online Courses from Udemy](https://www.udemy.com/topic/matlab/)
[MATLAB Online Courses from Coursera](https://www.coursera.org/courses?query=matlab)
[MATLAB Online Courses from edX](https://www.edx.org/learn/matlab)
[Building a MATLAB GUI](https://www.mathworks.com/discovery/matlab-gui.html)
[MATLAB Style Guidelines 2.0](https://www.mathworks.com/matlabcentral/fileexchange/46056-matlab-style-guidelines-2-0)
[Setting Up Git Source Control with MATLAB & Simulink](https://www.mathworks.com/help/matlab/matlab_prog/set-up-git-source-control.html)
[Pull, Push and Fetch Files with Git with MATLAB & Simulink](https://www.mathworks.com/help/matlab/matlab_prog/push-and-fetch-with-git.html)
[Create New Repository with MATLAB & Simulink](https://www.mathworks.com/help/matlab/matlab_prog/add-folder-to-source-control.html)
[PRMLT](http://prml.github.io/) is Matlab code for machine learning algorithms in the PRML book.
## MATLAB Tools, Libraries, Frameworks
**[MATLAB and Simulink Services & Applications List](https://www.mathworks.com/products.html)**
[MATLAB in the Cloud](https://www.mathworks.com/solutions/cloud.html) is a service that allows you to run in cloud environments from [MathWorks Cloud](https://www.mathworks.com/solutions/cloud.html#browser) to [Public Clouds](https://www.mathworks.com/solutions/cloud.html#public-cloud) including [AWS](https://aws.amazon.com/) and [Azure](https://azure.microsoft.com/).
[MATLAB Online™](https://matlab.mathworks.com) is a service that allows to users to uilitize MATLAB and Simulink through a web browser such as Google Chrome.
[Simulink](https://www.mathworks.com/products/simulink.html) is a block diagram environment for Model-Based Design. It supports simulation, automatic code generation, and continuous testing of embedded systems.
[Simulink Online™](https://www.mathworks.com/products/simulink-online.html) is a service that provides access to Simulink through your web browser.
[MATLAB Drive™](https://www.mathworks.com/products/matlab-drive.html) is a service that gives you the ability to store, access, and work with your files from anywhere.
[MATLAB Parallel Server™](https://www.mathworks.com/products/matlab-parallel-server.html) is a tool that lets you scale MATLAB® programs and Simulink® simulations to clusters and clouds. You can prototype your programs and simulations on the desktop and then run them on clusters and clouds without recoding. MATLAB Parallel Server supports batch jobs, interactive parallel computations, and distributed computations with large matrices.
[MATLAB Schemer](https://github.com/scottclowe/matlab-schemer) is a MATLAB package makes it easy to change the color scheme (theme) of the MATLAB display and GUI.
[LRSLibrary](https://github.com/andrewssobral/lrslibrary) is a Low-Rank and Sparse Tools for Background Modeling and Subtraction in Videos. The library was designed for moving object detection in videos, but it can be also used for other computer vision and machine learning problems.
[Image Processing Toolbox™](https://www.mathworks.com/products/image.html) is a tool that provides a comprehensive set of reference-standard algorithms and workflow apps for image processing, analysis, visualization, and algorithm development. You can perform image segmentation, image enhancement, noise reduction, geometric transformations, image registration, and 3D image processing.
[Computer Vision Toolbox™](https://www.mathworks.com/products/computer-vision.html) is a tool that provides algorithms, functions, and apps for designing and testing computer vision, 3D vision, and video processing systems. You can perform object detection and tracking, as well as feature detection, extraction, and matching. You can automate calibration workflows for single, stereo, and fisheye cameras. For 3D vision, the toolbox supports visual and point cloud SLAM, stereo vision, structure from motion, and point cloud processing.
[Statistics and Machine Learning Toolbox™](https://www.mathworks.com/products/statistics.html) is a tool that provides functions and apps to describe, analyze, and model data. You can use descriptive statistics, visualizations, and clustering for exploratory data analysis; fit probability distributions to data; generate random numbers for Monte Carlo simulations, and perform hypothesis tests. Regression and classification algorithms let you draw inferences from data and build predictive models either interactively, using the Classification and Regression Learner apps, or programmatically, using AutoML.
[Lidar Toolbox™](https://www.mathworks.com/products/lidar.html) is a tool that provides algorithms, functions, and apps for designing, analyzing, and testing lidar processing systems. You can perform object detection and tracking, semantic segmentation, shape fitting, lidar registration, and obstacle detection. Lidar Toolbox supports lidar-camera cross calibration for workflows that combine computer vision and lidar processing.
[Mapping Toolbox™](https://www.mathworks.com/products/mapping.html) is a tool that provides algorithms and functions for transforming geographic data and creating map displays. You can visualize your data in a geographic context, build map displays from more than 60 map projections, and transform data from a variety of sources into a consistent geographic coordinate system.
[UAV Toolbox](https://www.mathworks.com/products/uav.html) is an application that provides tools and reference applications for designing, simulating, testing, and deploying unmanned aerial vehicle (UAV) and drone applications. You can design autonomous flight algorithms, UAV missions, and flight controllers. The Flight Log Analyzer app lets you interactively analyze 3D flight paths, telemetry information, and sensor readings from common flight log formats.
[Parallel Computing Toolbox™](https://www.mathworks.com/products/matlab-parallel-server.html) is a tool that lets you solve computationally and data-intensive problems using multicore processors, GPUs, and computer clusters. High-level constructs such as parallel for-loops, special array types, and parallelized numerical algorithms enable you to parallelize MATLAB® applications without CUDA or MPI programming. The toolbox lets you use parallel-enabled functions in MATLAB and other toolboxes. You can use the toolbox with Simulink® to run multiple simulations of a model in parallel. Programs and models can run in both interactive and batch modes.
[Partial Differential Equation Toolbox™](https://www.mathworks.com/products/pde.html) is a tool that provides functions for solving structural mechanics, heat transfer, and general partial differential equations (PDEs) using finite element analysis.
[ROS Toolbox](https://www.mathworks.com/products/ros.html) is a tool that provides an interface connecting MATLAB® and Simulink® with the Robot Operating System (ROS and ROS 2), enabling you to create a network of ROS nodes. The toolbox includes MATLAB functions and Simulink blocks to import, analyze, and play back ROS data recorded in rosbag files. You can also connect to a live ROS network to access ROS messages.
[Robotics Toolbox™](https://www.mathworks.com/products/robotics.html) provides a toolbox that brings robotics specific functionality(designing, simulating, and testing manipulators, mobile robots, and humanoid robots) to MATLAB, exploiting the native capabilities of MATLAB (linear algebra, portability, graphics). The toolbox also supports mobile robots with functions for robot motion models (bicycle), path planning algorithms (bug, distance transform, D*, PRM), kinodynamic planning (lattice, RRT), localization (EKF, particle filter), map building (EKF) and simultaneous localization and mapping (EKF), and a Simulink model a of non-holonomic vehicle. The Toolbox also including a detailed Simulink model for a quadrotor flying robot.
