https://github.com/prompt-engineering/awesome-prompt-engineering
awesome for your to collections
https://github.com/prompt-engineering/awesome-prompt-engineering
List: awesome-prompt-engineering
awesome-list prompt-engineering
Last synced: 5 months ago
JSON representation
awesome for your to collections
- Host: GitHub
- URL: https://github.com/prompt-engineering/awesome-prompt-engineering
- Owner: prompt-engineering
- License: cc0-1.0
- Created: 2023-03-03T10:34:52.000Z (almost 3 years ago)
- Default Branch: master
- Last Pushed: 2023-03-30T01:19:47.000Z (over 2 years ago)
- Last Synced: 2025-07-21T04:02:10.910Z (5 months ago)
- Topics: awesome-list, prompt-engineering
- Size: 36.1 KB
- Stars: 21
- Watchers: 2
- Forks: 2
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- ultimate-awesome - awesome-prompt-engineering - Awesome for your to collections . (Other Lists / TeX Lists)
README
# awesome-prompts
> awesome for your to collections
## LLMs
based on: [总结当下可用的大模型LLMs](https://zhuanlan.zhihu.com/p/611403556)
| Model | 作者 | Size | 类型 | 开源? |
|-------|-------|-------|-------|-------|
| [LLaMa](https://github.com/facebookresearch/llama) | Meta AI | 7B-65B | Decoder | open |
| [OPT](https://github.com/facebookresearch/metaseq) | Meta AI | 125M-175B | Decoder | open |
| [T5](https://huggingface.co/google?sort_models=likes#models) | Google | 220M-11B | Encoder-Decoder | open |
| [mT5](https://huggingface.co/models?search=mt5) | Google | 235M-13B | Encoder-Decoder | open |
| [UL2](https://huggingface.co/google/ul2) | Google | 20B | Encoder-Decoder | open |
| PaLM | Google | 540B | Decoder | no |
| [LaMDA](https://blog.google/technology/ai/lamda/) | Google | 2B-137B | Decoder | no |
| [FLAN-T5](https://huggingface.co/google/flan-t5-large) | Google | 同T5 | Encoder-Decoder | open |
| FLAN-UL2 | Google | 同U2 | Encoder-Decoder | open |
| FLAN-PaLM | Google | 同PaLM | Decoder | no |
| FLAN | Google | 同LaMDA | Decoder | no |
| [BLOOM](https://huggingface.co/bigscience/bloom) | BigScience | 176B | Decoder | open |
| [T0](https://huggingface.co/bigscience/T0) | BigScience | 3B | Decoder | open |
| BLOOMZ | BigScience | 同BLOOM | Decoder | open |
| mT0 | BigScience | 同T0 | Decoder | open |
| [GPT-Neo](https://github.com/EleutherAI/gpt-neo) | EleutherAI | 125M-2.7B | Decoder | open |
| [GPT-NeoX](https://huggingface.co/EleutherAI/gpt-neox-20b) | EleutherAI | 20B | Decoder | open |
| GPT3 | OpenAI | 175B (davinci) | Decoder | no |
| GPT4 | OpenAI | unknown | OpenAI | no |
| InstructGPT | OpenAI | 1.3B | Decoder | no |
| [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) | Stanford | 同LLaMa | Decoder | open |
| [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B) | Tsinghua University | 6B | Decoder | open |
| [GLM-130B](https://github.com/THUDM/GLM-130B) | Tsinghua University | 130B | Decoder | open |
## Instruct/Prompt Tuning Data
based on [总结开源可用的Instruct/Prompt Tuning数据](https://zhuanlan.zhihu.com/p/615277009)
| 数据集/项目名称 | 组织/作者 | 简介 |
|-------------|-------------|-------------|
| [Natural Instruction / Super-Natural Instruction](https://instructions.apps.allenai.org/) | Allen AI | 包含61个NLP任务(Natural Instruction)和1600个NLP任务(Super-Natural Instruction)的指令数据 |
| [PromptSource / P3](https://github.com/bigscience-workshop/promptsource) | BigScience | 包含270个NLP任务的2000多个prompt模版(PromptSource)和规模在100M-1B之间的P3数据集 |
| [xMTF](https://github.com/bigscience-workshop/xmtf) | BigScience | 包含13个NLP任务、46种语言的多语言prompt数据 |
