https://github.com/ushakrishnan/awesome-llm-finetuning
Resources to aid your learning of LLM finetuning.
https://github.com/ushakrishnan/awesome-llm-finetuning
List: awesome-llm-finetuning
Last synced: 7 months ago
JSON representation
Resources to aid your learning of LLM finetuning.
- Host: GitHub
- URL: https://github.com/ushakrishnan/awesome-llm-finetuning
- Owner: ushakrishnan
- License: mit
- Created: 2023-10-08T10:26:06.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2023-11-07T22:53:37.000Z (over 1 year ago)
- Last Synced: 2024-05-21T17:06:02.833Z (about 1 year ago)
- Size: 15.6 KB
- Stars: 3
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- ultimate-awesome - awesome-llm-finetuning - Resources to aid your learning of LLM finetuning. (Other Lists / Julia Lists)
README
# LLM finetuning learning journey quickstart resources
Resources to aid your learning of LLM finetuning learning journey. Guides for starters, intermediate and advamced users. And before you do that, read why efficient finetuning is going to be the key for production read, cost efficient, domain relevant LLMs.
## Table of contents
> **Shortcut to learning media:**
> - [Is (efficient) LLM Finetuning the key to production ready solutions?](#is-efficient-llm-finetuning-the-key-to-production-ready-solutions)
> - [Reading Materials](#reading-materials)
> - [Videos](#videos)
> - [Code Samples](#code-samples)
> - [Whitepapers](#whitepapers)
## Is (efficient) LLM Finetuning the key to production ready solutions?
As POCs and POEs mature to become production ready platforms, the role of fine-tuning (together with RAG in many cases) becomes key to successful production ready LLM AI platforms / solutions. Finetuning gets to be come key and efficient finetuning the pinnacle of production success.
Two articles crisply shares my opinion. Rather than rehashing, here are the gems -
1. [Generative AI — LLMOps Architecture Patterns](https://medium.datadriveninvestor.com/generative-ai-llmops-deployment-architecture-patterns-6d45d1668aba)
Debmalya Biswas breaksdown possible architecture patterns into -
- Black-box LLM APIs
- Enterprise Apps in LLM App Store
- Enterprise LLMOps — LLM fine-tuning
- Multi-agent LLM Orchestration
[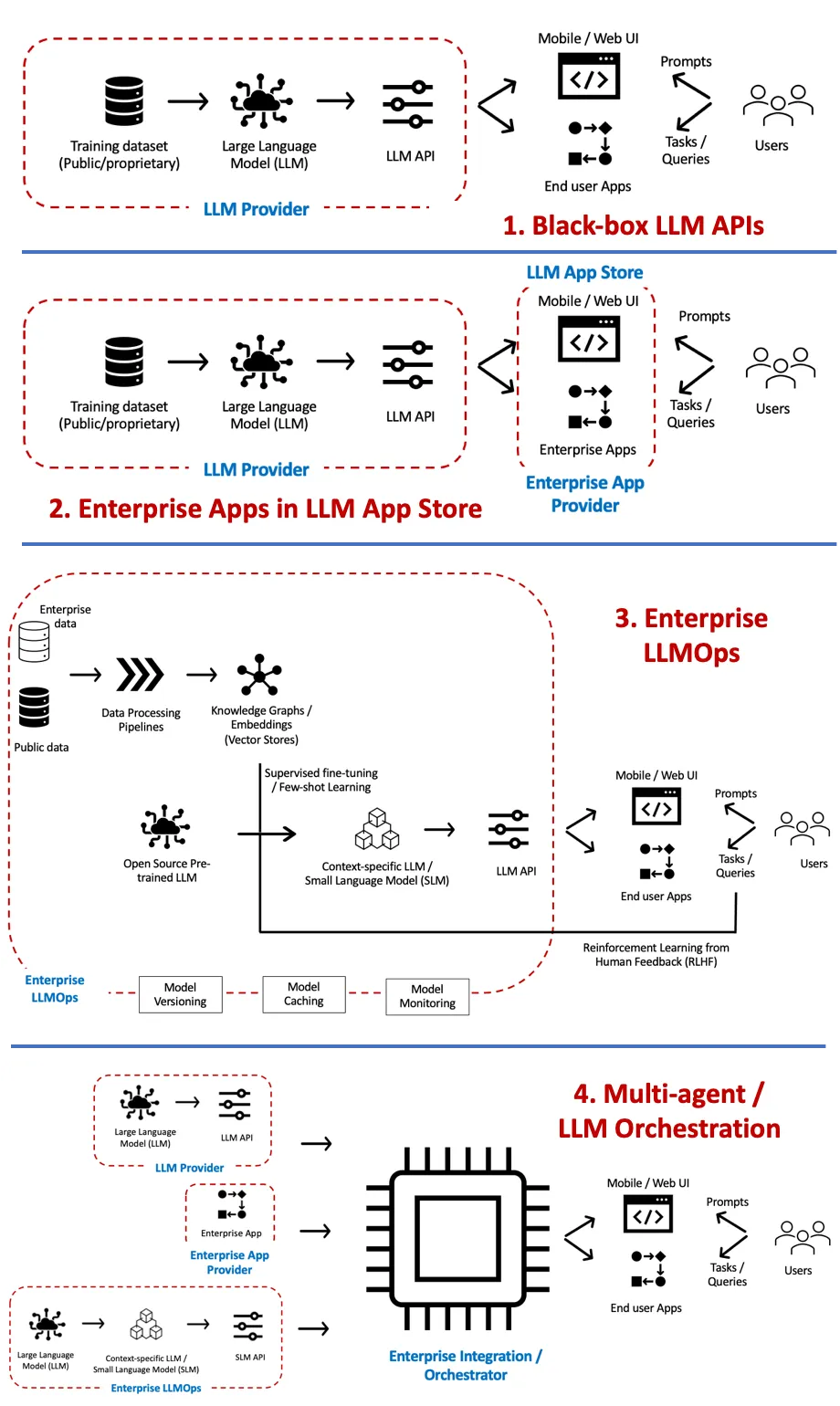](https://medium.datadriveninvestor.com/generative-ai-llmops-deployment-architecture-patterns-6d45d1668aba)