[Deep Learning Toolbox™](https://www.mathworks.com/products/deep-learning.html) is a tool that provides a framework for designing and implementing deep neural networks with algorithms, pretrained models, and apps. You can use convolutional neural networks (ConvNets, CNNs) and long short-term memory (LSTM) networks to perform classification and regression on image, time-series, and text data. You can build network architectures such as generative adversarial networks (GANs) and Siamese networks using automatic differentiation, custom training loops, and shared weights. With the Deep Network Designer app, you can design, analyze, and train networks graphically. It can exchange models with TensorFlow™ and PyTorch through the ONNX format and import models from TensorFlow-Keras and Caffe. The toolbox supports transfer learning with DarkNet-53, ResNet-50, NASNet, SqueezeNet and many other pretrained models.
[Reinforcement Learning Toolbox™](https://www.mathworks.com/products/reinforcement-learning.html) is a tool that provides an app, functions, and a Simulink® block for training policies using reinforcement learning algorithms, including DQN, PPO, SAC, and DDPG. You can use these policies to implement controllers and decision-making algorithms for complex applications such as resource allocation, robotics, and autonomous systems.
[Deep Learning HDL Toolbox™](https://www.mathworks.com/products/deep-learning-hdl.html) is a tool that provides functions and tools to prototype and implement deep learning networks on FPGAs and SoCs. It provides pre-built bitstreams for running a variety of deep learning networks on supported Xilinx® and Intel® FPGA and SoC devices. Profiling and estimation tools let you customize a deep learning network by exploring design, performance, and resource utilization tradeoffs.
[Model Predictive Control Toolbox™](https://www.mathworks.com/products/model-predictive-control.html) is a tool that provides functions, an app, and Simulink® blocks for designing and simulating controllers using linear and nonlinear model predictive control (MPC). The toolbox lets you specify plant and disturbance models, horizons, constraints, and weights. By running closed-loop simulations, you can evaluate controller performance.
[Vision HDL Toolbox™](https://www.mathworks.com/products/vision-hdl.html) is a tool that provides pixel-streaming algorithms for the design and implementation of vision systems on FPGAs and ASICs. It provides a design framework that supports a diverse set of interface types, frame sizes, and frame rates. The image processing, video, and computer vision algorithms in the toolbox use an architecture appropriate for HDL implementations.
[SoC Blockset™](https://www.mathworks.com/products/soc.html) is a tool that provides Simulink® blocks and visualization tools for modeling, simulating, and analyzing hardware and software architectures for ASICs, FPGAs, and systems on a chip (SoC). You can build your system architecture using memory models, bus models, and I/O models, and simulate the architecture together with the algorithms.
[Wireless HDL Toolbox™](https://www.mathworks.com/products/wireless-hdl.html) is a tool that provides pre-verified, hardware-ready Simulink® blocks and subsystems for developing 5G, LTE, and custom OFDM-based wireless communication applications. It includes reference applications, IP blocks, and gateways between frame and sample-based processing.
[ThingSpeak™](https://www.mathworks.com/products/thingspeak.html) is an IoT analytics service that allows you to aggregate, visualize, and analyze live data streams in the cloud. ThingSpeak provides instant visualizations of data posted by your devices to ThingSpeak. With the ability to execute MATLAB® code in ThingSpeak, you can perform online analysis and process data as it comes in. ThingSpeak is often used for prototyping and proof-of-concept IoT systems that require analytics.
[SEA-MAT](https://sea-mat.github.io/sea-mat/) is a collaborative effort to organize and distribute Matlab tools for the Oceanographic Community.
[Gramm](https://github.com/piermorel/gramm) is a complete data visualization toolbox for Matlab. It provides an easy to use and high-level interface to produce publication-quality plots of complex data with varied statistical visualizations. Gramm is inspired by R's ggplot2 library.
[hctsa](https://hctsa-users.gitbook.io/hctsa-manual) is a software package for running highly comparative time-series analysis using Matlab.
[Plotly](https://plot.ly/matlab/) is a Graphing Library for MATLAB.
[YALMIP](https://yalmip.github.io/) is a MATLAB toolbox for optimization modeling.
[GNU Octave](https://www.gnu.org/software/octave/) is a high-level interpreted language, primarily intended for numerical computations. It provides capabilities for the numerical solution of linear and nonlinear problems, and for performing other numerical experiments. It also provides extensive graphics capabilities for data visualization and manipulation.
# C/C++ Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## C/C++ Learning Resources
[C++](https://www.cplusplus.com/doc/tutorial/) is a cross-platform language that can be used to build high-performance applications developed by Bjarne Stroustrup, as an extension to the C language.
[C](https://www.iso.org/standard/74528.html) is a general-purpose, high-level language that was originally developed by Dennis M. Ritchie to develop the UNIX operating system at Bell Labs. It supports structured programming, lexical variable scope, and recursion, with a static type system. C also provides constructs that map efficiently to typical machine instructions, which makes it one was of the most widely used programming languages today.
[Embedded C](https://en.wikipedia.org/wiki/Embedded_C) is a set of language extensions for the C programming language by the [C Standards Committee](https://isocpp.org/std/the-committee) to address issues that exist between C extensions for different [embedded systems](https://en.wikipedia.org/wiki/Embedded_system). The extensions hep enhance microprocessor features such as fixed-point arithmetic, multiple distinct memory banks, and basic I/O operations. This makes Embedded C the most popular embedded software language in the world.
