https://github.com/yzy1996/Awesome-Shape-Correspondence
A collection of resources on Shape Correspondences and some of my reading notes.
https://github.com/yzy1996/Awesome-Shape-Correspondence
List: Awesome-Shape-Correspondence
awesome shape-correspondences
Last synced: 3 months ago
JSON representation
A collection of resources on Shape Correspondences and some of my reading notes.
- Host: GitHub
- URL: https://github.com/yzy1996/Awesome-Shape-Correspondence
- Owner: yzy1996
- Created: 2021-07-07T13:43:52.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2022-10-13T11:24:08.000Z (over 2 years ago)
- Last Synced: 2024-05-20T01:06:30.711Z (9 months ago)
- Topics: awesome, shape-correspondences
- Homepage:
- Size: 132 KB
- Stars: 3
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- ultimate-awesome - Awesome-Shape-Correspondence - A collection of resources on Shape Correspondences and some of my reading notes. (Other Lists / Julia Lists)
README
#
`Shape Correspondence`
[](https://github.com/sindresorhus/awesome)
[](https://GitHub.com/Naereen/StrapDown.js/graphs/commit-activity)
[](http://makeapullrequest.com)

A collection of resources on Shape Correspondences and some of my reading notes.
**Contributing:** Feedback and contributions are welcome! If you think I have missed out on something (or) have any suggestions (papers, implementations and other resources), feel free to pull a request or leave an issue. I will release the [latex-pdf version]() in the future. :arrow_down:markdown format:
``` markdown
[Paper Name](abs link)
*[Author 1](homepage), Author 2, and Author 3*
**[`Conference/Journal Year`] (`Institution`)** [[Github](link)] [[Project](link)]
```
:smile: Now you can use this [script](https://github.com/yzy1996/Python-Code/tree/master/Python%2BarXiv) to automatically generate the above text.
## Table of Contents
- [Introduction](#Introduction)
- [Impact](#Impact)
- [Evaluation](#Evaluation)
- [Data](#Data)
- [Literature](#Literature)
- [Survey](#Survey)
- [Supervised](#Supervised)
- [2D Perspective](#2D-Perspective)
- [3D Perspective](#3D-Perspective)
- [Other domain](#Other-domain)
## Introduction
Both 2D and 3D keypoint detection are long-standing problems in computer vision.
> A set of keypoints representing any object (**shape/structure**) is important for **geometric reasoning**, due to their simplicity and ease of handling. [^ intro2]
> Keypoints-based methods have been crucial to the success of many vision applications. Examples include: 3D reconstruction, registration, human body pose, recognition, and generation. [^ intro2]
Conventional works define keypoints manually or learn from supervised examples, automatically discovering them from unlabeled data (**unsupervised**) is what we need.
The keypoints should be **geometrically** and **semantically** consistent across viewing angles and instances of an object category.
The model we learn often covers a collection of objects of **a specific category**.
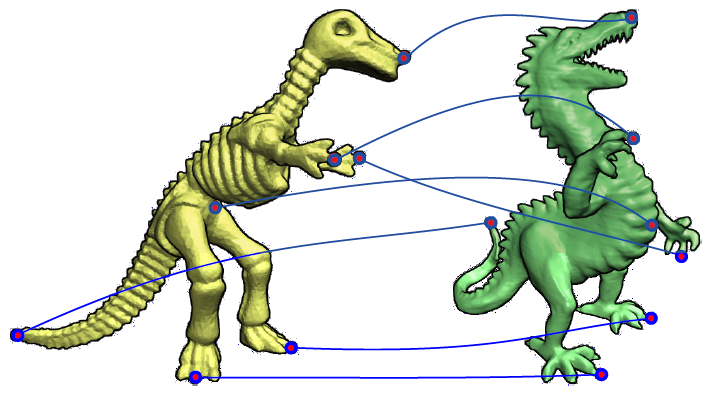
**Shape correspondence problem** is stated as finding a set of corresponding points between given shapes.
**Dense semantic correspondence** - given two images, the goal is to predict for each pixel in the former, the corresponding pixel in the latter.
**Sparse correspondences** focus on only a few keypoints.
We can use **infer/learn** xx as a predicate, and we can use points with lines or same colors to assign correspondences.