1. [Continuous Delivery for Machine Learning](https://martinfowler.com/articles/cd4ml.html) Danilo Sato, Arif Wider, Christoph Windheuser shares CD4ML which delves deep into how to productionize such models.
[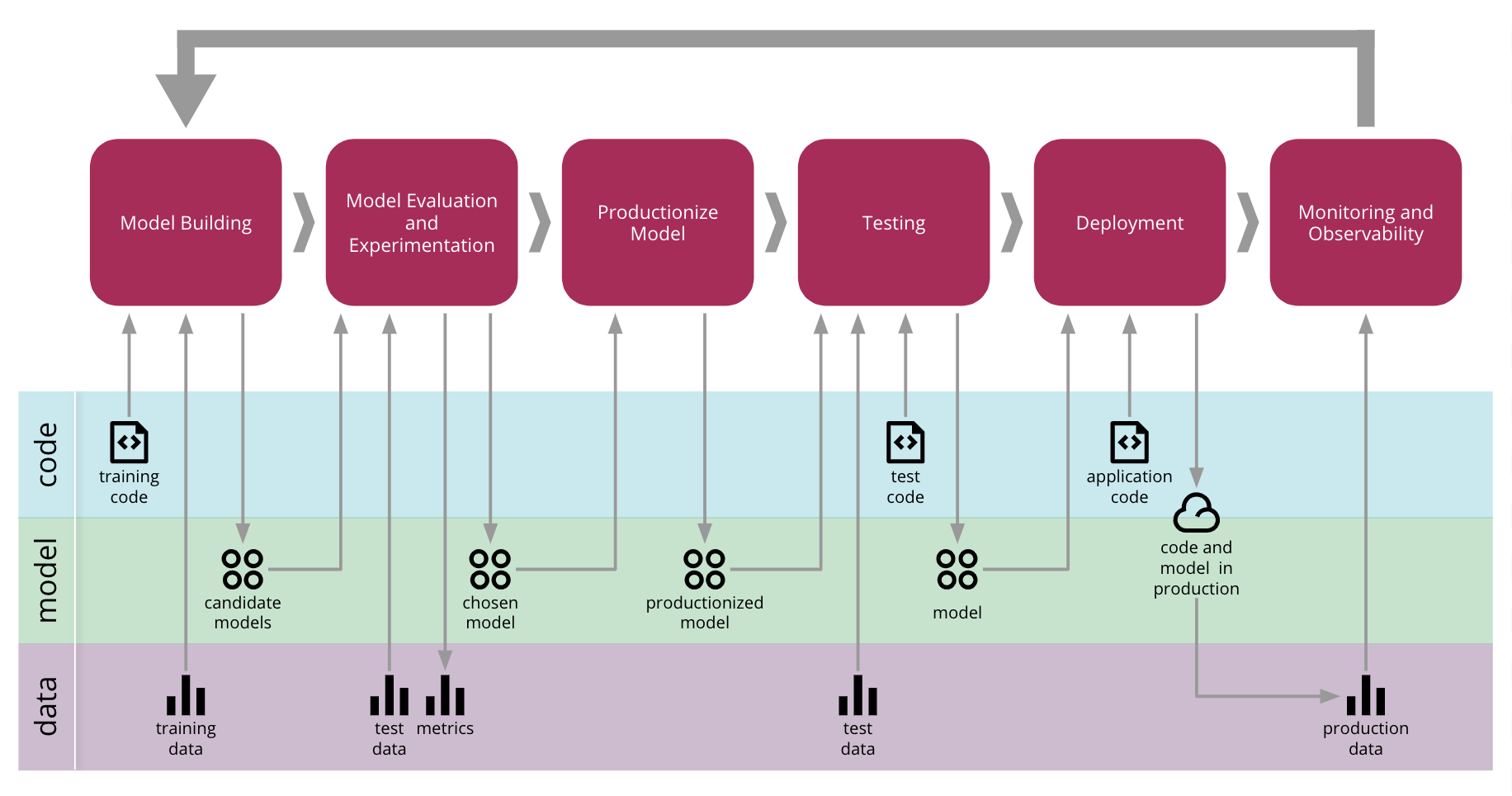](https://martinfowler.com/articles/cd4ml.html)
Also check out the collection of information on how to productionize ML. The biggest jump is from POC to Productionizing, which requires a lot more planning, thoughtful workflows and of course automation - [Awesome Production Machine Learning](https://github.com/EthicalML/awesome-production-machine-learning). Important principles - Reproducibility, Orchestration, Explainability.
Combine the pattern from Debmalya (gem 1) with true and tested MLOps / CD4ML (gem 2) for managing enterprise ready LLMOps platforms and solutions.
My bet from architecture patterns is pattern 3, but too early to call! Efficient Fine-Tuning will be the key to production ready cost effective, domain relevant solutions and platform. And the need to learn and train ourselves with finetuning which may be a preferred way of enterprise / production ready cost effective LLM solutions and platforms surfaces to the top!
And to be ready for this upcoming challenge, here is a collection of resources that can help you get a quickstart.