[C & C++ Developer Tools from JetBrains](https://www.jetbrains.com/cpp/)
[Open source C++ libraries on cppreference.com](https://en.cppreference.com/w/cpp/links/libs)
[C++ Graphics libraries](https://cpp.libhunt.com/libs/graphics)
[C++ Libraries in MATLAB](https://www.mathworks.com/help/matlab/call-cpp-library-functions.html)
[C++ Tools and Libraries Articles](https://www.cplusplus.com/articles/tools/)
[Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
[Introduction C++ Education course on Google Developers](https://developers.google.com/edu/c++/)
[C++ style guide for Fuchsia](https://fuchsia.dev/fuchsia-src/development/languages/c-cpp/cpp-style)
[C and C++ Coding Style Guide by OpenTitan](https://docs.opentitan.org/doc/rm/c_cpp_coding_style/)
[Chromium C++ Style Guide](https://chromium.googlesource.com/chromium/src/+/master/styleguide/c++/c++.md)
[C++ Core Guidelines](https://github.com/isocpp/CppCoreGuidelines/blob/master/CppCoreGuidelines.md)
[C++ Style Guide for ROS](http://wiki.ros.org/CppStyleGuide)
[Learn C++](https://www.learncpp.com/)
[Learn C : An Interactive C Tutorial](https://www.learn-c.org/)
[C++ Institute](https://cppinstitute.org/free-c-and-c-courses)
[C++ Online Training Courses on LinkedIn Learning](https://www.linkedin.com/learning/topics/c-plus-plus)
[C++ Tutorials on W3Schools](https://www.w3schools.com/cpp/default.asp)
[Learn C Programming Online Courses on edX](https://www.edx.org/learn/c-programming)
[Learn C++ with Online Courses on edX](https://www.edx.org/learn/c-plus-plus)
[Learn C++ on Codecademy](https://www.codecademy.com/learn/learn-c-plus-plus)
[Coding for Everyone: C and C++ course on Coursera](https://www.coursera.org/specializations/coding-for-everyone)
[C++ For C Programmers on Coursera](https://www.coursera.org/learn/c-plus-plus-a)
[Top C Courses on Coursera](https://www.coursera.org/courses?query=c%20programming)
[C++ Online Courses on Udemy](https://www.udemy.com/topic/c-plus-plus/)
[Top C Courses on Udemy](https://www.udemy.com/topic/c-programming/)
[Basics of Embedded C Programming for Beginners on Udemy](https://www.udemy.com/course/embedded-c-programming-for-embedded-systems/)
[C++ For Programmers Course on Udacity](https://www.udacity.com/course/c-for-programmers--ud210)
[C++ Fundamentals Course on Pluralsight](https://www.pluralsight.com/courses/learn-program-cplusplus)
[Introduction to C++ on MIT Free Online Course Materials](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-096-introduction-to-c-january-iap-2011/)
[Introduction to C++ for Programmers | Harvard ](https://online-learning.harvard.edu/course/introduction-c-programmers)
[Online C Courses | Harvard University](https://online-learning.harvard.edu/subject/c)
## C/C++ Tools and Frameworks
[AWS SDK for C++](https://aws.amazon.com/sdk-for-cpp/)
[Azure SDK for C++](https://github.com/Azure/azure-sdk-for-cpp)
[Azure SDK for C](https://github.com/Azure/azure-sdk-for-c)
[C++ Client Libraries for Google Cloud Services](https://github.com/googleapis/google-cloud-cpp)
[Visual Studio](https://visualstudio.microsoft.com/) is an integrated development environment (IDE) from Microsoft; which is a feature-rich application that can be used for many aspects of software development. Visual Studio makes it easy to edit, debug, build, and publish your app. By using Microsoft software development platforms such as Windows API, Windows Forms, Windows Presentation Foundation, and Windows Store.
[Visual Studio Code](https://code.visualstudio.com/) is a code editor redefined and optimized for building and debugging modern web and cloud applications.
[Vcpkg](https://github.com/microsoft/vcpkg) is a C++ Library Manager for Windows, Linux, and MacOS.
[ReSharper C++](https://www.jetbrains.com/resharper-cpp/features/) is a Visual Studio Extension for C++ developers developed by JetBrains.
[AppCode](https://www.jetbrains.com/objc/) is constantly monitoring the quality of your code. It warns you of errors and smells and suggests quick-fixes to resolve them automatically. AppCode provides lots of code inspections for Objective-C, Swift, C/C++, and a number of code inspections for other supported languages. All code inspections are run on the fly.
[CLion](https://www.jetbrains.com/clion/features/) is a cross-platform IDE for C and C++ developers developed by JetBrains.
[Code::Blocks](https://www.codeblocks.org/) is a free C/C++ and Fortran IDE built to meet the most demanding needs of its users. It is designed to be very extensible and fully configurable. Built around a plugin framework, Code::Blocks can be extended with plugins.
[CppSharp](https://github.com/mono/CppSharp) is a tool and set of libraries which facilitates the usage of native C/C++ code with the .NET ecosystem. It consumes C/C++ header and library files and generates the necessary glue code to surface the native API as a managed API. Such an API can be used to consume an existing native library in your managed code or add managed scripting support to a native codebase.
[Conan](https://conan.io/) is an Open Source Package Manager for C++ development and dependency management into the 21st century and on par with the other development ecosystems.
[High Performance Computing (HPC) SDK](https://developer.nvidia.com/hpc) is a comprehensive toolbox for GPU accelerating HPC modeling and simulation applications. It includes the C, C++, and Fortran compilers, libraries, and analysis tools necessary for developing HPC applications on the NVIDIA platform.
[Thrust](https://github.com/NVIDIA/thrust) is a C++ parallel programming library which resembles the C++ Standard Library. Thrust's high-level interface greatly enhances programmer productivity while enabling performance portability between GPUs and multicore CPUs. Interoperability with established technologies such as CUDA, TBB, and OpenMP integrates with existing software.
[Boost](https://www.boost.org/) is an educational opportunity focused on cutting-edge C++. Boost has been a participant in the annual Google Summer of Code since 2007, in which students develop their skills by working on Boost Library development.
[Automake](https://www.gnu.org/software/automake/) is a tool for automatically generating Makefile.in files compliant with the GNU Coding Standards. Automake requires the use of GNU Autoconf.
[Cmake](https://cmake.org/) is an open-source, cross-platform family of tools designed to build, test and package software. CMake is used to control the software compilation process using simple platform and compiler independent configuration files, and generate native makefiles and workspaces that can be used in the compiler environment of your choice.
[GDB](http://www.gnu.org/software/gdb/) is a debugger, that allows you to see what is going on `inside' another program while it executes or what another program was doing at the moment it crashed.
[GCC](https://gcc.gnu.org/) is a compiler Collection that includes front ends for C, C++, Objective-C, Fortran, Ada, Go, and D, as well as libraries for these languages.
[GSL](https://www.gnu.org/software/gsl/) is a numerical library for C and C++ programmers. It is free software under the GNU General Public License. The library provides a wide range of mathematical routines such as random number generators, special functions and least-squares fitting. There are over 1000 functions in total with an extensive test suite.
[OpenGL Extension Wrangler Library (GLEW)](https://www.opengl.org/sdk/libs/GLEW/) is a cross-platform open-source C/C++ extension loading library. GLEW provides efficient run-time mechanisms for determining which OpenGL extensions are supported on the target platform.
[Libtool](https://www.gnu.org/software/libtool/) is a generic library support script that hides the complexity of using shared libraries behind a consistent, portable interface. To use Libtool, add the new generic library building commands to your Makefile, Makefile.in, or Makefile.am.
[Maven](https://maven.apache.org/) is a software project management and comprehension tool. Based on the concept of a project object model (POM), Maven can manage a project's build, reporting and documentation from a central piece of information.
[TAU (Tuning And Analysis Utilities)](http://www.cs.uoregon.edu/research/tau/home.php) is capable of gathering performance information through instrumentation of functions, methods, basic blocks, and statements as well as event-based sampling. All C++ language features are supported including templates and namespaces.
