https://github.com/showlab/Awesome-Video-Diffusion
A curated list of recent diffusion models for video generation, editing, restoration, understanding, etc.
https://github.com/showlab/Awesome-Video-Diffusion
List: Awesome-Video-Diffusion
awesome diffusion-models text-to-motion text-to-video video-editing video-generation video-restoration video-understanding
Last synced: 11 months ago
JSON representation
A curated list of recent diffusion models for video generation, editing, restoration, understanding, etc.
- Host: GitHub
- URL: https://github.com/showlab/Awesome-Video-Diffusion
- Owner: showlab
- Created: 2023-04-17T10:34:17.000Z (almost 3 years ago)
- Default Branch: main
- Last Pushed: 2024-04-30T14:56:39.000Z (almost 2 years ago)
- Last Synced: 2024-05-23T01:06:03.368Z (almost 2 years ago)
- Topics: awesome, diffusion-models, text-to-motion, text-to-video, video-editing, video-generation, video-restoration, video-understanding
- Homepage:
- Size: 222 KB
- Stars: 2,554
- Watchers: 119
- Forks: 155
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- Awesome-Avatars - Awesome-Video-Diffusion
- awesome-awesome-artificial-intelligence - Awesome Video Diffusion - Video-Diffusion?style=social) | (Computer Vision)
- awesome-LLM-resources - Awesome-Video-Diffusion
- ultimate-awesome - Awesome-Video-Diffusion - A curated list of recent diffusion models for video generation, editing, and various other applications. (Other Lists / TeX Lists)
- awesome-gui-agent - Awesome-Video-Diffusion - MLLM-Hallucination](https://github.com/showlab/Awesome-MLLM-Hallucination). (Acknowledgements)
- awesome-ai-agents - showlab/Awesome-Video-Diffusion - A curated list of recent diffusion models and resources for video generation, editing, restoration, and various AI-driven video applications. (Multimodal AI & Vision Agents / Video Processing Agents)
- awesome-ai-papers - [Awesome-Video-Diffusion - Controllable-Video-Generation](https://github.com/mayuelala/Awesome-Controllable-Video-Generation)\] (Multimodal / 7. Text2Video)
README
# Awesome Video Diffusion [](https://github.com/sindresorhus/awesome)
A curated list of recent diffusion models for video generation, editing, restoration, understanding, nerf, etc.




(Source: Make-A-Video, Tune-A-Video, and Fate/Zero.)
## Table of Contents
- [Open-source Toolboxes and Foundation Models](#open-source-toolboxes-and-foundation-models)
- [Evaluation Benchmarks and Metrics](#evaluation-benchmarks-and-metrics)
- [Commercial Product](#commercial-product)
- [Video Generation](#video-generation)
- [Efficient Video Generation](#efficient-video-generation)
- [Controllable Video Generation](#controllable-video-generation)
- [Character Customization](#character-customization)
- [Motion Customization](#motion-customization)
- [Long Video / Film Generation](#long-video--film-generation)
- [Video Generation with 3D/Physical Prior](#video-generation-with-3dphysical-prior)
- [Video Editing](#video-editing)
- [Human or Subject Motion](#human-or-subject-motion)
- [Video Enhancement and Restoration](#video-enhancement-and-restoration)
- [Audio Synthesis for Video](#audio-synthesis-for-video)
- [Talking Head Generation](#talking-head-generation)
- [Human/AI Feedback for Video Generation](#human/ai-feedback-for-video-generation)
- [Policy Learning](#policy-learning)
- [Virtual Try-On](#virtual-try-on)
- [3D](#3d)
- [4D](#4d)
- [Game Generation](#game-generation)
- [AI Safety](#ai-safety)
- [Rendering with Virtual Engine](#rendering-with-virtual-engine)
- [Open-World Model](#open-world-model)
- [Video Understanding](#video-understanding)
- [Healthcare and Biology](#healthcare-and-biology)
- [Other Applications](#other-applications)
### Open-source Toolboxes and Foundation Models
+ [Wan-Video](https://github.com/Wan-Video/Wan2.1)
[](https://github.com/Wan-Video/Wan2.1)
[](https://wanxai.com/)
+ [DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio)
[](https://github.com/modelscope/DiffSynth-Studio)
+ [Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model](https://arxiv.org/abs/2502.10248)
[](https://github.com/stepfun-ai/Step-Video-T2V)
[](https://arxiv.org/abs/2502.10248)
[](https://yuewen.cn/videos)
+ [Cosmos](https://github.com/NVIDIA/Cosmos)
[](https://github.com/NVIDIA/Cosmos)
[](https://arxiv.org/abs/2501.03575)
[](https://research.nvidia.com/labs/dir/cosmos1/)
+ [LTX-Video](https://github.com/Lightricks/LTX-Video)
[](https://github.com/Lightricks/LTX-Video)
+ [HunyuanVideo: A Systematic Framework For Large Video Generative Models](https://arxiv.org/abs/2412.03603)
[](https://github.com/Tencent/HunyuanVideo)
+ [VideoTuna](https://videoverses.github.io/videotuna/)
[](https://github.com/VideoVerses/VideoTuna)
[](https://videoverses.github.io/videotuna/)
+ [Allegro](https://rhymes.ai/blog-details/allegro-advanced-video-generation-model)
[](https://github.com/rhymes-ai/Allegro)
[](https://arxiv.org/abs/2410.15458)
[](https://rhymes.ai/blog-details/allegro-advanced-video-generation-model)
+ [Mochi 1](https://www.genmo.ai/blog)
[](https://github.com/genmoai/mochi)
[](https://www.genmo.ai/blog)
+ [Movie Gen: A Cast of Media Foundation Models](https://ai.meta.com/research/publications/movie-gen-a-cast-of-media-foundation-models/)
[](https://github.com/facebookresearch/MovieGenBench)
[](https://arxiv.org/pdf/2410.13720)
[](https://www.youtube.com/playlist?list=PL86eLlsPNfyi27GSizYjinpYxp7gEl5K8)
+ [Pyramidal Flow Matching for Efficient Video Generative Modeling](https://pyramid-flow.github.io/)
[](https://github.com/jy0205/Pyramid-Flow)
[](https://pyramid-flow.github.io/)
+ [Open-Sora-Plan](https://github.com/PKU-YuanGroup/Open-Sora-Plan)
[](https://github.com/PKU-YuanGroup/Open-Sora-Plan)
[](https://github.com/PKU-YuanGroup/Open-Sora-Plan/blob/main/docs/Report-v1.0.0.md)
+ [Open-Sora](https://github.com/hpcaitech/Open-Sora)
[](https://github.com/hpcaitech/Open-Sora)
[](https://github.com/hpcaitech/Open-Sora/blob/main/docs/zh_CN/README.md)
+ [Stable Video Diffusion](https://github.com/Stability-AI/generative-models)
[](https://github.com/Stability-AI/generative-models)
[](https://stability.ai/news/stable-video-diffusion-open-ai-video-model)
+ [Show-1](https://github.com/showlab/Show-1)
[](https://github.com/showlab/Show-1)
[](https://showlab.github.io/Show-1/)
+ [Hotshot-XL (text-to-GIF)](https://github.com/hotshotco/Hotshot-XL)
[](https://github.com/hotshotco/Hotshot-XL)
+ [zeroscope_v2](https://huggingface.co/cerspense/zeroscope_v2_576w)
[](https://huggingface.co/cerspense/zeroscope_v2_576w)
[](https://huggingface.co/cerspense/zeroscope_v2_XL)
+ [I2VGen-XL (image-to-video / video-to-video)](https://modelscope.cn/models/damo/Image-to-Video/summary)
[-9cf)](https://modelscope.cn/models/damo/Image-to-Video/summary)
[-9cf)](https://modelscope.cn/models/damo/Video-to-Video/summary)
+ [text-to-video-synthesis-colab](https://github.com/camenduru/text-to-video-synthesis-colab)
[](https://github.com/camenduru/text-to-video-synthesis-colab)
+ [VideoCrafter: A Toolkit for Text-to-Video Generation and Editing](https://github.com/VideoCrafter/VideoCrafter)
[](https://github.com/VideoCrafter/VideoCrafter)
+ [ModelScope (Text-to-video synthesis)](https://modelscope.cn/models/damo/text-to-video-synthesis/summary)
[](https://github.com/modelscope/modelscope)
+ [Diffusers (Text-to-video synthesis)](https://huggingface.co/docs/diffusers/main/en/api/pipelines/text_to_video#texttovideo-synthesis)
[](https://github.com/huggingface/diffusers)
+ [Wunjo CE (Video Generation and Editing)](https://github.com/wladradchenko/wunjo.wladradchenko.ru)
[](https://github.com/wladradchenko/wunjo.wladradchenko.ru)
### Evaluation Benchmarks and Metrics
+ [VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness](https://arxiv.org/abs/2503.21755) (Mar., 2025)
[](https://github.com/Vchitect/VBench)
[](https://arxiv.org/abs/2503.21755)
[](https://vchitect.github.io/VBench-2.0-project/)
+ [Impossible Videos](https://arxiv.org/abs/2503.14378) (Mar., 2025)
[](https://github.com/showlab/Impossible-Videos)
[](https://arxiv.org/abs/2503.14378)
[](https://showlab.github.io/Impossible-Videos/)
+ [MEt3R: Measuring Multi-View Consistency in Generated Images](https://geometric-rl.mpi-inf.mpg.de/met3r/static/assets/met3r.pdf) (Jan., 2025)
[](https://github.com/mohammadasim98/MEt3R)
[](https://geometric-rl.mpi-inf.mpg.de/met3r/static/assets/met3r.pdf)
[](https://geometric-rl.mpi-inf.mpg.de/met3r/)
+ [Is Your World Simulator a Good Story Presenter? A Consecutive Events-Based Benchmark for Future Long Video Generation](https://arxiv.org/abs/2412.16211) (Dec., 2024)
[](https://github.com/ypwang61/StoryEval/tree/main)
[](https://arxiv.org/abs/2412.16211)
[](https://ypwang61.github.io/project/StoryEval/)
+ [Evaluation Agent, Efficient and Promptable Evaluation Framework for Visual Generative Models](https://arxiv.org/abs/2412.09645) (Dec., 2024)
[](https://github.com/Vchitect/Evaluation-Agent)
[](https://arxiv.org/abs/2412.09645)
[](https://vchitect.github.io/Evaluation-Agent-project/)
+ [Frechet Video Motion Distance: A Metric for Evaluating Motion Consistency in Videos](https://arxiv.org/pdf/2407.16124) (Jun., 2024)
[](https://github.com/DSL-Lab/FVMD-frechet-video-motion-distance)
[](https://arxiv.org/pdf/2407.16124)
[](https://pypi.org/project/fvmd/1.0.0/)
+ [T2V-CompBench: A Comprehensive Benchmark for Compositional Text-to-video Generation](https://arxiv.org/abs/2407.14505) (Jun., 2024)
[](https://github.com/KaiyueSun98/T2V-CompBench)
[](https://arxiv.org/abs/2407.14505)
[](https://t2v-compbench.github.io/)
+ [ChronoMagic-Bench: A Benchmark for Metamorphic Evaluation of Text-to-Time-lapse Video Generation](https://arxiv.org/abs/2406.18522) (NeurIPS, 2024)
[](https://github.com/PKU-YuanGroup/ChronoMagic-Bench)
[](https://arxiv.org/abs/2406.18522)
[](https://pku-yuangroup.github.io/ChronoMagic-Bench/)
+ [PEEKABOO: Interactive Video Generation via Masked-Diffusion](https://arxiv.org/abs/2312.07509) (CVPR, 2024)
[](https://github.com/microsoft/Peekaboo)
[](https://arxiv.org/abs/2312.07509)
[](https://jinga-lala.github.io/projects/Peekaboo/)
+ [T2VScore: Towards A Better Metric for Text-to-Video Generation](https://arxiv.org/abs/2401.07781) (Jan., 2024)
[](https://github.com/showlab/T2VScore)
[](https://arxiv.org/abs/2401.07781)
[](https://showlab.github.io/T2VScore/)
+ [StoryBench: A Multifaceted Benchmark for Continuous Story Visualization](https://arxiv.org/abs/2308.11606) (NeurIPS, 2023)
[](https://github.com/google/storybench)
[](https://arxiv.org/abs/2308.11606)
+ [VBench: Comprehensive Benchmark Suite for Video Generative Models](https://arxiv.org/abs/2311.17982) (Nov., 2023)
[](https://github.com/Vchitect/VBench?tab=readme-ov-file)
[](https://arxiv.org/abs/2311.17982)
[](https://vchitect.github.io/VBench-project/)
+ [FETV: A Benchmark for Fine-Grained Evaluation of Open-Domain Text-to-Video Generation](https://arxiv.org/abs/2311.01813) (Nov., 2023)
[](https://github.com/llyx97/FETV)
[](https://arxiv.org/abs/2311.01813)
+ [EvalCrafter: Benchmarking and Evaluating Large Video Generation Models](https://arxiv.org/abs/2310.11440) (Oct., 2023)
[](https://github.com/EvalCrafter/EvalCrafter)
[](https://arxiv.org/abs/2310.11440)
[](https://evalcrafter.github.io/)
[](https://huggingface.co/datasets/RaphaelLiu/EvalCrafter_T2V_Dataset)
+ [Evaluation of Text-to-Video Generation Models: A Dynamics Perspective](https://arxiv.org/pdf/2407.01094) (Jul., 2024)
[](https://github.com/MingXiangL/DEVIL)
[](https://arxiv.org/pdf/2407.01094)
+ [VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models](https://arxiv.org/abs/2403.06098) (May., 2024)
[](https://github.com/WangWenhao0716/VidProM)
[](https://arxiv.org/abs/2403.06098)
[](https://github.com/WangWenhao0716/VidProM)
[](https://vidprom.github.io/)
+ [Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers](https://arxiv.org/abs/2402.19479) (CVPR, 2024)
[](https://github.com/snap-research/Panda-70M)
[](https://arxiv.org/abs/2402.19479)
[](https://github.com/snap-research/Panda-70M)
[](https://snap-research.github.io/Panda-70M/)
+ [ReLight My NeRF: A Dataset for Novel View Synthesis and Relighting of Real World Objects](https://openaccess.thecvf.com/content/CVPR2023/html/Toschi_ReLight_My_NeRF_A_Dataset_for_Novel_View_Synthesis_and_CVPR_2023_paper.html) (CVPR, 2023)
[](https://github.com/eyecan-ai/rene)
[](https://openaccess.thecvf.com/content/CVPR2023/html/Toschi_ReLight_My_NeRF_A_Dataset_for_Novel_View_Synthesis_and_CVPR_2023_paper.html)
[](https://eyecan-ai.github.io/rene/)
### Commercial Product
+ [Veo 2](https://sora.com/) ([Google](https://deepmind.google/technologies/veo/veo-2/))
[](https://deepmind.google/technologies/veo/veo-2/)
+ [Kling](https://klingai.com/?gad_source=1&gclid=CjwKCAiAudG5BhAREiwAWMlSjMtrwX5RsW6xQvRSSg05fn1bA8wo9-AJiAKTIr-IkZnewbLXpCM44RoCkrsQAvD_BwE) ([KuaiShou](https://www.kuaishou.com/en))
[](https://klingai.com/?gad_source=1&gclid=CjwKCAiAudG5BhAREiwAWMlSjMtrwX5RsW6xQvRSSg05fn1bA8wo9-AJiAKTIr-IkZnewbLXpCM44RoCkrsQAvD_BwE)
+ [Gen 3](https://app.runwayml.com/login) ([Runway](https://runwayml.com/))
[](https://app.runwayml.com/login)
+ [Dream Machine](https://lumalabs.ai/dream-machine) ([Luma AI](https://lumalabs.ai/dream-machine))
[](https://lumalabs.ai/dream-machine)
+ [Sora](https://sora.com/) ([Open AI](https://openai.com/))
[](https://sora.com/)
+ [Wunjo](https://wunjo.online/) ([WR](https://wladradchenko.ru/en#products))
[](https://wunjo.online/)
### Video Generation
+ [Aligning Text-to-Video Generation Models with Prompt Optimization](https://arxiv.org/abs/2503.20491) (Mar., 2025)
[](https://github.com/thu-coai/VPO/tree/main)
[](https://arxiv.org/abs/2503.20491)
+ [Target-Aware Video Diffusion Models](https://arxiv.org/abs/2503.18950) (Mar., 2025)
[](https://github.com/taeksuu/tavid)
[](https://arxiv.org/abs/2503.18950)
[](https://taeksuu.github.io/tavid/)
+ [MagicComp: Training-free Dual-Phase Refinement for Compositional Video Generation](https://arxiv.org/abs/2503.14428) (Mar., 2025)
[](https://github.com/Hong-yu-Zhang/MagicComp)
[](https://arxiv.org/pdf/2503.14428)
[](https://hong-yu-zhang.github.io/MagicComp-Page/)
+ [Video-T1: Test-Time Scaling for Video Generation](https://arxiv.org/abs/2503.18942) (Mar., 2025)
[](https://github.com/liuff19/Video-T1)
[](https://arxiv.org/pdf/2503.18942)
[](https://liuff19.github.io/Video-T1/)
+ [Temporal Regularization Makes Your Video Generator Stronger](https://arxiv.org/abs/2503.15417) (Mar., 2025)
[](https://arxiv.org/pdf/2503.15417)
[](https://haroldchen19.github.io/FluxFlow/)
+ [VACE: All-in-One Video Creation and Editing](https://arxiv.org/pdf/2503.07598) (Mar., 2025)
[](https://github.com/ali-vilab/VACE)
[](https://arxiv.org/pdf/2503.07598)
[](https://ali-vilab.github.io/VACE-Page/)
+ [RIFLEx: A Free Lunch for Length Extrapolation in Video Diffusion Transformers](https://arxiv.org/abs/2502.15894) (Feb., 2025)
[](https://github.com/thu-ml/RIFLEx)
[](https://arxiv.org/abs/2502.15894)
[](https://riflex-video.github.io/)
+ [DLFR-VAE: Dynamic Latent Frame Rate VAE for Video Generation](https://arxiv.org/abs/2502.11897) (Feb., 2025)
[](https://arxiv.org/abs/2502.11897)
+ [Magic 1-For-1: Generating One Minute Video Clips within One Minute](https://arxiv.org/abs/2502.07701) (Feb., 2025)
[](https://github.com/DA-Group-PKU/Magic-1-For-1)
[](https://arxiv.org/abs/2502.07701)
[](https://magic-141.github.io/Magic-141/)
+ [Lumina-Video: Efficient and Flexible Video Generation with Multi-scale Next-DiT](https://arxiv.org/abs/2502.06782) (Feb., 2025)
[](https://github.com/Alpha-VLLM/Lumina-Video)
[](https://arxiv.org/abs/2502.06782)
+ [RepVideo: Rethinking Cross-Layer Representation for Video Generation](https://arxiv.org/pdf/2501.08994) (Jan., 2025)
[](https://github.com/Vchitect/RepVideo)
[](https://arxiv.org/pdf/2501.08994)
[](https://vchitect.github.io/RepVid-Webpage/)
+ [Large Motion Video Autoencoding with Cross-modal Video VAE](https://arxiv.org/abs/2412.17805) (Dec., 2024)
[](https://arxiv.org/abs/2412.17805)
[](https://github.com/VideoVerses/VideoVAEPlus)
+ [MotiF: Making Text Count in Image Animation with Motion Focal Loss](https://arxiv.org/abs/2412.16153) (Dec., 2024)
[](https://arxiv.org/abs/2412.16153)
[](https://wang-sj16.github.io/motif/#BibTeX)
+ [VideoDPO: Omni-Preference Alignment for Video Diffusion Generation](https://arxiv.org/pdf/2412.14167) (Dec., 2024)
[](https://arxiv.org/pdf/2412.14167)
[](https://videodpo.github.io/)
+ [Autoregressive Video Generation without Vector Quantization](https://arxiv.org/abs/2412.14169) (Dec., 2024)
[](https://github.com/baaivision/NOVA)
[](https://arxiv.org/abs/2412.14169)
+ [AniDoc: Animation Creation Made Easier](https://arxiv.org/pdf/2412.14173) (Dec., 2024)
[](https://github.com/yihao-meng/AniDoc)
[](https://arxiv.org/pdf/2412.14173)
[](https://yihao-meng.github.io/AniDoc_demo/)
+ [Video Diffusion Transformers are In-Context Learners](https://arxiv.org/abs/2412.10783) (Dec., 2024)
[](https://github.com/feizc/Video-In-Context)
[](https://arxiv.org/abs/2412.10783)
[](https://huggingface.co/feizhengcong/Video-In-Context)
+ [Track4Gen: Teaching Video Diffusion Models to Track Points Improves Video Generation](https://arxiv.org/abs/2412.06016) (Dec., 2024 | CVPR 2025)
[](https://arxiv.org/abs/2412.06016)
[](https://hyeonho99.github.io/track4gen/)
+ [Instructional Video Generation](https://arxiv.org/abs/2412.04189) (Dec., 2024)
[](https://arxiv.org/abs/2412.04189)
[](https://excitedbutter.github.io/Instructional-Video-Generation/)
+ [Mimir: Improving Video Diffusion Models for Precise Text Understanding](https://arxiv.org/abs/2412.03085) (Dec., 2024)
[](https://arxiv.org/abs/2412.03085)
[](https://lucaria-academy.github.io/Mimir/)
+ [Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling](https://arxiv.org/abs/2411.18664) (Dec., 2024)
[](https://github.com/junhahyung/STGuidance)
[](https://arxiv.org/abs/2411.18664)
[](https://junhahyung.github.io/STGuidance)
+ [Identity-Preserving Text-to-Video Generation by Frequency Decomposition](https://arxiv.org/abs/2411.17440) (Nov., 2024)
[](https://github.com/PKU-YuanGroup/ConsisID)
[](https://arxiv.org/abs/2411.17440)
[](https://pku-yuangroup.github.io/ConsisID/)
[](https://huggingface.co/datasets/BestWishYsh/ConsisID-preview-Data)
+ [WF-VAE: Enhancing Video VAE by Wavelet-Driven Energy Flow for Latent Video Diffusion Model](https://arxiv.org/abs/2411.17459) (Nov., 2024)
[](https://github.com/PKU-YuanGroup/WF-VAE)
[](https://arxiv.org/abs/2411.17459)
[](https://video-repair.github.io/)
+ [VideoRepair: Improving Text-to-Video Generation via Misalignment Evaluation and Localized Refinement](https://arxiv.org/pdf/2411.15115) (Nov., 2024)
[](https://github.com/daeunni/VideoRepair)
[](https://arxiv.org/pdf/2411.15115)
[](https://video-repair.github.io/)
+ [Enhancing Motion in Text-to-Video Generation with Decomposed Encoding and Conditioning](https://arxiv.org/abs/2410.24219) (Oct., 2024 | NeurIPS 2024)
[](https://github.com/PR-Ryan/DEMO)
[](https://arxiv.org/abs/2410.24219)
[](https://pr-ryan.github.io/DEMO-project/)
+ [Improved Video VAE for Latent Video Diffusion Model](https://arxiv.org/abs/2411.06449) (Oct., 2024)
[](https://arxiv.org/abs/2411.06449)
[](https://wpy1999.github.io/IV-VAE/)
+ [VideoAgent: Self-Improving Video Generation](https://arxiv.org/abs/2410.10076)
[](https://arxiv.org/abs/2410.10076)
+ [T2V-Turbo-v2: Enhancing Video Generation Model Post-Training Through Data, Reward, and Conditional Guidance Design](https://arxiv.org/pdf/2410.05677) (Oct, 2024)
[](https://github.com/Ji4chenLi/t2v-turbo)