**先笼统地介绍:**
- 关键点很重要:因为可以看成是物体的一种最简洁形状表征,就可以用来形状编辑,重建,识别等;所以如何找关键点是一个很重要的研究问题。同时分类和识别工作同时伴随着的是特征提取,那么在geometric vision 领域,比如 3D reconstruction and shape alignment 是不是也伴随着有一个 keypoint detection module 的前置任务,然后再是 geometric reasoning。
- 关键点的特点 - 不随视角,光线,形状变化,姿态 而变化
**Equivariance**: equivariant to image transformation, including object and camera motions. 3D pose, size, position, viewing angle, and illumination conditions
- 关键点检测的拓展:姿态估计
**现在可以做到:**
- 2D/3D数据输入
- 监督和无监督,这里的监督指的是特征点标记
- 一个模型涵盖同一类物体
**Keywords**: landmark, parts, skeletons, category-specific
keypoint heatmap: 关键点热力图,图中数值越大的位置,越有可能是关键点
## Impact
应用多 generic framework for: texture transfer \ pose and animation transfer \ statistical shape analysis \ 多视角识别
主要是: detection and segmentation. 对于相关性而言,都已经知道相关性了,one-shot标注后直接就迁移到了新的object上了。传统方法主要是依靠手动标记,所以重点找一下不需要手动标记的方法。
有一个最权威的人体关节点定位比赛: MS COCO Keypoint track
robotics applications need 3D keypoints for control
- 2019 Keypoint affordances for category-level robotic manipulation
- 2019 kpam-sc: Generalizable manipulation planning using keypoint affordance and shape completion
直接利用/借用keypoint的工作:
**Non-Rigid Structure-from-Motion (NRSfM)** methods ref:
- Multiview aggregation for learning category-specific shape reconstruction
- Symmetric non-rigid structure from motion for category-specific object structure estimation
> The key idea is that a large number of object deformations can be explained by linearly combining a smaller K number of basis shapes at some pose. 对刚体而言,只有一个基础形状,秩为3。
里面用来对**形状变形建模**的主要方法有:
- low-rank shape prior
- A simple prior-free method for non-rigid structure-from-motion factorization
- Recovering non-rigid 3D shape from image streams (鼻祖)
- Nonrigid structure-from-motion: Estimating shape and motion with hierarchical priors
- Nonrigid structure from motion in trajectory space
- isometric prior
- Non-rigid structure from locally-rigid motion
- Isometric non-rigid shape-from-motion in linear time
## Evaluation
可以手动标然后做回归
## Data
annotated keypoints for:
- face [^ face]
- hands [^ hand]
- human bodies [^ body1] [^ body2]
## Literature
最早的肯定是有监督的一类方法,而后是一类无监督的,而我们重点关心的是无监督的。所以文献归类里先把有监督的混在一起,然后无监督的再按更小的方法类别划分。最后还有一些用到人体,鸟类,家具上的。
### Survey
- [A survey on shape correspondence](https://www.cs.sfu.ca/~haoz/pubs/vanKaick_cgf11_survey.pdf)
**[`Computer Graphics Forum 2010`] (`Simon Fraser`)**
*Oliver van Kaick, Hao Zhang, Ghassan Hamarneh, Daniel Cohen-Or*
- [Recent advances in shape correspondence](https://link.springer.com/content/pdf/10.1007/s00371-019-01760-0.pdf)
**[`The Visual Computer 2020`] (`METU`)**
*Yusuf Sahillioglu*
### Supervised
- [Simultaneous facial landmark detection, pose and deformation estimation under facial occlusion](https://arxiv.org/pdf/1709.08130.pdf)
**[`CVPR 2017`] (`Rensselaer Polytechnic Institute`)**
*Yue Wu, Chao Gou, Qiang Ji*
- [Deep Deformation Network for Object Landmark Localization](https://arxiv.org/pdf/1605.01014.pdf)
**[`ECCV 2016`] (`NEC`)**
*Xiang Yu, Feng Zhou, Manmohan Chandraker*
- [Facial landmark detection by deep multi-task learning](http://personal.ie.cuhk.edu.hk/~ccloy/files/eccv_2014_deepfacealign.pdf)
**[`ECCV 2014`] (`CUHK`)**
*Zhanpeng Zhang, Ping Luo, Chen Change Loy, and Xiaoou Tang*
- [Deep Convolutional Network Cascade for Facial Point Detection](https://www.cv-foundation.org/openaccess/content_cvpr_2013/papers/Sun_Deep_Convolutional_Network_2013_CVPR_paper.pdf)
**[`CVPR 2013`] (`CUHK`)**
*Yi Sun, Xiaogang Wang, Xiaoou Tang*
下面分类是依据输入和输出数据的维度为2D还是3D
### 2D Perspective
(注意里面也包含了利用3D中间体过渡的一类方法)