[Clang](https://clang.llvm.org/) is a production quality C, Objective-C, C++ and Objective-C++ compiler when targeting X86-32, X86-64, and ARM (other targets may have caveats, but are usually easy to fix). Clang is used in production to build performance-critical software like Google Chrome or Firefox.
[OpenCV](https://opencv.org/) is a highly optimized library with focus on real-time applications. Cross-Platform C++, Python and Java interfaces support Linux, MacOS, Windows, iOS, and Android.
[Libcu++](https://nvidia.github.io/libcudacxx) is the NVIDIA C++ Standard Library for your entire system. It provides a heterogeneous implementation of the C++ Standard Library that can be used in and between CPU and GPU code.
[ANTLR (ANother Tool for Language Recognition)](https://www.antlr.org/) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files. It's widely used to build languages, tools, and frameworks. From a grammar, ANTLR generates a parser that can build parse trees and also generates a listener interface that makes it easy to respond to the recognition of phrases of interest.
[Oat++](https://oatpp.io/) is a light and powerful C++ web framework for highly scalable and resource-efficient web application. It's zero-dependency and easy-portable.
[JavaCPP](https://github.com/bytedeco/javacpp) is a program that provides efficient access to native C++ inside Java, not unlike the way some C/C++ compilers interact with assembly language.
[Cython](https://cython.org/) is a language that makes writing C extensions for Python as easy as Python itself. Cython is based on Pyrex, but supports more cutting edge functionality and optimizations such as calling C functions and declaring C types on variables and class attributes.
[Spdlog](https://github.com/gabime/spdlog) is a very fast, header-only/compiled, C++ logging library.
[Infer](https://fbinfer.com/) is a static analysis tool for Java, C++, Objective-C, and C. Infer is written in [OCaml](https://ocaml.org/).
# Java Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## Java Learning Resources
[Java](https://www.oracle.com/java/) is a popular programming language and development platform(JDK). It reduces costs, shortens development timeframes, drives innovation, and improves application services. With millions of developers running more than 51 billion Java Virtual Machines worldwide.
[The Eclipse Foundation](https://www.eclipse.org/downloads/) is home to a worldwide community of developers, the Eclipse IDE, Jakarta EE and over 375 open source projects, including runtimes, tools and frameworks for Java and other languages.
[Getting Started with Java](https://docs.oracle.com/javase/tutorial/)
[Oracle Java certifications from Oracle University](https://education.oracle.com/java-certification-benefits)
[Google Developers Training](https://developers.google.com/training/)
[Google Developers Certification](https://developers.google.com/certification/)
[Java Tutorial by W3Schools](https://www.w3schools.com/java/)
[Building Your First Android App in Java](codelabs.developers.google.com/codelabs/build-your-first-android-app/)
[Getting Started with Java in Visual Studio Code](https://code.visualstudio.com/docs/java/java-tutorial)
[Google Java Style Guide](https://google.github.io/styleguide/javaguide.html)
[AOSP Java Code Style for Contributors](https://source.android.com/setup/contribute/code-style)
[Chromium Java style guide](https://chromium.googlesource.com/chromium/src/+/master/styleguide/java/java.md)
[Get Started with OR-Tools for Java](https://developers.google.com/optimization/introduction/java)
[Getting started with Java Tool Installer task for Azure Pipelines](https://docs.microsoft.com/en-us/azure/devops/pipelines/tasks/tool/java-tool-installer)
[Gradle User Manual](https://docs.gradle.org/current/userguide/userguide.html)
## Java Tools, Libraries, and Frameworks
[Java SE](https://www.oracle.com/java/technologies/javase/tools-jsp.html) contains several tools to assist in program development and debugging, and in the monitoring and troubleshooting of production applications.
[JDK Development Tools](https://docs.oracle.com/javase/7/docs/technotes/tools/) includes the Java Web Start Tools (javaws) Java Troubleshooting, Profiling, Monitoring and Management Tools (jcmd, jconsole, jmc, jvisualvm); and Java Web Services Tools (schemagen, wsgen, wsimport, xjc).
[Android Studio](https://developer.android.com/studio/) is the official integrated development environment for Google's Android operating system, built on JetBrains' IntelliJ IDEA software and designed specifically for Android development. Availble on Windows, macOS, Linux, Chrome OS.
[IntelliJ IDEA](https://www.jetbrains.com/idea/) is an IDE for Java, but it also understands and provides intelligent coding assistance for a large variety of other languages such as Kotlin, SQL, JPQL, HTML, JavaScript, etc., even if the language expression is injected into a String literal in your Java code.
[NetBeans](https://netbeans.org/features/java/index.html) is an IDE provides Java developers with all the tools needed to create professional desktop, mobile and enterprise applications. Creating, Editing, and Refactoring. The IDE provides wizards and templates to let you create Java EE, Java SE, and Java ME applications.
[Java Design Patterns ](https://github.com/iluwatar/java-design-patterns) is a collection of the best formalized practices a programmer can use to solve common problems when designing an application or system.
[Elasticsearch](https://www.elastic.co/products/elasticsearch) is a distributed RESTful search engine built for the cloud written in Java.
[RxJava](https://github.com/ReactiveX/RxJava) is a Java VM implementation of [Reactive Extensions](http://reactivex.io/): a library for composing asynchronous and event-based programs by using observable sequences. It extends the [observer pattern](http://en.wikipedia.org/wiki/Observer_pattern) to support sequences of data/events and adds operators that allow you to compose sequences together declaratively while abstracting away concerns about things like low-level threading, synchronization, thread-safety and concurrent data structures.
[Guava](https://github.com/google/guava) is a set of core Java libraries from Google that includes new collection types (such as multimap and multiset), immutable collections, a graph library, and utilities for concurrency, I/O, hashing, caching, primitives, strings, and more! It is widely used on most Java projects within Google, and widely used by many other companies as well.
[okhttp](https://square.github.io/okhttp/) is a HTTP client for Java and Kotlin developed by Square.
[Retrofit](https://square.github.io/retrofit/) is a type-safe HTTP client for Android and Java develped by Square.
[LeakCanary](https://square.github.io/leakcanary/) is a memory leak detection library for Android develped by Square.
[Apache Spark](https://spark.apache.org/) is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.
[Apache Flink](https://flink.apache.org/) is an open source stream processing framework with powerful stream- and batch-processing capabilities with elegant and fluent APIs in Java and Scala.
[Fastjson](https://github.com/alibaba/fastjson/wiki) is a Java library that can be used to convert Java Objects into their JSON representation. It can also be used to convert a JSON string to an equivalent Java object.
[libGDX](https://libgdx.com/) is a cross-platform Java game development framework based on OpenGL (ES) that works on Windows, Linux, Mac OS X, Android, your WebGL enabled browser and iOS.
[Jenkins](https://www.jenkins.io/) is the leading open-source automation server. Built with Java, it provides over 1700 [plugins](https://plugins.jenkins.io/) to support automating virtually anything, so that humans can actually spend their time doing things machines cannot.