[](https://arxiv.org/pdf/2410.05677)
[](https://t2v-turbo-v2.github.io/)
+ [Progressive Autoregressive Video Diffusion Models](https://arxiv.org/abs/2410.08151) (Oct., 2024)
[](https://github.com/desaixie/pa_vdm)
[](https://arxiv.org/abs/2410.08151)
[](https://desaixie.github.io/pa-vdm/)
+ [Real-Time Video Generation with Pyramid Attention Broadcast](https://arxiv.org/abs/2408.12588) (Aug., 2024)
[](https://github.com/NUS-HPC-AI-Lab/VideoSys)
[](https://arxiv.org/abs/2408.12588)
+ [xGen-VideoSyn-1: High-fidelity Text-to-Video Synthesis with Compressed Representations](https://arxiv.org/abs/2408.12590) (Aug., 2024)
[](https://github.com/SalesforceAIResearch/xgen-videosyn)
[](https://arxiv.org/abs/2408.12590)
+ [CogVideoX: Text-to-video generation](https://github.com/THUDM/CogVideo/blob/main/resources/CogVideoX.pdf) (Aug., 2024)
[](https://github.com/THUDM/CogVideo)
[](https://github.com/THUDM/CogVideo/blob/main/resources/CogVideoX.pdf)
+ [FreeLong: Training-Free Long Video Generation with SpectralBlend Temporal Attention](https://arxiv.org/abs/2407.19918) (Aug., 2024)
[](https://arxiv.org/abs/2407.19918)
[](https://yulu.net.cn/freelong/)
+ [VEnhancer: Generative Space-Time Enhancement for Video Generation](https://arxiv.org/abs/2407.07667) (Jul., 2024)
[](https://github.com/Vchitect/VEnhancer)
[](https://arxiv.org/abs/2407.07667)
[](https://vchitect.github.io/VEnhancer-project/)
+ [Live2Diff: Live Stream Translation via Uni-directional Attention in Video Diffusion Models](https://arxiv.org/abs/2407.08701) (Jul., 2024)
[](https://github.com/open-mmlab/Live2Diff)
[](https://arxiv.org/abs/2407.08701)
[](https://live2diff.github.io/)
+ [Video Diffusion Alignment via Reward Gradient](https://arxiv.org/abs/2407.08737) (Jul., 2024)
[](https://github.com/mihirp1998/VADER)
[](https://arxiv.org/abs/2407.08737)
[](https://vader-vid.github.io/)
+ [ExVideo: Extending Video Diffusion Models via Parameter-Efficient Post-Tuning](https://arxiv.org/abs/2406.14130) (Jun., 2024)
[](https://arxiv.org/abs/2406.14130)
+ [MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance](https://arxiv.org/abs/2406.19680) (Jul., 2024)
[](https://github.com/Tencent/MimicMotion)
[](https://arxiv.org/abs/2406.19680)
[](https://tencent.github.io/MimicMotion/)
+ [Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model](https://arxiv.org/abs/2406.15735) (Jun., 2024)
[](https://github.com/thu-ml/cond-image-leakage/tree/main?tab=readme-ov-file)
[](https://arxiv.org/abs/2406.15735)
[](https://cond-image-leak.github.io/)
+ [Video-Infinity: Distributed Long Video Generation](https://arxiv.org/abs/2406.16260) (Jun., 2024)
[](https://arxiv.org/abs/2406.16260)
[](https://video-infinity.tanzhenxiong.com/)
+ [MotionBooth: Motion-Aware Customized Text-to-Video Generation](https://arxiv.org/abs/2406.17758) (Jun., 2024)
[](https://arxiv.org/abs/2406.17758)
[](https://jianzongwu.github.io/projects/motionbooth/)
+ [Text-Animator: Controllable Visual Text Video Generation](https://arxiv.org/abs/2406.17777) (Jun., 2024)
[](https://arxiv.org/abs/2406.17777)
[](https://laulampaul.github.io/text-animator.html)
+ [UniAnimate: Taming Unified Video Diffusion Models for Consistent Human Image Animation](https://arxiv.org/abs/2406.01188) (Jun., 2024)
[](https://arxiv.org/abs/2406.01188)
[](https://unianimate.github.io/)
+ [T2V-Turbo: Breaking the Quality Bottleneck of Video Consistency Model with Mixed Reward Feedback](https://arxiv.org/abs/2405.18750) (May, 2024)
[](https://arxiv.org/abs/2405.18750)
[](https://t2v-turbo.github.io/)
+ [Collaborative Video Diffusion: Consistent Multi-video Generation with Camera Control](https://arxiv.org/abs/2405.17414) (May, 2024)
[](https://arxiv.org/abs/2405.17414)
[](https://collaborativevideodiffusion.github.io/)
+ [Human4DiT: Free-view Human Video Generation with 4D Diffusion Transformer](https://arxiv.org/abs/2405.17405) (May, 2024)
[](https://arxiv.org/abs/2405.17405)
[](https://human4dit.github.io/)
+ [FIFO-Diffusion: Generating Infinite Videos from Text without Training](https://arxiv.org/abs/2405.11473) (May, 2024)
[](https://github.com/jjihwan/FIFO-Diffusion_public)
[](https://arxiv.org/abs/2405.11473)
[](https://jjihwan.github.io/projects/FIFO-Diffusion)
+ [Vidu: a Highly Consistent, Dynamic and Skilled Text-to-Video Generator with Diffusion Models](https://arxiv.org/abs/2405.04233) (May, 2024)
[](https://arxiv.org/abs/2405.04233)
[](https://www.shengshu-ai.com/vidu)
+ [Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers](https://arxiv.org/abs/2405.05945) (May, 2024)
[](https://github.com/Alpha-VLLM/Lumina-T2X)
[](https://arxiv.org/abs/2405.05945)
+ [StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation](https://arxiv.org/abs/2405.01434) (May, 2024)
[](https://github.com/HVision-NKU/StoryDiffusion)
[](https://arxiv.org/abs/2405.01434)
[](https://storydiffusion.github.io/)
+ [TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models](https://arxiv.org/abs/2404.16306) (CVPR 2024)
[](https://github.com/merlresearch/TI2V-Zero)
[](https://arxiv.org/abs/2404.16306)
[](https://merl.com/research/highlights/TI2V-Zero)
+ [ID-Animator: Zero-Shot Identity-Preserving Human Video Generation](https://arxiv.org/abs/2404.15275) (Apr., 2024)
[](https://github.com/ID-Animator/ID-Animator)
[](https://arxiv.org/abs/2404.15275)
[](https://id-animator.github.io/)
+ [AnimateZoo: Zero-shot Video Generation of Cross-Species Animation via Subject Alignment](https://arxiv.org/abs/2404.04946) (Apr., 2024)
[](https://github.com/JustinXu0/AnimateZoo)
[](https://arxiv.org/abs/2404.04946)
[](https://justinxu0.github.io/AnimateZoo/)
+ [MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators](https://arxiv.org/abs/2404.05014) (Apr., 2024)
[](https://github.com/PKU-YuanGroup/MagicTime)
[](https://arxiv.org/abs/2404.05014)
[](https://pku-yuangroup.github.io/MagicTime/)
[](https://huggingface.co/datasets/BestWishYsh/ChronoMagic)
+ [TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models](https://arxiv.org/abs/2403.17005) (CVPR 2024)
[](https://arxiv.org/abs/2403.17005)
[](https://trip-i2v.github.io/TRIP/)
+ [VSTAR: Generative Temporal Nursing for Longer Dynamic Video Synthesis](https://arxiv.org/abs/2403.13501) (Mar., 2024)
[](https://arxiv.org/abs/2403.13501)
[](https://yumengli007.github.io/VSTAR/)
+ [StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text](https://arxiv.org/abs/2403.14773) (Mar., 2024)
[](https://github.com/Picsart-AI-Research/StreamingT2V)
[](https://arxiv.org/abs/2403.14773)
[](https://streamingt2v.github.io/)
+ [Intention-driven Ego-to-Exo Video Generation](https://arxiv.org/abs/2403.09194) (Mar., 2024)
[](https://arxiv.org/abs/2403.09194)
+ [VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models](https://arxiv.org/abs/2403.05438) (Mar., 2024)
[](https://github.com/YBYBZhang/VideoElevator)
[](https://arxiv.org/abs/2403.05438)
[](https://videoelevator.github.io/)
+ [Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis](https://arxiv.org/abs/2402.14797) (Feb., 2024)
[](https://arxiv.org/abs/2402.14797)
[](https://snap-research.github.io/snapvideo/)
+ [One-Shot Motion Customization of Text-to-Video Diffusion Models](https://arxiv.org/abs/2402.14780) (Feb., 2024)
[](https://arxiv.org/abs/2402.14780)
[](https://anonymous-314.github.io/)
+ [Magic-Me: Identity-Specific Video Customized Diffusion](https://arxiv.org/abs/2402.09368) (Feb., 2024)
[](https://github.com/Zhen-Dong/Magic-Me)
[](https://arxiv.org/abs/2402.09368)
[](https://magic-me-webpage.github.io/)
+ [ConsistI2V: Enhancing Visual Consistency for Image-to-Video Generation](https://arxiv.org/abs/2402.04324) (Feb., 2024)
[](https://github.com/TIGER-AI-Lab/ConsistI2V)
[](https://arxiv.org/abs/2402.04324)
[](https://tiger-ai-lab.github.io/ConsistI2V/)
+ [Direct-a-Video: Customized Video Generation with User-Directed Camera Movement and Object Motion](https://arxiv.org/abs/2402.03162) (Feb., 2024)
[](https://arxiv.org/abs/2402.03162)
[](https://direct-a-video.github.io/)
+ [Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization](https://arxiv.org/abs/2402.03161) (Feb., 2024)
[](https://github.com/jy0205/LaVIT)
[](https://arxiv.org/abs/2402.03161)
[](https://video-lavit.github.io/)
+ [Boximator: Generating Rich and Controllable Motions for Video Synthesis](https://arxiv.org/abs/2402.01566) (Feb., 2024)
[](https://arxiv.org/abs/2402.01566)
[](https://boximator.github.io/)
+ [Lumiere: A Space-Time Diffusion Model for Video Generation](https://arxiv.org/abs/2401.12945) (Jan., 2024)
[](https://arxiv.org/abs/2401.12945)
[](https://lumiere-video.github.io/)
+ [ActAnywhere: Subject-Aware Video Background Generation](https://arxiv.org/abs/2401.10822) (Jan., 2024)
[](https://arxiv.org/abs/2401.10822)
[](https://actanywhere.github.io/)
+ [WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens](https://arxiv.org/abs/2401.09985) (Jan., 2024)
[](https://github.com/JeffWang987/WorldDreamer)
[](https://arxiv.org/abs/2401.09985)
[](https://world-dreamer.github.io/)
+ [CustomVideo: Customizing Text-to-Video Generation with Multiple Subjects](https://arxiv.org/abs/2401.09962) (Jan., 2024)
[](https://arxiv.org/abs/2401.09962)
[](https://kyfafyd.wang/projects/customvideo/)
+ [UniVG: Towards UNIfied-modal Video Generation](https://arxiv.org/abs/2401.09084) (Jan., 2024)
[](https://arxiv.org/abs/2401.09084)
[](https://univg-baidu.github.io/)
+ [VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models](https://arxiv.org/abs/2401.09047) (Jan., 2024)
[](https://github.com/AILab-CVC/VideoCrafter)
[](https://arxiv.org/abs/2401.09047)
[](https://ailab-cvc.github.io/videocrafter2/)
+ [360DVD: Controllable Panorama Video Generation with 360-Degree Video Diffusion Model](https://arxiv.org/abs/2401.06578) (Jan., 2024)
[](https://arxiv.org/abs/2401.06578)
[](https://akaneqwq.github.io/360DVD/)
+ [RAVEN: Rethinking Adversarial Video Generation with Efficient Tri-plane Networks](https://arxiv.org/abs/2401.06035) (Jan., 2024)
[](https://arxiv.org/abs/2401.06035)
+ [Latte: Latent Diffusion Transformer for Video Generation](https://arxiv.org/abs/2401.03048) (Jan., 2024)
[](https://github.com/Vchitect/Latte)
[](https://arxiv.org/abs/2401.03048)
[](https://maxin-cn.github.io/latte_project/)
+ [MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation](https://arxiv.org/abs/2401.04468) (Jan., 2024)
[](https://arxiv.org/abs/2401.04468)
[](https://magicvideov2.github.io/)
+ [VideoDrafter: Content-Consistent Multi-Scene Video Generation with LLM](https://arxiv.org/abs/2401.01256) (Jan., 2024)
[](https://arxiv.org/abs/2401.01256)
[](https://videodrafter.github.io/)
+ [FlashVideo: A Framework for Swift Inference in Text-to-Video Generation](https://arxiv.org/abs/2401.00869) (Dec., 2023)
[](https://arxiv.org/abs/2401.00869)
+ [I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models](https://arxiv.org/abs/2312.16693) (Dec., 2023)
[](https://arxiv.org/abs/2312.16693)
+ [A Recipe for Scaling up Text-to-Video Generation with Text-free Videos](https://arxiv.org/abs/2312.15770) (Dec., 2023)
[](https://arxiv.org/abs/2312.15770)
[](https://tf-t2v.github.io/)
+ [PIA: Your Personalized Image Animator via Plug-and-Play Modules in Text-to-Image Models](https://arxiv.org/abs/2312.13964) (Dec., 2023)
[](https://github.com/open-mmlab/PIA)
[](https://arxiv.org/abs/2312.13964)
[](https://pi-animator.github.io/)
+ [VideoPoet: A Large Language Model for Zero-Shot Video Generation](https://arxiv.org/abs/2312.14125) (Dec., 2023)
[](https://arxiv.org/abs/2312.14125)
[](https://sites.research.google/videopoet/)
+ [InstructVideo: Instructing Video Diffusion Models with Human Feedback](https://arxiv.org/abs/2312.12490) (Dec., 2023)
[](https://github.com/damo-vilab/i2vgen-xl/blob/main/doc/InstructVideo.md)
[](https://arxiv.org/abs/2312.12490)
[](https://instructvideo.github.io/)
+ [VideoLCM: Video Latent Consistency Model](https://arxiv.org/abs/2312.09109) (Dec., 2023)
[](https://arxiv.org/abs/2312.09109)
+ [PEEKABOO: Interactive Video Generation via Masked-Diffusion](https://arxiv.org/abs/2312.07509) (Dec., 2023)
[](https://github.com/microsoft/Peekaboo)
[](https://arxiv.org/abs/2312.07509)
[](https://jinga-lala.github.io/projects/Peekaboo/)
+ [FreeInit: Bridging Initialization Gap in Video Diffusion Models](https://arxiv.org/abs/2312.07537) (Dec., 2023)
[](https://github.com/TianxingWu/FreeInit)
[](https://arxiv.org/abs/2312.07537)
[](https://tianxingwu.github.io/pages/FreeInit/)
+ [Photorealistic Video Generation with Diffusion Models](https://arxiv.org/abs/2312.06662) (Dec., 2023)
[](https://arxiv.org/abs/2312.06662)
[](https://walt-video-diffusion.github.io/)
+ [Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution](https://arxiv.org/abs/2312.06640) (Dec., 2023)
[](https://github.com/sczhou/Upscale-A-Video)
[](https://arxiv.org/abs/2312.06640)
[](https://shangchenzhou.com/projects/upscale-a-video/)
+ [DreaMoving: A Human Video Generation Framework based on Diffusion Models](https://arxiv.org/abs/2312.05107) (Dec., 2023)
[](https://github.com/dreamoving/dreamoving-project)
[](https://arxiv.org/abs/2312.05107)
[](https://dreamoving.github.io/dreamoving/)
+ [MotionCrafter: One-Shot Motion Customization of Diffusion Models](https://arxiv.org/abs/2312.05288) (Dec., 2023)
[](https://github.com/zyxElsa/MotionCrafter)
[](https://arxiv.org/abs/2312.05288)
+ [AnimateZero: Video Diffusion Models are Zero-Shot Image Animators](https://arxiv.org/abs/2312.03793) (Dec., 2023)
[](https://github.com/vvictoryuki/AnimateZero)
[](https://arxiv.org/abs/2312.03793)
[](https://vvictoryuki.github.io/animatezero.github.io/)
+ [AVID: Any-Length Video Inpainting with Diffusion Model](https://arxiv.org/abs/2312.03816) (Dec., 2023)
[](https://github.com/zhang-zx/AVID)
[](https://arxiv.org/abs/2312.03816)
[](https://zhang-zx.github.io/AVID/)
+ [MTVG : Multi-text Video Generation with Text-to-Video Models](https://arxiv.org/abs/2312.04086) (Dec., 2023)
[](https://arxiv.org/abs/2312.04086)
[](https://kuai-lab.github.io/mtvg-page)
+ [DreamVideo: Composing Your Dream Videos with Customized Subject and Motion](https://arxiv.org/abs/2312.04433) (Dec., 2023)
[](https://github.com/damo-vilab/i2vgen-xl)
[](https://arxiv.org/abs/2312.04433)
[](https://dreamvideo-t2v.github.io/)
+ [Hierarchical Spatio-temporal Decoupling for Text-to-Video Generation](https://arxiv.org/abs/2312.04483) (Dec., 2023)
[](https://github.com/damo-vilab/i2vgen-xl)
[](https://arxiv.org/abs/2312.04483)
[](https://higen-t2v.github.io/)
+ [GenTron: Delving Deep into Diffusion Transformers for Image and Video Generation](https://arxiv.org/abs/2312.04557) (CVPR 2024)
[](https://arxiv.org/abs/2312.04557)
[](https://www.shoufachen.com/gentron_website/)
+ [GenDeF: Learning Generative Deformation Field for Video Generation](https://arxiv.org/abs/2312.04561) (Dec., 2023)
[](https://github.com/aim-uofa/GenDeF)
[](https://arxiv.org/abs/2312.04561)
[](https://aim-uofa.github.io/GenDeF/)
+ [F3-Pruning: A Training-Free and Generalized Pruning Strategy towards Faster and Finer Text-to-Video Synthesis](https://arxiv.org/abs/2312.03459) (Dec., 2023)
[](https://arxiv.org/abs/2312.03459)
+ [DreamVideo: High-Fidelity Image-to-Video Generation with Image Retention and Text Guidance](https://arxiv.org/abs/2312.03018) (Dec., 2023)
[](https://github.com/anonymous0769/DreamVideo)
[](https://arxiv.org/abs/2312.03018)
[](https://anonymous0769.github.io/DreamVideo/)
+ [LivePhoto: Real Image Animation with Text-guided Motion Control](https://arxiv.org/abs/2312.02928) (Dec., 2023)
[](https://github.com/XavierCHEN34/LivePhoto)
[](https://arxiv.org/abs/2312.02928)
[](https://xavierchen34.github.io/LivePhoto-Page/)
+ [Fine-grained Controllable Video Generation via Object Appearance and Context](https://arxiv.org/abs/2312.02919) (Dec., 2023)
[](https://arxiv.org/abs/2312.02919)
[](https://hhsinping.github.io/factor/)
+ [VideoBooth: Diffusion-based Video Generation with Image Prompts](https://arxiv.org/abs/2312.00777) (Dec., 2023)
[](https://github.com/Vchitect/VideoBooth)
[](https://arxiv.org/abs/2312.00777)
[](https://vchitect.github.io/VideoBooth-project/)
+ [StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter](https://arxiv.org/abs/2312.00330) (Dec., 2023)
[](https://github.com/GongyeLiu/StyleCrafter)
[](https://arxiv.org/abs/2312.00330)
[](https://gongyeliu.github.io/StyleCrafter.github.io/)
+ [MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation](https://arxiv.org/abs/2311.18829) (Nov., 2023)
[](https://arxiv.org/abs/2311.18829)
[](https://wangyanhui666.github.io/MicroCinema.github.io/)
+ [ART•V: Auto-Regressive Text-to-Video Generation with Diffusion Models](https://arxiv.org/abs/2311.18834) (Nov., 2023)
[](https://github.com/WarranWeng/ART.V)
[](https://arxiv.org/abs/2311.18834)
[](https://warranweng.github.io/art.v/)
+ [Smooth Video Synthesis with Noise Constraints on Diffusion Models for One-shot Video Tuning](https://arxiv.org/abs/2311.17536) (Nov., 2023)
[](https://github.com/SPengLiang/SmoothVideo)
[](https://arxiv.org/abs/2311.17536)
+ [VideoAssembler: Identity-Consistent Video Generation with Reference Entities using Diffusion Model](https://arxiv.org/abs/2311.17338) (Nov., 2023)
[](https://arxiv.org/abs/2311.17338)
[](https://videoassembler.github.io/videoassembler/)
+ [MotionZero:Exploiting Motion Priors for Zero-shot Text-to-Video Generation](https://arxiv.org/abs/2311.16635) (Nov., 2023)
[](https://arxiv.org/abs/2311.16635)
+ [MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model](https://arxiv.org/abs/2311.16498) (Nov., 2023)
[](https://github.com/magic-research/magic-animate)
[](https://arxiv.org/abs/2311.16498)
[](https://showlab.github.io/magicanimate)
+ [FlowZero: Zero-Shot Text-to-Video Synthesis with LLM-Driven Dynamic Scene Syntax](https://arxiv.org/abs/2311.15813) (Nov., 2023)
[](https://github.com/aniki-ly/FlowZero)
[](https://arxiv.org/abs/2311.15813)
[](https://flowzero-video.github.io/)
+ [Sketch Video Synthesis](https://arxiv.org/abs/2311.15306) (Nov., 2023)
[](https://github.com/yudianzheng/SketchVideo)
[](https://arxiv.org/abs/2311.15306)
[](https://sketchvideo.github.io/)
+ [Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets](https://arxiv.org/abs/2311.15127) (Nov., 2023)
[](https://github.com/Stability-AI/generative-models)
[](https://arxiv.org/abs/2311.15127)
[](https://stability.ai/news/stable-video-diffusion-open-ai-video-model)
+ [Decouple Content and Motion for Conditional Image-to-Video Generation](https://arxiv.org/abs/2311.14294) (Nov., 2023)
[](https://arxiv.org/abs/2311.14294)
+ [FusionFrames: Efficient Architectural Aspects for Text-to-Video Generation Pipeline](https://arxiv.org/abs/2311.13073) (Nov., 2023)
[](https://github.com/ai-forever/KandinskyVideo)
[](https://arxiv.org/abs/2311.13073)
[](https://ai-forever.github.io/kandinsky-video/)
+ [Fine-Grained Open Domain Image Animation with Motion Guidance](https://arxiv.org/abs/2311.12886) (Nov., 2023)
[](https://github.com/alibaba/animate-anything)
[](https://arxiv.org/abs/2311.12886)
[](https://animationai.github.io/AnimateAnything/)
+ [GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning](https://arxiv.org/abs/2311.12631) (Nov., 2023)
[](https://github.com/jiaxilv/GPT4Motion)
[](https://arxiv.org/abs/2311.12631)
[](https://gpt4motion.github.io/)
+ [MagicDance: Realistic Human Dance Video Generation with Motions & Facial Expressions Transfer](https://arxiv.org/abs/2311.12052) (Nov., 2023)
[](https://github.com/Boese0601/MagicDance)
[](https://arxiv.org/abs/2311.12052)
[](https://boese0601.github.io/magicdance/)