- [SIFT: Object recognition from local scale-invariant features](https://www.cs.ubc.ca/~lowe/papers/iccv99.pdf)
**[`ICCV 1999`] (`British Columbia`)**
*D.G. Lowe*
- [SURF: Speeded Up Robust Features](https://people.ee.ethz.ch/~surf/eccv06.pdf)
**[`ECCV 2006`] (`ETH`)**
*Herbert Bay, Tinne Tuytelaars, Luc Van Gool*
#### local descriptor based
用一些特征算子找,用神经网络提取特征层面的对应关系,需要有标记的数据集
- [SIFT Flow: Dense Correspondence across Scenes and Its Applications](https://people.csail.mit.edu/celiu/SIFTflow/SIFTflow.pdf)
**[`PAMI 2011`] (`MIT, Microsoft`)**
*Ce Liu, Jenny Yuen, Antonio Torralba*
- [Deformable spatial pyramid matching for fast dense correspondences](https://people.csail.mit.edu/celiu/pdfs/CVPR13-DSPM.pdf)
**[`CVPR 2013`] (`UT Austin, Microsoft`)**
*Jaechul Kim, Ce Liu, Fei Sha, Kristen Grauman*
- [Do convnets learn correspondence?](https://arxiv.org/pdf/1411.1091.pdf)
**[`NeurIPS 2014`] (`UCB`)**
*Jonathan Long, Ning Zhang, Trevor Darrell*
- [Proposal flow](https://arxiv.org/pdf/1511.05065.pdf)
**[`CVPR 2016`] (`Inria`)**
*Bumsub Ham, Minsu Cho, Cordelia Schmid, Jean Ponce*
#### parametric warping
match local feature 提取像素点的特征,然后做匹配,既可以通过学习变形的function,也可以通过学习encoder压缩到一个低维共性点
同一物体,同一视角,很受限
Warpnet: Weakly supervised matching for singleview reconstruction
- [Convolutional neural network architecture for geometric matching](https://arxiv.org/pdf/1703.05593.pdf)
**[`CVPR 2017`] (`DI ENS, Inria`)**
*Ignacio Rocco, Relja Arandjelovic, Josef Sivic*
- [End-to-end weakly-supervised semantic alignment](https://arxiv.org/pdf/1712.06861.pdf)
**[`CVPR 2018`] (`DI ENS, Inria, DeepMind`)**
*Ignacio Rocco, Relja Arandjelovic, Josef Sivic*
#### learn equivariant embeddings/decoder
- [Unsupervised learning of object frames by dense equivariant image labelling](https://arxiv.org/pdf/1706.02932.pdf)
**[`NeurIPS 2017`] (`Oxford`)**
*James Thewlis, Hakan Bilen, Andrea Vedaldi*
- [Unsupervised learning of object landmarks by factorized spatial embeddings](https://arxiv.org/pdf/1705.02193.pdf)
**[`ICCV 2017`] (`Oxford`)**
*James Thewlis, Hakan Bilen, Andrea Vedaldi*
- [Self-supervised learning of a facial attribute embedding from video](https://arxiv.org/pdf/1808.06882.pdf)
**[`BMVC 2018`] (`Oxford`)**
*Olivia Wiles, A. Sophia Koepke, Andrew Zisserman*
- [Unsupervised learning of object landmarks through conditional image generation](https://arxiv.org/pdf/1806.07823.pdf)
**[`NeurIPS 2018`] (`Oxford`)**
*Tomas Jakab, Ankush Gupta, Hakan Bilen, Andrea Vedaldi*
- [Unsupervised discovery of object landmarks as structural representations](https://arxiv.org/pdf/1804.04412.pdf)
**[`CVPR 2018`] (`Michigan`)**
*Yuting Zhang, Yijie Guo, Yixin Jin, Yijun Luo, Zhiyuan He, Honglak Lee*
- [Teacher supervises students how to learn from partially labeled images for facial landmark detection](https://arxiv.org/pdf/1908.02116.pdf)
**[`ICCV 2019`] (`SUST`)**
*Xuanyi Dong, Yi Yang*
- [Unsupervised learning of landmarks by descriptor vector exchange](https://arxiv.org/pdf/1908.06427.pdf)
**[`ICCV 2019`] (`Oxford`)**
*James Thewlis, Samuel Albanie, Hakan Bilen, Andrea Vedaldi*
- [Self-supervised learning of interpretable keypoints from unlabelled videos](https://openaccess.thecvf.com/content_CVPR_2020/papers/Jakab_Self-Supervised_Learning_of_Interpretable_Keypoints_From_Unlabelled_Videos_CVPR_2020_paper.pdf)
**[`CVPR_2020`] (`Oxford`)**
*Tomas Jakab, Ankush Gupta, Hakan Bilen, Andrea Vedaldi*
除了直接找2D特征层面的相关性,还可以借助3D层面特征为中间过渡
Compared with directly learning correspondence maps from 2D images, learning from 3D structures as an intermediate medium is more powerful.