[DBeaver](https://dbeaver.io/) is a free multi-platform database tool for developers, SQL programmers, database administrators and analysts. Supports any database which has JDBC driver (which basically means - ANY database). EE version also supports non-JDBC datasources (MongoDB, Cassandra, Redis, DynamoDB, etc).
[Redisson](https://redisson.pro/) is a Redis Java client with features of In-Memory Data Grid. Over 50 Redis based Java objects and services: Set, Multimap, SortedSet, Map, List, Queue, Deque, Semaphore, Lock, AtomicLong, Map Reduce, Publish / Subscribe, Bloom filter, Spring Cache, Tomcat, Scheduler, JCache API, Hibernate, MyBatis, RPC, and local cache.
[GraalVM](https://www.graalvm.org/) is a universal virtual machine for running applications written in JavaScript, Python, Ruby, R, JVM-based languages like Java, Scala, Clojure, Kotlin, and LLVM-based languages such as C and C++.
[Gradle](https://gradle.org/) is a build automation tool for multi-language software development. From mobile apps to microservices, from small startups to big enterprises, Gradle helps teams build, automate and deliver better software, faster. Write in Java, C++, Python or your language of choice.
[Apache Groovy](http://www.groovy-lang.org/) is a powerful, optionally typed and dynamic language, with static-typing and static compilation capabilities, for the Java platform aimed at improving developer productivity thanks to a concise, familiar and easy to learn syntax. It integrates smoothly with any Java program, and immediately delivers to your application powerful features, including scripting capabilities, Domain-Specific Language authoring, runtime and compile-time meta-programming and functional programming.
[JaCoCo](https://www.jacoco.org/jacoco/) is a free code coverage library for Java, which has been created by the EclEmma team based on the lessons learned from using and integration existing libraries for many years.
[Apache JMeter](http://jmeter.apache.org/) is used to test performance both on static and dynamic resources, Web dynamic applications. It also used to simulate a heavy load on a server, group of servers, network or object to test its strength or to analyze overall performance under different load types.
[Junit](https://junit.org/) is a simple framework to write repeatable tests. It is an instance of the xUnit architecture for unit testing frameworks.
[Mockito](https://site.mockito.org/) is the most popular Mocking framework for unit tests written in Java.
[SpotBugs](https://spotbugs.github.io/) is a program which uses static analysis to look for bugs in Java code.
[SpringBoot](https://spring.io/projects/spring-boot) is a great tool that helps you to create Spring-powered, production-grade applications and services with absolute minimum fuss. It takes an opinionated view of the Spring platform so that new and existing users can quickly get to the bits they need.
[YourKit](https://www.yourkit.com/) is a technology leader, creator of the most innovative and intelligent tools for profiling Java & .NET applications.
# Python Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## Python Learning Resources
[Python](https://www.python.org) is an interpreted, high-level programming language. Python is used heavily in the fields of Data Science and Machine Learning.
[Python Developer’s Guide](https://devguide.python.org) is a comprehensive resource for contributing to Python – for both new and experienced contributors. It is maintained by the same community that maintains Python.
[Azure Functions Python developer guide](https://docs.microsoft.com/en-us/azure/azure-functions/functions-reference-python) is an introduction to developing Azure Functions using Python. The content below assumes that you've already read the [Azure Functions developers guide](https://docs.microsoft.com/en-us/azure/azure-functions/functions-reference).
[CheckiO](https://checkio.org/) is a programming learning platform and a gamified website that teaches Python through solving code challenges and competing for the most elegant and creative solutions.
[Python Institute](https://pythoninstitute.org)
[PCEP – Certified Entry-Level Python Programmer certification](https://pythoninstitute.org/pcep-certification-entry-level/)
[PCAP – Certified Associate in Python Programming certification](https://pythoninstitute.org/pcap-certification-associate/)
[PCPP – Certified Professional in Python Programming 1 certification](https://pythoninstitute.org/pcpp-certification-professional/)
[PCPP – Certified Professional in Python Programming 2](https://pythoninstitute.org/pcpp-certification-professional/)
[MTA: Introduction to Programming Using Python Certification](https://docs.microsoft.com/en-us/learn/certifications/mta-introduction-to-programming-using-python)
[Getting Started with Python in Visual Studio Code](https://code.visualstudio.com/docs/python/python-tutorial)
[Google's Python Style Guide](https://google.github.io/styleguide/pyguide.html)
[Google's Python Education Class](https://developers.google.com/edu/python/)
[Real Python](https://realpython.com)
[The Python Open Source Computer Science Degree by Forrest Knight](https://github.com/ForrestKnight/open-source-cs-python)
[Intro to Python for Data Science](https://www.datacamp.com/courses/intro-to-python-for-data-science)
[Intro to Python by W3schools](https://www.w3schools.com/python/python_intro.asp)
[Codecademy's Python 3 course](https://www.codecademy.com/learn/learn-python-3)
[Learn Python with Online Courses and Classes from edX](https://www.edx.org/learn/python)
[Python Courses Online from Coursera](https://www.coursera.org/courses?query=python)
## Python Frameworks and Tools
[Python Package Index (PyPI)](https://pypi.org/) is a repository of software for the Python programming language. PyPI helps you find and install software developed and shared by the Python community.
[PyCharm](https://www.jetbrains.com/pycharm/) is the best IDE I've ever used. With PyCharm, you can access the command line, connect to a database, create a virtual environment, and manage your version control system all in one place, saving time by avoiding constantly switching between windows.
[Python Tools for Visual Studio(PTVS)](https://microsoft.github.io/PTVS/) is a free, open source plugin that turns Visual Studio into a Python IDE. It supports editing, browsing, IntelliSense, mixed Python/C++ debugging, remote Linux/MacOS debugging, profiling, IPython, and web development with Django and other frameworks.
[Pylance](https://github.com/microsoft/pylance-release) is an extension that works alongside Python in Visual Studio Code to provide performant language support. Under the hood, Pylance is powered by Pyright, Microsoft's static type checking tool.
[Pyright](https://github.com/Microsoft/pyright) is a fast type checker meant for large Python source bases. It can run in a “watch” mode and performs fast incremental updates when files are modified.
[Django](https://www.djangoproject.com/) is a high-level Python Web framework that encourages rapid development and clean, pragmatic design.
[Flask](https://flask.palletsprojects.com/) is a micro web framework written in Python. It is classified as a microframework because it does not require particular tools or libraries.
[Web2py](http://web2py.com/) is an open-source web application framework written in Python allowing allows web developers to program dynamic web content. One web2py instance can run multiple web sites using different databases.
[AWS Chalice](https://github.com/aws/chalice) is a framework for writing serverless apps in python. It allows you to quickly create and deploy applications that use AWS Lambda.
[Tornado](https://www.tornadoweb.org/) is a Python web framework and asynchronous networking library. Tornado uses a non-blocking network I/O, which can scale to tens of thousands of open connections.