+ [MoVideo: Motion-Aware Video Generation with Diffusion Models](https://arxiv.org/abs/2311.11325) (Nov., 2023)
[](https://arxiv.org/abs/2311.11325)
[](https://jingyunliang.github.io/MoVideo/)
+ [Make Pixels Dance: High-Dynamic Video Generation](https://arxiv.org/abs/2311.10982) (Nov., 2023)
[](https://arxiv.org/abs/2311.10982)
[](https://makepixelsdance.github.io/)
+ [Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning](https://arxiv.org/abs/2311.10709) (Nov., 2023)
[](https://arxiv.org/abs/2311.10709)
[](https://emu-video.metademolab.com/)
+ [Optimal Noise pursuit for Augmenting Text-to-Video Generation](https://arxiv.org/abs/2311.00949) (Nov., 2023)
[](https://arxiv.org/abs/2311.00949)
+ [VideoDreamer: Customized Multi-Subject Text-to-Video Generation with Disen-Mix Finetuning](https://arxiv.org/abs/2311.00990) (Nov., 2023)
[](https://github.com/videodreamer23/videodreamer23.github.io)
[](https://arxiv.org/abs/2311.00990)
[](https://videodreamer23.github.io/)
+ [SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction](https://arxiv.org/abs/2310.20700) (Oct., 2023)
[](https://github.com/Vchitect/SEINE)
[](https://arxiv.org/abs/2310.20700)
[](https://vchitect.github.io/SEINE-project/)
+ [FreeNoise: Tuning-Free Longer Video Diffusion Via Noise Rescheduling](https://arxiv.org/abs/2310.15169) (Oct., 2023)
[](https://github.com/arthur-qiu/LongerCrafter)
[](https://arxiv.org/abs/2310.15169)
[](http://haonanqiu.com/projects/FreeNoise.html)
+ [DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors](https://arxiv.org/abs/2310.12190) (Oct., 2023)
[](https://github.com/Doubiiu/DynamiCrafter)
[](https://arxiv.org/abs/2310.12190)
[](https://doubiiu.github.io/projects/DynamiCrafter/)
+ [LAMP: Learn A Motion Pattern for Few-Shot-Based Video Generation](https://arxiv.org/abs/2310.10769) (Oct., 2023)
[](https://github.com/RQ-Wu/LAMP)
[](https://arxiv.org/abs/2310.10769)
[](https://rq-wu.github.io/projects/LAMP/)
+ [Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation](https://arxiv.org/abs/2309.15818) (Sep., 2023)
[](https://github.com/showlab/Show-1)
[](https://arxiv.org/abs/2309.15818)
[](https://showlab.github.io/Show-1/)
+ [MotionDirector: Motion Customization of Text-to-Video Diffusion Models](https://arxiv.org/abs/2310.08465) (Sep., 2023)
[](https://github.com/showlab/MotionDirector)
[](https://arxiv.org/abs/2310.08465)
[](https://showlab.github.io/MotionDirector/)
+ [LAVIE: High-Quality Video Generation with Cascaded Latent Diffusion Models](https://arxiv.org/abs/2309.15103) (Sep., 2023)
[](https://github.com/Vchitect/LaVie)
[](https://arxiv.org/abs/2309.15103)
[](https://vchitect.github.io/LaVie-project/)
+ [Free-Bloom: Zero-Shot Text-to-Video Generator with LLM Director and LDM Animator](https://arxiv.org/abs/2309.14494) (Sep., 2023)
[](https://github.com/SooLab/Free-Bloom)
[](https://arxiv.org/abs/2309.14494)
+ [Hierarchical Masked 3D Diffusion Model for Video Outpainting](https://arxiv.org/abs/2309.02119) (Sep., 2023)
[](https://arxiv.org/abs/2309.02119)
[](https://fanfanda.github.io/M3DDM/)
+ [Reuse and Diffuse: Iterative Denoising for Text-to-Video Generation](https://arxiv.org/abs/2309.03549) (Sep., 2023)
[](https://github.com/anonymous0x233/ReuseAndDiffuse)
[](https://arxiv.org/abs/2309.03549)
[](https://anonymous0x233.github.io/ReuseAndDiffuse/)
+ [VideoGen: A Reference-Guided Latent Diffusion Approach for High Definition Text-to-Video Generation](https://arxiv.org/abs/2309.00398) (Sep., 2023)
[](https://arxiv.org/abs/2309.00398)
+ [MagicAvatar: Multimodal Avatar Generation and Animation](https://arxiv.org/abs/2308.14748) (Aug., 2023)
[](https://github.com/magic-research/magic-avatar)
[](https://arxiv.org/abs/2308.14748)
[](https://magic-avatar.github.io/)
+ [Empowering Dynamics-aware Text-to-Video Diffusion with Large Language Models](https://arxiv.org/abs/2308.13812) (Aug., 2023)
[](https://github.com/scofield7419/Dysen)
[](https://arxiv.org/abs/2308.13812)
[](https://haofei.vip/Dysen-VDM/)
+ [SimDA: Simple Diffusion Adapter for Efficient Video Generation](https://arxiv.org/abs/2308.09710) (Aug., 2023)
[](https://github.com/ChenHsing/SimDA)
[](https://arxiv.org/abs/2308.09710)
[](https://chenhsing.github.io/SimDA/)
+ [ModelScope Text-to-Video Technical Report](https://arxiv.org/abs/2308.06571) (Aug., 2023)
[](https://arxiv.org/abs/2308.06571)
[](https://modelscope.cn/models/damo/text-to-video-synthesis/summary)
+ [Dual-Stream Diffusion Net for Text-to-Video Generation](https://arxiv.org/abs/2308.08316) (Aug., 2023)
[](https://arxiv.org/abs/2308.08316)
[](https://anonymous.4open.science/r/Private-C3E8)
+ [InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation](https://arxiv.org/abs/2307.06942) (Jul., 2023)
[](https://github.com/OpenGVLab/InternVideo/tree/main/Data/InternVid)
[](https://arxiv.org/abs/2307.06942)
+ [Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation](https://arxiv.org/abs/2307.06940) (Jul., 2023)
[](https://github.com/VideoCrafter/Animate-A-Story)
[](https://arxiv.org/abs/2307.06940)
[](https://videocrafter.github.io/Animate-A-Story/)
+ [AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning](https://arxiv.org/abs/2307.04725) (Jul., 2023)
[](https://github.com/guoyww/animatediff/)
[](https://arxiv.org/abs/2307.04725)
[](https://animatediff.github.io/)
+ [DisCo: Disentangled Control for Referring Human Dance Generation in Real World](https://arxiv.org/abs/2307.000400) (Jul., 2023)
[](https://github.com/Wangt-CN/DisCo)
[](https://arxiv.org/abs/2307.00040)
[](https://disco-dance.github.io/)
+ [Learn the Force We Can: Enabling Sparse Motion Control in Multi-Object Video Generation](https://arxiv.org/abs/2306.03988) (Jun., 2023)
[](https://github.com/araachie/yoda)
[](https://arxiv.org/abs/2306.03988)
[](https://araachie.github.io/yoda/)
+ [VideoComposer: Compositional Video Synthesis with Motion Controllability](https://arxiv.org/abs/2306.02018) (Jun., 2023)
[](https://github.com/damo-vilab/videocomposer)
[](https://arxiv.org/abs/2306.02018)
[](https://videocomposer.github.io/)
+ [Probabilistic Adaptation of Text-to-Video Models](https://arxiv.org/abs/2306.01872) (Jun., 2023)
[](https://arxiv.org/abs/2306.01872)
[](https://video-adapter.github.io/video-adapter/)
+ [Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance](https://arxiv.org/abs/2306.00943) (Jun., 2023)
[](https://github.com/VideoCrafter/Make-Your-Video)
[](https://arxiv.org/abs/2306.00943)
[](https://doubiiu.github.io/projects/Make-Your-Video/)
+ [Gen-L-Video: Multi-Text to Long Video Generation via Temporal Co-Denoising](https://arxiv.org/abs/2305.18264) (May, 2023)
[](https://github.com/G-U-N/Gen-L-Video)
[](https://arxiv.org/abs/2305.18264)
[](https://g-u-n.github.io/projects/gen-long-video/index.html)
+ [Cinematic Mindscapes: High-quality Video Reconstruction from Brain Activity](https://arxiv.org/abs/2305.11675) (May, 2023)
[](https://github.com/jqin4749/MindVideo)
[](https://arxiv.org/abs/2305.11675)
[](https://mind-video.com/)
+ [Any-to-Any Generation via Composable Diffusion](https://arxiv.org/abs/2305.11846) (May, 2023)
[](https://github.com/microsoft/i-Code/tree/main/i-Code-V3)
[](https://arxiv.org/abs/2305.11846)
[](https://codi-gen.github.io/)
+ [VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation](https://arxiv.org/abs/2305.10874) (May, 2023)
[](https://arxiv.org/abs/2305.10874)
+ [Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models](https://arxiv.org/abs/2305.10474) (May, 2023)
[](https://arxiv.org/abs/2305.10474)
[](https://research.nvidia.com/labs/dir/pyoco/)
+ [LaMD: Latent Motion Diffusion for Video Generation](https://arxiv.org/abs/2304.11603) (Apr., 2023)
[](https://arxiv.org/abs/2304.11603)
+ [Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2304.08818) (CVPR 2023)
[](https://arxiv.org/abs/2304.08818)
[](https://research.nvidia.com/labs/toronto-ai/VideoLDM/)
+ [Text2Performer: Text-Driven Human Video Generation](https://arxiv.org/abs/2304.08483) (Apr., 2023)
[](https://github.com/yumingj/Text2Performer)
[](https://arxiv.org/abs/2304.08483)
[](https://yumingj.github.io/projects/Text2Performer)
+ [Generative Disco: Text-to-Video Generation for Music Visualization](https://arxiv.org/abs/2304.08551) (Apr., 2023)
[](https://arxiv.org/abs/2304.08551)
+ [Latent-Shift: Latent Diffusion with Temporal Shift](https://arxiv.org/abs/2304.08477) (Apr., 2023)
[](https://arxiv.org/abs/2304.08477)
[](https://latent-shift.github.io/)
+ [DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion](https://arxiv.org/abs/2304.06025) (Apr., 2023)
[](https://github.com/johannakarras/DreamPose)
[](https://arxiv.org/abs/2304.06025)
[](https://grail.cs.washington.edu/projects/dreampose/)
+ [Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos](https://arxiv.org/abs/2304.01186) (Apr., 2023)
[](https://github.com/mayuelala/FollowYourPose)
[](https://arxiv.org/abs/2304.01186)
[](https://follow-your-pose.github.io/)
+ [Physics-Driven Diffusion Models for Impact Sound Synthesis from Videos](https://arxiv.org/abs/2303.16897) (CVPR 2023)
[](https://github.com/sukun1045/video-physics-sound-diffusion)
[](https://arxiv.org/abs/2303.16897)
[](https://sukun1045.github.io/video-physics-sound-diffusion/)
+ [Seer: Language Instructed Video Prediction with Latent Diffusion Models](https://arxiv.org/abs/2303.14897) (Mar., 2023)
[](https://arxiv.org/abs/2303.14897)
[](https://seervideodiffusion.github.io/)
+ [Text2video-Zero: Text-to-Image Diffusion Models Are Zero-Shot Video Generators](https://arxiv.org/abs/2303.13439) (Mar., 2023)
[](https://github.com/Picsart-AI-Research/Text2Video-Zero)
[](https://arxiv.org/abs/2303.13439)
[](https://text2video-zero.github.io/)
+ [Conditional Image-to-Video Generation with Latent Flow Diffusion Models](https://arxiv.org/abs/2303.13744) (CVPR 2023)
[](https://github.com/nihaomiao/CVPR23_LFDM)
[](https://arxiv.org/abs/2303.13744)
+ [Decomposed Diffusion Models for High-Quality Video Generation](https://arxiv.org/abs/2303.08320) (CVPR 2023)
[](https://arxiv.org/abs/2303.08320)
[](https://modelscope.cn/models/damo/text-to-video-synthesis/summary)
+ [Video Probabilistic Diffusion Models in Projected Latent Space](https://arxiv.org/abs/2302.07685) (CVPR 2023)
[](https://github.com/sihyun-yu/PVDM)
[](https://arxiv.org/abs/2302.07685)
[](https://sihyun.me/PVDM/)
+ [Learning 3D Photography Videos via Self-supervised Diffusion on Single Images](https://arxiv.org/abs/2302.10781) (Feb., 2023)
[](https://arxiv.org/abs/2302.10781)
+ [Structure and Content-Guided Video Synthesis With Diffusion Models](https://arxiv.org/abs/2302.03011) (Feb., 2023)
[](https://arxiv.org/abs/2302.03011)
[](https://research.runwayml.com/gen2)
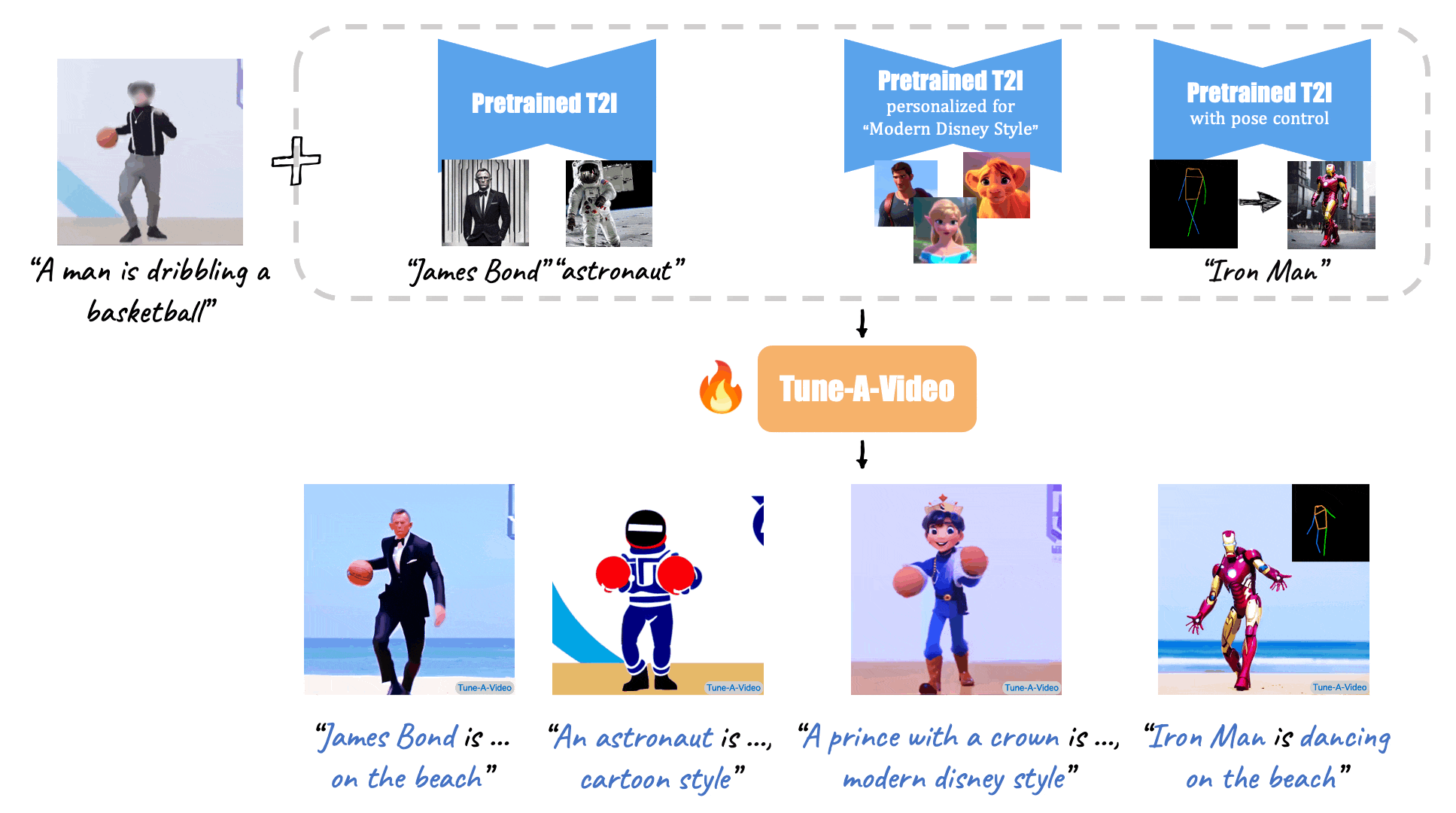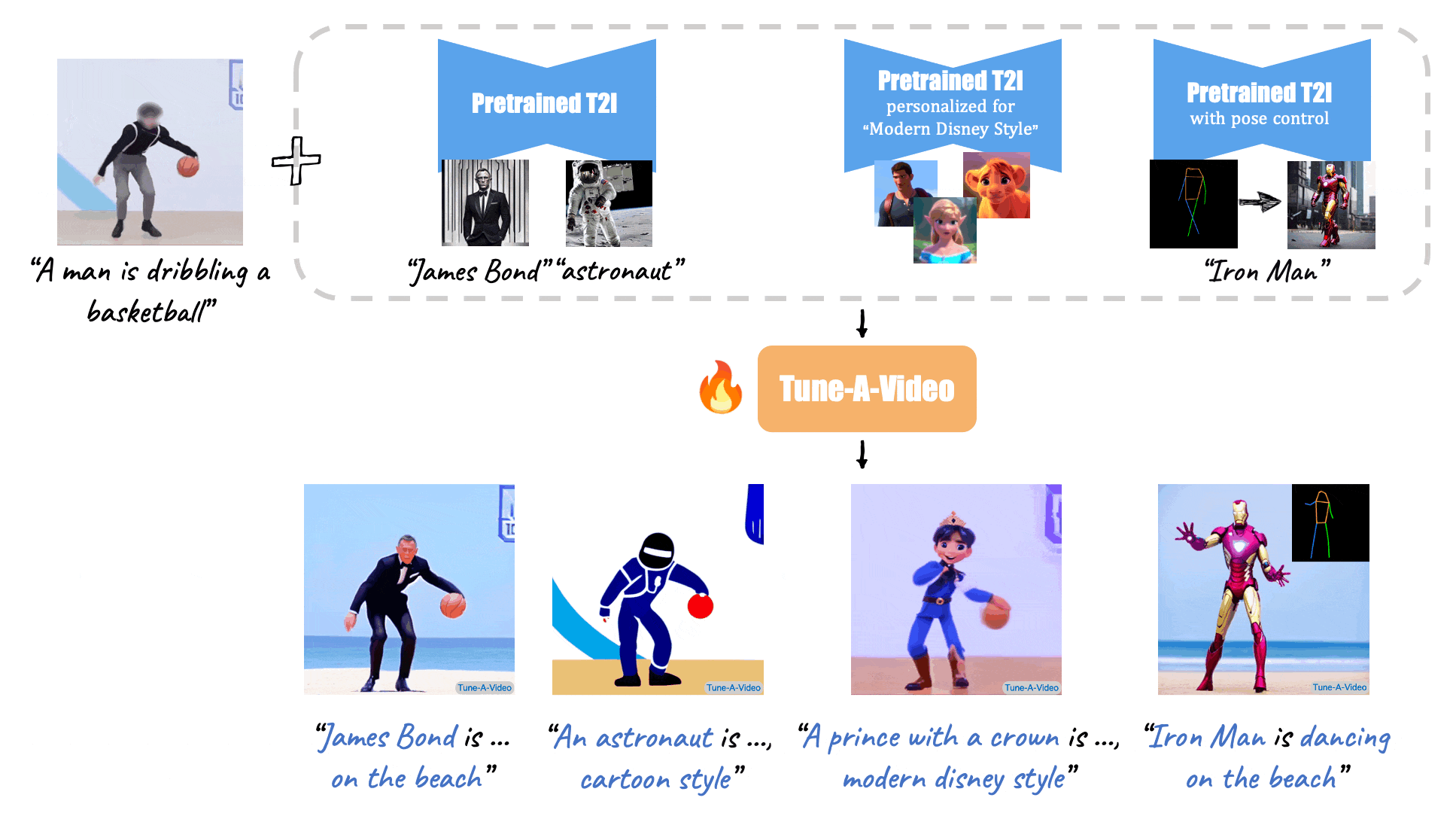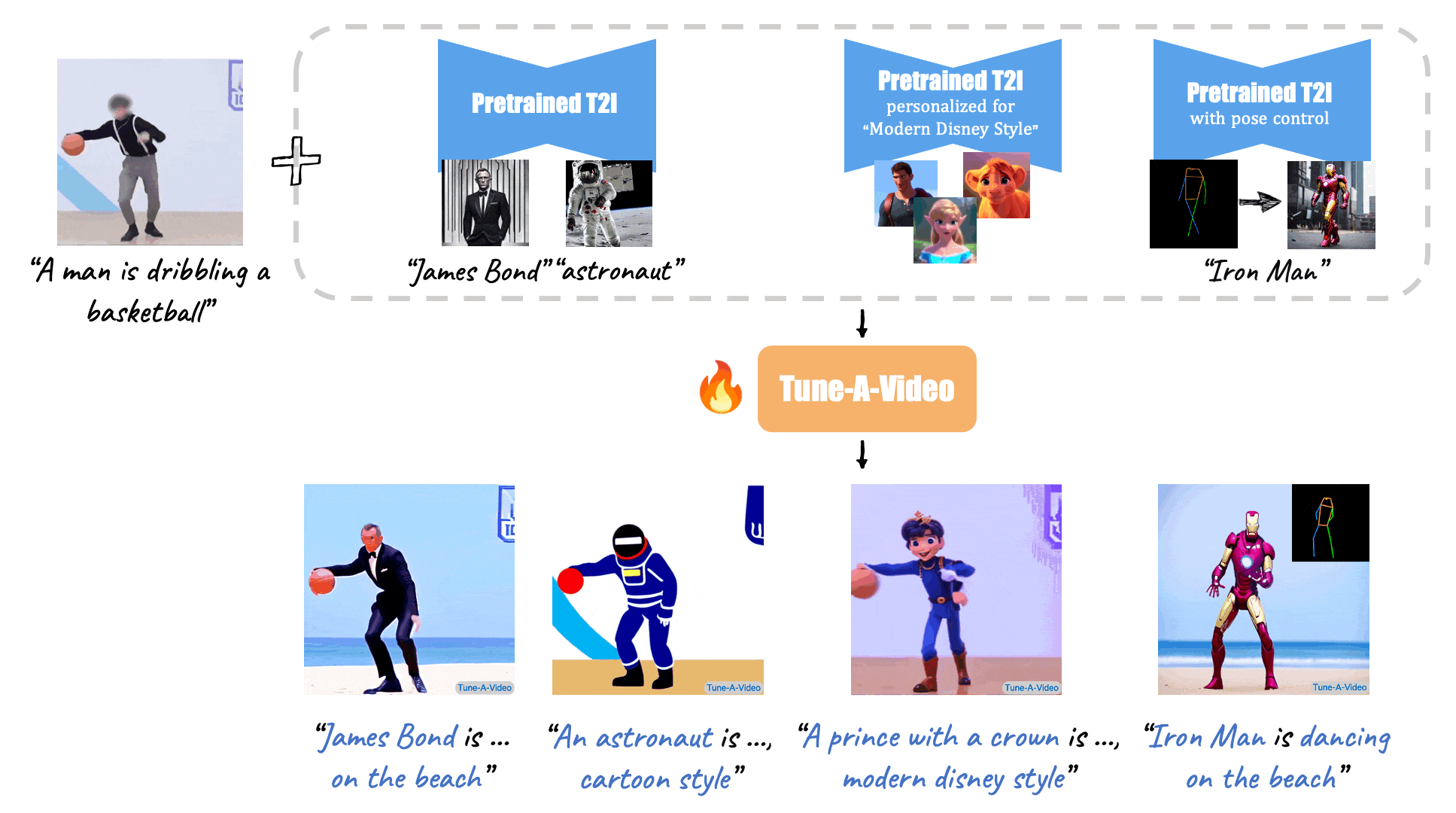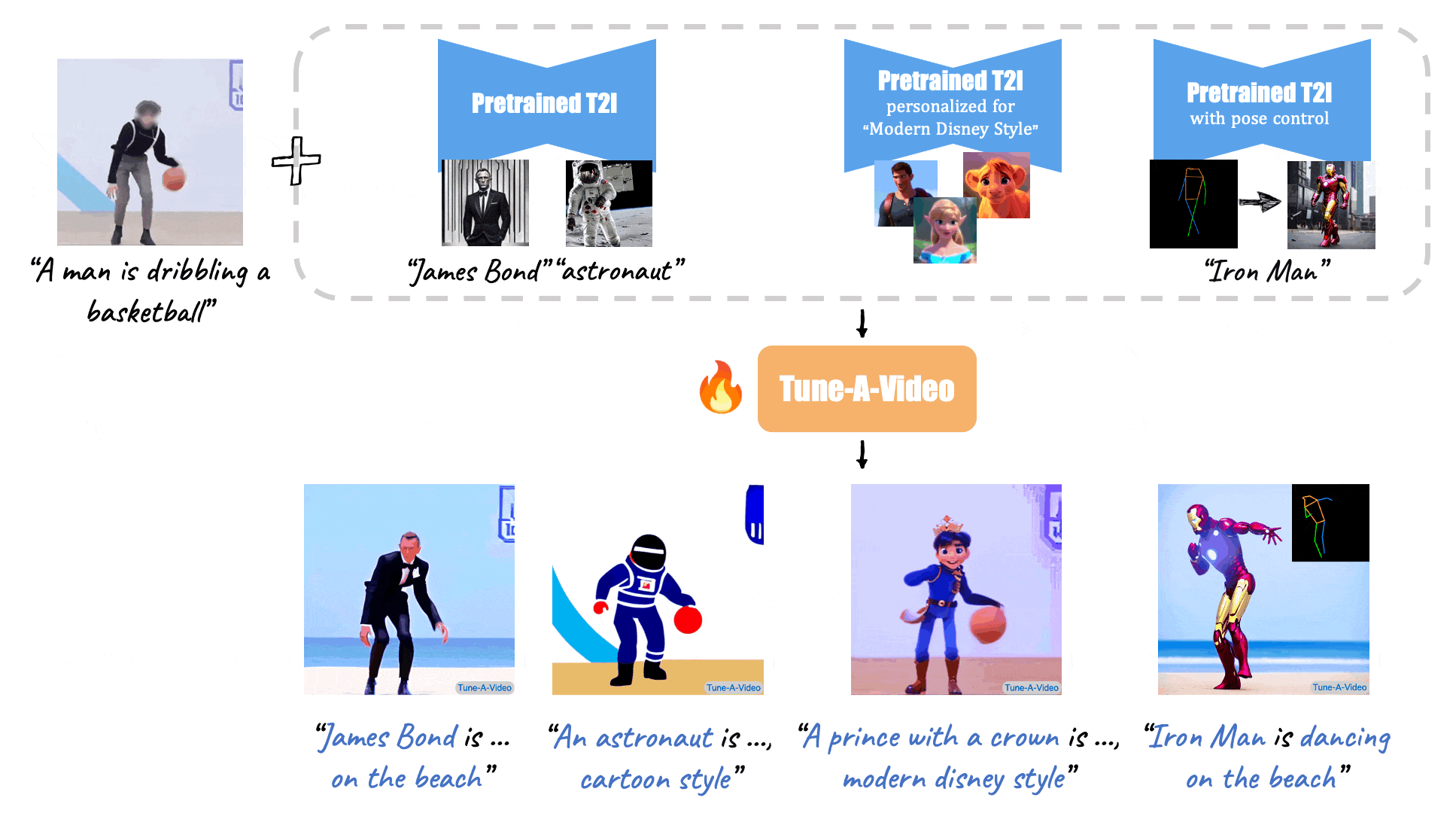
+ [Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation](https://arxiv.org/abs/2212.11565) (ICCV 2023)
[](https://github.com/showlab/Tune-A-Video)
[](https://arxiv.org/abs/2212.11565)
[](https://tuneavideo.github.io/)
+ [Mm-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation](https://arxiv.org/abs/2212.09478) (CVPR 2023)
[](https://github.com/researchmm/MM-Diffusion)
[](https://arxiv.org/abs/2212.09478)
+ [Magvit: Masked Generative Video Transformer](https://arxiv.org/abs/2212.05199) (Dec., 2022)
[](https://github.com/MAGVIT/magvit)
[](https://arxiv.org/abs/2212.05199)
[](https://magvit.cs.cmu.edu/)
+ [VIDM: Video Implicit Diffusion Models](https://arxiv.org/abs/2212.00235) (AAAI 2023)
[](https://github.com/MKFMIKU/VIDM)
[](https://arxiv.org/abs/2212.00235)
[](https://kfmei.page/vidm/)
+ [Efficient Video Prediction via Sparsely Conditioned Flow Matching](https://arxiv.org/abs/2211.14575) (Nov., 2022)
[](https://github.com/araachie/river)
[](https://arxiv.org/abs/2211.14575)
[](https://araachie.github.io/river/)
+ [Latent Video Diffusion Models for High-Fidelity Video Generation With Arbitrary Lengths](https://arxiv.org/abs/2211.13221) (Nov., 2022)
[](https://github.com/YingqingHe/LVDM)
[](https://arxiv.org/abs/2211.13221)
[](https://yingqinghe.github.io/LVDM/)
+ [SinFusion: Training Diffusion Models on a Single Image or Video](https://arxiv.org/abs/2211.11743) (Nov., 2022)
[](https://github.com/yanivnik/sinfusion-code)
[](https://arxiv.org/abs/2211.11743)
[](https://yanivnik.github.io/sinfusion/)
+ [MagicVideo: Efficient Video Generation With Latent Diffusion Models](https://arxiv.org/abs/2211.11018) (Nov., 2022)
[](https://arxiv.org/abs/2211.11018)
[](https://magicvideo.github.io/#)
+ [Imagen Video: High Definition Video Generation With Diffusion Models](https://arxiv.org/abs/2210.02303) (Oct., 2022)
[](https://arxiv.org/abs/2210.02303)
[](https://imagen.research.google/video/)
+ [Make-A-Video: Text-to-Video Generation without Text-Video Data](https://openreview.net/forum?id=nJfylDvgzlq) (ICLR 2023)
[](https://openreview.net/forum?id=nJfylDvgzlq)
[](https://makeavideo.studio)
+ [Diffusion Models for Video Prediction and Infilling](https://arxiv.org/abs/2206.07696) (TMLR 2022)
[](https://github.com/Tobi-r9/RaMViD)
[](https://arxiv.org/abs/2206.07696)
[](https://sites.google.com/view/video-diffusion-prediction)
+ [McVd: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation](https://arxiv.org/abs/2205.09853) (NeurIPS 2022)
[](https://github.com/voletiv/mcvd-pytorch)
[](https://arxiv.org/abs/2205.09853)
[](https://mask-cond-video-diffusion.github.io)
+ [Video Diffusion Models](https://arxiv.org/abs/2204.03458) (Apr., 2022)
[](https://arxiv.org/abs/2204.03458)
[](https://video-diffusion.github.io/)
+ [Diffusion Probabilistic Modeling for Video Generation](https://arxiv.org/abs/2203.09481) (Mar., 2022)
[](https://github.com/buggyyang/RVD)
[](https://arxiv.org/abs/2203.09481)
### Efficient Video Generation
+ [SpargeAttn: Accurate Sparse Attention Accelerating Any Model Inference](https://arxiv.org/abs/2502.18137) (Feb., 2025)
[](https://github.com/thu-ml/SpargeAttn)
[](https://arxiv.org/abs/2502.18137)
+ [SageAttention2: Efficient Attention with Thorough Outlier Smoothing and Per-thread INT4 Quantization](https://arxiv.org/abs/2411.10958) (Feb., 2025)
[](https://github.com/thu-ml/SageAttention)
[](https://arxiv.org/abs/2411.10958)
+ [FlashVideo:Flowing Fidelity to Detail for Efficient High-Resolution Video Generation](https://arxiv.org/abs/2502.05179) (Feb., 2025)
[](https://github.com/FoundationVision/FlashVideo)
[](https://arxiv.org/abs/2502.05179)
+ [Fast Video Generation with Sliding Tile Attention](https://arxiv.org/abs/2502.04507) (Feb, 2025)
[](https://arxiv.org/abs/2502.04507)
+ [Sparse VideoGen: Accelerating Video Diffusion Transformers with Spatial-Temporal Sparsity](https://arxiv.org/abs/2502.01776) (Feb, 2025)
[](https://arxiv.org/abs/2502.01776)
+ [Diffusion Adversarial Post-Training for One-Step Video Generation](https://arxiv.org/abs/2501.08316) (Jan, 2025)
[](https://arxiv.org/abs/2501.08316)
+ [From Slow Bidirectional to Fast Causal Video Generators](https://arxiv.org/pdf/2412.07772) (Dec., 2024)
[](https://arxiv.org/pdf/2412.07772)
[](https://causvid.github.io/)
+ [SnapGen-V: Generating a Five-Second Video within Five Seconds on a Mobile Device](https://arxiv.org/pdf/2412.10494) (Dec., 2024)
[](https://arxiv.org/pdf/2412.10494)
[](https://snap-research.github.io/snapgen-v/)
+ [Mobile Video Diffusion](https://arxiv.org/abs/2412.07583) (Dec., 2024)
[](https://arxiv.org/abs/2412.07583)
[](https://qualcomm-ai-research.github.io/mobile-video-diffusion/)
+ [MoViE: Mobile Diffusion for Video Editing](https://arxiv.org/abs/2412.06578) (Dec., 2024)
[](https://arxiv.org/abs/2412.06578)
[](https://qualcomm-ai-research.github.io/mobile-video-editing/)
+ [Individual Content and Motion Dynamics Preserved Pruning for Video Diffusion Models](https://arxiv.org/abs/2411.18375) (Nov., 2024)
[](https://arxiv.org/abs/2411.18375)
+ [Adaptive Caching for Faster Video Generation with Diffusion Transformers](https://arxiv.org/pdf/2411.02397) (Nov., 2024)
[](https://github.com/AdaCache-DiT/AdaCache)
[](https://arxiv.org/pdf/2411.02397)
[](https://adacache-dit.github.io/)
+ [Fast and Memory-Efficient Video Diffusion Using Streamlined Inference](https://arxiv.org/abs/2411.01171) (Nov., 2024)
[](https://arxiv.org/abs/2411.01171)
+ [SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration](https://arxiv.org/abs/2410.02367) (Oct., 2024)
[](https://github.com/thu-ml/SageAttention)
[](https://arxiv.org/abs/2410.02367)
### Controllable Video Generation
+ [SketchVideo: Sketch-based Video Generation and Editing](https://arxiv.org/abs/2503.23284) (Apr., 2025)
[](https://github.com/IGLICT/SketchVideo)
[](https://arxiv.org/abs/2503.23284)
[](http://geometrylearning.com/SketchVideo/)
+ [Any2Caption:Interpreting Any Condition to Caption for Controllable Video Generation](https://arxiv.org/abs/2503.24379) (Apr., 2025)
[](https://arxiv.org/abs/2503.24379)
[](https://sqwu.top/Any2Cap/)
+ [Reangle-A-Video: 4D Video Generation as Video-to-Video Translation](https://arxiv.org/abs/2503.09151) (Mar., 2025)
[](https://github.com/HyeonHo99/Reangle-Video)
[](https://arxiv.org/abs/2503.09151)
[](https://hyeonho99.github.io/reangle-a-video/)
+ [DynamiCtrl: Rethinking the Basic Structure and the Role of Text for High-quality Human Image Animation](https://arxiv.org/abs/2503.21246) (Mar., 2025)
[](https://github.com/gulucaptain/DynamiCtrl)
[](https://arxiv.org/abs/2503.21246)
[](https://gulucaptain.github.io/DynamiCtrl/)
+ [HunyuanPortrait: Implicit Condition Control for Enhanced Portrait Animation](https://arxiv.org/pdf/2503.18860) (Mar., 2025)
[](https://github.com/kkakkkka/HunyuanPortrait)
[](https://arxiv.org/pdf/2503.18860)
[](https://kkakkkka.github.io/HunyuanPortrait/)
+ [Enabling Versatile Controls for Video Diffusion Models](https://arxiv.org/abs/2503.16983) (Mar., 2025)
[](https://arxiv.org/abs/2503.16421)
+ [MagicMotion: Controllable Video Generation with Dense-to-Sparse Trajectory Guidance](https://arxiv.org/abs/2503.16421) (Mar., 2025)
[](https://github.com/quanhaol/MagicMotion)
[](https://arxiv.org/abs/2503.16421)
[](https://quanhaol.github.io/magicmotion-site/)
+ [MusicInfuser: Making Video Diffusion Listen and Dance](https://arxiv.org/abs/2503.14505) (Mar., 2025)
[](https://github.com/SusungHong/MusicInfuser)
[](https://arxiv.org/abs/2503.14505)
[](https://susunghong.github.io/MusicInfuser)
+ [ReCamMaster: Camera-Controlled Generative Rendering from A Single Video](https://arxiv.org/abs/2503.11647) (Mar., 2025)
[](https://github.com/KwaiVGI/ReCamMaster)
[](https://arxiv.org/abs/2503.11647)
[](https://jianhongbai.github.io/ReCamMaster/)
+ [CameraCtrl II: Dynamic Scene Exploration via Camera-controlled Video Diffusion Models](https://arxiv.org/abs/2503.10592) (Mar., 2025)
[](https://arxiv.org/abs/2503.10592)
[](https://hehao13.github.io/Projects-CameraCtrl-II/)
+ [GEN3C: 3D-Informed World-Consistent Video Generation with Precise Camera Control](https://arxiv.org/abs/2503.03751) (Mar., 2025 | CVPR 2025)
[](https://github.com/nv-tlabs/GEN3C)
[](https://arxiv.org/abs/2503.03751)
[](https://research.nvidia.com/labs/toronto-ai/GEN3C/)
+ [C-Drag: Chain-of-Thought Driven Motion Controller for Video Generation](https://arxiv.org/abs/2502.19868) (Feb., 2025)
[](https://github.com/WesLee88524/C-Drag-Official-Repo)
[](https://arxiv.org/abs/2502.19868)
+ [X-Dancer: Expressive Music to Human Dance Video Generation](https://arxiv.org/pdf/2502.17414) (Feb., 2025)
[](https://arxiv.org/pdf/2502.17414)
+ [CineMaster: A 3D-Aware and Controllable Framework for Cinematic Text-to-Video Generation](https://arxiv.org/abs/2502.08639) (Feb., 2025)