| [HH-RLHF](https://huggingface.co/datasets/Anthropic/hh-rlhf) | Anthropic | 旨在训练Helpful and Harmless(HH)的LLMs的RLHF数据集 |
| [Unnatural Instruction](https://github.com/orhonovich/unnatural-instructions) | orhonovich | 使用GPT3生成64k的instruction prompt数据,经改写后得到240k条instruction数据 |
| [Self-Instruct](https://github.com/yizhongw/self-instruct) | yizhongw | 使用LLMs生成prompt进行instruct-tuning的方法,引入Task pool和Quality filtering等概念 |
| [UnifiedSKG](https://unifiedskg.com/) | HKU | 在Text-to-Text框架中加入knowledge grounding,将结构化数据序列化并嵌入到prompt中 |
| [Flan Collection](https://github.com/google-research/FLAN/tree/main/flan/v2) | Google | 将Flan 2021数据与一些开源的instruction数据(P3,super-natural instruction等)进行合并 |
| [InstructDial](https://github.com/prakharguptaz/Instructdial/tree/main/datasets) | prakharguptaz | 在特定的一种任务类型(对话指令)上进行指令微调的尝试 |
| [Alpaca-LoRA](https://github.com/tloen/alpaca-lora) | tloen | Low-Rank LLaMA Instruct-Tuning |
## Projects:
- [Prompt Engineering Guide](https://github.com/dair-ai/Prompt-Engineering-Guide) - Guides, papers, lecture, and resources for prompt engineering
- [notebooks](https://github.com/dair-ai/Prompt-Engineering-Guide/tree/main/notebooks)
- [LangChain](https://github.com/hwchase17/langchain/) - ⚡ Building applications with LLMs through composability ⚡
- [ChatLangChain](https://github.com/hwchase17/chat-langchain) is an implementation of a locally hosted chatbot specifically focused on question answering over the LangChain documentation. Built with LangChain and FastAPI.
- [Langflow](https://github.com/logspace-ai/langflow) - LangFlow is a GUI for LangChain, designed with react-flow to provide an effortless way to experiment and prototype flows with drag-and-drop components and a chat box.
- [Alpaca]
- [Alpaca-LoRA](https://github.com/tloen/alpaca-lora) - Low-Rank LLaMA Instruct-Tuning, Instruct-tune LLaMA on consumer hardware .
- [Alpaca-LoRA as a Chatbot Service](https://github.com/deep-diver/Alpaca-LoRA-Serve)
- [AlpacaDataCleaned](https://github.com/gururise/AlpacaDataCleaned)
- [BELLE](https://github.com/LianjiaTech/BELLE) - Bloom-Enhanced Large Language model Engine,针对 Stanford Alpaca 中文做了优化,模型调优仅使用由ChatGPT生产的数据(不包含任何其他数据)。
- [https://github.com/LC1332/Chinese-alpaca-lora](https://github.com/LC1332/Chinese-alpaca-lora) - A Chinese finetuned instruction LLaMA.
- [Dolly](https://github.com/databrickslabs/dolly) - fine-tunes the GPT-J 6B model on the Alpaca dataset using a Databricks notebook.
- [ChatRWKV](https://github.com/BlinkDL/ChatRWKV) - ChatRWKV is like ChatGPT but powered by RWKV (100% RNN) language model, and open source.
- [GPT-j]
## Infra
- [PEFT](https://github.com/huggingface/peft) - Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient adaptation of pre-trained language models (PLMs) to various downstream applications without fine-tuning all the model's parameters.
## Patterns
[Semantic Kernel](https://github.com/microsoft/semantic-kernel)
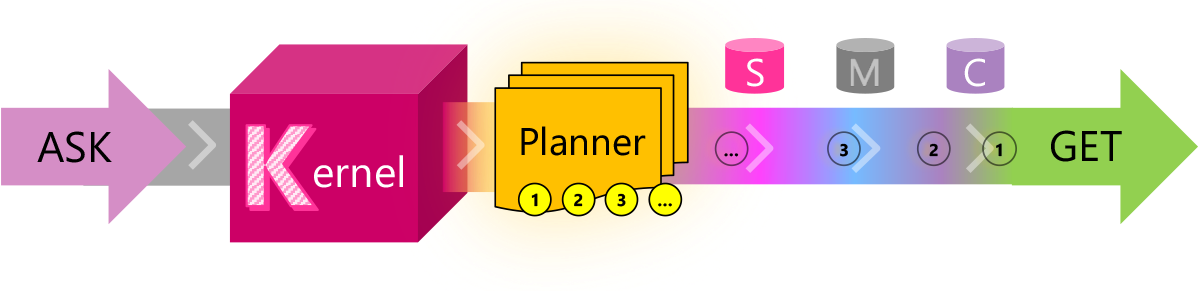
Semantic Kernel is designed to support and encapsulate several design patterns from the latest in AI research, such that developers can infuse their applications with complex skills like prompt chaining, recursive reasoning, summarization, zero/few-shot learning, contextual memory, long-term memory, embeddings, semantic indexing, planning, and accessing external knowledge stores as well as your own data.
## Prompter Papers
- MathPrompter: Mathematical Reasoning using Large Language Models