[HTTPie](https://github.com/httpie/httpie) is a command line HTTP client that makes CLI interaction with web services as easy as possible. HTTPie is designed for testing, debugging, and generally interacting with APIs & HTTP servers.
[Scrapy](https://scrapy.org/) is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
[Sentry](https://sentry.io/) is a service that helps you monitor and fix crashes in realtime. The server is in Python, but it contains a full API for sending events from any language, in any application.
[Pipenv](https://github.com/pypa/pipenv) is a tool that aims to bring the best of all packaging worlds (bundler, composer, npm, cargo, yarn, etc.) to the Python world.
[Python Fire](https://github.com/google/python-fire) is a library for automatically generating command line interfaces (CLIs) from absolutely any Python object.
[Bottle](https://github.com/bottlepy/bottle) is a fast, simple and lightweight [WSGI](https://www.wsgi.org/) micro web-framework for Python. It is distributed as a single file module and has no dependencies other than the [Python Standard Library](https://docs.python.org/library/).
[CherryPy](https://cherrypy.org) is a minimalist Python object-oriented HTTP web framework.
[Sanic](https://github.com/huge-success/sanic) is a Python 3.6+ web server and web framework that's written to go fast.
[Pyramid](https://trypyramid.com) is a small and fast open source Python web framework. It makes real-world web application development and deployment more fun and more productive.
[TurboGears](https://turbogears.org) is a hybrid web framework able to act both as a Full Stack framework or as a Microframework.
[Falcon](https://falconframework.org/) is a reliable, high-performance Python web framework for building large-scale app backends and microservices with support for MongoDB, Pluggable Applications and autogenerated Admin.
[Neural Network Intelligence(NNI)](https://github.com/microsoft/nni) is an open source AutoML toolkit for automate machine learning lifecycle, including [Feature Engineering](https://github.com/microsoft/nni/blob/master/docs/en_US/FeatureEngineering/Overview.md), [Neural Architecture Search](https://github.com/microsoft/nni/blob/master/docs/en_US/NAS/Overview.md), [Model Compression](https://github.com/microsoft/nni/blob/master/docs/en_US/Compressor/Overview.md) and [Hyperparameter Tuning](https://github.com/microsoft/nni/blob/master/docs/en_US/Tuner/BuiltinTuner.md).
[Dash](https://plotly.com/dash) is a popular Python framework for building ML & data science web apps for Python, R, Julia, and Jupyter.
[Luigi](https://github.com/spotify/luigi) is a Python module that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization etc. It also comes with Hadoop support built-in.
[Locust](https://github.com/locustio/locust) is an easy to use, scriptable and scalable performance testing tool.
[spaCy](https://github.com/explosion/spaCy) is a library for advanced Natural Language Processing in Python and Cython.
[NumPy](https://www.numpy.org/) is the fundamental package needed for scientific computing with Python.
[Pillow](https://python-pillow.org/) is a friendly PIL(Python Imaging Library) fork.
[IPython](https://ipython.org/) is a command shell for interactive computing in multiple programming languages, originally developed for the Python programming language, that offers enhanced introspection, rich media, additional shell syntax, tab completion, and rich history.
[GraphLab Create](https://turi.com/) is a Python library, backed by a C++ engine, for quickly building large-scale, high-performance machine learning models.
[Pandas](https://pandas.pydata.org/) is a fast, powerful, and easy to use open source data structrures, data analysis and manipulation tool, built on top of the Python programming language.
[PuLP](https://coin-or.github.io/pulp/) is an Linear Programming modeler written in python. PuLP can generate LP files and call on use highly optimized solvers, GLPK, COIN CLP/CBC, CPLEX, and GUROBI, to solve these linear problems.
[Matplotlib](https://matplotlib.org/) is a 2D plotting library for creating static, animated, and interactive visualizations in Python. Matplotlib produces publication-quality figures in a variety of hardcopy formats and interactive environments across platforms.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a simple and efficient tool for data mining and data analysis. It is built on NumPy,SciPy, and mathplotlib.
# Scala Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## Scala Learning Resources
[Scala](https://scala-lang.org/) is a combination of object-oriented and functional programming in one concise, high-level language. Scala's static types help avoid bugs in complex applications, and its JVM and JavaScript runtimes let you build high-performance systems with easy access to huge ecosystems of libraries.
[Scala Style Guide](https://docs.scala-lang.org/style/)
[Databricks Scala Style Guide](https://github.com/databricks/scala-style-guide)
[Data Science using Scala and Spark on Azure](https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/scala-walkthrough)
[Creating a Scala Maven application for Apache Spark in HDInsight using IntelliJ](https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-create-standalone-application)
[Intro to Spark DataFrames using Scala with Azure Databricks](https://docs.microsoft.com/en-us/azure/databricks/spark/latest/dataframes-datasets/introduction-to-dataframes-scala)
[Using Scala to Program AWS Glue ETL Scripts](https://docs.aws.amazon.com/glue/latest/dg/glue-etl-scala-using.html)
[Using Flink Scala shell with Amazon EMR clusters](https://docs.aws.amazon.com/emr/latest/ReleaseGuide/flink-scala.html)
[AWS EMR and Spark 2 using Scala from Udemy](https://www.udemy.com/course/aws-emr-and-spark-2-using-scala/)
[Using the Google Cloud Storage connector with Apache Spark](https://cloud.google.com/dataproc/docs/tutorials/gcs-connector-spark-tutorial)
[Write and run Spark Scala jobs on Cloud Dataproc for Google Cloud](https://cloud.google.com/dataproc/docs/tutorials/spark-scala)
[Scala Courses and Certifications from edX](https://www.edx.org/learn/scala)
[Scala Courses from Coursera](https://www.coursera.org/courses?query=scala)
[Top Scala Courses from Udemy](https://www.udemy.com/topic/scala/)
## Scala Tools and Libraries
[Apache Spark](https://spark.apache.org/) is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.
[Apache Spark Connector for SQL Server and Azure SQL](https://github.com/microsoft/sql-spark-connector) is a high-performance connector that enables you to use transactional data in big data analytics and persists results for ad-hoc queries or reporting. The connector allows you to use any SQL database, on-premises or in the cloud, as an input data source or output data sink for Spark jobs.
[Azure Databricks](https://azure.microsoft.com/en-us/services/databricks/) is a fast and collaborative Apache Spark-based big data analytics service designed for data science and data engineering. Azure Databricks, sets up your Apache Spark environment in minutes, autoscale, and collaborate on shared projects in an interactive workspace. Azure Databricks supports Python, Scala, R, Java, and SQL, as well as data science frameworks and libraries including TensorFlow, PyTorch, and scikit-learn.
[Apache PredictionIO](https://predictionio.apache.org/) is an open source machine learning framework for developers, data scientists, and end users. It supports event collection, deployment of algorithms, evaluation, querying predictive results via REST APIs. It is based on scalable open source services like Hadoop, HBase (and other DBs), Elasticsearch, Spark and implements what is called a Lambda Architecture.