#### 3D medium Template
> Plato famously remarked that while there are many cups in the world, there is only one 'idea' of a cup, which he defined as a 'cupness'. So Any particular instance of a category can thus be understood via its relationship to this platonic ideal. We humans have an ability to reason 3D structure from a 2D image.
- [Learning Dense Correspondence via 3D-guided Cycle Consistency](https://arxiv.org/pdf/1604.05383.pdf)
**[`CVPR 2016`] (`UCB`)**
*Tinghui Zhou, Philipp Krähenbßhl, Mathieu Aubry, Qixing Huang, Alexei A. Efros*
- [Canonical Surface Mapping via Geometric Cycle Consistency](https://arxiv.org/pdf/1907.10043.pdf)
**[`ICCV 2019`] (`CMU, Facebook`)**
*Nilesh Kulkarni, Abhinav Gupta, Shubham Tulsiani*
- [Articulation-aware Canonical Surface Mapping](https://arxiv.org/pdf/2004.00614.pdf)
**[`CVPR 2020`] (`UM, CMU, Facebook`)**
*Nilesh Kulkarni, Abhinav Gupta, David F. Fouhey, Shubham Tulsiani*
> 上面的方法需要假设存在这样一个“模板“,究竟是否真实存在呢?下面方法说可以不要模板
#### 3D medium semantic transfer
- [Semantic Correspondence via 2D-3D-2D Cycle](https://arxiv.org/pdf/2004.09061.pdf)
**[`Arxiv 2020`] (`SJTU`)**
*Yang You, Chengkun Li, Yujing Lou, Zhoujun Cheng, Lizhuang Ma, Cewu Lu, Weiming Wang*
用带pose的2D图片
- [Discovery of latent 3d keypoints via end-to-end geometric reasoning](https://arxiv.org/pdf/1807.03146.pdf)
**[`NeurIPS 2018`] (`Google`)**
*Supasorn Suwajanakorn, Noah Snavely, Jonathan Tompson, Mohammad Norouzi*
- [Implicit 3D Orientation Learning for 6D Object Detection from RGB Images](https://arxiv.org/pdf/1902.01275.pdf)
**[`ECCV 2018`] (`German Aerospace Center, TUM`)**
*Martin Sundermeyer, Zoltan-Csaba Marton, Maximilian Durner, Manuel Brucker, Rudolph Triebel*
### 3D Perspective
> Dataset: ShapeNet, PartNet
- [KeypointDeformer: Unsupervised 3D Keypoint Discovery for Shape Control](https://arxiv.org/pdf/2104.11224.pdf)
**[`CVPR 2021`] (`Oxford, UCB, Stanford`)**
*Tomas Jakab, Richard Tucker, Ameesh Makadia, Jiajun Wu, Noah Snavely, Angjoo Kanazawa*
- [Unsupervised learning of intrinsic structural representation points](https://arxiv.org/pdf/2003.01661.pdf)
**[`CVPR 2020`] (`HKU, MPI`)**
*Nenglun Chen, Lingjie Liu, Zhiming Cui, Runnan Chen, Duygu Ceylan, Changhe Tu, Wenping Wang*
- [KeypointNet: A Large-scale 3D Keypoint Dataset Aggregated from Numerous Human Annotations](https://arxiv.org/pdf/2002.12687.pdf)
**[`CVPR 2020`] (`SJTU`)**
*Yang You, Yujing Lou, Chengkun Li, Zhoujun Cheng, Liangwei Li, Lizhuang Ma, Weiming Wang, Cewu Lu*
- [Unsupervised Learning of Category-Specific Symmetric 3D Keypoints from Point Sets](https://arxiv.org/pdf/2003.07619.pdf)
**[`ECCV 2020`] (`ETH`)**
*Clara Fernandez-Labrador, Ajad Chhatkuli, Danda Pani Paudel, Jose J. Guerrero, CĂŠdric Demonceaux, Luc Van Gool*