[](https://arxiv.org/abs/2502.08639)
[](https://cinemaster-dev.github.io/)
+ [RealCam-I2V: Real-World Image-to-Video Generation with Interactive Complex Camera Control](https://arxiv.org/abs/2502.10059) (Feb., 2025)
[](https://arxiv.org/abs/2502.10059)
[](https://zgctroy.github.io/RealCam-I2V/)
+ [AnyCharV: Bootstrap Controllable Character Video Generation with Fine-to-Coarse Guidance](https://arxiv.org/abs/2502.08189) (Feb., 2025)
[](https://github.com/AnyCharV/AnyCharV)
[](https://arxiv.org/abs/2502.08189)
[](https://anycharv.github.io/)
+ [A 3D-Aware and Controllable Framework for Cinematic Text-to-Video Generation](https://arxiv.org/abs/2502.08639) (Feb., 2025)
[](https://arxiv.org/abs/2502.08639)
[](https://cinemaster-dev.github.io/)
+ [VidCRAFT3: Camera, Object, and Lighting Control for Image-to-Video Generation](https://arxiv.org/pdf/2502.07531) (Feb., 2025)
[](https://arxiv.org/pdf/2502.07531)
+ [FloVD: Optical Flow Meets Video Diffusion Model for Camera-Controlled Video Synthesis](https://jinwonjoon.github.io/flovd_site/FloVD_files/main.pdf) (Feb., 2025)
[](https://github.com/JinWonjoon/FloVD/)
[](https://jinwonjoon.github.io/flovd_site/FloVD_files/main.pdf)
[](https://jinwonjoon.github.io/flovd_site/)
+ [Light-A-Video: Training-free Video Relighting via Progressive Light Fusion](https://arxiv.org/abs/2502.08590) (Feb., 2025)
[](https://github.com/bcmi/Light-A-Video/)
[](https://arxiv.org/abs/2502.08590)
[](https://bujiazi.github.io/light-a-video.github.io/)
+ [MotionCanvas: Cinematic Shot Design with Controllable Image-to-Video Generation](https://arxiv.org/abs/2502.04299) (Feb., 2025)
[](https://arxiv.org/abs/2502.04299)
[](https://motion-canvas25.github.io/)
+ [MotionCanvas: Cinematic Shot Design with Controllable Image-to-Video Generation](https://arxiv.org/pdf/2502.04299) (Feb., 2025)
[](https://arxiv.org/pdf/2502.04299)
+ [DynVFX: Augmenting Real Videos with Dynamic Content](https://arxiv.org/pdf/2502.03621) (Feb., 2025)
[](https://arxiv.org/pdf/2502.03621)
+ [MotionAgent: Fine-grained Controllable Video Generation via Motion Field Agent](https://arxiv.org/pdf/2502.03207) (Feb., 2025)
[](https://arxiv.org/pdf/2502.03207)
+ [RelightVid: Temporal-Consistent Diffusion Model for Video Relighting](https://arxiv.org/abs/2501.16330) (Feb., 2025)
[](https://arxiv.org/abs/2501.16330)
+ [Perception-as-Control: Fine-grained Controllable Image Animation with 3D-aware Motion Representation](https://arxiv.org/pdf/2501.05020) (Jan., 2025)
[](https://arxiv.org/pdf/2501.05020)
[](https://chen-yingjie.github.io/projects/Perception-as-Control/)
[](https://github.com/chen-yingjie/Perception-as-Control)
+ [BlobGEN-Vid: Compositional Text-to-Video Generation with Blob Video Representations](https://arxiv.org/abs/2501.07647) (Jan., 2025)
[](https://github.com/Tian-one/FCVG)
[](https://arxiv.org/abs/2501.07647)
[](https://blobgen-vid2.github.io/)
+ [On Unifying Video Generation and Camera Pose Estimation](https://arxiv.org/abs/2501.01409) (Jan., 2025)
[](https://arxiv.org/abs/2501.01409)
+ [VideoAnydoor: High-fidelity Video Object Insertion with Precise Motion Control](https://arxiv.org/pdf/2501.01427) (Jan., 2025)
[](https://arxiv.org/pdf/2501.01427)
[](https://videoanydoor.github.io/)
+ [DirectorLLM for Human-Centric Video Generation](https://arxiv.org/pdf/2412.14484) (Dec., 2024)
[](https://arxiv.org/pdf/2412.14484)
+ [Consistent Human Image and Video Generation with Spatially Conditioned Diffusion](https://arxiv.org/abs/2412.14531) (Dec., 2024)
[](https://github.com/ljzycmd/SCD)
[](https://arxiv.org/abs/2412.14531)
+ [Generative Inbetweening through Frame-wise Conditions-Driven Video Generation](https://arxiv.org/abs/2412.11755) (Dec., 2024)
[](https://github.com/Tian-one/FCVG)
[](https://arxiv.org/abs/2412.11755)
[](https://fcvg-inbetween.github.io/)
+ [InterDyn: Controllable Interactive Dynamics with Video Diffusion Models](https://interdyn.is.tue.mpg.de/media/upload/interdyn_video.pdf) (Dec., 2024)
[](https://interdyn.is.tue.mpg.de/media/upload/interdyn_video.pdf)
[](https://interdyn.is.tue.mpg.de/)
+ [OmniDrag: Enabling Motion Control for Omnidirectional Image-to-Video Generation](https://arxiv.org/pdf/2412.09623) (Dec., 2024)
[](https://arxiv.org/pdf/2412.09623)
[](https://lwq20020127.github.io/OmniDrag/)
+ [SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints](https://arxiv.org/abs/2412.07760) (Dec., 2024)
[](https://github.com/KwaiVGI/SynCamMaster)
[](https://arxiv.org/abs/2412.07760)
[](https://jianhongbai.github.io/SynCamMaster/)
+ [3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation](https://drive.google.com/file/d/111Z5CMJZupkmg-xWpV4Tl4Nb7SRFcoWx/view) (Dec., 2024)
[](https://github.com/KwaiVGI/3DTrajMaster)
[](https://drive.google.com/file/d/111Z5CMJZupkmg-xWpV4Tl4Nb7SRFcoWx/view)
[](https://wzhouxiff.github.io/projects/ObjCtrl-2.5D/)
+ [ObjCtrl-2.5D: Training-free Object Control with Camera Poses](https://arxiv.org/pdf/2412.07721) (Dec., 2024)
[](https://github.com/wzhouxiff/ObjCtrl-2.5D)
[](https://arxiv.org/pdf/2412.07721)
[](https://wzhouxiff.github.io/projects/ObjCtrl-2.5D/)
+ [Motion Prompting: Controlling Video Generation with Motion Trajectories](https://arxiv.org/abs/2412.02700) (Nov., 2024)
[](https://arxiv.org/abs/2412.02700)
[](https://motion-prompting.github.io/)
+ [Identity-Preserving Text-to-Video Generation by Frequency Decomposition](https://arxiv.org/abs/2411.17440) (Nov., 2024)
[](https://github.com/PKU-YuanGroup/ConsisID)
[](https://arxiv.org/abs/2411.17440)
[](https://pku-yuangroup.github.io/ConsisID/)
[](https://huggingface.co/datasets/BestWishYsh/ConsisID-preview-Data)
+ [FlipSketch: Flipping assets Drawings to Text-Guided Sketch Animations](https://arxiv.org/pdf/2411.10818) (Nov., 2024)
[](https://github.com/hmrishavbandy/FlipSketch)
[](https://arxiv.org/pdf/2411.10818)
+ [AnimateAnything: Consistent and Controllable Animation for video generation](https://arxiv.org/pdf/2411.10836) (Nov., 2024)
[](https://github.com/yu-shaonian/AnimateAnything)
[](https://arxiv.org/pdf/2411.10836)
[](https://yu-shaonian.github.io/Animate_Anything/)
+ [MVideo: Motion Control for Enhanced Complex Action Video Generation](https://arxiv.org/pdf/2411.08328) (Nov., 2024)
[](https://arxiv.org/pdf/2411.08328)
[](https://mvideo-v1.github.io/)
+ [ReCapture: Generative Video Camera Controls for User-Provided Videos using Masked Video Fine-Tuning](https://arxiv.org/abs/2411.05003) (Nov., 2024 | CVPR 2025)
[](https://arxiv.org/abs/2411.05003)
[](https://generative-video-camera-controls.github.io/)
+ [SG-I2V: Self-Guided Trajectory Control in Image-to-Video Generation](https://arxiv.org/pdf/2411.04989) (Nov., 2024)
[](https://arxiv.org/pdf/2411.04989)
[](https://kmcode1.github.io/Projects/SG-I2V/)
[](https://github.com/Kmcode1/SG-I2V)
+ [X-Portrait: Expressive Portrait Animation with Hierarchical Motion Attention](https://arxiv.org/abs/2403.15931) (Nov., 2024)
[](https://arxiv.org/abs/2403.15931)
[](https://byteaigc.github.io/x-portrait/)
[](https://github.com/bytedance/X-Portrait)
+ [LumiSculpt: A Consistency Lighting Control Network for Video Generation](https://arxiv.org/pdf/2410.22979) (Nov., 2024)
[](https://arxiv.org/pdf/2410.22979)
+ [FRAMER: INTERACTIVE FRAME INTERPOLATION](https://arxiv.org/pdf/2410.18978) (Oct., 2024)
[](https://github.com/aim-uofa/Framer)
[](https://arxiv.org/pdf/2410.18978)
[](https://aim-uofa.github.io/Framer/)
+ [CamI2V: Camera-Controlled Image-to-Video Diffusion Model](https://arxiv.org/pdf/2410.15957) (Oct., 2024)
[](https://github.com/ZGCTroy/CamI2V)
[](https://arxiv.org/pdf/2410.15957)
[](https://zgctroy.github.io/CamI2V/)
+ [Cavia: Camera-controllable Multi-view Video Diffusion with View-Integrated Attention](https://arxiv.org/abs/2410.10774) (Oct., 2024)
[](https://arxiv.org/abs/2410.10774)
[](https://ir1d.github.io/Cavia/)
+ [Animate Your Motion: Turning Still Images into Dynamic Videos](https://arxiv.org/abs/2403.10179)(Mar., 2023|ECCV 2024)
[](https://arxiv.org/abs/2403.10179)
[](https://mingxiao-li.github.io/smcd/)
+ [EasyControl: Transfer ControlNet to Video Diffusion for Controllable Generation and Interpolation](https://arxiv.org/abs/2408.13005) (Aug., 2024)
[](https://arxiv.org/abs/2408.13005)
+ [ControlNeXt: Powerful and Efficient Control for Image and Video Generation](https://arxiv.org/pdf/2408.06070) (Aug., 2024)
[](https://github.com/dvlab-research/ControlNeXt)
[](https://arxiv.org/pdf/2408.06070)
[](https://pbihao.github.io/projects/controlnext/index.html)
+ [TrackGo: A Flexible and Efficient Method for Controllable Video Generation](https://arxiv.org/abs/2408.11475) (Aug., 2024)
[](https://arxiv.org/abs/2408.11475)
[](https://zhtjtcz.github.io/TrackGo-Page/#)
+ [Puppet-Master: Scaling Interactive Video Generation as a Motion Prior for Part-Level Dynamics](https://arxiv.org/abs/2408.04631) (Aug., 2024)
[](https://arxiv.org/abs/2408.04631)
[](https://vgg-puppetmaster.github.io/)
+ [Sketch2Scene: Automatic Generation of Interactive 3D Game Scenes from User's Casual Sketches](https://arxiv.org/abs/2408.04567) (Aug., 2024)
[](https://arxiv.org/abs/2408.04567)
[](https://xrvisionlabs.github.io/Sketch2Scene/)
+ [Expressive Whole-Body 3D Gaussian Avatar](https://arxiv.org/abs/2407.21686) (Aug., 2024)
[](https://arxiv.org/abs/2407.21686)
[](https://mks0601.github.io/ExAvatar/)
+ [Tora: Trajectory-oriented Diffusion Transformer for Video Generation](https://arxiv.org/abs/2407.21705) (Jul., 2024 | CVPR 2025)
[](https://github.com/alibaba/Tora)
[](https://arxiv.org/abs/2407.21705)
[](https://ali-videoai.github.io/tora_video/)
+ [HumanVid: Demystifying Training Data for Camera-controllable Human Image Animation](https://arxiv.org/pdf/2407.17438) (Jul., 2024)
[](https://github.com/zhenzhiwang/HumanVid)
[](https://arxiv.org/pdf/2407.17438)
[](https://humanvid.github.io/#)
+ [Cinemo: Consistent and Controllable Image Animation with Motion Diffusion Models](https://arxiv.org/abs/2407.15642) (Jul., 2024)
[](https://github.com/maxin-cn/Cinemo)
[](https://arxiv.org/abs/2407.15642)
[](https://maxin-cn.github.io/cinemo_project/)
+ [VD3D: Taming Large Video Diffusion Transformers for 3D Camera Control](https://arxiv.org/abs/2407.12781) (Jul., 2024)
[](https://arxiv.org/abs/2407.12781)
[](https://snap-research.github.io/vd3d/)
+ [Still-Moving: Customized Video Generation without Customized Video Data](https://arxiv.org/abs/2407.08674) (Jul., 2024)
[](https://arxiv.org/abs/2407.08674)
[](https://still-moving.github.io/)
+ [LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control](https://arxiv.org/abs/2407.03168) (Jul., 2024)
[](https://github.com/KwaiVGI/LivePortrait)
[](https://arxiv.org/abs/2407.03168)
[](https://github.com/KwaiVGI/LivePortrait)
+ [Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model](https://arxiv.org/abs/2406.15735) (Jun., 2024 | NeurIPS 2024)
[](https://github.com/thu-ml/cond-image-leakage/tree/main?tab=readme-ov-file)
[](https://arxiv.org/abs/2406.15735)
[](https://cond-image-leak.github.io/)
+ [Image Conductor: Precision Control for Interactive Video Synthesis](https://arxiv.org/pdf/2406.15339) (Jun., 2024)
[](https://github.com/liyaowei-stu/ImageConductor)
[](https://arxiv.org/pdf/2406.15339)
[](https://liyaowei-stu.github.io/project/ImageConductor/)
+ [MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance](https://arxiv.org/abs/2406.19680) (Jun., 2024)
[](https://arxiv.org/abs/2406.19680)
+ [FreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models](https://arxiv.org/abs/2406.16863) (Jun., 2024)
[](https://github.com/arthur-qiu/FreeTraj)
[](https://arxiv.org/abs/2406.16863)
[](http://haonanqiu.com/projects/FreeTraj.html)
+ [MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model](https://arxiv.org/abs/2405.20222) (Jun., 2024)
[](https://github.com/MyNiuuu/MOFA-Video)
[](https://arxiv.org/abs/2405.20222)
[](https://myniuuu.github.io/MOFA_Video/)
+ [Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance](https://arxiv.org/abs/2403.14781) (Mar., 2024)
[](https://github.com/fudan-generative-vision/champ)
[](https://arxiv.org/abs/2403.14781)
[](https://fudan-generative-vision.github.io/champ/)
+ [TrailBlazer: Trajectory Control for Diffusion-Based Video Generation](https://arxiv.org/abs/2401.00896) (Jan., 2024)
[](https://github.com/hohonu-vicml/Trailblazer)
[](https://arxiv.org/abs/2401.00896)
[](https://hohonu-vicml.github.io/Trailblazer.Page/)
+ [Motion-Zero: Zero-Shot Moving Object Control Framework for Diffusion-Based Video Generation](https://arxiv.org/abs/2401.10150) (Jan., 2024)
[](https://arxiv.org/abs/2401.10150)
+ [Moonshot: Towards Controllable Video Generation and Editing with Multimodal Conditions](https://arxiv.org/abs/2401.01827) (Jan., 2024)
[](https://arxiv.org/abs/2401.01827)
[](https://showlab.github.io/Moonshot/)
+ [MotionCtrl: A Unified and Flexible Motion Controller for Video Generation](https://arxiv.org/abs/2312.03641) (Dec., 2023)
[](https://github.com/TencentARC/MotionCtrl)
[](https://arxiv.org/abs/2312.03641)
[](https://wzhouxiff.github.io/projects/MotionCtrl/)
+ [Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation](https://arxiv.org/abs/2311.17117) (Nov., 2023)
[](https://github.com/HumanAIGC/AnimateAnyone)
[](https://arxiv.org/abs/2311.17117)
[](https://humanaigc.github.io/animate-anyone/)
+ [SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models](https://arxiv.org/abs/2311.16933) (Nov., 2023)
[](https://arxiv.org/abs/2311.16933)
[](https://guoyww.github.io/projects/SparseCtrl/)
+ [Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models](https://arxiv.org/abs/2305.13840) (May, 2023)
[](https://github.com/Weifeng-Chen/control-a-video)
[](https://arxiv.org/abs/2305.13840)
[](https://controlavideo.github.io/)
+ [Motion-Conditioned Diffusion Model for Controllable Video Synthesis](https://arxiv.org/abs/2304.14404) (Apr., 2023)
[](https://arxiv.org/abs/2304.14404)
[](https://tsaishien-chen.github.io/MCDiff/)
+ [ControlVideo: Training-free Controllable Text-to-Video Generation](https://arxiv.org/abs/2305.13077) (May, 2023)
[](https://github.com/YBYBZhang/ControlVideo)
[](https://arxiv.org/abs/2305.13077)
+ [DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory](https://arxiv.org/abs/2308.08089) (Aug., 2023)
[](https://arxiv.org/abs/2308.08089)
[](https://www.microsoft.com/en-us/research/project/dragnuwa/)
+ [DragAnything: Motion Control for Anything using Entity Representation](https://arxiv.org/abs/2403.07420) (ECCV, 2024)
[](https://github.com/showlab/DragAnything)
[](https://arxiv.org/abs/2403.07420)
[](https://weijiawu.github.io/draganything_page/)
+ [CameraCtrl: Enabling Camera Control for Video Diffusion Models](https://arxiv.org/abs/2404.02101) (Apr., 2024)
[](https://github.com/hehao13/CameraCtrl)
[](https://arxiv.org/abs/2404.02101)
[](https://hehao13.github.io/projects-CameraCtrl/)
+ [Training-free Camera Control for Video Generation](https://arxiv.org/pdf/2406.10126) (Jun., 2024)
[](https://arxiv.org/pdf/2406.10126)
[](https://lifedecoder.github.io/CamTrol/)
+ [Customizing Motion in Text-to-Video Diffusion Models](https://arxiv.org/abs/2312.04966) (Dec., 2023)
[](https://arxiv.org/abs/2312.04966)
[](https://joaanna.github.io/customizing_motion/)
+ [MotionClone: Training-Free Motion Cloning for Controllable Video Generation](https://arxiv.org/abs/2406.05338) (Jun., 2024)
[](https://arxiv.org/abs/2406.05338)
[](https://bujiazi.github.io/motionclone.github.io/)
### Character Customization
+ [VideoMage: Multi-Subject and Motion Customization of Text-to-Video Diffusion Models](https://arxiv.org/abs/2503.21781) (Mar., 2025)
[](https://arxiv.org/abs/2503.21781)
[](https://jasper0314-huang.github.io/videomage-customization/)
+ [MagicID: Hybrid Preference Optimization for ID-Consistent and Dynamic-Preserved Video Customization](https://arxiv.org/abs/2503.12689) (Mar., 2025)
[](https://github.com/EchoPluto/MagicID)
[](https://arxiv.org/abs/2503.12689)
[](https://echopluto.github.io/MagicID-project/)
+ [Concat-ID: Towards Universal Identity-Preserving Video Synthesis](https://arxiv.org/abs/2503.14151) (Mar., 2025)
[](https://github.com/ML-GSAI/Concat-ID)
[](https://arxiv.org/abs/2503.14151)
[](https://ml-gsai.github.io/Concat-ID-demo/)
+ [CINEMA: Coherent Multi-Subject Video Generation via MLLM-Based Guidance](https://arxiv.org/abs/2503.10391) (Mar., 2025)
[](https://arxiv.org/abs/2503.10391)
+ [FantasyID: Face Knowledge Enhanced ID-Preserving Video Generation](https://arxiv.org/abs/2502.13995) (Feb., 2025)
[](https://arxiv.org/abs/2502.13995)
+ [Dynamic Concepts Personalization from Single Videos](https://arxiv.org/abs/2502.14844) (Feb., 2025)
[](https://arxiv.org/abs/2502.14844)
[](https://snap-research.github.io/dynamic_concepts/)
+ [Phantom: Subject-consistent video generation via cross-modal alignment](https://arxiv.org/pdf/2502.11079) (Feb., 2025)
[](https://github.com/Phantom-video/Phantom)
[](https://arxiv.org/pdf/2502.11079)
[](https://phantom-video.github.io/Phantom/)
+ [Movie Weaver: Tuning-Free Multi-Concept Video Personalization with Anchored Prompts](https://arxiv.org/abs/2502.07802) (Feb., 2025)
[](https://arxiv.org/abs/2502.07802)
[](https://jeff-liangf.github.io/projects/movieweaver/)
+ [Animate Anyone 2: High-Fidelity Character Image Animation with Environment Affordance](https://arxiv.org/pdf/2502.06145) (Feb., 2025)
[](https://arxiv.org/pdf/2502.06145)
[](https://humanaigc.github.io/animate-anyone-2/)
+ [Multi-subject Open-set Personalization in Video Generation](https://arxiv.org/abs/2501.06187) (Jan., 2025)
[](https://arxiv.org/abs/2501.06187)
[](https://snap-research.github.io/open-set-video-personalization/)
+ [Magic Mirror: ID-Preserved Video Generation in Video Diffusion Transformers](https://arxiv.org/abs/2501.03931) (Jan., 2025)
[](https://github.com/dvlab-research/MagicMirror/)
[](https://arxiv.org/abs/2501.03931)
[](https://julianjuaner.github.io/projects/MagicMirror/)
+ [ConceptMaster: Multi-Concept Video Customization on Diffusion Transformer Models Without Test-Time Tuning](https://arxiv.org/abs/2501.04698) (Jan., 2025)
[](https://arxiv.org/abs/2501.04698)
[](https://yuzhou914.github.io/ConceptMaster/)
+ [VideoMaker: Zero-shot Customized Video Generation with the Inherent Force of Video Diffusion Models](https://arxiv.org/pdf/2412.19645) (Dec., 2024)
[](https://github.com/WuTao-CS/VideoMaker)
[](https://arxiv.org/pdf/2412.19645)
[](https://wutao-cs.github.io/VideoMaker/)
+ [PersonalVideo: High ID-Fidelity Video Customization without Dynamic and Semantic Degradation](https://arxiv.org/pdf/2411.17048) (Nov., 2024)
[](https://arxiv.org/pdf/2411.17048)
[](https://personalvideo.github.io/)
+ [DreamVideo-2: Zero-Shot Subject-Driven Video Customization with Precise Motion Control](https://arxiv.org/abs/2410.13830) (Oct., 2024)
[](https://arxiv.org/abs/2410.13830)
[](https://dreamvideo2.github.io/)
+ [CustomCrafter: Customized Video Generation with Preserving Motion and Concept Composition Abilities](https://arxiv.org/abs/2408.13239) (Aug., 2024)
[](https://github.com/WuTao-CS/CustomCrafter)
[](https://arxiv.org/abs/2408.13239)
[](https://customcrafter.github.io/)
### Motion Customization
+ [Separate Motion from Appearance: Customizing Motion via Customizing Text-to-Video Diffusion Models](https://arxiv.org/abs/2501.16714) (Feb., 2025)
[](https://arxiv.org/abs/2501.16714)
+ [Go-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise](https://arxiv.org/pdf/2501.08331) (Jan., 2025)
[](https://github.com/VGenAI-Netflix-Eyeline-Research/Go-with-the-Flow)