[Cluster Manager for Apache Kafka(CMAK)](https://github.com/yahoo/CMAK) is a tool for managing [Apache Kafka](https://kafka.apache.org/) clusters.
[BigDL](https://bigdl-project.github.io/) is a distributed deep learning library for Apache Spark. With BigDL, users can write their deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters.
[Eclipse Deeplearning4J (DL4J)](https://deeplearning4j.konduit.ai/) is a set of projects intended to support all the needs of a JVM-based(Scala, Kotlin, Clojure, and Groovy) deep learning application. This means starting with the raw data, loading and preprocessing it from wherever and whatever format it is in to building and tuning a wide variety of simple and complex deep learning networks.
[Play Framework](https://github.com/playframework/playframework) is a web framework combines productivity and performance making it easy to build scalable web applications with Java and Scala.
[Dotty](https://github.com/lampepfl/dotty) is a research compiler that will become Scala 3.
[AWScala](https://github.com/seratch/AWScala) is a tool that enables Scala developers to easily work with Amazon Web Services in the Scala way.
[Scala.js](https://www.scala-js.org/) is a compiler that converts Scala to JavaScript.
[Polynote](https://polynote.org/) is an experimental polyglot notebook environment. Currently, it supports Scala and Python (with or without Spark), SQL, and Vega.
[Scala Native](http://scala-native.org/) is an optimizing ahead-of-time compiler and lightweight managed runtime designed specifically for Scala.
[Gitbucket](https://gitbucket.github.io/) is a Git platform powered by Scala with easy installation, high extensibility & GitHub API compatibility.
[Finagle](https://twitter.github.io/finagle) is a fault tolerant, protocol-agnostic RPC system
[Gatling](https://gatling.io/) is a load test tool. It officially supports HTTP, WebSocket, Server-Sent-Events and JMS.
[Scalatra](https://scalatra.org/) is a tiny Scala high-performance, async web framework, inspired by [Sinatra](https://www.sinatrarb.com/).
# R Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## R Learning Resources
[R](https://www.r-project.org/) is an open source software environment for statistical computing and graphics. It compiles and runs on a wide variety of platforms such as Windows and MacOS.
[An Introduction to R](https://cran.r-project.org/doc/manuals/r-release/R-intro.pdf)
[Google's R Style Guide](https://google.github.io/styleguide/Rguide.html)
[R developer's guide to Azure](https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/r-developers-guide)
[Running R at Scale on Google Compute Engine](https://cloud.google.com/solutions/running-r-at-scale)
[Running R on AWS](https://aws.amazon.com/blogs/big-data/running-r-on-aws/)
[RStudio Server Pro for AWS](https://aws.amazon.com/marketplace/pp/RStudio-RStudio-Server-Pro-for-AWS/B06W2G9PRY)
[Learn R by Codecademy](https://www.codecademy.com/learn/learn-r)
[Learn R Programming with Online Courses and Lessons by edX](https://www.edx.org/learn/r-programming)
[R Language Courses by Coursera](https://www.coursera.org/courses?query=r%20language)
[Learn R For Data Science by Udacity](https://www.udacity.com/course/programming-for-data-science-nanodegree-with-R--nd118)
## R Tools, Libraries, and Frameworks
[Visual Studio Code](https://code.visualstudio.com/) is a code editor redefined and optimized for building and debugging modern web and cloud applications.
[Code Server](https://coder.com/) is a tool that allows you to run [VS Code](https://code.visualstudio.com/) on any machine anywhere and access it in the browser.
[VSCode-R](https://marketplace.visualstudio.com/items?itemName=Ikuyadeu.r) is a VS Code extension provides support for the [R programming language](https://www.r-project.org/), including features such as extended syntax highlighting, R language service based on code analysis, interacting with R terminals, viewing data, plots, workspace variables, help pages, managing packages, and working with [R Markdown](https://rmarkdown.rstudio.com/) documents.
[R Debugger](https://marketplace.visualstudio.com/items?itemName=RDebugger.r-debugger) is an extension that adds debugging capabilities for the R programming language to Visual Studio Code and depends on the R package [vscDebugger (documentation)](https://github.com/ManuelHentschel/vscDebugger).
[Language Server Protocol (LSP)](https://microsoft.github.io/language-server-protocol/) is a tool that defines the protocol used between an editor or IDE and a language server that provides language features like auto complete, go to definition, find all references.
[RStudio](https://rstudio.com/) is an integrated development environment for R and Python, with a console, syntax-highlighting editor that supports direct code execution, and tools for plotting, history, debugging and workspace management.
[Shiny](https://shiny.rstudio.com/) is a newer package from RStudio that makes it incredibly easy to build interactive web applications with R.
[Rmarkdown](https://rmarkdown.rstudio.com/) is a package helps you create dynamic analysis documents that combine code, rendered output (such as figures), and prose.
[R Host](https://github.com/microsoft/R-Host) is a host process for R that provides access and extensibility to it remotely over WebSocket and JSON.
[Rplugin](https://github.com/JetBrains/Rplugin) is R Language supported plugin for the IntelliJ IDE.
[Plotly](https://plotly-r.com/) is an R package for creating interactive web graphics via the open source JavaScript graphing library [plotly.js](https://github.com/plotly/plotly.js).
[Metaflow](https://metaflow.org/) is a Python/R library that helps scientists and engineers build and manage real-life data science projects. Metaflow was originally developed at Netflix to boost productivity of data scientists who work on a wide variety of projects from classical statistics to state-of-the-art deep learning.
[Prophet](https://facebook.github.io/prophet) is a procedure for forecasting time series data based on an additive model where non-linear trends are fit with yearly, weekly, and daily seasonality, plus holiday effects. It works best with time series that have strong seasonal effects and several seasons of historical data.
[LightGBM](https://lightgbm.readthedocs.io/) is a gradient boosting framework that uses tree based learning algorithms, used for ranking, classification and many other machine learning tasks.
[Dash](https://plotly.com/dash) is a Python framework for building analytical web applications in Python, R, Julia, and Jupyter.
[MLR](https://mlr.mlr-org.com/) is Machine Learning in R.
[ML workspace](https://github.com/ml-tooling/ml-workspace) is an all-in-one web-based IDE specialized for machine learning and data science. It is simple to deploy and gets you started within minutes to productively built ML solutions on your own machines. ML workspace is the ultimate tool for developers preloaded with a variety of popular data science libraries (Tensorflow, PyTorch, Keras, and MXnet) and dev tools (Jupyter, VS Code, and Tensorboard) perfectly configured, optimized, and integrated.
[CatBoost](https://catboost.ai/) is a fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
[Plumber](https://www.rplumber.io/) is a tool that allows you to create a web API by merely decorating your existing R source code with special comments.