- [Unsupervised learning of dense shape correspondence](https://openaccess.thecvf.com/content_CVPR_2019/papers/Halimi_Unsupervised_Learning_of_Dense_Shape_Correspondence_CVPR_2019_paper.pdf)
**[`CVPR 2019`] (`Technion`)**
*Oshri Halimi, Or Litany, Emanuele RodolĂ RodolĂ , Alex M. Bronstein, Ron Kimmel*
- [USIP: Unsupervised Stable Interest Point Detection from 3D Point Clouds](https://arxiv.org/pdf/1904.00229.pdf)
**[`ICCV 2019`] (`NUS`)**
*Jiaxin Li, Gim Hee Lee*
- [Convolutional experts constrained local model for 3d facial landmark detection](https://arxiv.org/pdf/1611.08657.pdf)
**[`CVPR-W 2017`] (`CMU`)**
*Amir Zadeh, Tadas BaltruĹĄaitis, Louis-Philippe Morency*
### Other domain
#### human bodies
- [Cascaded pose regression](https://authors.library.caltech.edu/23201/1/Dollar2010p133332008_Ieee_Conference_On_Computer_Vision_And_Pattern_Recognition_Vols_1-12.pdf)
**[`CVPR 2010`] (`CIT`)**
*Piotr DollĂĄr, Peter Welinder, Pietro Perona*
- [Articulated pose estimation with flexible mixtures-of-parts](https://www.cs.cmu.edu/~deva/papers/pose2011.pdf)
**[`CVPR 2011`] (`UCI`)**
*Yi Yang, Deva Ramanan*
- [DeepPose: Human pose estimation via deep neural networks](https://arxiv.org/pdf/1312.4659.pdf)
**[`CVPR 2014`] (`Google`)**
*Alexander Toshev, Christian Szegedy*
- [Cascaded hand pose regression](https://openaccess.thecvf.com/content_cvpr_2015/papers/Sun_Cascaded_Hand_Pose_2015_CVPR_paper.pdf)
**[`CVPR 2015`] (`CUHK`)**
*Xiao Sun, Yichen Wei, Shuang Liang, Xiaoou Tang, Jian Sun*
- [Stacked Hourglass Networks for Human Pose Estimation](https://arxiv.org/pdf/1603.06937.pdf)
**[`ECCV 2016`] (`Michigan`)**
*Alejandro Newell, Kaiyu Yang, Jia Deng*
- [Hand Keypoint Detection in Single Images using Multiview Bootstrapping](https://arxiv.org/pdf/1704.07809.pdf)
**[`CVPR 2017`] (`CMU`)**
*Tomas Simon, Hanbyul Joo, Iain Matthews, Yaser Sheikh*
#### bird
- Deep Deformation Network for Object Landmark Localization
- Part Localization using Multi-Proposal Consensus for Fine-Grained Categorization
- Bird part localization using exemplar-based models with enforced pose and subcategory consistency
#### furniture
- [Single Image 3D Interpreter Network](https://arxiv.org/pdf/1604.08685.pdf)
**[`ECCV 2016`] (`MIT`)**
*Jiajun Wu, Tianfan Xue, Joseph J. Lim, Yuandong Tian, Joshua B. Tenenbaum, Antonio Torralba, William T. Freeman*
## Knowledge
**UV mapping**:
[^ intro2]: Unsupervised Learning of Category-Specific Symmetric 3D Keypoints from Point Sets
[^KeypointDeformer]: KeypointDeformer
[^ face]: 300 faces in-the-wild challenge: Database and results
[^ hand]: Real-time continuous pose recovery of human hands using convolutional networks
[^ body1]: 2D human pose estimation: New benchmark and state of the art analysis
[^ body2]: Microsoft COCO: Common objects in context