[](https://arxiv.org/pdf/2501.08331)
[](https://vgenai-netflix-eyeline-research.github.io/Go-with-the-Flow/)
+ [Training-Free Motion-Guided Video Generation with Enhanced Temporal Consistency Using Motion Consistency Loss](https://arxiv.org/abs/2501.07563v1) (Jan., 2025)
[](https://arxiv.org/abs/2501.07563v1)
[](https://zhangxinyu-xyz.github.io/SimulateMotion.github.io/)
+ [Free-Form Motion Control: A Synthetic Video Generation Dataset with Controllable Camera and Object Motions](https://arxiv.org/abs/2501.01425) (Jan., 2025)
[](https://arxiv.org/abs/2501.01425)
[](https://henghuiding.github.io/SynFMC/)
+ [CustomTTT: Motion and Appearance Customized Video Generation via Test-Time Training](https://arxiv.org/pdf/2412.15646) (Dec., 2024)
[](https://arxiv.org/pdf/2412.15646)
+ [MotionShop: Zero-Shot Motion Transfer in Video Diffusion Models with Mixture of Score Guidance](https://motionshop-diffusion.github.io/MotionShop.pdf) (Dec., 2024)
[](https://github.com/gemlab-vt/motionshop)
[](https://motionshop-diffusion.github.io/MotionShop.pdf)
[](https://motionshop-diffusion.github.io/)
+ [Video Motion Transfer with Diffusion Transformers](https://arxiv.org/abs/2412.07776) (Dec., 2024)
[](https://github.com/ditflow/ditflow)
[](https://arxiv.org/abs/2412.07776)
[](https://ditflow.github.io/)
+ [Latent-Reframe: Enabling Camera Control for Video Diffusion Model without Training](https://arxiv.org/abs/2412.06029) (Dec., 2024)
[](https://arxiv.org/abs/2412.06029)
[](https://latent-reframe.github.io/)
+ [Motion Modes: What Could Happen Next?](https://motionmodes.github.io/resources/MotionModes.pdf) (Dec., 2024)
[](https://motionmodes.github.io/resources/MotionModes.pdf)
[](https://motionmodes.github.io/)
+ [MoTrans: Customized Motion Transfer with Text-driven Video](https://arxiv.org/abs/2412.01343) (Dec., 2024)
[](https://arxiv.org/abs/2412.01343)
+ [AC3D: Analyzing and Improving 3D Camera Control in Video Diffusion Transformers](https://arxiv.org/abs/2411.18673) (Dec., 2024)
[](https://arxiv.org/abs/2411.18673)
[](https://snap-research.github.io/ac3d/)
+ [Trajectory Attention For Fine-grained Video Motion Control](https://arxiv.org/abs/2411.14208) (Dec., 2024)
[](https://github.com/xizaoqu/TrajectoryAttntion)
[](https://arxiv.org/abs/2411.19324)
[](https://xizaoqu.github.io/trajattn/)
+ [ViewExtrapolator: Novel View Extrapolation with Video Diffusion Priors](https://arxiv.org/abs/2411.14208) (Nov., 2024)
[](https://github.com/Kunhao-Liu/ViewExtrapolator)
[](https://arxiv.org/abs/2411.14208)
[](https://kunhao-liu.github.io/ViewExtrapolator/)
+ [I2VControl-Camera: Precise Video Camera Control with Adjustable Motion Strength](https://arxiv.org/pdf/2411.06525) (Nov., 2024)
[](https://arxiv.org/pdf/2411.06525)
+ [MotionDirector: Motion Customization of Text-to-Video Diffusion Models](https://arxiv.org/abs/2310.08465) (Sep., 2023 | ECCV 2024)
[](https://github.com/showlab/MotionDirector)
[](https://arxiv.org/abs/2310.08465)
[](https://showlab.github.io/MotionDirector/)
+ [LAMP: Learn A Motion Pattern for Few-Shot-Based Video Generation](https://arxiv.org/abs/2310.10769) (Oct., 2023 | CVPR 2024)
[](https://github.com/RQ-Wu/LAMP)
[](https://arxiv.org/abs/2310.10769)
[](https://rq-wu.github.io/projects/LAMP/)
+ [Vmc: Video motion customization using temporal attention adaption for text-to-video diffusion models](https://arxiv.org/abs/2312.00845) (Dec., 2023 | CVPR 2024)
[](https://github.com/HyeonHo99/Video-Motion-Customization)
[](https://arxiv.org/abs/2312.00845)
[](https://video-motion-customization.github.io/)
+ [DreamVideo: Composing Your Dream Videos with Customized Subject and Motion](https://arxiv.org/abs/2312.04433) (Dec., 2023 | CVPR 2024)
[](https://github.com/ali-vilab/VGen)
[](https://arxiv.org/abs/2312.04433)
[](https://dreamvideo-t2v.github.io/)
+ [MotionCtrl: A Unified and Flexible Motion Controller for Video Generation](https://arxiv.org/abs/2312.03641) (Dec., 2023 | SIGGRAPH 2024)
[](https://github.com/TencentARC/MotionCtrl)
[](https://arxiv.org/abs/2312.03641)
[](https://wzhouxiff.github.io/projects/MotionCtrl/)
+ [Customizing Motion in Text-to-Video Diffusion Models](https://arxiv.org/abs/2312.04966) (Dec., 2023)
[](https://arxiv.org/abs/2312.04966)
[](https://joaanna.github.io/customizing_motion/)
+ [Direct-a-Video: Customized Video Generation with User-Directed Camera Movement and Object Motion](https://arxiv.org/abs/2402.03162) (Feb., 2024)
[](https://github.com/ysy31415/direct_a_video)
[](https://arxiv.org/abs/2402.03162)
[](https://direct-a-video.github.io/)
+ [Customize-A-Video: One-Shot Motion Customization of Text-to-Video Diffusion Models](https://arxiv.org/abs/2402.14780) (Feb., 2024)
[](https://arxiv.org/abs/2402.14780)
+ [DreamMotion: Space-Time Self-Similar Score Distillation for Zero-Shot Video Editing](https://arxiv.org/abs/2403.12002) (Mar., 2024 | ECCV 2024)
[](https://arxiv.org/abs/2403.12002)
[](https://hyeonho99.github.io/dreammotion/)
+ [DragAnything: Motion Control for Anything using Entity Representation](https://arxiv.org/abs/2403.07420) (Mar., 2024 | ECCV 2024)
[](https://github.com/showlab/DragAnything)
[](https://arxiv.org/abs/2403.07420)
[](https://weijiawu.github.io/draganything_page/)
+ [Spectral Motion Alignment for Video Motion Transfer using Diffusion Models](https://arxiv.org/abs/2403.15249) (Mar., 2024)
[](https://github.com/geonyeong-park/Spectral-Motion-Alignment)
[](https://arxiv.org/abs/2403.15249)
[](https://geonyeong-park.github.io/spectral-motion-alignment/)
+ [Motion Inversion for Video Customization](https://arxiv.org/abs/2403.20193) (Mar., 2024)
[](https://github.com/EnVision-Research/MotionInversion)
[](https://arxiv.org/abs/2403.20193)
[](https://wileewang.github.io/MotionInversion/)
+ [Edit-Your-Motion: Space-Time Diffusion Decoupling Learning for Video Motion Editing](https://arxiv.org/abs/2405.04496) (Mar., 2024)
[](https://arxiv.org/abs/2405.04496)
+ [Video Diffusion Models are Training-free Motion Interpreter and Controller](https://arxiv.org/abs/2405.14864) (May., 2024)
[](https://arxiv.org/abs/2405.14864)
[](https://xizaoqu.github.io/moft/)
+ [Collaborative Video Diffusion: Consistent Multi-video Generation with Camera Control](https://arxiv.org/abs/2405.17414) (May., 2024)
[](https://github.com/CollaborativeVideoDiffusion/CVD)
[](https://arxiv.org/abs/2405.17414)
[](https://collaborativevideodiffusion.github.io/)
+ [MotionClone: Training-Free Motion Cloning for Controllable Video Generation](https://arxiv.org/abs/2406.05338) (Jun., 2024)
[](https://github.com/Bujiazi/MotionClone/)
[](https://arxiv.org/abs/2406.05338)
[](https://bujiazi.github.io/motionclone.github.io/)
+ [FreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models](https://arxiv.org/abs/2406.16863) (Jun., 2024)
[](https://github.com/arthur-qiu/FreeTraj)
[](https://arxiv.org/abs/2406.16863)
[](http://haonanqiu.com/projects/FreeTraj.html)
+ [Zero-Shot Controllable Image-to-Video Animation via Motion Decomposition](https://www.amazon.science/publications/zero-shot-controllable-image-to-video-animation-via-motion-decomposition) (Jul., 2024 | ACM MM 2024)
[](https://img2vidanim-0.github.io/)
+ [Tora: Trajectory-oriented Diffusion Transformer for Video Generation](https://arxiv.org/abs/2407.21705) (Jul., 2024)
[](https://github.com/alibaba/Tora)
[](https://arxiv.org/abs/2407.21705)
[](https://ali-videoai.github.io/tora_video/)
+ [Reenact Anything: Semantic Video Motion Transfer Using Motion-Textual Inversion](https://arxiv.org/abs/2408.00458) (Aug., 2024)
[](https://arxiv.org/abs/2408.00458)
### Long Video / Film Generation
+ [Long-Context Autoregressive Video Modeling with Next-Frame Prediction](https://arxiv.org/abs/2503.19325) (Mar., 2025)
[](https://arxiv.org/abs/2503.19325)
[](https://farlongctx.github.io/)
[](https://github.com/showlab/FAR)
+ [MovieAgent: Automated Movie Generation via Multi-Agent CoT Planning](https://arxiv.org/abs/2503.07314) (Mar., 2025)
[](https://arxiv.org/abs/2503.07314)
[](https://weijiawu.github.io/MovieAgent/)
[](https://github.com/showlab/MovieAgent)
+ [Long Context Tuning for Video Generation](https://arxiv.org/pdf/2503.10589) (Mar., 2025)
[](https://arxiv.org/pdf/2503.10589)
[](https://guoyww.github.io/projects/long-context-video/)
+ [RIFLEx: A Free Lunch for Length Extrapolation in Video Diffusion Transformers](https://arxiv.org/abs/2502.15894) (Feb., 2025)
[](https://github.com/thu-ml/RIFLEx)
[](https://arxiv.org/abs/2502.15894)
[](https://riflex-video.github.io/)
+ [VideoRAG: Retrieval-Augmented Generation with Extreme Long-Context Videos](https://arxiv.org/abs/2502.01549) (Feb., 2025)
[](https://github.com/HKUDS/VideoRAG)
[](https://arxiv.org/abs/2502.01549)
+ [Ouroboros-Diffusion: Exploring Consistent Content Generation in Tuning-free Long Video Diffusion](https://arxiv.org/pdf/2501.09019) (Jan., 2025)
[](https://arxiv.org/pdf/2501.09019)
+ [VideoAuteur: Towards Long Narrative Video Generation](https://arxiv.org/abs/2501.06173) (Jan., 2025)
[](https://github.com/lambert-x/VideoAuteur)
[](https://arxiv.org/abs/2501.06173)
[](https://videoauteur.github.io/)
+ [DiTCtrl: Exploring Attention Control in Multi-Modal Diffusion Transformer for Tuning-Free Multi-Prompt Longer Video Generation](https://arxiv.org/abs/2412.18597) (Dec., 2024)
[](https://github.com/TencentARC/DiTCtrl)
[](https://arxiv.org/abs/2412.18597)
[](https://onevfall.github.io/project_page/ditctrl/)
+ [LinGen: Towards High-Resolution Minute-Length Text-to-Video Generation with Linear Computational Complexity](https://arxiv.org/abs/2412.09856) (Dec., 2024)
[](https://arxiv.org/abs/2412.09856)
[](https://lineargen.github.io/)
+ [Owl-1: Omni World Model for Consistent Long Video Generation](https://arxiv.org/abs/2412.09600) (Dec., 2024)
[](https://github.com/huang-yh/Owl)
[](https://arxiv.org/abs/2412.09600)
+ [Video Storyboarding: Multi-Shot Character Consistency for Text-to-Video Generation](https://arxiv.org/pdf/2412.07750) (Dec., 2024)
[](https://arxiv.org/pdf/2412.07750)
[](https://research.nvidia.com/labs/par/video_storyboarding/)
+ [Mind the Time: Temporally-Controlled Multi-Event Video Generation](https://arxiv.org/abs/2412.05263) (Dec., 2024)
[](https://github.com/Karine-Huang/GenMAC)
[](https://arxiv.org/abs/2412.05263)
[](https://mint-video.github.io/)
+ [GenMAC: Compositional Text-to-Video Generation with Multi-Agent Collaboration](https://arxiv.org/abs/2412.04440) (Dec., 2024)
[](https://github.com/Karine-Huang/GenMAC)
[](https://arxiv.org/abs/2412.04440)
[](https://karine-h.github.io/GenMAC/)
+ [Long Video Diffusion Generation with Segmented Cross-Attention and Content-Rich Video Data Curation](https://arxiv.org/pdf/2412.01316) (Dec., 2024)
[](https://arxiv.org/pdf/2412.01316)
[](https://presto-video.github.io/)
+ [VideoGen-of-Thought: A Collaborative Framework for Multi-Shot Video Generation](https://arxiv.org/abs/2412.02259) (Dec., 2024)
[](https://arxiv.org/abs/2412.02259)
[](https://cheliosoops.github.io/VGoT/)
+ [MotionCharacter: Identity-Preserving and Motion Controllable Human Video Generation](https://arxiv.org/pdf/2411.18281) (Nov., 2024)
[](https://arxiv.org/pdf/2411.18281)
[](https://motioncharacter.github.io/)
+ [Identity-Preserving Text-to-Video Generation by Frequency Decomposition](https://arxiv.org/abs/2411.17440) (Nov., 2024)
[](https://github.com/PKU-YuanGroup/ConsisID)
[](https://arxiv.org/abs/2411.17440)
[](https://pku-yuangroup.github.io/ConsisID/)
[](https://huggingface.co/datasets/BestWishYsh/ConsisID-preview-Data)
+ [MovieBench: A Hierarchical Movie Level Dataset for Long Video Generation](https://arxiv.org/abs/2411.15262) (CVPR 2025)
[](https://arxiv.org/abs/2411.15262)
[](https://weijiawu.github.io/MovieBench/)
[](https://github.com/showlab/MovieBecnh)
+ [MotionPrompt: Optical-Flow Guided Prompt Optimization for Coherent Video Generation](https://arxiv.org/pdf/2411.15540) (Nov., 2024)
[](https://arxiv.org/pdf/2411.15540)
[](https://motionprompt.github.io/)
[](https://github.com/HyelinNAM/MotionPrompt)
+ [DreamRunner: Fine-Grained Storytelling Video Generation with Retrieval-Augmented Motion Adaptation](https://arxiv.org/pdf/2411.16657) (Nov., 2024)
[](https://arxiv.org/pdf/2411.16657)
[](https://dreamrunner-story2video.github.io/)
[](https://github.com/wz0919/DreamRunner)
+ [StoryMaker: Towards consistent characters in text-to-image generation](https://arxiv.org/abs/2409.12576) (Nov., 2024)
[](https://arxiv.org/abs/2409.12576)
[](https://github.com/RedAIGC/StoryMaker)
+ [Storynizor: Consistent Story Generation via Inter-Frame Synchronized and Shuffled ID Injection](https://arxiv.org/pdf/2409.19624) (Nov., 2024)
[](https://arxiv.org/pdf/2409.19624)
+ [ACDC: Autoregressive Coherent Multimodal Generation using Diffusion Correction](https://arxiv.org/abs/2410.04721) (Nov., 2024)
[](https://arxiv.org/abs/2410.04721)
[](https://acdc2025.github.io/)
+ [Story-Adapter: A Training-free Iterative Framework for Long Story Visualization](https://arxiv.org/abs/2410.06244) (Nov., 2024)
[](https://arxiv.org/abs/2410.06244)
[](https://jwmao1.github.io/storyadapter/)
[](https://github.com/jwmao1/story-adapter)
+ [In-Context LoRA for Diffusion Transformers](https://arxiv.org/abs/2410.23775) (Aug., 2024)
[](https://arxiv.org/abs/2410.23775)
[](https://ali-vilab.github.io/In-Context-LoRA-Page/)
[](https://github.com/ali-vilab/In-Context-LoRA)
+ [SEED-Story: Multimodal Long Story Generation with Large Language Model](https://arxiv.org/abs/2407.08683) (Jul., 2024)
[](https://arxiv.org/abs/2407.08683)
[](https://github.com/TencentARC/SEED-Story)
+ [StoryAgent: Customized Storytelling Video Generation via Multi-Agent Collaboration](https://arxiv.org/pdf/2411.04925) (Nov., 2024)
[](https://arxiv.org/pdf/2411.04925)
+ [ARLON: Boosting Diffusion Transformers With Autoregressive Models for Long Video Generation](https://arxiv.org/abs/2410.20502) (Oct., 2024)
[](https://arxiv.org/abs/2410.20502)
[](https://arlont2v.github.io/)
+ [Unbounded: A Generative Infinite Game of Character Life Simulation](https://arxiv.org/abs/2410.18975) (Oct., 2024)
[](https://arxiv.org/abs/2410.18975)
[](https://generative-infinite-game.github.io/)
+ [Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach](https://arxiv.org/abs/2410.03160) (Oct., 2024)
[](https://github.com/Yaofang-Liu/FVDM)
[](https://arxiv.org/abs/2410.03160)
+ [Loong: Generating Minute-level Long Videos with Autoregressive Language Models](https://arxiv.org/abs/2410.02757) (Oct., 2024)
[](https://arxiv.org/abs/2410.02757)
[](https://epiphqny.github.io/Loong-video/)
+ [DreamCinema: Cinematic Transfer with Free Camera and 3D Character](https://arxiv.org/pdf/2410.04721) (Oct., 2024)
[](https://arxiv.org/pdf/2410.04721)
[](https://acdc2025.github.io/)
+ [CinePreGen: Camera Controllable Video Previsualization via Engine-powered Diffusion](https://arxiv.org/pdf/2408.17424) (Aug., 2024)
[](https://arxiv.org/pdf/2408.17424)
+ [DreamCinema: Cinematic Transfer with Free Camera and 3D Character](https://arxiv.org/abs/2408.12601) (Aug., 2024)
[](https://github.com/chen-wl20/DreamCinema?tab=readme-ov-file)
[](https://arxiv.org/abs/2408.12601)
[](https://liuff19.github.io/DreamCinema/)
+ [SkyScript-100M: 1,000,000,000 Pairs of Scripts and Shooting Scripts for Short Drama](https://arxiv.org/pdf/2408.09333) (Aug., 2024)
[](https://github.com/vaew/SkyScript-100M)
[](https://arxiv.org/pdf/2408.09333)
+ [Anim-Director: A Large Multimodal Model Powered Agent for Controllable Animation Video Generation](https://arxiv.org/abs/2408.09787) (Aug., 2024)
[](https://github.com/HITsz-TMG/Anim-Director)
[](https://arxiv.org/abs/2408.09787)
+ [Kubrick: Multimodal Agent Collaborations for Synthetic Video Generation](https://arxiv.org/pdf/2408.10453) (Aug., 2024)
[](https://arxiv.org/pdf/2408.10453)
+ [DreamFactory: Pioneering Multi-Scene Long Video Generation with a Multi-Agent Framework](https://arxiv.org/abs/2408.11788) (Jul, 2024)
[](https://arxiv.org/abs/2408.11788)
+ [MovieDreamer: Hierarchical Generation for Coherent Long Visual Sequence](https://arxiv.org/abs/2407.16655) (Jul, 2024)
[](https://github.com/aim-uofa/MovieDreamer)
[](https://arxiv.org/abs/2407.16655)
[](https://aim-uofa.github.io/MovieDreamer/)
+ [Streetscapes: Large-scale Consistent Street View Generation Using Autoregressive Video Diffusion](https://arxiv.org/pdf/2407.13759) (Jul., 2024)
[](https://arxiv.org/pdf/2407.13759)
[](https://boyangdeng.com/streetscapes/)
+ [AutoAD-Zero: A Training-Free Framework for Zero-Shot Audio Description](https://arxiv.org/abs/2407.15850) (Jul, 2024)
[](https://github.com/Jyxarthur/AutoAD-Zero)
[](https://arxiv.org/abs/2407.15850)
[](https://www.robots.ox.ac.uk/~vgg/research/autoad-zero/)
+ [AesopAgent: Agent-driven Evolutionary System on Story-to-Video Production](https://arxiv.org/abs/2403.07952) (Jul, 2024)
[](https://arxiv.org/abs/2403.07952)
[](https://aesopai.github.io/)
+ [TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation](https://arxiv.org/abs/2404.18919) (Jul, 2024)
[](https://github.com/donahowe/Theatergen)
[](https://arxiv.org/abs/2404.18919)
[](https://howe140.github.io/theatergen.io/)
+ [AutoStudio: Crafting Consistent Subjects in Multi-turn Interactive Image Generation](https://github.com/donahowe/AutoStudio) (Jul, 2024)
[](https://github.com/donahowe/AutoStudio)
[](https://arxiv.org/abs/2406.01388)
[](https://github.com/donahowe/AutoStudio)
+ [DreamStory: Open-Domain Story Visualization by LLM-Guided Multi-Subject Consistent Diffusion](https://arxiv.org/abs/2407.12899) (Jul, 2024)
[](https://arxiv.org/abs/2407.12899)
[](https://dream-xyz.github.io/dreamstory)
+ [VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning](https://arxiv.org/abs/2309.15091) (Jul, 2024)
[](https://github.com/HL-hanlin/VideoDirectorGPT)
[](https://arxiv.org/abs/2309.15091)
[](https://videodirectorgpt.github.io/)
+ [MCVD: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation](https://arxiv.org/abs/2205.09853) (NeurIPS 2022)
[](https://github.com/voletiv/mcvd-pytorch)
[](https://arxiv.org/abs/2205.09853)
[](https://mask-cond-video-diffusion.github.io)
+ [NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation](https://arxiv.org/abs/2303.12346) (Mar., 2023)
[](https://arxiv.org/abs/2303.12346)
[](https://msra-nuwa.azurewebsites.net/#/)
+ [Flexible Diffusion Modeling of Long Videos](https://arxiv.org/abs/2205.11495) (May, 2022)
[](https://github.com/plai-group/flexible-video-diffusion-modeling)
[](https://arxiv.org/abs/2205.11495)
[](https://fdmolv.github.io/)
### Video Generation with 3D/Physical Prior
+ [SyncVP: Joint Diffusion for Synchronous Multi-Modal Video Prediction](https://arxiv.org/abs/2503.18933) (CVPR 2025)
[](https://github.com/PallottaEnrico/SyncVP)
[](https://arxiv.org/abs/2503.18933)
[](https://syncvp.github.io/)
+ [DiffusionRenderer: Neural Inverse and Forward Rendering with Video Diffusion Models](https://arxiv.org/abs/2501.18590) (Feb, 2025)
[](https://arxiv.org/abs/2501.18590)
[](https://research.nvidia.com/labs/toronto-ai/DiffusionRenderer/)
+ [Generative Physical AI in Vision: A Survey](https://arxiv.org/abs/2501.10928) (Jan, 2025)
[](https://github.com/BestJunYu/Awesome-Physics-aware-Generation)
[](https://arxiv.org/abs/2501.10928)
[](https://github.com/BestJunYu/Awesome-Physics-aware-Generation)
+ [Do generative video models learn physical principles from watching videos?](https://arxiv.org/pdf/2501.09038) (Jan, 2025)
[](https://arxiv.org/pdf/2501.09038)
[](https://physics-iq.github.io/)
+ [Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control](https://arxiv.org/pdf/2501.03847) (Jan, 2025)