## Reading Materials
| Content / Blog | Description |
| ----------- | ----------- |
| [**(Beginner)** RAG vs Finetuning](https://towardsdatascience.com/rag-vs-finetuning-which-is-the-best-tool-to-boost-your-llm-application-94654b1eaba7) | RAG vs Finetuning — Which Is the Best Tool to Boost Your LLM Application? The definitive guide for choosing the right method for your use case |
| [**(Beginner)** RAG, Fine-tuning or Both?](https://www.matrixflows.com/blog/retrieval-augmented-generation-rag-finetuning-hybrid-framework-for-choosing-right-strategy) | RAG, Fine-tuning or Both? A Complete Framework for Choosing the Right Strategy |
| [Optimizing LLMs](https://blog.lancedb.com/optimizing-llms-a-step-by-step-guide-to-fine-tuning-with-peft-and-qlora-22eddd13d25b)
_[Accompanying code](https://pbase.ai/FineTuneLlama)_
| Optimizing LLMs: A Step-by-Step Guide to Fine-Tuning with PEFT and QLoRA (A Practical Guide to Fine-Tuning LLM using QLora) |
| [Parameter-Efficient Fine-Tuning (PEFT)](https://huggingface.co/docs/peft/index) | PEFT methods only fine-tune a small number of (extra) model parameters, significantly decreasing computational and storage costs because fine-tuning large-scale PLMs is prohibitively costly. |
| [A guide to parameter efficient fine-tuning (PEFT)](https://www.leewayhertz.com/parameter-efficient-fine-tuning/) | This article will discuss the PEFT method in detail, exploring its benefits and how it has become an efficient way to fine-tune LLMs on downstream tasks.|
| [PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware](https://huggingface.co/blog/peft) | PEFT approaches enable you to get performance comparable to full fine-tuning while only having a small number of trainable parameters.|
| [Ludwig - Declarative deep learning framework](https://ludwig.ai/latest/) _[Framework code](https://github.com/ludwig-ai/ludwig)_
_[Code sample](https://colab.research.google.com/drive/1c3AO8l_H6V_x37RwQ8V7M6A-RmcBf2tG?usp=sharing)_
| Declarative deep learning framework built for scale and efficiency. Ludwig is a low-code framework for building custom AI models like LLMs and other deep neural networks. Learn when and how to use Ludwig! |
| [Fine-tuning OpenLLaMA-7B with QLoRA for instruction following](https://georgesung.github.io/ai/qlora-ift/) _[Accompanying code](https://colab.research.google.com/drive/1IlpeofYD9EU6dNHyKKObZhIzkBMyqlUS?usp=sharing)_
_[Full repo](https://github.com/georgesung/llm_qlora/tree/main)_
| Tried and tested sample - With the availability of powerful base LLMs (e.g. LLaMA, Falcon, MPT, etc.) and instruction tuning datasets, along with the development of LoRA and QLoRA, instruction fine-tuning a base model is increasingly accessible to more people/organizations.|
| [Personal Copilot: Train Your Own Coding Assistant](https://huggingface.co/blog/personal-copilot) _[Code sample](https://github.com/pacman100/DHS-LLM-Workshop/tree/main/personal_copilot/training)_
| In this blog post we show how we created HugCoder, a code LLM fine-tuned on the code contents from the public repositories of the huggingface GitHub organization. |
## Videos
| Video | Description |
| ----------- | ----------- |
| [Efficient Fine-Tuning for Llama-v2-7b on a Single GPU](https://www.youtube.com/watch?v=g68qlo9Izf0) | This session will equip ML engineers to unlock the capabilities of LLMs like Llama-2 on for their own projects.