[Drake](https://docs.ropensci.org/drake) is an R-focused pipeline toolkit for reproducibility and high-performance computing.
[DiagrammeR](https://visualizers.co/diagrammer/) is a package you can create, modify, analyze, and visualize network graph diagrams. The output can be incorporated into R Markdown documents, integrated with Shiny web apps, converted to other graph formats, or exported as image files.
[Knitr](https://yihui.org/knitr/) is a general-purpose literate programming engine in R, with lightweight API's designed to give users full control of the output without heavy coding work.
[Broom](https://broom.tidymodels.org/) is a tool that converts statistical analysis objects from R into tidy format.
# Julia Development
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)

## Julia Learning Resources
[Julia](https://julialang.org) is a high-level, [high-performance](https://julialang.org/benchmarks/) dynamic language for technical computing. Julia programs compile to efficient native code for [multiple platforms](https://julialang.org/downloads/#support_tiers) via LLVM.
[JuliaHub](https://juliahub.com/) contains over 4,000 Julia packages for use by the community.
[Julia Observer](https://www.juliaobserver.com)
[Julia Manual](https://docs.julialang.org/en/v1/manual/getting-started/)
[JuliaLang Essentials](https://docs.julialang.org/en/v1/base/base/)
[Julia Style Guide](https://docs.julialang.org/en/v1/manual/style-guide/)
[Julia By Example](https://juliabyexample.helpmanual.io/)
[JuliaLang Gitter](https://gitter.im/JuliaLang/julia)
[DataFrames Tutorial using Jupyter Notebooks](https://github.com/bkamins/Julia-DataFrames-Tutorial/)
[Julia Academy](https://juliaacademy.com/courses?preview=logged_out)
[Julia Meetup groups](https://www.meetup.com/topics/julia/)
[Julia on Microsoft Azure](https://juliacomputing.com/media/2017/02/08/azure.html)
## Julia Tools, Libraries and Frameworks
[JuliaPro](https://juliacomputing.com/products/juliapro.html) is a free and fast way to setup Julia for individual researchers, engineers, scientists, quants, traders, economists, students and others. Julia developers can build better software quicker and easier while benefiting from Julia's unparalleled high performance. It includes 2600+ open source packages or from a curated list of 250+ JuliaPro packages. Curated packages are tested, documented and supported by Julia Computing.
[Juno](https://junolab.org) is a powerful, free IDE based on [Atom](https://atom.io/) for the Julia language.
[Debugger.jl](https://github.com/JuliaDebug/Debugger.jl) is the Julia debuggin tool.
[Profile (Stdlib)](https://docs.julialang.org/en/v1/manual/profile/) is a module provides tools to help developers improve the performance of their code. When used, it takes measurements on running code, and produces output that helps you understand how much time is spent on individual line's.
[Revise.jl](https://github.com/timholy/Revise.jl) allows you to modify code and use the changes without restarting Julia. With Revise, you can be in the middle of a session and then update packages, switch git branches, and/or edit the source code in the editor of your choice; any changes will typically be incorporated into the very next command you issue from the REPL. This can save you the overhead of restarting Julia, loading packages, and waiting for code to JIT-compile.
[JuliaGPU](https://juliagpu.org/) is a Github organization created to unify the many packages for programming GPUs in Julia. With its high-level syntax and flexible compiler, Julia is well positioned to productively program hardware accelerators like GPUs without sacrificing performance.
[IJulia.jl](https://github.com/JuliaLang/IJulia.jl) is the Julia kernel for Jupyter.
[AWS.jl](https://github.com/JuliaCloud/AWS.jl) is a Julia interface for [Amazon Web Services](https://aws.amazon.com/).
[CUDA.jl](https://juliagpu.gitlab.io/CUDA.jl) is a package for the main programming interface for working with NVIDIA CUDA GPUs using Julia. It features a user-friendly array abstraction, a compiler for writing CUDA kernels in Julia, and wrappers for various CUDA libraries.
[XLA.jl](https://github.com/JuliaTPU/XLA.jl) is a package for compiling Julia to XLA for [Tensor Processing Unit(TPU)](https://cloud.google.com/tpu/).
[Nanosoldier.jl](https://github.com/JuliaCI/Nanosoldier.jl) is a package for running JuliaCI services on MIT's Nanosoldier cluster.
[Julia for VSCode](https://www.julia-vscode.org) is a powerful extension for the Julia language.
[JuMP.jl](https://jump.dev/) is a domain-specific modeling language for [mathematical optimization](https://en.wikipedia.org/wiki/Mathematical_optimization) embedded in Julia.
[Optim.jl](https://github.com/JuliaNLSolvers/Optim.jl) is a univariate and multivariate optimization in Julia.
[RCall.jl](https://github.com/JuliaInterop/RCall.jl) is a package that allows you to call R functions from Julia.
[JavaCall.jl](http://juliainterop.github.io/JavaCall.jl) is a package that allows you to call Java functions from Julia.
[PyCall.jl](https://github.com/JuliaPy/PyCall.jl) is a package that allows you to call Python functions from Julia.
[MXNet.jl](https://github.com/dmlc/MXNet.jl) is the Apache MXNet Julia package. MXNet.jl brings flexible and efficient GPU computing and state-of-art deep learning to Julia.
[Knet](https://denizyuret.github.io/Knet.jl/latest) is the [Koç University deep](http://www.ku.edu.tr/en) learning framework implemented in Julia by [Deniz Yuret](https://www.denizyuret.com/) and collaborators. It supports GPU operation and automatic differentiation using dynamic computational graphs for models defined in plain Julia.
[Distributions.jl](https://github.com/JuliaStats/Distributions.jl) is a Julia package for probability distributions and associated functions.
[DataFrames.jl](http://juliadata.github.io/DataFrames.jl/stable/) is a tool for working with tabular data in Julia.
[Flux.jl](https://fluxml.ai/) is an elegant approach to machine learning. It's a 100% pure-Julia stack, and provides lightweight abstractions on top of Julia's native GPU and AD support.
[IRTools.jl](https://github.com/FluxML/IRTools.jl) is a simple and flexible IR format, expressive enough to work with both lowered and typed Julia code, as well as external IRs.
[Cassette.jl](https://github.com/jrevels/Cassette.jl) is a Julia package that provides a mechanism for dynamically injecting code transformation passes into Julia’s just-in-time (JIT) compilation cycle, enabling post hoc analysis and modification of "Cassette-unaware" Julia programs without requiring manual source annotation or refactoring of the target code.
## Contribute
- [x] If would you like to contribute to this guide simply make a [Pull Request](https://github.com/mikeroyal/Distributed-Systems-Guide/pulls).
## License
[Back to the Top](https://github.com/mikeroyal/Distributed-Systems-Guide#table-of-contents)
Distributed under the [Creative Commons Attribution 4.0 International (CC BY 4.0) Public License](https://creativecommons.org/licenses/by/4.0/).