[](https://github.com/IGL-HKUST/DiffusionAsShader)
[](https://arxiv.org/pdf/2501.03847)
[](https://igl-hkust.github.io/das/)
+ [Motion Dreamer: Realizing Physically Coherent Video Generation through Scene-Aware Motion Reasoning](https://arxiv.org/pdf/2412.00547) (Nov, 2024)
[](https://arxiv.org/pdf/2412.00547)
+ [PhyT2V: LLM-Guided Iterative Self-Refinement for Physics-Grounded Text-to-Video Generation](https://arxiv.org/abs/2412.00596) (Nov, 2024)
[](https://github.com/pittisl/PhyT2V)
[](https://arxiv.org/abs/2412.00596)
+ [Phys4DGen: A Physics-Driven Framework for Controllable and Efficient 4D Content Generation from a Single Image](https://arxiv.org/pdf/2411.16800) (Nov, 2024)
[](https://arxiv.org/pdf/2411.16800)
+ [PhysMotion: Physics-Grounded Dynamics From a Single Image](https://arxiv.org/abs/2411.17189) (Nov, 2024)
[](https://arxiv.org/abs/2411.17189)
[](https://supertan0204.github.io/physmotion_website/)
+ [AutoVFX: Physically Realistic Video Editing from Natural Language Instructions](https://arxiv.org/pdf/2411.02385) (Nov, 2024)
[](https://github.com/haoyuhsu/autovfx)
[](https://haoyuhsu.github.io/autovfx-website/)
[](https://haoyuhsu.github.io/autovfx-website/)
+ [How Far is Video Generation from World Model: A Physical Law Perspective](https://arxiv.org/pdf/2411.02385) (Oct, 2024)
[](https://github.com/phyworld/phyworld)
[](https://arxiv.org/pdf/2411.02385)
[](https://phyworld.github.io/)
+ [Tex4D: Zero-shot 4D Scene Texturing with Video Diffusion Models](https://arxiv.org/pdf/2410.10821) (Oct, 2024)
[](https://github.com/ZqlwMatt/Tex4D)
[](https://arxiv.org/pdf/2410.10821)
[](https://tex4d.github.io/)
+ [PhyGenBench: Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation](https://arxiv.org/pdf/2410.05363) (Oct, 2024)
[](https://github.com/OpenGVLab/PhyGenBench)
[](https://arxiv.org/pdf/2410.05363)
[](https://phygenbench123.github.io/)
+ [PhysGen: Rigid-Body Physics-Grounded Image-to-Video Generation](https://arxiv.org/abs/2409.18964) (Oct, 2024)
[](https://github.com/stevenlsw/physgen)
[](https://arxiv.org/abs/2409.18964)
[](https://stevenlsw.github.io/physgen/)
+ [StereoCrafter: Diffusion-based Generation of Long and High-fidelity Stereoscopic 3D from Monocular Videos](https://arxiv.org/pdf/2409.07447) (Oct, 2024)
[](https://arxiv.org/pdf/2409.07447)
[](http://stereocrafter.github.io/)
+ [ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis](https://arxiv.org/abs/2409.02048) (Sep, 2024)
[](https://github.com/Drexubery/ViewCrafter)
[](https://arxiv.org/abs/2409.02048)
[](https://drexubery.github.io/ViewCrafter/)
+ [Compositional 3D-aware Video Generation with LLM Director](https://www.microsoft.com/en-us/research/project/compositional-3d-aware-video-generation/) (Aug, 2024)
[](https://arxiv.org/pdf/2409.00558)
[](https://www.microsoft.com/en-us/research/project/compositional-3d-aware-video-generation/)
+ [IDOL: Unified Dual-Modal Latent Diffusion for Human-Centric Joint Video-Depth Generation](https://arxiv.org/abs/2407.10937) (Jul, 2024)
[](https://github.com/yhZhai/idol)
[](https://arxiv.org/abs/2405.16823)
[](https://arxiv.org/abs/2407.10937)
+ [PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation](https://arxiv.org/abs/2404.13026) (ECCV 2024)
[](https://github.com/a1600012888/PhysDreamer)
[](https://arxiv.org/abs/2404.13026)
[](https://physdreamer.github.io/)
### Video Editing
+ [MTV-Inpaint: Multi-Task Long Video Inpainting](https://arxiv.org/abs/2503.11412) (Mar., 2025)
[](https://arxiv.org/abs/2503.11412)
[](https://mtv-inpaint.github.io/)
+ [Señorita-2M : A High-Quality Instruction-based Dataset for General Video Editing by Video Specialists](https://arxiv.org/abs/2502.06734) (Mar., 2025)
[](https://github.com/zibojia/SENORITA)
[](https://arxiv.org/abs/2502.06734)
[](https://senorita-2m-dataset.github.io/)
+ [VideoGrain: Modulating Space-Time Attention for Multi-grained Video Editing](https://arxiv.org/abs/2502.17258) (Feb., 2025 | ICLR 2025)
[](https://github.com/knightyxp/VideoGrain)
[](https://arxiv.org/abs/2502.17258)
[](https://knightyxp.github.io/VideoGrain_project_page/)
+ [Perception-as-Control: Fine-grained Controllable Image Animation with 3D-aware Motion Representation](https://arxiv.org/pdf/2501.05020) (Jan., 2025)
[](https://github.com/chen-yingjie/Perception-as-Control)
[](https://arxiv.org/pdf/2501.05020)
[](https://chen-yingjie.github.io/projects/Perception-as-Control/)
+ [Qffusion: Controllable Portrait Video Editing via Quadrant-Grid Attention Learning](https://arxiv.org/abs/2501.06438) (Jan., 2025)
[](https://arxiv.org/abs/2501.06438)
+ [MIVE: New Design and Benchmark for Multi-Instance Video Editing](https://arxiv.org/abs/2412.12877) (Dec., 2024)
[](https://arxiv.org/abs/2412.12877)
[](https://kaist-viclab.github.io/mive-site/)
+ [VividFace: A Diffusion-Based Hybrid Framework for High-Fidelity Video Face Swapping](https://arxiv.org/abs/2403.16999) (Dec., 2024)
[](https://github.com/deepcs233/VividFace)
[](https://arxiv.org/abs/2403.16999)
[](https://hao-shao.com/projects/vividface.html)
+ [MotionFlow: Attention-Driven Motion Transfer in Video Diffusion Models](https://arxiv.org/abs/2412.05275) (Dec., 2024)
[](https://arxiv.org/abs/2412.05275)
[](https://motionflow-diffusion.github.io/)
+ [DIVE: Taming DINO for Subject-Driven Video Editing](https://arxiv.org/abs/2412.03347) (Dec., 2024)
[](https://arxiv.org/abs/2412.03347)
[](https://dino-video-editing.github.io/)
+ [AniGS: Animatable Gaussian Avatar from a Single Image with Inconsistent Gaussian Reconstruction](https://arxiv.org/pdf/2412.02684) (Dec., 2024)
[](https://github.com/aigc3d/AniGS)
[](https://arxiv.org/pdf/2412.02684)
[](https://lingtengqiu.github.io/2024/AniGS/)
+ [StableV2V: Stablizing Shape Consistency in Video-to-Video Editing](https://arxiv.org/pdf/2411.11045) (Nov, 2024)
[](https://github.com/AlonzoLeeeooo/StableV2V)
[](https://arxiv.org/pdf/2411.11045)
[](https://alonzoleeeooo.github.io/StableV2V/)
+ [Unified Editing of Panorama, 3D Scenes, and Videos Through Disentangled Self-Attention Injection](https://arxiv.org/abs/2405.16823) (May, 2024)
[](https://arxiv.org/abs/2405.16823)
[](https://unifyediting.github.io/)
+ [I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models](https://arxiv.org/abs/2405.16537) (May, 2024)
[](https://arxiv.org/abs/2405.16537)
[](https://i2vedit.github.io/)
+ [Looking Backward: Streaming Video-to-Video Translation with Feature Banks](https://arxiv.org/abs/2405.15757) (May, 2024)
[](https://github.com/Jeff-LiangF/streamv2v)
[](https://arxiv.org/abs/2405.15757)
[](https://jeff-liangf.github.io/projects/streamv2v/)
+ [ReVideo: Remake a Video with Motion and Content Control](https://arxiv.org/abs/2405.13865) (May, 2024)
[](https://github.com/MC-E/ReVideo)
[](https://arxiv.org/abs/2405.13865)
[](https://mc-e.github.io/project/ReVideo/)
+ [Slicedit: Zero-Shot Video Editing With Text-to-Image Diffusion Models Using Spatio-Temporal Slices](https://arxiv.org/abs/2405.12211) (May, 2024)
[](https://github.com/fallenshock/Slicedit)
[](https://arxiv.org/abs/2405.12211)
[](https://matankleiner.github.io/slicedit/)
+ [ViViD: Video Virtual Try-on using Diffusion Models](https://arxiv.org/abs/2405.11794) (May, 2024)
[](https://github.com/BecauseImBatman0/ViViD)
[](https://arxiv.org/abs/2405.11794)
[](https://becauseimbatman0.github.io/ViViD)
+ [Edit-Your-Motion: Space-Time Diffusion Decoupling Learning for Video Motion Editing](https://arxiv.org/abs/2405.04496) (May, 2024)
[](https://arxiv.org/abs/2405.04496)
+ [GenVideo: One-shot target-image and shape aware video editing using T2I diffusion models](https://arxiv.org/abs/2404.12541) (Apr., 2024)
[](https://arxiv.org/abs/2404.12541)
+ [EVA: Zero-shot Accurate Attributes and Multi-Object Video Editing](https://arxiv.org/abs/2403.16111) (Mar., 2024)
[](https://github.com/knightyxp/EVA_Video_Edit)
[](https://arxiv.org/abs/2403.16111)
[](https://knightyxp.github.io/EVA/)
+ [Spectral Motion Alignment for Video Motion Transfer using Diffusion Models](https://arxiv.org/abs/2403.15249) (Mar., 2024)
[](https://arxiv.org/abs/2403.15249)
[](https://geonyeong-park.github.io/spectral-motion-alignment/)
+ [AnyV2V: A Tuning-Free Framework For Any Video-to-Video Editing Tasks](https://arxiv.org/abs/2403.14468) (Mar., 2024)
[](https://github.com/TIGER-AI-Lab/AnyV2V)
[](https://arxiv.org/abs/2403.14468)
[](https://tiger-ai-lab.github.io/AnyV2V/)
+ [CoCoCo: Improving Text-Guided Video Inpainting for Better Consistency, Controllability and Compatibility](https://arxiv.org/abs/2403.12035) (Mar., 2024)
[](https://arxiv.org/abs/2403.12035)
[](https://cococozibojia.github.io/)
[](https://github.com/zibojia/COCOCO)
+ [DreamMotion: Space-Time Self-Similarity Score Distillation for Zero-Shot Video Editing](https://arxiv.org/abs/2403.12002) (Mar., 2024)
[](https://arxiv.org/abs/2403.12002)
[](https://hyeonho99.github.io/dreammotion/)
+ [Video Editing via Factorized Diffusion Distillation](https://arxiv.org/abs/2403.09334) (Mar., 2024)
[](https://arxiv.org/abs/2403.09334)
[](https://fdd-video-edit.github.io/)
+ [FastVideoEdit: Leveraging Consistency Models for Efficient Text-to-Video Editing](https://arxiv.org/abs/2403.06269) (Mar., 2024)
[](https://arxiv.org/abs/2403.06269)
+ [UniEdit: A Unified Tuning-Free Framework for Video Motion and Appearance Editing](https://arxiv.org/abs/2402.13185) (Feb., 2024)
[](https://github.com/JianhongBai/UniEdit)
[](https://arxiv.org/abs/2402.13185)
[](https://jianhongbai.github.io/UniEdit/)
+ [Object-Centric Diffusion for Efficient Video Editing](https://arxiv.org/abs/2401.05735) (Jan., 2024)
[](https://arxiv.org/abs/2401.05735)
+ [VASE: Object-Centric Shape and Appearance Manipulation of Real Videos](https://arxiv.org/abs/2401.02473) (Jan., 2024)
[](https://github.com/helia95/VASE)
[](https://arxiv.org/abs/2401.02473)
[](https://helia95.github.io/vase-website/)
+ [FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis](https://arxiv.org/abs/2312.17681) (Dec., 2023)
[](https://github.com/Jeff-LiangF/FlowVid)
[](https://arxiv.org/abs/2312.17681)
[](https://jeff-liangf.github.io/projects/flowvid/)
+ [Fairy: Fast Parallelized Instruction-Guided Video-to-Video Synthesis](https://arxiv.org/abs/2312.13834) (Dec., 2023)
[](https://arxiv.org/abs/2312.13834)
[](https://fairy-video2video.github.io/)
+ [RealCraft: Attention Control as A Solution for Zero-shot Long Video Editing](https://arxiv.org/abs/2312.12635) (Dec., 2023)
[](https://arxiv.org/abs/2312.12635)
+ [MaskINT: Video Editing via Interpolative Non-autoregressive Masked Transformers](https://arxiv.org/abs/2312.12468) (Dec., 2023)
[](https://arxiv.org/abs/2312.12468)
[](https://maskint.github.io/)
+ [VidToMe: Video Token Merging for Zero-Shot Video Editing](https://arxiv.org/abs/2312.10656) (Dec., 2023)
[](https://github.com/lixirui142/VidToMe)
[](https://arxiv.org/abs/2312.10656)
[](https://vidtome-diffusion.github.io/)
+ [A Video is Worth 256 Bases: Spatial-Temporal Expectation-Maximization Inversion for Zero-Shot Video Editing](https://arxiv.org/abs/2312.05856) (Dec., 2023)
[](https://github.com/STEM-Inv/stem-inv)
[](https://arxiv.org/abs/2312.05856)
[](https://stem-inv.github.io/page/)
+ [Neutral Editing Framework for Diffusion-based Video Editing](https://arxiv.org/abs/2312.06708) (Dec., 2023)
[](https://arxiv.org/abs/2312.06708)
[](https://neuedit.github.io/)
+ [DiffusionAtlas: High-Fidelity Consistent Diffusion Video Editing](https://arxiv.org/abs/2312.03772) (Dec., 2023)
[](https://arxiv.org/abs/2312.03772)
+ [RAVE: Randomized Noise Shuffling for Fast and Consistent Video Editing with Diffusion Models](https://arxiv.org/abs/2312.04524) (Dec., 2023)
[](https://github.com/rehg-lab/RAVE)
[](https://arxiv.org/abs/2312.04524)
[](https://rave-video.github.io/)
+ [SAVE: Protagonist Diversification with Structure Agnostic Video Editing](https://arxiv.org/abs/2312.02503) (Dec., 2023)
[](https://arxiv.org/abs/2312.02503)
[](https://ldynx.github.io/SAVE/)
+ [MagicStick: Controllable Video Editing via Control Handle Transformations](https://arxiv.org/abs/2312.03047) (Dec., 2023)
[](https://github.com/mayuelala/MagicStick)
[](https://arxiv.org/abs/2312.03047)
[](https://magic-stick-edit.github.io/)
+ [VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence](https://arxiv.org/abs/2312.02087) (CVPR 2024)
[](https://github.com/showlab/VideoSwap)
[](https://arxiv.org/abs/2312.02087)
[](https://videoswap.github.io/)
+ [DragVideo: Interactive Drag-style Video Editing](https://arxiv.org/abs/2312.02216) (Dec., 2023)
[](https://github.com/RickySkywalker/DragVideo-Official)
[](https://arxiv.org/abs/2312.02216)
+ [Drag-A-Video: Non-rigid Video Editing with Point-based Interaction](https://arxiv.org/abs/2312.02936) (Dec., 2023)
[](https://arxiv.org/abs/2312.02936)
[](https://drag-a-video.github.io/)
+ [BIVDiff: A Training-Free Framework for General-Purpose Video Synthesis via Bridging Image and Video Diffusion Models](https://arxiv.org/abs/2312.02813) (Dec., 2023)
[](https://arxiv.org/abs/2312.02813)
[](https://bivdiff.github.io/)
+ [VMC: Video Motion Customization using Temporal Attention Adaption for Text-to-Video Diffusion Models](https://arxiv.org/abs/2312.00845) (CVPR 2024)
[](https://github.com/HyeonHo99/Video-Motion-Customization)
[](https://arxiv.org/abs/2312.00845)
[](https://video-motion-customization.github.io)
+ [FLATTEN: optical FLow-guided ATTENtion for consistent text-to-video editing](https://arxiv.org/abs/2310.05922) (ICLR 2024)
[](https://github.com/yrcong/flatten)
[](https://arxiv.org/abs/2310.05922)
[](https://flatten-video-editing.github.io)
+ [MotionEditor: Editing Video Motion via Content-Aware Diffusion](https://arxiv.org/abs/2311.18830) (Nov., 2023)
[](https://github.com/Francis-Rings/MotionEditor)
[](https://arxiv.org/abs/2311.18830)
[](https://francis-rings.github.io/MotionEditor/)
+ [Motion-Conditioned Image Animation for Video Editing](https://arxiv.org/abs/2311.18827) (Nov., 2023)
[](https://arxiv.org/abs/2311.18827)
[](https://facebookresearch.github.io/MoCA/)
+ [Space-Time Diffusion Features for Zero-Shot Text-Driven Motion Transfer](https://arxiv.org/abs/2311.17009) (CVPR 2024)
[](https://arxiv.org/abs/2311.17009)
[](https://diffusion-motion-transfer.github.io/)
+ [Cut-and-Paste: Subject-Driven Video Editing with Attention Control](https://arxiv.org/abs/2311.11697) (Nov., 2023)
[](https://arxiv.org/abs/2311.11697)
+ [LatentWarp: Consistent Diffusion Latents for Zero-Shot Video-to-Video Translation](https://arxiv.org/abs/2311.00353) (Nov., 2023)
[](https://arxiv.org/abs/2311.00353)
+ [Fuse Your Latents: Video Editing with Multi-source Latent Diffusion Models](https://arxiv.org/abs/2310.16400) (Oct., 2023)
[](https://arxiv.org/abs/2310.16400)
+ [DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing](https://arxiv.org/abs/2310.10624) (Oct., 2023)
[](https://arxiv.org/abs/2310.10624)
[](https://showlab.github.io/DynVideo-E/)
+ [Ground-A-Video: Zero-shot Grounded Video Editing using Text-to-image Diffusion Models](https://arxiv.org/abs/2310.01107) (ICLR 2024)
[](https://github.com/Ground-A-Video/Ground-A-Video)
[](https://arxiv.org/abs/2310.01107)
[](https://ground-a-video.github.io/)
+ [CCEdit: Creative and Controllable Video Editing via Diffusion Models](https://arxiv.org/abs/2309.16496) (Sep., 2023)
[](https://arxiv.org/abs/2309.16496)
+ [MagicProp: Diffusion-based Video Editing via Motion-aware Appearance Propagation](https://arxiv.org/abs/2309.00908) (Sep., 2023)
[](https://arxiv.org/abs/2309.00908)
+ [MagicEdit: High-Fidelity and Temporally Coherent Video Editing](https://arxiv.org/abs/2308.14749) (Aug., 2023)
[](https://github.com/magic-research/magic-edit)
[](https://arxiv.org/abs/2308.14749)
[](https://magic-edit.github.io/)
+ [StableVideo: Text-driven Consistency-aware Diffusion Video Editing](https://arxiv.org/abs/2308.09592) (ICCV 2023)
[](https://github.com/rese1f/StableVideo)
[](https://arxiv.org/abs/2308.09592)
[](https://rese1f.github.io/StableVideo/)
+ [CoDeF: Content Deformation Fields for Temporally Consistent Video Processing](https://arxiv.org/abs/2308.07926) (CVPR 2024)
[](https://github.com/qiuyu96/CoDeF)
[](https://arxiv.org/abs/2308.07926)
[](https://qiuyu96.github.io/CoDeF/)
+ [TokenFlow: Consistent Diffusion Features for Consistent Video Editing](https://arxiv.org/abs/2307.10373) (ICLR 2024)
[](https://github.com/omerbt/TokenFlow)
[](https://arxiv.org/abs/2307.10373)
[](https://diffusion-tokenflow.github.io/)
+ [INVE: Interactive Neural Video Editing](https://arxiv.org/abs/2307.07663) (Jul., 2023)
[](https://arxiv.org/abs/2307.07663)
[](https://gabriel-huang.github.io/inve/)
+ [VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing](https://arxiv.org/abs//2306.08707) (Jun., 2023)
[](https://arxiv.org/abs//2306.08707)
[](https://videdit.github.io/)
+ [Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation](https://arxiv.org/abs/2306.07954) (SIGGRAPH Asia 2023)
[](https://github.com/williamyang1991/Rerender_A_Video)
[](https://arxiv.org/abs/2306.07954)
[](https://www.mmlab-ntu.com/project/rerender/)
+ [ControlVideo: Adding Conditional Control for One Shot Text-to-Video Editing](https://arxiv.org/abs/2305.17098) (May, 2023)
[](https://github.com/thu-ml/controlvideo)
[](https://arxiv.org/abs/2305.17098)
[](https://ml.cs.tsinghua.edu.cn/controlvideo/)
+ [Make-A-Protagonist: Generic Video Editing with An Ensemble of Experts](https://arxiv.org/abs/2305.08850) (May, 2023)
[](https://github.com/Make-A-Protagonist/Make-A-Protagonist)
[](https://arxiv.org/abs/2305.08850)
[](https://make-a-protagonist.github.io/)
+ [Soundini: Sound-Guided Diffusion for Natural Video Editing](https://arxiv.org/abs/2304.06818) (Apr., 2023)
[](https://github.com/kuai-lab/soundini-official)
[](https://arxiv.org/abs/2304.06818)
[](https://kuai-lab.github.io/soundini-gallery/)
+ [Zero-Shot Video Editing Using Off-the-Shelf Image Diffusion Models](https://arxiv.org/abs/2303.17599) (Mar., 2023)
[](https://github.com/baaivision/vid2vid-zero)
[](https://arxiv.org/abs/2303.17599)
[](https://huggingface.co/spaces/BAAI/vid2vid-zero)
+ [Edit-A-Video: Single Video Editing with Object-Aware Consistency](https://arxiv.org/abs/2303.17599) (Mar., 2023)
[](https://arxiv.org/abs/2303.07945)
[](https://edit-a-video.github.io/)
+ [FateZero: Fusing Attentions for Zero-shot Text-based Video Editing](https://arxiv.org/abs/2303.09535) (Mar., 2023)
[](https://github.com/ChenyangQiQi/FateZero)
[](https://arxiv.org/abs/2303.09535)
[](https://fate-zero-edit.github.io/)
+ [Pix2video: Video Editing Using Image Diffusion](https://arxiv.org/abs/2303.12688) (Mar., 2023)
[](https://arxiv.org/abs/2303.12688)
[](https://duyguceylan.github.io/pix2video.github.io/)
+ [Video-P2P: Video Editing with Cross-attention Control](https://arxiv.org/abs/2303.04761) (Mar., 2023)
[](https://github.com/ShaoTengLiu/Video-P2P)
[](https://arxiv.org/abs/2303.04761)
[](https://video-p2p.github.io/)
+ [Dreamix: Video Diffusion Models Are General Video Editors](https://arxiv.org/abs/2302.01329) (Feb., 2023)
[](https://arxiv.org/abs/2302.01329)
[](https://dreamix-video-editing.github.io/)
+ [Shape-Aware Text-Driven Layered Video Editing](https://arxiv.org/abs/2301.13173) (Jan., 2023)
[](https://arxiv.org/abs/2301.13173)
[](https://text-video-edit.github.io/)
+ [Speech Driven Video Editing via an Audio-Conditioned Diffusion Model](https://arxiv.org/abs/2301.04474) (Jan., 2023)
[](https://github.com/DanBigioi/DiffusionVideoEditing)
[](https://arxiv.org/abs/2301.04474)
[](https://danbigioi.github.io/DiffusionVideoEditing/)
+ [Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding](https://arxiv.org/abs/2212.02802) (CVPR 2023)
[](https://github.com/man805/Diffusion-Video-Autoencoders)
[](https://arxiv.org/abs/2212.02802)
[](https://diff-video-ae.github.io/)
### Human or Subject Motion
+ [AnyTop: Character Animation Diffusion with Any Topology](https://arxiv.org/abs/2502.17327) (Feb., 2025)
[](https://github.com/Anytop2025/Anytop)
[](https://arxiv.org/abs/2502.17327)
[](https://anytop2025.github.io/Anytop-page/)
+ [HumanDiT: Pose-Guided Diffusion Transformer for Long-form Human Motion Video Generation](https://arxiv.org/abs/2502.04847) (Feb., 2025)
[](https://arxiv.org/abs/2502.04847)
[](https://agnjason.github.io/HumanDiT-page/)
+ [VideoJAM: Joint Appearance-Motion Representations for Enhanced Motion Generation in Video Models](https://hila-chefer.github.io/videojam-paper.github.io/VideoJAM_arxiv.pdf) (Feb., 2025)
[](https://hila-chefer.github.io/videojam-paper.github.io/VideoJAM_arxiv.pdf)
[](https://hila-chefer.github.io/videojam-paper.github.io/)
+ [OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models](https://arxiv.org/abs/2502.01061) (Feb., 2025)
[](https://arxiv.org/abs/2502.01061)
[](https://omnihuman-lab.github.io/)
+ [AnchorCrafter: Animate CyberAnchors Saling Your Products via Human-Object Interacting Video Generation](https://arxiv.org/pdf/2411.17383) (Nov., 2024)
[](https://github.com/cangcz/AnchorCrafter)
[](https://arxiv.org/pdf/2411.17383)
[](https://cangcz.github.io/Anchor-Crafter/)
+ [KMM: Key Frame Mask Mamba for Extended Motion Generation](https://arxiv.org/abs/2411.06481) (Nov., 2024)
[](https://github.com/steve-zeyu-zhang/KMM)
[](https://arxiv.org/abs/2411.06481)
[](https://steve-zeyu-zhang.github.io/KMM/)
+ [DanceFusion: A Spatio-Temporal Skeleton Diffusion Transformer for Audio-Driven Dance Motion Reconstruction](https://arxiv.org/abs/2411.04646) (Nov., 2024)
[](https://arxiv.org/abs/2411.04646)
[](https://th-mlab.github.io/DanceFusion/)
+ [Enhancing Motion in Text-to-Video Generation with Decomposed Encoding and Conditioning](https://arxiv.org/abs/2410.24219) (Nov., 2024)
[](https://github.com/PR-Ryan/DEMO)
[](https://arxiv.org/abs/2410.24219)
[](https://pr-ryan.github.io/DEMO-project/)
+ [A Comprehensive Survey on Human Video Generation: Challenges, Methods, and Insights](https://arxiv.org/abs/2407.08428) (Jul., 2024)
[](https://arxiv.org/abs/2407.08428)
+ [OccFusion: Rendering Occluded Humans with Generative Diffusion Priors](https://arxiv.org/pdf/2406.08801) (Jul., 2024)
[](https://arxiv.org/pdf/2407.00316)
[](https://cs.stanford.edu/~xtiange/projects/occfusion/)
+ [EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditions](https://arxiv.org/abs/2407.08136) (Jul., 2024)
[](https://github.com/BadToBest/EchoMimic)
[](https://arxiv.org/pdf/2407.08136)
[](https://badtobest.github.io/echomimic.html)
+ [DiffSHEG: A Diffusion-Based Approach for Real-Time Speech-driven Holistic 3D Expression and Gesture Generation](https://arxiv.org/abs/2401.04747) (CVPR 2024)
[](https://github.com/JeremyCJM/DiffSHEG)
[](https://arxiv.org/abs/2401.04747)
[](https://jeremycjm.github.io/proj/DiffSHEG/)
+ [Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model](https://arxiv.org/abs/2304.08577) (CVPR 2023)
[](https://github.com/facebookresearch/AGRoL)
[](https://arxiv.org/abs/2304.08577)
[](https://dulucas.github.io/agrol/)
+ [InterGen: Diffusion-based Multi-human Motion Generation under Complex Interactions](https://arxiv.org/abs/2304.05684) (Apr., 2023)
[](https://github.com/tr3e/InterGen)
[](https://arxiv.org/abs/2304.05684)
+ [ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model](https://arxiv.org/abs/2304.01116) (Apr., 2023)
[](https://github.com/mingyuan-zhang/ReMoDiffuse)
[](https://arxiv.org/abs/2304.01116)
[](https://mingyuan-zhang.github.io/projects/ReMoDiffuse.html)
+ [Human Motion Diffusion as a Generative Prior](https://arxiv.org/abs/2303.01418) (Mar., 2023)
[](https://github.com/priorMDM/priorMDM)
[](https://arxiv.org/abs/2303.01418)
[](https://priormdm.github.io/priorMDM-page/)
+ [Can We Use Diffusion Probabilistic Models for 3d Motion Prediction?](https://arxiv.org/abs/2302.14503) (Feb., 2023)
[](https://github.com/cotton-ahn/diffusion-motion-prediction)
[](https://arxiv.org/abs/2302.14503)
[](https://sites.google.com/view/diffusion-motion-prediction)
+ [Single Motion Diffusion](https://arxiv.org/abs/2302.05905) (Feb., 2023)
[](https://github.com/SinMDM/SinMDM)
[](https://arxiv.org/abs/2302.05905)
[](https://sinmdm.github.io/SinMDM-page/)
+ [HumanMAC: Masked Motion Completion for Human Motion Prediction](https://arxiv.org/abs/2302.03665) (Feb., 2023)
[](https://github.com/LinghaoChan/HumanMAC)
[](https://arxiv.org/abs/2302.03665)
[](https://lhchen.top/Human-MAC/)
+ [DiffMotion: Speech-Driven Gesture Synthesis Using Denoising Diffusion Model](https://arxiv.org/abs/2301.10047) (Jan., 2023)
[](https://arxiv.org/abs/2301.10047)
+ [Modiff: Action-Conditioned 3d Motion Generation With Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2301.03949) (Jan., 2023)
[](https://arxiv.org/abs/2301.03949)
+ [Unifying Human Motion Synthesis and Style Transfer With Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2212.08526) (GRAPP 2023)
[](https://github.com/mrzzy2021/styledmotionsynthesis)
[](https://arxiv.org/abs/2212.08526)
+ [Executing Your Commands via Motion Diffusion in Latent Space](https://arxiv.org/abs/2212.04048) (CVPR 2023)
[](https://github.com/ChenFengYe/motion-latent-diffusion)
[](https://arxiv.org/abs/2212.04048)
[](https://chenxin.tech/mld/)
+ [Pretrained Diffusion Models for Unified Human Motion Synthesis](https://arxiv.org/abs/2212.02837) (Dec., 2022)
[](https://arxiv.org/abs/2212.02837)
[](https://ofa-sys.github.io/MoFusion/)
+ [PhysDiff: Physics-Guided Human Motion Diffusion Model](https://arxiv.org/abs/2212.02500) (Dec., 2022)
[](https://arxiv.org/abs/2212.02500)
[](https://nvlabs.github.io/PhysDiff/)
+ [BeLFusion: Latent Diffusion for Behavior-Driven Human Motion Prediction](https://arxiv.org/abs/2211.14304) (Dec., 2022)
[](https://github.com/BarqueroGerman/BeLFusion)
[](https://arxiv.org/abs/2211.14304)
[](https://barquerogerman.github.io/BeLFusion/)
+ [Diffusion Motion: Generate Text-Guided 3d Human Motion by Diffusion Model](https://arxiv.org/abs/2210.12315) (ICASSP 2023)
[](https://arxiv.org/abs/2210.12315)
+ [Human Joint Kinematics Diffusion-Refinement for Stochastic Motion Prediction](https://arxiv.org/abs/2210.05976) (Oct., 2022)
[](https://arxiv.org/abs/2210.05976)
+ [Human Motion Diffusion Model](https://arxiv.org/abs/2209.14916) (ICLR 2023)
[](https://github.com/GuyTevet/motion-diffusion-model)
[](https://arxiv.org/abs/2209.14916)
[](https://guytevet.github.io/mdm-page/)
+ [FLAME: Free-form Language-based Motion Synthesis & Editing](https://arxiv.org/abs/2209.00349) (AAAI 2023)
[](https://github.com/kakaobrain/flame)
[](https://arxiv.org/abs/2209.00349)
[](https://kakaobrain.github.io/flame/)
+ [MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model](https://arxiv.org/abs/2208.15001) (Aug., 2022)
[](https://github.com/mingyuan-zhang/MotionDiffuse)
[](https://arxiv.org/abs/2208.15001)
[](https://mingyuan-zhang.github.io/projects/MotionDiffuse.html)
+ [Stochastic Trajectory Prediction via Motion Indeterminacy Diffusion](https://arxiv.org/abs/2203.13777) (CVPR 2022)
[](https://github.com/gutianpei/MID)
[](https://arxiv.org/abs/2203.13777)
### Video Enhancement and Restoration
+ [Enhance-A-Video: Better Generated Video for Free](https://arxiv.org/abs/2502.07508) (Feb., 2025)
[](https://github.com/NUS-HPC-AI-Lab/Enhance-A-Video)
[](https://arxiv.org/abs/2502.07508)
[](https://oahzxl.github.io/Enhance_A_Video/)
+ [SVFR: A Unified Framework for Generalized Video Face Restoration](https://arxiv.org/abs/2501.01235) (Jan., 2025)
[](https://arxiv.org/abs/2501.01235)
+ [Disentangled Motion Modeling for Video Frame Interpolation](https://arxiv.org/abs/2406.17256) (Jun, 2024)
[](https://github.com/JHLew/MoMo)
[](https://arxiv.org/abs/2406.17256)
[](https://github.com/JHLew/MoMo)
+ [DiffIR2VR-Zero: Zero-Shot Video Restoration with Diffusion-based Image Restoration Models](https://arxiv.org/abs/2407.01519) (Jul., 2024)
[](https://arxiv.org/abs/2407.01519)
[](https://jimmycv07.github.io/DiffIR2VR_web/)
+ [LDMVFI: Video Frame Interpolation with Latent Diffusion Models](https://arxiv.org/abs/2303.09508) (Mar., 2023)
[](https://arxiv.org/abs/2303.09508)
+ [CaDM: Codec-aware Diffusion Modeling for Neural-enhanced Video Streaming](https://arxiv.org/abs/2211.08428) (Nov., 2022)
[](https://arxiv.org/abs/2211.08428)
### Audio Synthesis for Video
+ [AV-DiT: Efficient Audio-Visual Diffusion Transformer for Joint Audio and Video Generation](https://arxiv.org/pdf/2406.07686) (Feb., 2025)
[](https://arxiv.org/pdf/2406.07686)
+ [UniForm: A Unified Diffusion Transformer for Audio-Video Generation](https://arxiv.org/abs/2502.03897) (Feb., 2025)
[](https://arxiv.org/abs/2502.03897)
[](https://uniform-t2av.github.io/)
+ [AGAV-Rater: Enhancing LMM for AI-Generated Audio-Visual Quality Assessment](https://arxiv.org/abs/2501.18314) (Jan., 2025)
[](https://arxiv.org/abs/2501.18314)
[](https://agav-rater.github.io/)
+ [XMusic: Towards a Generalized and Controllable Symbolic Music Generation Framework](https://arxiv.org/abs/2501.08809) (Jan., 2025)
[](https://arxiv.org/abs/2501.08809)
[](https://xmusic-project.github.io/)
+ [Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis](https://arxiv.org/abs/2412.15322) (Dec., 2024)
[](https://github.com/hkchengrex/MMAudio)
[](https://arxiv.org/abs/2412.15322)
[](https://hkchengrex.com/MMAudio/)
+ [Stable-V2A: Synthesis of Synchronized Audio Effects with Temporal and Semantic Controls](https://arxiv.org/abs/2412.15023) (Dec., 2024)
[](https://github.com/ispamm/Stable-V2A)
[](https://arxiv.org/abs/2412.15023)
[](https://ispamm.github.io/Stable-V2A/)
+ [AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation](https://arxiv.org/abs/2412.15191) (Dec., 2024)
[](https://github.com/snap-research/AVLink)
[](https://arxiv.org/abs/2412.15191)
[](https://snap-research.github.io/AVLink/)
+ [VinTAGe: Joint Video and Text Conditioning for Holistic Audio Generation](https://arxiv.org/abs/2412.10768) (Nov., 2024)
[](https://arxiv.org/abs/2412.10768)
[](https://www.youtube.com/watch?v=QmqWhUjPkJI)
+ [YingSound: Video-Guided Sound Effects Generation with Multi-modal Chain-of-Thought Controls](https://arxiv.org/abs/2412.09551) (Nov., 2024)
[](https://arxiv.org/abs/2412.09551)
[](https://giantailab.github.io/yingsound/)
+ [Video-Guided Foley Sound Generation with Multimodal Controls](https://arxiv.org/pdf/2411.17698) (Nov., 2024)
[](https://arxiv.org/pdf/2411.17698)
[](https://ificl.github.io/MultiFoley/)
+ [MuVi: Video-to-Music Generation with Semantic Alignment and Rhythmic Synchronization](https://arxiv.org/abs/2410.12957) (Oct., 2024)
[](https://arxiv.org/abs/2410.12957)
+ [Diverse and Aligned Audio-to-Video Generation via Text-to-Video Model Adaptation](https://arxiv.org/abs/2309.16429) (Sep., 2023)
[](https://github.com/guyyariv/TempoTokens)
[](https://arxiv.org/abs/2309.16429)
[](https://pages.cs.huji.ac.il/adiyoss-lab/TempoTokens/)
+ [VMAs: Video-to-Music Generation via Semantic Alignment in Web Music Videos](https://www.arxiv.org/abs/2409.07450) (Oct., 2024)
[](https://www.arxiv.org/abs/2409.07450)
[](https://genjib.github.io/project_page/VMAs/index.html)
+ [STA-V2A: Video-to-Audio Generation with Semantic and Temporal Alignment](https://arxiv.org/pdf/2409.08601) (Oct., 2024)
[](https://github.com/y-ren16/STAV2A)
[](https://arxiv.org/pdf/2409.08601)
[](https://y-ren16.github.io/STAV2A/)
+ [Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio Synthesis](https://arxiv.org/pdf/2409.06135) (Sep., 2024)
[](https://github.com/yannqi/Draw-an-Audio-Code)
[](https://arxiv.org/pdf/2409.06135)
[](https://yannqi.github.io/Draw-an-Audio/)
+ [Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming](https://arxiv.org/abs/2408.16725) (Jul., 2024)
[](https://github.com/gpt-omni/mini-omni)
[](https://arxiv.org/abs/2408.16725)
[](https://github.com/gpt-omni/mini-omni)
+ [Speech To Speech: an effort for an open-sourced and modular GPT4-o](https://github.com/huggingface/speech-to-speech) (Aug., 2024)
[](https://github.com/huggingface/speech-to-speech)
[](https://github.com/huggingface/speech-to-speech)
+ [Video-Foley: Two-Stage Video-To-Sound Generation via Temporal Event Condition For Foley Sound](https://arxiv.org/abs/2408.11915) (Aug., 2024)
[](https://github.com/jnwnlee/video-foley)
[](https://arxiv.org/abs/2408.11915)
[](https://jnwnlee.github.io/video-foley-demo/)
+ [Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity](https://arxiv.org/abs/2407.10387) (Jul., 2024)
[](https://arxiv.org/abs/2407.10387)
[](https://maskvat.github.io/)
+ [Video-to-Audio Generation with Hidden Alignment](https://arxiv.org/abs/2407.07464) (Jul., 2024)
[](https://github.com/ariesssxu/vta-ldm)
[](https://arxiv.org/abs/2407.07464)
[](https://sites.google.com/view/vta-ldm)
+ [Read, Watch and Scream! Sound Generation from Text and Video](https://arxiv.org/abs/2407.05551) (Jul., 2024)
[](https://github.com/naver-ai/rewas)
[](https://arxiv.org/abs/2407.05551)
[](https://naver-ai.github.io/rewas/)
+ [FoleyCrafter: Bring Silent Videos to Life with Lifelike and Synchronized Sounds](https://arxiv.org/abs/2407.01494) (July, 2024)
[](https://arxiv.org/abs/2407.01494)
[](https://foleycrafter.github.io/)
+ [Network Bending of Diffusion Models for Audio-Visual Generation](https://arxiv.org/abs/2406.19589) (CVPR, 2024)
[](https://github.com/dzluke/DAFX2024)
[](https://arxiv.org/abs/2406.19589)
### Talking Head Generation
+ [Audio-visual Controlled Video Diffusion with Masked Selective State Spaces Modelling for Natural Talking Head Generation](https://harlanhong.github.io/publications/actalker/index.html) (Apr., 2025)
[](https://arxiv.org/abs/2504.02542)
[](https://harlanhong.github.io/publications/actalker/index.html)
[](https://github.com/harlanhong/ACTalker)
+ [MoCha: Towards Movie-Grade Talking Character Synthesis](https://arxiv.org/abs/2503.23307) (Apr., 2025)
[](https://arxiv.org/abs/2503.23307)
[](https://congwei1230.github.io/MoCha/)
+ [SayAnything: Audio-Driven Lip Synchronization with Conditional Video Diffusion](https://arxiv.org/pdf/2502.11515) (Feb., 2025)
[](https://arxiv.org/pdf/2502.11515)
+ [VQTalker: Towards Multilingual Talking Avatars through Facial Motion Tokenization](https://arxiv.org/abs/2412.09892) (Dec., 2024)
[](https://arxiv.org/abs/2412.09892)
[](https://x-lance.github.io/VQTalker/)
+ [IF-MDM: Implicit Face Motion Diffusion Model for High-Fidelity Realtime Talking Head Generation](https://arxiv.org/abs/2412.04000) (Dec., 2024)
[](https://arxiv.org/abs/2412.04000)
[](http://ec2-3-25-102-128.ap-southeast-2.compute.amazonaws.com/IF-MDM/ifmdm_supplementary/index.html)
+ [INFP: Audio-Driven Interactive Head Generation in Dyadic Conversations](https://arxiv.org/pdf/2412.04037) (Dec., 2024)
[](https://arxiv.org/pdf/2412.04037)
[](https://grisoon.github.io/INFP/)
+ [MEMO: Memory-Guided Diffusion for Expressive Talking Video Generation](https://arxiv.org/abs/2412.04448) (Dec., 2024)
[](https://arxiv.org/abs/2412.04448)
[](https://memoavatar.github.io/)
[](https://github.com/memoavatar/memo)
+ [SINGER: Vivid Audio-driven Singing Video Generation with Multi-scale Spectral Diffusion Model](https://arxiv.org/pdf/2412.03430) (Dec., 2024)
[](https://arxiv.org/pdf/2412.03430)
[](https://yl4467.github.io/)
+ [Synergizing Motion and Appearance: Multi-Scale Compensatory Codebooks for Talking Head Video Generation](https://arxiv.org/abs/2412.00719) (Nov., 2024)
[](https://github.com/ShaelynZ/synergize-motion-appearance)
[](https://arxiv.org/abs/2412.00719)
[](https://shaelynz.github.io/synergize-motion-appearance/)
+ [Hallo3: Highly Dynamic and Realistic Portrait Image Animation with Diffusion Transformer Networks](https://arxiv.org/pdf/2412.00733) (Nov., 2024)
[](https://arxiv.org/pdf/2412.00733)
[](https://github.com/fudan-generative-vision/hallo3)
+ [FLOAT: Generative Motion Latent Flow Matching for Audio-driven Talking Portrait](https://arxiv.org/abs/2412.01064) (Nov., 2024)
[](https://arxiv.org/abs/2412.01064)
[](https://deepbrainai-research.github.io/float/)
+ [EmotiveTalk: Expressive Talking Head Generation through Audio Information Decoupling and Emotional Video Diffusion](https://arxiv.org/pdf/2411.16726) (Nov., 2024)
[](https://arxiv.org/pdf/2411.16726)
+ [LetsTalk: Latent Diffusion Transformer for Talking Video Synthesis](https://arxiv.org/pdf/2411.16748) (Nov., 2024)
[](https://arxiv.org/pdf/2411.16748)
+ [Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency](https://arxiv.org/pdf/2409.02634) (Nov., 2024)
[](https://arxiv.org/pdf/2409.02634)
[](https://loopyavatar.github.io/)
+ [HelloMeme: Integrating Spatial Knitting Attentions to Embed High-Level and Fidelity-Rich Conditions in Diffusion Models](https://arxiv.org/abs/2410.22901) (Oct., 2024)
[](https://github.com/HelloVision/HelloMeme)
[](https://arxiv.org/abs/2410.22901)
[](https://songkey.github.io/hellomeme/)
+ [PersonaTalk: Bring Attention to Your Persona in Visual Dubbing](https://arxiv.org/pdf/2409.05379) (Oct., 2024)
[](https://arxiv.org/pdf/2409.05379)
[](https://grisoon.github.io/PersonaTalk/)
+ [Talking With Hands 16.2M: A Large-Scale Dataset of Synchronized Body-Finger Motion and Audio for Conversational Motion Analysis and Synthesis](https://openaccess.thecvf.com/content_ICCV_2019/papers/Lee_Talking_With_Hands_16.2M_A_Large-Scale_Dataset_of_Synchronized_Body-Finger_ICCV_2019_paper.pdf) (Oct., 2024)
[](https://openaccess.thecvf.com/content_ICCV_2019/papers/Lee_Talking_With_Hands_16.2M_A_Large-Scale_Dataset_of_Synchronized_Body-Finger_ICCV_2019_paper.pdf)
+ [Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion](https://arxiv.org/abs/2204.08451) (Oct., 2024)
[](https://github.com/evonneng/learning2listen)
[](https://arxiv.org/abs/2204.08451)
[](https://evonneng.github.io/learning2listen/)
+ [GestureDiffuCLIP: Gesture Diffusion Model with CLIP Latents](https://arxiv.org/abs/2303.14613) (Oct., 2024)
[](https://arxiv.org/abs/2303.14613)
[](https://pku-mocca.github.io/GestureDiffuCLIP-Page/)
+ [From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations](https://evonneng.github.io/projects/audio2photoreal/static/CCA.pdf) (Oct., 2024)
[](https://evonneng.github.io/projects/audio2photoreal/static/CCA.pdf)
[](https://evonneng.github.io/projects/audio2photoreal/index.html)
+ [Takin-ADA: Emotion Controllable Audio-Driven Animation with Canonical and Landmark Loss Optimization](https://arxiv.org/pdf/2410.14283) (Oct., 2024)
[](https://arxiv.org/pdf/2410.14283)
[](https://everest-ai.github.io/takinada/)
+ [DAWN: Dynamic Frame Avatar with Non-autoregressive Diffusion Framework for Talking Head Video Generation](https://arxiv.org/abs/2410.13726) (Oct., 2024)
[](https://github.com/Hanbo-Cheng/DAWN-pytorch)
[](https://arxiv.org/abs/2410.13726)
[](https://hanbo-cheng.github.io/DAWN/)
+ [MimicTalk: Mimicking a personalized and expressive 3D talking face in few minutes](https://arxiv.org/abs/2410.06734) (Oct., 2024)
[](https://github.com/yerfor/MimicTalk)
[](https://arxiv.org/abs/2410.06734)
[](https://mimictalk.github.io/)
+ [Hallo2: Long-Duration and High-Resolution Audio-driven Portrait Image Animation](https://arxiv.org/pdf/2410.07718) (Oct., 2024)
[](https://github.com/fudan-generative-vision/hallo2)
[](https://arxiv.org/pdf/2410.07718)
[](https://fudan-generative-vision.github.io/hallo2/#/)
+ [Listen, Denoise, Action! Audio-Driven Motion Synthesis With Diffusion Models](https://arxiv.org/abs/2211.09707) (Nov. 2022)
[](https://arxiv.org/abs/2211.09707)
[](https://www.speech.kth.se/research/listen-denoise-action/)
+ [TANGO: Co-Speech Gesture Video Reenactment with Hierarchical Audio Motion Embedding and Diffusion Interpolation](https://arxiv.org/pdf/2410.04221) (Oct., 2024)
[](https://arxiv.org/pdf/2410.04221)
[](https://pantomatrix.github.io/TANGO/)
+ [Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation](https://arxiv.org/pdf/2406.08801) (Jun., 2024)
[](https://github.com/fudan-generative-vision/hallo)
[](https://arxiv.org/pdf/2406.08801)
[](https://fudan-generative-vision.github.io/hallo/#/)
### Human/AI Feedback for Video Generation
+ [LiFT: Leveraging Human Feedback for Text-to-Video Model Alignment](https://arxiv.org/pdf/2412.04814) (Dec., 2024)
[](https://github.com/CodeGoat24/LiFT)
[](https://arxiv.org/pdf/2412.04814)
[](https://codegoat24.github.io/LiFT/)
+ [Improving Dynamic Object Interactions in Text-to-Video Generation with AI Feedback](https://arxiv.org/abs/2412.02617) (Nov., 2024)
[](https://arxiv.org/abs/2412.02617)
[](https://sites.google.com/view/aif-dynamic-t2v/)
+ [VIDEOSCORE: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation](https://arxiv.org/pdf/2406.15252) (July, 2024)
[](https://github.com/TIGER-AI-Lab/VideoScore/)
[](https://arxiv.org/abs/2406.15252)
[](https://tiger-ai-lab.github.io/VideoScore/)
### Policy Learning
+ [Object-Centric Image to Video Generation with Language Guidance](https://arxiv.org/abs/2502.11655) (Feb, 2025)
[](https://github.com/angelvillar96/TextOCVP)
[](https://arxiv.org/abs/2502.11655)
[](https://play-slot.github.io/TextOCVP/)
+ [Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations](https://arxiv.org/abs/2412.14803) (Dec, 2024)
[](https://arxiv.org/abs/2412.14803)
[](https://video-prediction-policy.github.io/)
+ [Motion Tracks: A Unified Representation for Human-Robot Transfer in Few-Shot Imitation Learning](https://portal-cornell.github.io/motion_track_policy/) (Dec, 2024)
[](https://portal-cornell.github.io/motion_track_policy/)
[](https://portal-cornell.github.io/motion_track_policy/)
+ [Stag-1: Towards Realistic 4D Driving Simulation with Video Generation Model](https://arxiv.org/abs/2412.05280) (Dec, 2024)
[](https://github.com/wzzheng/Stag)
[](https://arxiv.org/abs/2412.05280)
[](https://wzzheng.net/Stag/)
+ [RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches](https://arxiv.org/abs/2403.02709) (Dec, 2024)
[](https://arxiv.org/abs/2403.02709)
[](https://rt-sketch.github.io/)
+ [EgoVid-5M: A Large-Scale Video-Action Dataset for Egocentric Video Generation](https://arxiv.org/pdf/2411.08380) (Nov, 2024)
[](https://github.com/JeffWang987/EgoVid)
[](https://arxiv.org/pdf/2411.08380)
[](https://egovid.github.io/)
+ [GR-MG: Leveraging Partially Annotated Data via Multi-Modal Goal Conditioned Policy](https://arxiv.org/abs/2408.14368) (July, 2024)
[](https://github.com/bytedance/GR-MG)
[](https://arxiv.org/abs/2408.14368)
[](https://gr-mg.github.io/)
+ [Any-point Trajectory Modeling for Policy Learning](https://arxiv.org/abs/2401.00025) (July, 2024)
[](https://github.com/Large-Trajectory-Model/ATM)
[](https://arxiv.org/abs/2401.00025)
[](https://xingyu-lin.github.io/atm/)
+ [This&That: Language-Gesture Controlled Video Generation for Robot Planning](https://arxiv.org/abs/2407.05530) (Jun, 2024)
[](https://github.com/cfeng16/this-and-that)
[](https://arxiv.org/abs/2407.05530)
[](https://cfeng16.github.io/this-and-that/)
+ [Dreamitate: Real-World Visuomotor Policy Learning via Video Generation](https://arxiv.org/abs/2406.16862) (Jun, 2024)
[](https://github.com/cvlab-columbia/dreamitate)
[](https://arxiv.org/abs/2406.16862)
[](https://dreamitate.cs.columbia.edu/)
### Virtual Try-On
+ [1-2-1: Renaissance of Single-Network Paradigm for Virtual Try-On](https://arxiv.org/abs/2501.05369) (Jan., 2025)
[](https://github.com/ningshuliang/1-2-1-MNVTON)
[](https://arxiv.org/abs/2501.05369)
[](https://ningshuliang.github.io/2023/Arxiv/index.html)
+ [Dynamic Try-On: Taming Video Virtual Try-on with Dynamic Attention Mechanism](https://arxiv.org/abs/2412.09822) (Dec., 2024)
[](https://arxiv.org/abs/2412.09822)
[](https://zhengjun-ai.github.io/dynamic-tryon-page/)
+ [Fashion-VDM: Video Diffusion Model for Virtual Try-On](https://arxiv.org/abs/2411.00225) (Nov., 2024)
[](https://arxiv.org/abs/2411.00225)
[](https://johannakarras.github.io/Fashion-VDM/)
### 3D
+ [Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models](https://arxiv.org/abs/2503.01774) (Mar., 2025 | CVPR 2025)
[](https://arxiv.org/abs/2503.01774)
[](https://research.nvidia.com/labs/toronto-ai/difix3d/)
+ [Wonderland: Navigating 3D Scenes from a Single Image](https://arxiv.org/abs/2412.12091) (Dec., 2024)
[](https://arxiv.org/abs/2412.12091)
[](https://snap-research.github.io/wonderland/)
+ [GPT-4V(ision) is a Human-Aligned Evaluator for Text-to-3D Generation](https://arxiv.org/abs/2401.04092) (Jan., 2024)
[](https://arxiv.org/abs/2401.04092)
[](https://gpteval3d.github.io/)
[](https://github.com/3DTopia/GPTEval3D)
+ [MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion](https://arxiv.org/abs/2410.03825) (Oct., 2024)
[](https://arxiv.org/abs/2410.03825)
[](https://monst3r-project.github.io/)
[](https://github.com/Junyi42/monst3r)
+ [L3DG: Latent 3D Gaussian Diffusion](https://arxiv.org/abs/2112.03288) (Oct., 2024)
[](https://arxiv.org/abs/2112.03288)
[](https://barbararoessle.github.io/l3dg/)
+ [ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model](https://arxiv.org/abs/2410.07155) (Oct., 2024)
[](https://github.com/YangLing0818/Trans4D)
[](https://arxiv.org/abs/2410.07155)
[](https://github.com/YangLing0818/Trans4D)
+ [Hi3D: Pursuing High-Resolution Image-to-3D Generation with Video Diffusion Models](https://arxiv.org/pdf/2409.07452) (Oct., 2024)
[](https://github.com/yanghb22-fdu/Hi3D-Official)
[](https://arxiv.org/pdf/2409.07452)
+ [ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model](https://arxiv.org/abs/2408.16767) (Aug., 2024)
[](https://github.com/liuff19/ReconX)
[](https://arxiv.org/abs/2408.16767)
[](https://liuff19.github.io/ReconX/)
+ [SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency](https://arxiv.org/abs/2407.17470) (Jul., 2024)
[](https://github.com/Stability-AI/generative-models)
[](https://arxiv.org/abs/2407.13764)
[](https://sv4d.github.io/)
+ [Shape of Motion: 4D Reconstruction from a Single Video](https://arxiv.org/abs/2407.13764) (Jul., 2024)
[](https://github.com/vye16/shape-of-motion/)
[](https://arxiv.org/abs/2407.13764)
[](https://shape-of-motion.github.io/)
+ [WonderWorld: Interactive 3D Scene Generation from a Single Image](https://arxiv.org/abs/2406.09394) (Jun., 2024)
[](https://arxiv.org/abs/2406.09394)
[](https://wonderworld-2024.github.io/)
+ [WonderJourney: Going from Anywhere to Everywhere](https://arxiv.org/pdf/2312.03884) (CVPR 2024)
[](https://github.com/KovenYu/WonderJourney)
[](https://arxiv.org/pdf/2312.03884)
[](https://kovenyu.com/wonderjourney/)
+ [MultiDiff: Consistent Novel View Synthesis from a Single Image](https://sirwyver.github.io/MultiDiff/static/assets/MultiDiff.pdf) (CVPR, 2024)
[](https://sirwyver.github.io/MultiDiff/static/assets/MultiDiff.pdf)
[](https://sirwyver.github.io/MultiDiff/)
+ [Vivid-ZOO: Multi-View Video Generation with Diffusion Model](https://arxiv.org/pdf/2406.08659v1) (Jun, 2024)
[](https://github.com/hi-zhengcheng/vividzoo)
[](https://arxiv.org/pdf/2406.08659v1)
[](https://hi-zhengcheng.github.io/vividzoo/)
+ [Director3D: Real-world Camera Trajectory and 3D Scene Generation from Text](https://arxiv.org/pdf/2406.17601) (June, 2024)
[](https://github.com/imlixinyang/director3d)
[](https://arxiv.org/pdf/2406.17601)
[](https://imlixinyang.github.io/director3d-page/)
+ [YouDream: Generating Anatomically Controllable Consistent Text-to-3D Animals](https://arxiv.org/abs/2406.16273v1) (June, 2024)
[](https://github.com/YouDream3D/YouDream/)
[](https://arxiv.org/abs/2406.16273v1)
[](https://youdream3d.github.io/)
+ [Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields](https://arxiv.org/abs/2305.11588) (May, 2023)
[](https://arxiv.org/abs/2305.11588)
[](https://eckertzhang.github.io/Text2NeRF.github.io/)
+ [RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture](https://arxiv.org/abs/2305.11337) (May, 2023)
[](https://arxiv.org/abs/2305.11337)
+ [NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models](https://arxiv.org/abs/2304.09787) (CVPR 2023)
[](https://arxiv.org/abs/2304.09787)
[](https://research.nvidia.com/labs/toronto-ai/NFLDM/)
+ [Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction](https://arxiv.org/abs/2304.06714) (Apr., 2023)
[](https://github.com/Lakonik/SSDNeRF)
[](https://arxiv.org/abs/2304.06714)
[](https://lakonik.github.io/ssdnerf/)
+ [Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions](https://arxiv.org/abs/2303.12789) (Mar., 2023)
[](https://github.com/ayaanzhaque/instruct-nerf2nerf)
[](https://arxiv.org/abs/2303.12789)
[](https://instruct-nerf2nerf.github.io/)
+ [DiffusioNeRF: Regularizing Neural Radiance Fields with Denoising Diffusion Models](https://arxiv.org/abs/2302.12231) (Feb., 2023)
[](https://github.com/nianticlabs/diffusionerf)
[](https://arxiv.org/abs/2302.12231)
+ [NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion](https://arxiv.org/abs/2302.10109) (Feb., 2023)
[](https://arxiv.org/abs/2302.10109)
[](https://jiataogu.me/nerfdiff/)
+ [DiffRF: Rendering-guided 3D Radiance Field Diffusion](https://arxiv.org/abs/2212.01206) (CVPR 2023)
[](https://arxiv.org/abs/2212.01206)
[](https://sirwyver.github.io/DiffRF/)
### 4D
+ [AvatarArtist: Open-Domain 4D Avatarization](https://arxiv.org/abs/2503.19906) (Apr., 2025)
[](https://github.com/ant-research/AvatarArtist)
[](https://arxiv.org/abs/2503.19906)
[](https://kumapowerliu.github.io/AvatarArtist/)
+ [Not All Frame Features Are Equal: Video-to-4D Generation via Decoupling Dynamic-Static Features](https://arxiv.org/abs/2502.08377) (Feb., 2025)
[](https://github.com/paintscene4d/paintscene4d.github.io)
[](https://arxiv.org/abs/2502.08377)
[](https://paintscene4d.github.io/)
+ [DreamDrive: Generative 4D Scene Modeling from Street View Images](https://arxiv.org/pdf/2501.00601) (Jan., 2025)
[](https://arxiv.org/pdf/2501.00601)
+ [Stereo4D Learning How Things Move in 3D from Internet Stereo Videos](https://arxiv.org/pdf/2412.09621) (Dec., 2024)
[](https://arxiv.org/pdf/2412.09621)
[](https://stereo4d.github.io/)
+ [4Real-Video: Learning Generalizable Photo-Realistic 4D Video Diffusion](https://arxiv.org/abs/2412.04462) (Dec., 2024)
[](https://arxiv.org/abs/2412.04462)
[](https://snap-research.github.io/4Real-Video/)
+ [PaintScene4D: Consistent 4D Scene Generation from Text Prompts](https://arxiv.org/abs/2412.04471) (Dec., 2024)
[](https://github.com/paintscene4d/paintscene4d.github.io)
[](https://arxiv.org/abs/2412.04471)
[](https://paintscene4d.github.io/)
+ [CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models](https://arxiv.org/abs/2411.18613) (Nov., 2024)
[](https://arxiv.org/abs/2411.18613)
[](https://cat-4d.github.io/)
+ [DimensionX: Create Any 3D and 4D Scenes from a Single Image with Controllable Video Diffusion](https://arxiv.org/pdf/2411.04928) (Nov., 2024)
[](https://github.com/wenqsun/DimensionX)
[](https://arxiv.org/pdf/2411.04928)
[](https://chenshuo20.github.io/DimensionX/)
### Game Generation
+ [Playable Game Generation](https://arxiv.org/pdf/2412.00887) (Nov., 2024)
[](https://arxiv.org/pdf/2412.00887)
[](http://124.156.151.207)
### AI Safety
+ [What Matters in Detecting AI-Generated Videos like Sora?](https://arxiv.org/abs/2406.19568) (Jun., 2024)
[](https://arxiv.org/abs/2406.19568)
[](https://justin-crchang.github.io/3DCNNDetection.github.io/)
### Rendering with Virtual Engine
+ [UnrealZoo: Enriching Photo-realistic Virtual Worlds for Embodied AI](https://arxiv.org/abs/2412.20977) (Jan., 2025)
[](https://github.com/UnrealZoo/unrealzoo-gym)
[](https://arxiv.org/abs/2412.20977)
[](http://unrealzoo.site/)
+ [Infinigen Indoors: Photorealistic Indoor Scenes using Procedural Generation](https://arxiv.org/abs/2406.11824) (CVPR 2024)
[](https://arxiv.org/abs/2406.11824)
[](https://infinigen.org/)
+ [Scene Co-pilot: Procedural Text to Video Generation with Human in the Loop](https://arxiv.org/abs/2411.18644) (Dec., 2024)
[](https://arxiv.org/abs/2411.18644)
[](https://abolfazl-sh.github.io/Scene_co-pilot_site/)
### Open-World Model
+ [Aether: Geometric-Aware Unified World Modeling](https://arxiv.org/pdf/2503.18945) (Mar., 2025)
[](https://github.com/OpenRobotLab/Aether)
[](https://arxiv.org/pdf/2503.18945)
[](https://aether-world.github.io/#team)
+ [Pre-Trained Video Generative Models as World Simulators](https://arxiv.org/abs/2502.07825) (Feb., 2025)
[](https://arxiv.org/abs/2502.07825)
+ [VideoWorld: Exploring Knowledge Learning from Unlabeled Videos](https://arxiv.org/abs/2501.09781) (Jan., 2025)
[](https://github.com/bytedance/VideoWorld)
[](https://arxiv.org/abs/2501.09781)
[](https://maverickren.github.io/VideoWorld.github.io/)
+ [GameFactory: Creating New Games with Generative Interactive Videos](https://arxiv.org/abs/2501.08325) (Jan., 2025)
[](https://github.com/KwaiVGI/GameFactory)
[](https://arxiv.org/abs/2501.08325)
[](https://vvictoryuki.github.io/gamefactory/)
+ [Vid2Sim: Realistic and Interactive Simulation from Video for Urban Navigation](https://arxiv.org/abs/2501.06693) (Jan., 2025)
[](https://arxiv.org/abs/2501.06693)
[](https://metadriverse.github.io/vid2sim/)
+ [GenEx: Generating an Explorable World](https://arxiv.org/abs/2412.09624) (Dec., 2024)
[](https://arxiv.org/abs/2412.09624)
[](https://genex.world/)
+ [The Matrix: Infinite-Horizon World Generation with Real-Time Moving Control](https://arxiv.org/pdf/2412.03568) (Dec., 2024)
[](https://arxiv.org/pdf/2412.03568)
[](https://thematrix1999.github.io/)
+ [Navigation World Models](https://arxiv.org/abs/2412.03572) (Dec., 2024)
[](https://arxiv.org/abs/2412.03572)
[](https://www.amirbar.net/nwm/)
+ [Genie 2: A large-scale foundation world model](https://deepmind.google/discover/blog/genie-2-a-large-scale-foundation-world-model/) (Dec., 2024)
[](https://deepmind.google/discover/blog/genie-2-a-large-scale-foundation-world-model/)
+ [Understanding World or Predicting Future? A Comprehensive Survey of World Models](https://arxiv.org/abs/2411.14499) (Nov., 2024)
[](https://arxiv.org/abs/2411.14499)
+ [AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents](https://arxiv.org/abs/2407.18901) (Nov., 2024)
[](https://github.com/stonybrooknlp/appworld/)
[](https://arxiv.org/abs/2407.18901)
[](https://appworld.dev/)
+ [Oasis: A Universe in a Transformer](https://www.decart.ai/articles/oasis-interactive-ai-video-game-model) (Nov., 2024)
[](https://github.com/etched-ai/open-oasis)
[](https://www.decart.ai/articles/oasis-interactive-ai-video-game-model)
[](https://www.decart.ai/articles/oasis-interactive-ai-video-game-model)
+ [Digital Life Project: Autonomous 3D Characters with Social Intelligence](https://arxiv.org/abs/2312.04547) (CVPR 2024)
[](https://github.com/caizhongang/Digital_Life_Project)
[](https://arxiv.org/abs/2312.04547)
[](https://digital-life-project.com/)
+ [3D-VLA: A 3D Vision-Language-Action Generative World Model](https://arxiv.org/abs/2403.09631) (ICML 2024)
[](https://github.com/UMass-Foundation-Model/3D-VLA)
[](https://arxiv.org/abs/2403.09631)
[](https://vis-www.cs.umass.edu/3dvla/)
### Video Understanding
+ [UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics](https://arxiv.org/pdf/2412.07774) (Dec., 2024)
[](https://arxiv.org/pdf/2412.07774)
[](https://xavierchen34.github.io/UniReal-Page/)
+ [Divot: Diffusion Powers Video Tokenizer for Comprehension and Generation](https://arxiv.org/abs/2412.04432) (Nov., 2024)
[](https://github.com/TencentARC/Divot)
[](https://arxiv.org/abs/2412.04432)
+ [VLM-Grounder: A VLM Agent for Zero-Shot 3D Visual Grounding](https://arxiv.org/pdf/2410.13860) (Oct., 2024)
[](https://github.com/OpenRobotLab/VLM-Grounder)
[](https://arxiv.org/pdf/2410.13860)
+ [Exploring Diffusion Models for Unsupervised Video Anomaly Detection](https://arxiv.org/abs/2304.05841) (Apr., 2023)
[](https://arxiv.org/abs/2304.05841)
+ [PDPP:Projected Diffusion for Procedure Planning in Instructional Videos](https://arxiv.org/abs/2303.14676) (CVPR 2023)
[](https://github.com/MCG-NJU/PDPP)
[](https://arxiv.org/abs/2303.14676)
+ [DiffTAD: Temporal Action Detection with Proposal Denoising Diffusion](https://arxiv.org/abs/2303.14863) (Mar., 2023)
[](https://github.com/sauradip/DiffusionTAD)
[](https://arxiv.org/abs/2303.14863)
+ [Diffusion Action Segmentation](https://arxiv.org/abs/2303.17959) (ICCV 2023)
[](https://github.com/Finspire13/DiffAct)
[](https://arxiv.org/abs/2303.17959)
[](https://daochang.site/DiffAct-Project-Page/)
+ [DiffusionRet: Generative Text-Video Retrieval with Diffusion Model](https://arxiv.org/abs/2303.09867) (ICCV 2023)
[](https://github.com/jpthu17/DiffusionRet)
[](https://arxiv.org/abs/2303.09867)
+ [Refined Semantic Enhancement Towards Frequency Diffusion for Video Captioning](https://arxiv.org/abs/2211.15076) (Nov., 2022)
[](https://github.com/lzp870/RSFD)
[](https://arxiv.org/abs/2211.15076)
+ [A Generalist Framework for Panoptic Segmentation of Images and Videos](https://arxiv.org/abs/2210.06366) (Oct., 2022)
[](https://github.com/google-research/pix2seq)
[](https://arxiv.org/abs/2210.06366)
### Healthcare and Biology
+ [Medical Video Generation for Disease Progression Simulation](https://arxiv.org/abs/2411.11943) (Nov., 2024)
[](https://arxiv.org/abs/2411.11943)
+ [Artificial Intelligence for Biomedical Video Generation](https://arxiv.org/pdf/2411.07619) (Nov., 2024)
[](https://github.com/Finspire13/DiffAct)
[](https://arxiv.org/pdf/2411.07619)
+ [Exploring Variational Autoencoders for Medical Image Generation: A Comprehensive Study](https://arxiv.org/abs/2411.07348) (Nov., 2024)
[](https://arxiv.org/abs/2411.07348)
+ [MedSora: Optical Flow Representation Alignment Mamba Diffusion Model for Medical Video Generation](https://arxiv.org/abs/2411.01647) (Nov., 2024)
[](https://arxiv.org/abs/2411.01647)
[](https://wongzbb.github.io/MedSora/)
+ [Annealed Score-Based Diffusion Model for Mr Motion Artifact Reduction](https://arxiv.org/abs/2301.03027) (Jan., 2023)
[](https://arxiv.org/abs/2301.03027)
+ [Feature-Conditioned Cascaded Video Diffusion Models for Precise Echocardiogram Synthesis](https://arxiv.org/abs/2303.12644) (Mar., 2023)
[](https://arxiv.org/abs/2303.12644)
+ [Neural Cell Video Synthesis via Optical-Flow Diffusion](https://arxiv.org/abs/2212.03250) (Dec., 2022)
[](https://arxiv.org/abs/2212.03250)
### Other Applications
+ [History-Guided Video Diffusion](https://arxiv.org/abs/2502.06764) (Feb., 2025)
[](https://github.com/kwsong0113/diffusion-forcing-transformer)
[](https://arxiv.org/abs/2502.06764)
[](https://boyuan.space/history-guidance/)
+ [VidSketch: Hand-drawn Sketch-Driven Video Generation with Diffusion Control](https://arxiv.org/pdf/2502.01101) (Feb., 2025)
[](https://arxiv.org/pdf/2502.01101)
+ [VanGogh: A Unified Multimodal Diffusion-based Framework for Video Colorization](https://arxiv.org/pdf/2501.09499) (Jan., 2025)
[](https://github.com/BecauseImBatman0/VanGogh)
[](https://arxiv.org/pdf/2501.09499)
[](https://becauseimbatman0.github.io/VanGogh)
+ [PhysAnimator: Physics-Guided Generative Cartoon Animation](https://arxiv.org/pdf/2501.16550) (Feb., 2025)
[](https://arxiv.org/pdf/2501.16550)