| [Efficiently Build Custom LLMs on Your Data with Open-source Ludwig](https://www.youtube.com/watch?v=NAyKpcOdHLE)
_[Accompanying code](https://pbase.ai/3YDMrcz)_
| detail for the video |
| [Introduction to Ludwig - multi-model sample](https://www.youtube.com/watch?v=K7yLtB2yaPg) _[Accompanying code](https://colab.research.google.com/drive/1jJcikGm8lSZtWIfw5yAWHmQuALPsU_4p?usp=sharing)_
| Train and Deploy Amazing Models in Less Than 6 Lines of Code with Ludwig AI|
|[Ludwig: A Toolbox for Training and Testing Deep Learning Models without Writing Code](https://huggingface.co/blog/peft) _[Blog post](https://huggingface.co/blog/peft)_
_[Accompanying code](https://colab.research.google.com/drive/14xo6sj4dARk8lXZbOifHEn1f_70qNAwy?usp=sharing)_
| Ludwig, an open source, deep learning toolbox built on top of TensorFlow that allows users to train and test machine learning models without writing code. |
| [**(Beginner)** Build Your Own LLM in Less Than 10 Lines of YAML (Predibase)](https://www.youtube.com/watch?v=efMQgwM9dFY) | Did you know you can start trying [Ludwig OpenSource](https://ludwig.ai/) on Azure How you can get started building your own LLM - How declarative ML simplifies model building and training; How to use off-the-shelf pretrained LLMs with Ludwig - the open-source declarative ML framework from Uber ; How to rapidly fine-tune an LLM on your data in less than 10 lines of code with Ludwig using parameter efficient methods, deepspeed and Ray |
| [**(Beginner)** To Fine Tune or Not Fine Tune? That is the question](https://www.youtube.com/watch?v=0Jo-z-MFxJs) | Ever wondered about the balance between the benefits and drawbacks of fine-tuning models? Curious about when it's the right move for customers? Look no further; we've got you covered! |
## Code Samples
| Sample | Description |
| ----------- | ----------- |
| [Parameter-Efficient Fine-Tuning (PEFT)](https://github.com/huggingface/peft) | PEFT methods only fine-tune a small number of (extra) model parameters, significantly decreasing computational and storage costs because fine-tuning large-scale PLMs is prohibitively costly. |
| [QLoRA: Efficient Finetuning of Quantized LLMs](https://github.com/artidoro/qlora)
_[whitepaper](#qlorawp)_
| QLORA - an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance |
| [Ludwig](https://github.com/ludwig-ai/ludwig) | Low-code framework for building custom LLMs, neural networks, and other AI models |
| [**(Beginner)** Ludwig 0.8: Hands On Webinar](https://colab.research.google.com/drive/1lB4ALmEyvcMycE3Mlnsd7I3bc0zxvk39#scrollTo=xb1aLHZRFrwA) [Webinar video](https://www.youtube.com/watch?v=NAyKpcOdHLE)
| How integrations with Deepspeed and parameter-efficient fine-tuning techniques make training LLMs with Ludwig fast and easy |
| [Fine-tuning LLMs with PEFT and LoRA](https://www.youtube.com/watch?v=Us5ZFp16PaU) _[Accompanying code](https://colab.research.google.com/drive/14xo6sj4dARk8lXZbOifHEn1f_70qNAwy?usp=sharing)_
_[Blog post](https://huggingface.co/blog/peft)_
| PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware |
| [**(Beginner)** Fine-tuning OpenLLaMA-7B with QLoRA for instruction following](https://github.com/georgesung/llm_qlora/tree/main) _[Accompanying code](https://colab.research.google.com/drive/1IlpeofYD9EU6dNHyKKObZhIzkBMyqlUS?usp=sharing)_
_[Blog post](https://georgesung.github.io/ai/qlora-ift/)_
| Tried and tested sample - With the availability of powerful base LLMs (e.g. LLaMA, Falcon, MPT, etc.) and instruction tuning datasets, along with the development of LoRA and QLoRA, instruction fine-tuning a base model is increasingly accessible to more people/organizations.|
| [Curated list of the best LLMOps tools for developers](https://github.com/tensorchord/awesome-llmops) | An awesome & curated list of the best LLMOps tools for developers. |
| [Awesome Production Machine Learning](https://github.com/EthicalML/awesome-production-machine-learning) _[Additional video](https://www.youtube.com/watch?v=Ynb6X0KZKxY)_
| MLOps tools to scale your production machine learning - This repository contains a curated list of awesome open source libraries that will help you deploy, monitor, version, scale and secure your production machine learning |
## Whitepapers
| Sample | Description |
| ----------- | ----------- |
| [LoRA: Low-Rabm Adaptation of Large Language Models](https://arxiv.org/pdf/2106.09685.pdf)| Train with significantly fewer GPUs and avoid I/O bottlenecks. Another benefit is that we can switch between taskswhile deployed at a much lower cost by only swapping the LoRA weights as opposed to all the parameters|
| [QLORA: Efficient Finetuning of Quantized LLMs](https://arxiv.org/pdf/2305.14314.pdf)
_[code sample](#qloracode)_
| QLORA - an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance|